在微服务架构中做机器学习,真的太难了
Posted AI前线
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了在微服务架构中做机器学习,真的太难了相关的知识,希望对你有一定的参考价值。
本文最初发布于 StreamSQL 博客,经原作者授权由 InfoQ 中文站翻译并分享。
我曾在很多团队中参与构建过由深度学习驱动的项目,从个性化定制到推荐付费,可以说无所不包。在这个过程中,我需要花费大量时间开会,然后寻找数据,构建 ETL 来获取和清理数据。我遇到最糟糕的情况就是被迫处理面向微服务的架构。 我不是呼吁大家停止使用微服务,但如果想在一个严格的微服务架构中推动机器学习项目,很大程度要失败。
本文,我将介绍为什么面向微服务的架构和机器学习不对付。然后,我将介绍诸如 Airbnb 和 Uber 这样的公司所采用的解决方案。
微服务已成为技术公司事实上的架构选择。微服务能让大型公司的众多团队构建小型、独立的组件。团队无需堆砌庞大的单体架构就可以解决问题并满足需求,让团队可以快速前进。但是,如果微服务用过了头,比如将一个用户会话 Token 转换为用户配置文件这么简单的操作,就可能会触发足足二十个网络调用。
我最近在 Twitter 上看到了一段视频,给了我一些启发。这段视频很有趣,并且完美解释了这个概念(下文是视频中的对话文本):
产品经理:为什么在个人资料页面显示生日日期如此困难?
工程师:首先,我们必须调用 Bingo 服务以获取 UserID,然后调用 Papaya 将其转换为一个用户会话 Token。我们使用 LMNOP 进行验证,然后才可以从 Racoon 提取用户信息。但是 Racoon 不能保证信息里有 [生日],所以接下来我们调用...
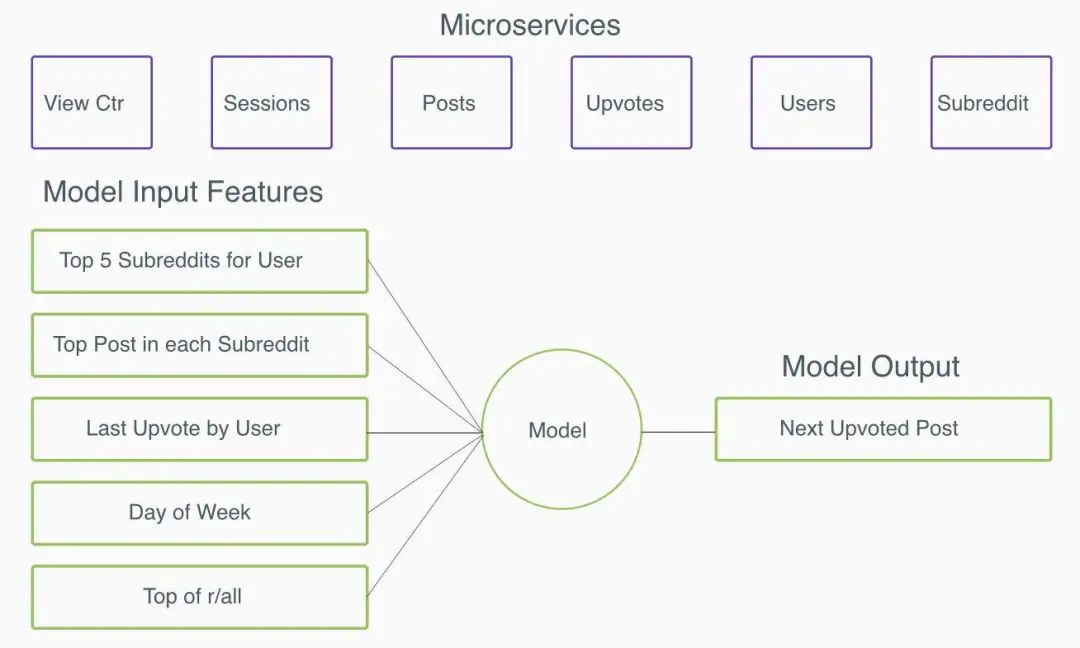
在诸如用户行为之类的复杂数据源上构建机器学习模型时,使用微服务会尤其让人头疼。在这些场景中,做一个预测,需要从大量微服务中获取信息,这些微服务又会从其他众多服务中获取它们所需的所有上下文信息。 例如,如果要为用户构建一个个性化的 Reddit Feed,可能需要了解这位用户所属的所有社区,这些社区中的热门帖子,用户点击并喜欢的所有帖子以及更多详细信息。添加额外的输入还会为模型提供更多信号。例如,某些用户在周末与工作日可能会有截然不同的行为。为模型提供额外的输入(比如说一周具体哪一天)后,就能够了解这些趋势。
机器学习模型的每个逻辑输入都称为一项特征。假设、构建和测试模型输入的过程称为特征工程。 通常,对于机器学习团队而言,特征工程是最耗时的任务之一。创造性地提出很多新特征只是这个过程的一部分;大部分时间都花在了寻找所需数据,学习其特殊性和边缘情况,以及建立数据管道来清洗数据,并将其转换成可用形式等操作上。
在基于微服务的架构中,收集特定数据的唯一方法是通过 API 调用。单个模型可能需要很多 API 调用的特征。例如,模型可能需要查询用户所属社区的服务,然后需要查询每个社区中的热门帖子,然后查询每个帖子获得的点赞数(以 Reddit 为例)。由于几乎从来没有人为这种用途构建对应的系统,因此它将在下游推倒网络调用的一连串多米诺骨牌。
与 Web 前端不同,机器学习模型在缺少特征时欠缺灵活性。它必须等待所有请求完成,否则就可能会带来很多垃圾结果。 模型本身在计算上繁琐且缓慢,在此基础上跟微服务混在一起就不可能提供实时推荐。
机器学习模型的工作机制是模仿自己观察到的东西。为此,模型需要一个观察结果的数据集,以及在观察时的输入来进行训练。在基于微服务架构中生成训练集的过程太难受了。以 Reddit 为例,我们需要一组用户点赞的数据集,以及他们点击赞同时的特征集。
从技术上讲,我们可以通过抓取用户和帖子的微服务来获得用户点赞信息和所有的帖子数据(虽然这远算不上理想方案)。但是,对时点的正确性要求意味着很多情况下这个问题都是无法解决的。要进行训练,我们需要知道某个帖子在 subreddit 中某个时点的排名。但是,subreddit 微服务不太可能支持追溯查询。
一种选择是打破封装并从数据库转储读取数据,从而完全避免微服务。现在,我们可以绕过那些 API,并将数据集直接插入 Apache Spark 或其他批处理系统。我们可以将表连接起来,并更方便地处理数据。这样,我们也就能在 Spark 获取数据的同时同步生成训练数据集。虽然在一开始好像应该使用一个数据湖,但它会导致机器学习服务依赖原始数据的架构,这种模式肯定会随着时间而改变,许多微服务会被淘汰并替换。数据不一致、错误和问题会不断堆积起来。最后,每个机器学习团队都必须维护已经混乱的代码和数据,挣扎着尝试挽救局面。这些管道非常容易变化,并且会占用大量时间和资源。

另一种选择是利用诸如 Apache Kafka、Apache Pulsar 或 Segment 之类的事件流平台,从而让机器学习团队订阅他们所需的事件流。数据湖的许多缺陷也适用于事件流,但与数据湖转储不一样的是,事件流往往具有质量更高的数据。由于事件流通常会为关键任务服务提供动力,因此团队必须遵守更高的数据质量和文档编制标准。相比之下,数据湖是机器学习和分析团队自己所有的,并不符合那么高的标准。
事件流处理存在冷启动问题。事件流平台很少配置为可以很长时间保留事件,一般来说保存时间只有一个星期。如果想生成一个新特征,则在生成训练集时可能只有最后一周的数据可用。创建新的有状态特征时,冷启动问题会更加明显。有状态特征要求汇总一定时间范围内的所有事件,例如用户上周发布的帖子总数。在这些情况下甚至可能要花费几周时间才能开始生成训练数据集。
特征工程是一个反复的过程。生成一个假设,建立一个实验,然后运行一个测试。你可以将其合并到主要模型中,或将其废弃。迭代越快,模型也改进得越快。如果一次测试需要花费数周时间,那么机器学习团队就会失去完成工作的能力,团队最后会浪费很多数据管道。为了获取数据还要玩弄手段,结果根本没时间去构建更好的模型。
微服务问题既不是什么新问题,也不是什么罕见的疑难杂症。有趣的是,许多公司都各自独立发展出了相同的解决方案。Airbnb 构建了 Zipline,Uber 建立了 Michelangelo,Lyft 发展出了 Dryft,这些系统统称为特征存储。
在原始的“Reddit”微服务架构中,每个服务都拥有自己的数据。帖子微服务是关于帖子数据的真实来源,用户微服务是关于用户数据的真实来源,依此类推。特征存储尝试在自己内部的数据结构中创建这些数据的视图。它通过将域事件流处理为物化状态来实现这一点。域事件是逻辑事件,例如用户对文章点赞或创建新帖子时生成的事件。物化视图是对事件流运行查询的结果集。因此,如果我们希望模型知道用户点赞的帖子数,则可以使用以下逻辑创建一个物化视图:
SELECT user, COUNT(DISTINCT item) FROM upvote_stream GROUP BY user;
所有物化视图都存在于同一特征存储中,并且已为机器学习应用做了预处理。我们已经将我们关心的所有微服务数据合并到了一个单体的数据存储中。这样就解决了从微服务获取实时特征相关的问题。现在,特征只需一次往返就能获取。由于物化视图存储在一个高可用且最终一致的数据存储中,因此特征存储还额外有着抗灾的好处。由于我们自己处理原始事件,因此我们在创建特征时可以控制自己的业务逻辑,这样我们就能松散地耦合到每个微服务中的业务逻辑上。
我们的特征与传入事件保持一致。它本质上是微服务表的一个镜像,但是已针对机器学习的用途做过了预处理,并且全部都放在了一个地方。与微服务不同,特征存储将每个传入事件无限期地保存到日志中。如果我们将日志中的每个事件重播到一个空白的特征存储中,那么最终将获得完全相同的物化状态。事件日志成为系统的真实来源。这种设计模式称为事件溯源(Event Sourcing)。
通过事件溯源,我们可以为模型生成训练数据集。为了说明应该如何完成此操作,我们以 Reddit 示例为例,在这个示例中我们要预测用户将点赞的下一篇文章。相关的域事件将流式传输到特征存储中,该存储将更新模型输入特征。观察到的结果也应流式传输到特征存储,在这个示例中是用户的每一次点赞。
feature_store.append_observation(userId, postId, now())
由于特征存储会维护每个事件的日志,以及将事件流转换为有状态的逻辑,因此它可以在任何时间点获取特征状态。要生成一个训练集时,它将遍历观察结果并在该点生成特征集。将两者结合起来后,我们最终就能得到一个训练数据集。
def generate_training_set():
for observed in observations:
feature_store.process_events_until(observed.time)
features = feature_store.get_features(observed.userId)
yield (features, observed.postId)
特征存储使我们能够与微服务架构解耦,并控制我们自己的特征。但是,构建和维护特征存储并非是免费的,团队在部署特征存储基础架构之前应考虑以下几点。
特征存储要求域事件通过事件流平台(例如 Kafka 或 Pulsar)传递。这样,特征存储就能独立于微服务实现其状态。保留事件日志可以使其在任何时间点实现特征。
从一个大型的基于微服务的系统转为使用事件流是一个巨大转变,必须注入常规程序以捕获重要事件。这可能需要使用新的依赖项和新的条件来更新旧的关键微服务。另一个选择是使用每个数据库中的 Change-Data-Capture 语义将更新转换为流。但这样一来,特征存储就容易受到微服务数据库内部架构更改的影响。
特征库仍然依赖于事件流的架构。如果流更改其架构,或者微服务行为不当并上载垃圾数据,则它可能会使下游的特征存储失去能力。事件流模式应与数据库模式一样被认真对待,迁移程序应该内容明确并经过测试,事件应使用 Protobuf 或 JSON 等可扩展格式编写。
处理和存储大量数据不是免费的。在许多情况下,特征存储将重复各个微服务执行的计算。一个特征存储是以基础架构成本和复杂性为代价,为开发人员带来速度和易用性。建立和维护特征库需要资金投入和专业的工程师。
机器学习特征通常适用于许多不同的用例。Reddit 可能具有许多各不相同的特征,这些特征全都通过用户活动做出决策。发现和理解他人构建的特征可以加快开发速度,并为特征工程提供灵感。由于特征存储是一个相对较新的架构,因此团队必须为如何发布和共享特征编写对应的文档。
合适的特征存储使机器学习团队专注于构建模型,而不是数据管道。团队可以在 SQL 中创建单个特征定义,以备训练和服务使用,有状态特征会自动回填以消除等待时间。
原文链接:https://streamsql.io/blog/microservices-with-machine-learning-feature-store
拥有吃喝玩乐全场景丰富数据的美团点评,利用跨场景数据挖掘、映射、聚合与关联构建了一个庞大的生活服务知识图谱——“美团大脑”,这个知识图谱可以促进每个场景下应用服务的智能升级。点击「阅读原文」来AICon上海2020了解新零售场景下的知识图谱如何构建与落地。大会限时8折购票中,欢迎咨询票务小姐姐:18514549229(微信同号)。
今日荐文
台积电拿下苹果5nm全部订单;滴滴开搞自动驾驶;美国贸易管制黑名单再次新增| AI一周资讯
你也「在看」吗? 以上是关于在微服务架构中做机器学习,真的太难了的主要内容,如果未能解决你的问题,请参考以下文章