实例演示:如何构建高可用的微服务架构
Posted RancherLabs
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了实例演示:如何构建高可用的微服务架构相关的知识,希望对你有一定的参考价值。
R
5月8日晚20:30,Kubernetes Master Class在线培训第五期即将开播,点击文末【阅读原文】即可免费预约注册!
当你设计和构建大规模应用时,你将面临两个重大挑战:可伸缩性和健壮性。
你应该这样设计你的服务,即使它受到间歇性的重负载,它仍能可靠地运行。
以Apple Store为例,每年都有数百万的Apple客户预先注册购买新的iPhone。这是数百万人同时购买物品。
如果你要将Apple商店的流量描述为每秒的请求数量,那么它可能是下图的样子:
现在想象一下,你的任务是构建这样的应用程序。
你正在建立一个商店,用户可以在那里购买自己喜欢的商品。
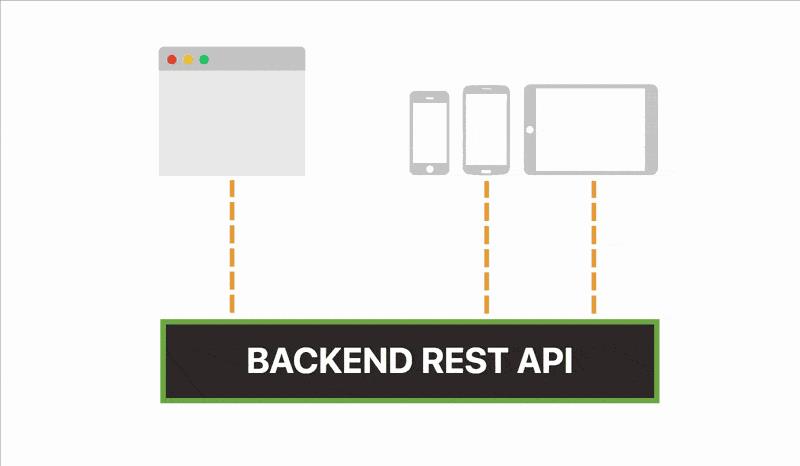
你构建一个微服务来呈现网页并提供静态资产。你还构建了一个后端REST API来处理传入的请求。
你希望将两个组件分开,因为这样可以使用相同的REST API,为网站和移动应用程序提供服务。
今天是重要的一天,你的商店上线了。
你决定将应用程序扩展为前端四个实例和后端四个实例,因为你预测网站比平常更繁忙。
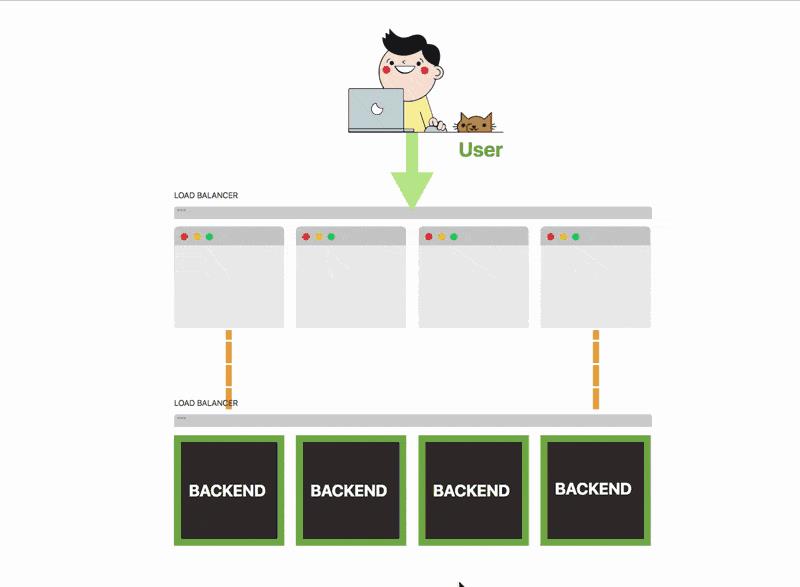
你开始接收越来越多的流量。
前端服务正在很好得处理流量。但是你注意到连接到数据库的后端正在努力跟上事务的数量。
不用担心,你可以将后端的副本数量扩展到8。
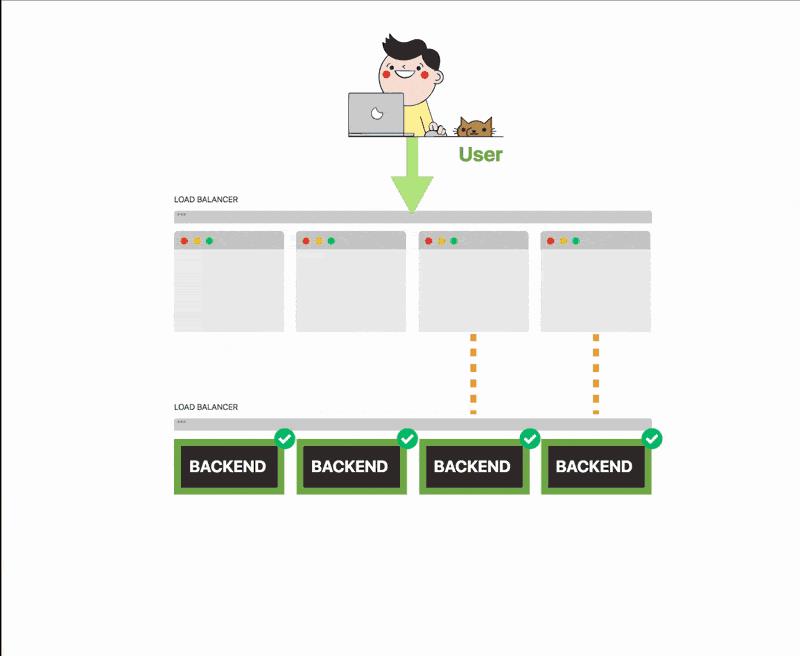
你收到的流量更多,后端无法应对。
一些服务开始丢弃连接。愤怒的客户与你的客服取得联系。而现在你被淹没在大量流量中。
你的后端无法应付它,它会失去很多连接。
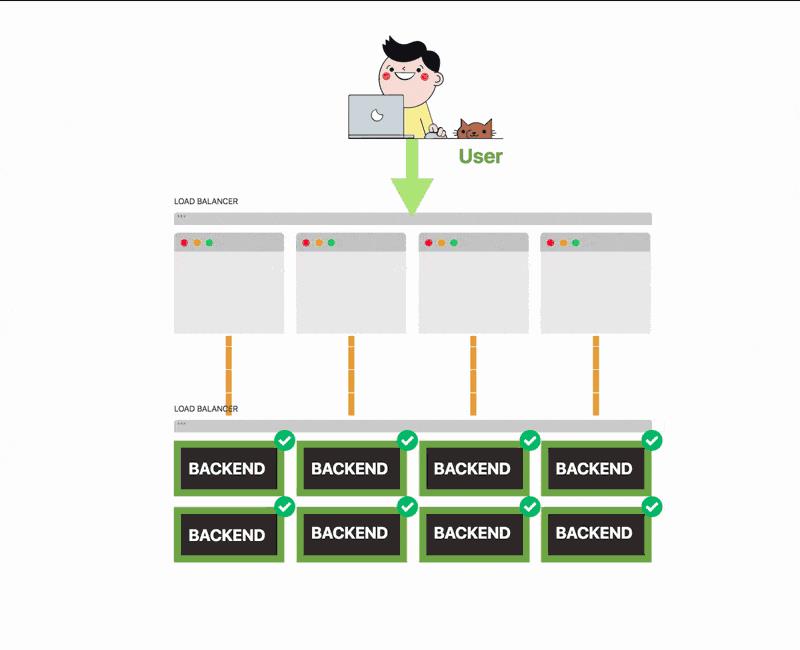
你刚丢了一大笔钱,你的顾客也不高兴。
你的应用程序设计得并不理想,也不满足高可用,因为在你的架构中:
前端和后端紧密耦合——实际上它不能在没有后端的情况下处理应用
前端和后端必须一致扩展——如果没有足够的后端,你可能会淹没在流量中
如果后端不可用,则无法处理传入的事务。
失去事务意味着收入损失。
你可以重新设计架构,以便将前端和后端用队列分离。
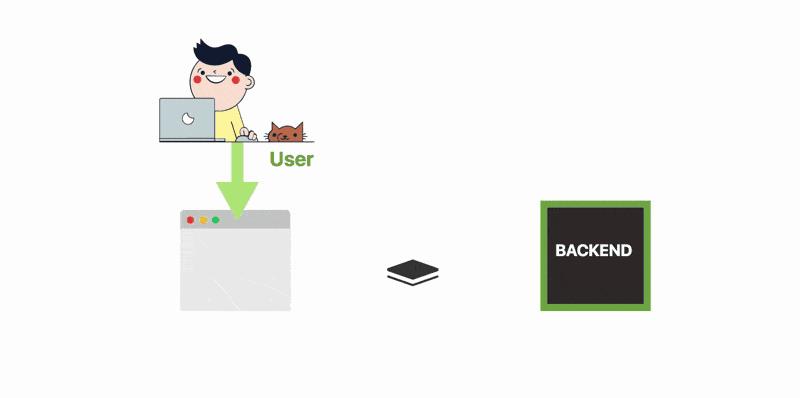
前端将消息发布到队列,而后端则一次处理一个待处理消息。
新架构有一些明显的好处:
如果后端不可用,则队列充当缓冲区
如果前端产生的消息多于后端可以处理的消息,则这些消息将缓冲在队列中
你可以独立于前端扩展后端——即你可以拥有数百个前端服务和后端的单个实例
太好了,但是你如何构建这样的应用程序?
你如何设计可处理数十万个请求的服务?你如何部署动态扩展的应用程序?在深入了解部署和扩展的细节之前,让我们关注应用程序。

编写Spring应用程序
该服务有三个组件:前端,后端和消息代理。
前端是一个简单的Spring Boot Web应用程序,带有Thymeleaf模板引擎。后端是一个消耗队列消息的工作者。
由于Spring Boot与JSM能出色得集成,因此你可以使用它来发送和接收异步消息。
你可以在learnk8s / spring-boot-k8s-hpa[1]中找到一个连接到JSM的前端和后端应用程序的示例项目。
请注意,该应用程序是用Java 10编写的,以利用改进的Docker容器集成能力。
只有一个代码库,你可以将项目配置为作为前端或后端运行。
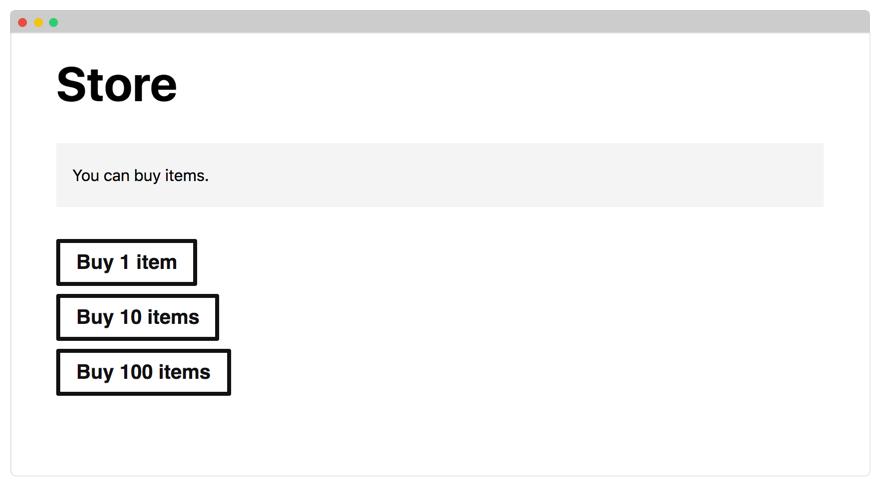
你应该知道该应用程序具有:
一个购买物品的主页
管理面板,你可以在其中检查队列中的消息数
一个 /health 端点,用于在应用程序准备好接收流量时发出信号
一个 /submit 端点,从表单接收提交并在队列中创建消息
一个 /metrics 端点,用于公开队列中待处理消息的数量(稍后将详细介绍)
该应用程序可以在两种模式下运行:
作为前端,应用程序呈现人们可以购买物品的网页。
作为工作者,应用程序等待队列中的消息并处理它们。
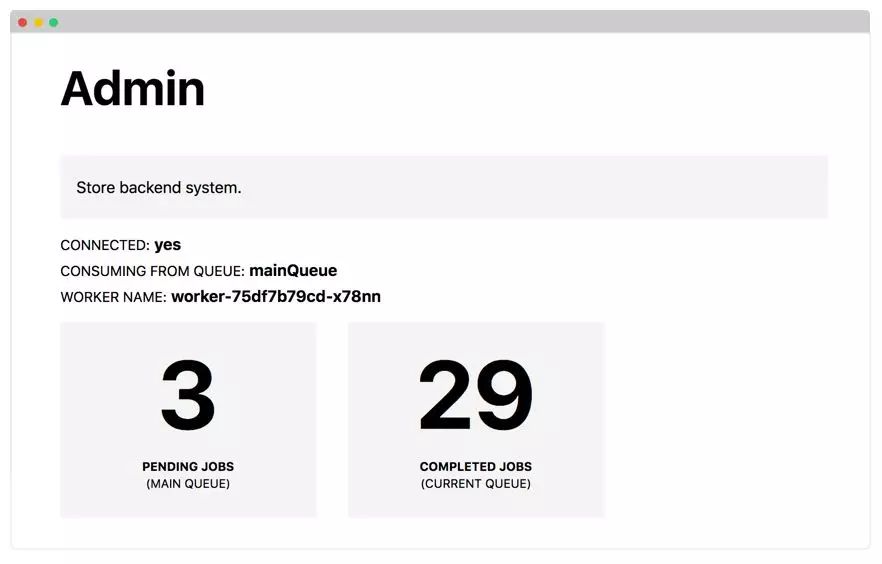
请注意,在示例项目中,使用Thread.sleep(5000)等待五秒钟来模拟处理。
你可以通过更改application.yaml中的值来在任一模式下配置应用程序。
模拟应用程序的运行
默认情况下,应用程序作为前端和工作程序启动。
你可以运行该应用程序,只要你在本地运行ActiveMQ实例,你就应该能够购买物品并让系统处理这些物品。
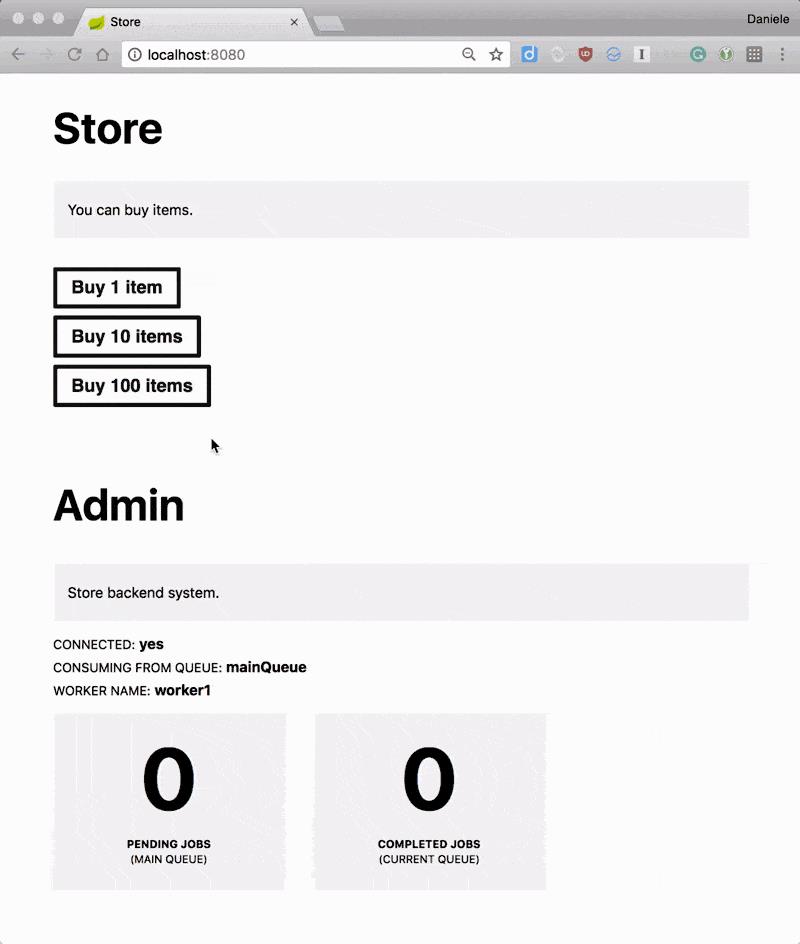
如果检查日志,则应该看到工作程序处理项目。
它确实工作了!编写Spring Boot应用程序很容易。
一个更有趣的主题是学习如何将Spring Boot连接到消息代理。
使用JMS发送和接收消息
Spring JMS(Java消息服务)是一种使用标准协议发送和接收消息的强大机制。
如果你以前使用过JDBC API,那么你应该熟悉JMS API,因为它的工作方式很类似。
你可以按JMS方式来使用的最流行的消息代理是ActiveMQ——一个开源消息服务器。
使用这两个组件,你可以使用熟悉的接口(JMS)将消息发布到队列(ActiveMQ),并使用相同的接口来接收消息。
更妙的是,Spring Boot与JMS的集成非常好,因此你可以立即加快速度。
实际上,以下短类封装了用于与队列交互的逻辑:
@Component
public class QueueService implements MessageListener {
private static final Logger LOGGER = LoggerFactory.getLogger(QueueService.class);
@Autowired
private JmsTemplate jmsTemplate;
public void send(String destination, String message) {
LOGGER.info("sending message='{}' to destination='{}'", message, destination);
jmsTemplate.convertAndSend(destination, message);
}
@Override
public void onMessage(Message message) {
if (message instanceof ActiveMQTextMessage) {
ActiveMQTextMessage textMessage = (ActiveMQTextMessage) message;
try {
LOGGER.info("Processing task " textMessage.getText());
Thread.sleep(5000);
LOGGER.info("Completed task " textMessage.getText());
} catch (InterruptedException e) {
e.printStackTrace();
} catch (JMSException e) {
e.printStackTrace();
}
} else {
LOGGER.error("Message is not a text message " message.toString());
}
}
}
你可以使用send方法将消息发布到命名队列。
此外,Spring Boot将为每个传入消息执行onMessage方法。
最后一个难题是指示Spring Boot使用该类。
你可以通过在Spring Boot应用程序中注册侦听器来在后台处理消息,如下所示:
@SpringBootApplication
@EnableJms
public class SpringBootApplication implements JmsListenerConfigurer {
@Autowired
private QueueService queueService;
public static void main(String[] args) {
SpringApplication.run(SpringBootApplication.class, args);
}
@Override
public void configureJmsListeners(JmsListenerEndpointRegistrar registrar) {
SimpleJmsListenerEndpoint endpoint = new SimpleJmsListenerEndpoint();
endpoint.setId("myId");
endpoint.setDestination("queueName");
endpoint.setMessageListener(queueService);
registrar.registerEndpoint(endpoint);
}
}
其中id是使用者的唯一标识符,destination是队列的名称。
你可以从GitHub[2]上的项目中完整地读取Spring队列服务的源代码。
回顾一下你是如何在少于40行代码中编写可靠队列的。
你一定很喜欢Spring Boot。
你在部署时节省的所有时间都可以专注于编码
你验证了应用程序的工作原理,现在是时候部署它了。
此时,你可以启动VPS,安装Tomcat,并花些时间制作自定义脚本来测试,构建,打包和部署应用程序。
或者你可以编写你希望拥有的描述:一个消息代理和两个使用负载均衡器部署的应用程序。
诸如Kubernetes之类的编排器可以阅读你的愿望清单并提供正确的基础设施。
由于花在基础架构上的时间减少意味着更多的时间编码,这次你将把应用程序部署到Kubernetes。但在开始之前,你需要一个Kubernetes集群。
你可以注册Google云平台或Azure,并使用Kubernetes提供的云提供商服务。或者,你可以在将应用程序移动到云上之前在本地尝试Kubernetes。
minikube是一个打包为虚拟机的本地Kubernetes集群。如果你使用的是Windows,Linux和Mac,那就太好了,因为创建群集需要五分钟。
你还应该安装kubectl,即连接到你的群集的客户端。
你可以从官方文档[3]中找到有关如何安装minikube和kubectl的说明。
如果你在Windows上运行,则应查看有关如何安装Kubernetes和Docker的详细指南[4]。
你应该启动一个具有8GB RAM和一些额外配置的集群:
minikube start
--memory 8096
--extra-config=controller-manager.horizontal-pod-autoscaler-upscale-delay=1m
--extra-config=controller-manager.horizontal-pod-autoscaler-downscale-delay=2m
--extra-config=controller-manager.horizontal-pod-autoscaler-sync-period=10s
请注意,如果你使用的是预先存在的minikube实例,则可以通过销毁VM来重新调整VM的大小。只需添加--memory8096就不会有任何影响。
验证安装是否成功。你应该看到以列表形式展示的一些资源。集群已经准备就绪,也许你应该立即开始部署?
还不行。
你必须先装好你的东西。
什么比uber-jar更好?容器
部署到Kubernetes的应用程序必须打包为容器。毕竟,Kubernetes是一个容器编排器,所以它本身无法运行你的jar。
容器类似于fat jar:它们包含运行应用程序所需的所有依赖项。甚至JVM也是容器的一部分。所以他们在技术上是一个更胖的fat-jar。
将应用程序打包为容器的流行技术是Docker。
虽然Docker是最受欢迎的,但它并不是唯一能够运行容器的技术。其他受欢迎的选项包括rkt和lxd。
如果你没有安装Docker,可以按照Docker官方网站上的说明[5]进行操作。
通常,你构建容器并将它们推送到仓库。它类似于向Artifactory或Nexus推送jar包。但在这种特殊情况下,你将在本地工作并跳过仓库部分。实际上,你将直接在minikube中创建容器镜像。
首先,按照此命令打印的说明将Docker客户端连接到minikube:
minikube docker-env
请注意,如果切换终端,则需要重新连接minikube内的Docker守护程序。每次使用不同的终端时都应遵循相同的说明。
并从项目的根目录构建容器镜像:
docker build -t spring-k8s-hp0a .
你可以验证镜像是否已构建并准备好运行:
docker images |grep spring
很好。
集群已准备好,你打包应用程序,也许你已准备好立即部署?
是的,你最终可以要求Kubernetes部署应用程序。
将你的应用程序部署到Kubernetes
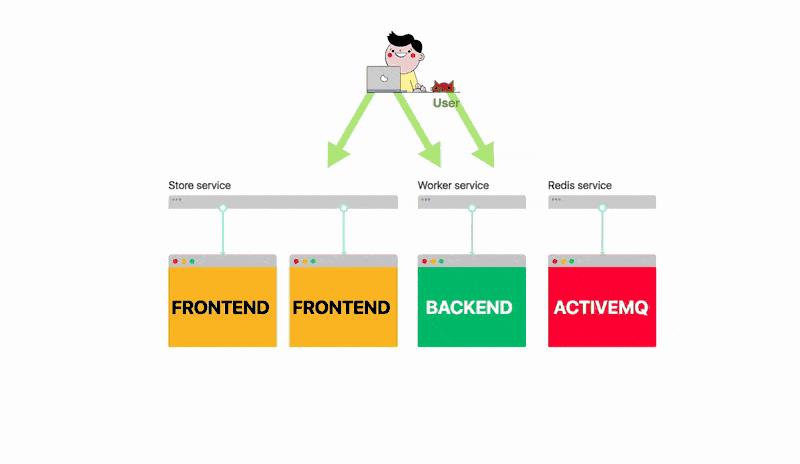
你的应用程序有三个组件:
呈现前端的Spring Boot应用程序
ActiveMQ作为消息代理
处理事务的Spring Boot后端
你应该分别部署这三个组件。
对于每个组件你都应该创建:
Deployment对象,描述部署的容器及其配置
一个Service对象,充当Deployment部署创建的应用程序的所有实例的负载均衡器
部署中的每个应用程序实例都称为Pod。
部署ActiveMQ
让我们从ActiveMQ开始吧。
你应该创建一个activemq-deployment.yaml文件,其中包含以下内容:
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: queue
spec:
replicas: 1
template:
metadata:
labels:
app: queue
spec:
containers:
- name: web
image: webcenter/activemq:5.14.3
imagePullPolicy: IfNotPresent
ports:
- containerPort: 61616
resources:
limits:
memory: 512Mi
该模板冗长但直接易读:
你从名为webcenter / activemq的官方仓库中请求了一个activemq容器
容器在端口61616上公开消息代理
为容器分配了512MB的内存
你要求提供单个副本 - 你的应用程序的单个实例
使用以下内容创建activemq-service.yaml文件:
apiVersion: v1
kind: Service
metadata:
name: queue
spec:
ports:
- port: 61616
targetPort: 61616
selector:
app: queue
幸运的是,这个模板更短!
这个yaml表示:
你创建了一个公开端口61616的负载均衡器
传入流量分发到所有具有app:queue类型标签的Pod(请参阅上面的部署)
targetPort是Pod暴露的端口
你可以使用以下命令创建资源:
kubectl create -f activemq-deployment.yaml
kubectl create -f activemq-service.yaml
你可以使用以下命令验证数据库的一个实例是否正在运行:
kubectl get pods -l=app=queue
部署前端
使用以下内容创建fe-deployment.yaml文件:
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: frontend
spec:
replicas: 1
template:
metadata:
labels:
app: frontend
spec:
containers:
- name: frontend
image: spring-boot-hpa
imagePullPolicy: IfNotPresent
env:
- name: ACTIVEMQ_BROKER_URL
value: "tcp://queue:61616"
- name: STORE_ENABLED
value: "true"
- name: WORKER_ENABLED
value: "false"
ports:
- containerPort: 8080
livenessProbe:
initialDelaySeconds: 5
periodSeconds: 5
httpGet:
path: /health
port: 8080
resources:
limits:
memory: 512Mi
Deployment看起来很像前一个。
但是有一些新的字段:
有一个section可以注入环境变量
还有Liveness探针,可以告诉你应用程序何时可以接受流量
使用以下内容创建fe-service.yaml文件:
apiVersion: v1
kind: Service
metadata:
name: frontend
spec:
ports:
- nodePort: 32000
port: 80
targetPort: 8080
selector:
app: frontend
type: NodePort
kubectl create -f fe-deployment.yaml
kubectl create -f fe-service.yaml
你可以使用以下命令验证前端应用程序的一个实例是否正在运行:
kubectl get pods -l=app=frontend
部署后端
使用以下内容创建backend-deployment.yaml文件:
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: backend
spec:
replicas: 1
template:
metadata:
labels:
app: backend
annotations:
prometheus.io/scrape: 'true'
spec:
containers:
- name: backend
image: spring-boot-hpa
imagePullPolicy: IfNotPresent
env:
- name: ACTIVEMQ_BROKER_URL
value: "tcp://queue:61616"
- name: STORE_ENABLED
value: "false"
- name: WORKER_ENABLED
value: "true"
ports:
- containerPort: 8080
livenessProbe:
initialDelaySeconds: 5
periodSeconds: 5
httpGet:
path: /health
port: 8080
resources:
limits:
memory: 512Mi
使用以下内容创建backend-service.yaml文件:
apiVersion: v1
kind: Service
metadata:
name: backend
spec:
ports:
- nodePort: 31000
port: 80
targetPort: 8080
selector:
app: backend
type: NodePort
你可以使用以下命令创建资源:
kubectl create -f backend-deployment.yaml
kubectl create -f backend-service.yaml
你可以验证后端的一个实例是否正在运行:
kubectl get pods -l=app=backend
部署完成。
它真的有效吗?
你可以使用以下命令在浏览器中访问该应用程序:
minikube service backend
minikube service frontend
如果它有效,你应该尝试购买一些物品!
工作者在处理交易吗?
是的,如果有足够的时间,工作人员将处理所有待处理的消息。
恭喜!
你刚刚将应用程序部署到Kubernetes!
手动扩展以满足不断增长的需求
单个工作程序可能无法处理大量消息。实际上,它当时只能处理一条消息。
如果你决定购买数千件物品,则需要数小时才能清除队列。
此时你有两个选择:
你可以手动放大和缩小
你可以创建自动缩放规则以自动向上或向下扩展
让我们先从基础知识开始。
你可以使用以下方法将后端扩展为三个实例:
kubectl scale --replicas=5 deployment/backend
你可以验证Kubernetes是否创建了另外五个实例:
kubectl get pods
并且应用程序可以处理五倍以上的消息。
一旦工人排空队列,你可以缩小:
kubectl scale --replicas=1 deployment/backend
如果你知道最多的流量何时达到你的服务,手动扩大和缩小都很棒。
如果不这样做,设置自动缩放器允许应用程序自动缩放而无需手动干预。
你只需要定义一些规则。
公开应用程序指标
Kubernetes如何知道何时扩展你的申请?
很简单,你必须告诉它。
自动调节器通过监控指标来工作。只有这样,它才能增加或减少应用程序的实例。
因此,你可以将队列长度公开为度量标准,并要求autoscaler观察该值。队列中的待处理消息越多,Kubernetes将创建的应用程序实例就越多。
那么你如何公开这些指标呢?
应用程序具有/metrics端点以显示队列中的消息数。如果你尝试访问该页面,你会注意到以下内容:
# HELP messages Number of messages in the queue
# TYPE messages gauge
messages 0
应用程序不会将指标公开为JSON格式。格式为纯文本,是公开Prometheus指标的标准。不要担心记忆格式。大多数情况下,你将使用其中一个Prometheus客户端库。
在Kubernetes中使用应用程序指标
你几乎已准备好进行自动缩放——但你应首先安装度量服务器。实际上,默认情况下,Kubernetes不会从你的应用程序中提取指标。如果你愿意,可以启用Custom Metrics API。
要安装Custom Metrics API,你还需要Prometheus - 时间序列数据库。安装Custom Metrics API所需的所有文件都可以方便地打包在learnk8s / spring-boot-k8s-hpa中[1]。
你应下载该存储库的内容,并将当前目录更改为该项目的monitoring文件夹。
cd spring-boot-k8s-hpa/monitoring
从那里,你可以创建自定义指标API:
kubectl create -f ./metrics-server
kubectl create -f ./namespaces.yaml
kubectl create -f ./prometheus
kubectl create -f ./custom-metrics-api
你应该等到以下命令返回自定义指标列表:
kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1" | jq .
任务完成!
你已准备好使用指标。
实际上,你应该已经找到了队列中消息数量的自定义指标:
kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1/namespaces/default/pods/*/messages" | jq .
恭喜,你有一个公开指标的应用程序和使用它们的指标服务器。
你最终可以启用自动缩放器!
在Kubernetes中进行自动扩展部署
Kubernetes有一个名为Horizontal Pod Autoscaler的对象,用于监视部署并上下调整Pod的数量。
你将需要其中一个来自动扩展实例。
你应该创建一个包含以下内容的hpa.yaml文件:
apiVersion: autoscaling/v2beta1
kind: HorizontalPodAutoscaler
metadata:
name: spring-boot-hpa
spec:
scaleTargetRef:
apiVersion: extensions/v1beta1
kind: Deployment
name: backend
minReplicas: 1
maxReplicas: 10
metrics:
- type: Pods
pods:
metricName: messages
targetAverageValue: 10
这个文件很神秘,所以让我为你翻译一下:
Kubernetes监视scaleTargetRef中指定的部署。在这种情况下,它是工人。
你正在使用messages指标来扩展你的Pod。当队列中有超过十条消息时,Kubernetes将触发自动扩展。
至少,部署应该有两个Pod。10个Pod是上限。
你可以使用以下命令创建资源:
kubectl create -f hpa.yaml
提交自动缩放器后,你应该注意到后端的副本数量是两个。这是有道理的,因为你要求自动缩放器始终至少运行两个副本。
你可以检查触发自动缩放器的条件以及由此产生的事件:
kubectl describe hpa
自动定标器表示它能够将Pod扩展到2,并且它已准备好监视部署。
令人兴奋的东西,但它有效吗?
负载测试
只有一种方法可以知道它是否有效:在队列中创建大量消息。
转到前端应用程序并开始添加大量消息。在添加消息时,使用以下方法监视Horizontal Pod Autoscaler的状态:
kubectl describe hpa
Pod的数量从2上升到4,然后是8,最后是10。
该应用程序随消息数量而变化!欢呼!
你刚刚部署了一个完全可伸缩的应用程序,可根据队列中的待处理消息数进行扩展。
另外,缩放算法如下:
MAX(CURRENT_REPLICAS_LENGTH * 2, 4)
在解释算法时,文档没有多大帮助。你可以在代码中找到详细信息。此外,每分钟都会重新评估每个放大,而每两分钟缩小一次。
以上所有都是可以调整的设置。
但是你还没有完成。
什么比自动缩放实例更好?
自动缩放集群
跨节点缩放Pod非常有效。但是,如果集群中没有足够的容量来扩展Pod,该怎么办?
如果达到峰值容量,Kubernetes将使Pod处于暂挂状态并等待更多资源可用。
如果你可以使用类似于Horizontal Pod Autoscaler的自动缩放器,但对于节点则会很棒。
好消息!
你可以拥有一个集群自动缩放器,可以在你需要更多资源时为Kubernetes群集添加更多节点。
集群自动缩放器具有不同的形状和大小。它也是特定于云提供商的。
请注意,你将无法使用minikube测试自动缩放器,因为它根据定义是单节点。
你可以在GitHub[6]上找到有关集群自动调节器和云提供程序实现的更多信息。
概 览
设计大规模应用程序需要仔细规划和测试。
基于队列的体系结构是一种出色的设计模式,可以解耦你的微服务并确保它们可以独立扩展和部署。
虽然你可以用脚本来扩展你的应用,但可以更轻松地利用容器编排器(如Kubernetes)自动部署和扩展应用程序。
相关链接:
https://github.com/learnk8s/spring-boot-k8s-hpa
https://github.com/learnk8s/spring-boot-k8s-hpa/blob/master/src/main/java/com/learnk8s/app/queue/QueueService.java
https://kubernetes.io/docs/tasks/tools/
https://learnk8s.io/blog/installing-docker-and-kubernetes-on-windows
https://docs.docker.com/install/
https://github.com/kubernetes/autoscaler/tree/master/cluster-autoscaler#deployment
原文链接:
https://medium.freecodecamp.org/how-to-scale-microservices-with-message-queues-spring-boot-and-kubernetes-f691b7ba3acf
译者:池剑锋
本文转载自:
推荐阅读
5月8日 晚20:30,Kubernetes Master Class系列在线培训的第五期课程来啦!备受期待的日志、监控与告警内容,一应俱全!戳下图即可查看课程详情!
点击【阅读原文】,也可即刻报名!
About Rancher Labs
Rancher Labs由硅谷云计算泰斗、CloudStack之父梁胜创建,致力于打造创新的开源软件,帮助企业在生产环境中运行容器与Kubernetes。旗舰产品Rancher是一个开源的企业级Kubernetes平台,是业界首个且唯一可以管理所有云上、所有发行版、所有Kubernetes集群的平台。解决了生产环境中企业用户可能面临的基础设施不同的困境,改善Kubernetes原生UI易用性不佳以及学习曲线陡峭的问题,是企业落地Kubernetes的不二之选。
Rancher在全球拥有超过一亿的下载量,超过20000家企业客户。全球知名企业如中国人寿、华为、中国平安、民生银行、兴业银行、上汽集团、海尔、米其林、天合光能、丰田、本田、霍尼韦尔、金风科技、普华永道、海南航空、厦门航空、恒大人寿、中国太平、巴黎银行、美国银行、HSCIS恒生指数、中国水利、暴雪、CCTV等均是Rancher的付费客户。
第五期 Kubernetes Master Class 传送门
以上是关于实例演示:如何构建高可用的微服务架构的主要内容,如果未能解决你的问题,请参考以下文章