想要落地微服务架构,这些设计的陷阱你了解吗
Posted 架构摆渡人
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了想要落地微服务架构,这些设计的陷阱你了解吗相关的知识,希望对你有一定的参考价值。
O’Reilly的电子书《Microservices AntiPatterns and Pitfalls》讲述了在微服务设计实现时十种最常见的反模式和陷阱。本文基于此书,将这十个点列出。

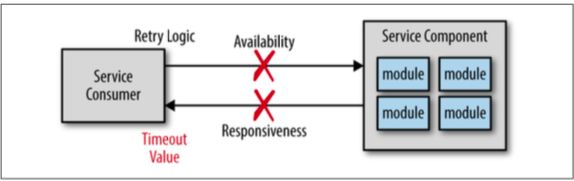
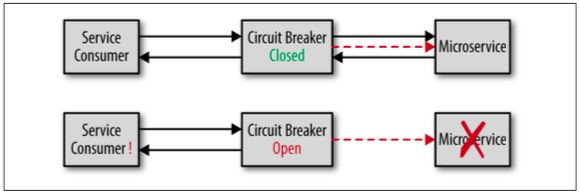
可用性:服务消费方能够连接服务方,并可以向其发送请求。
响应性:服务方能够在消费方期望时间内给予请求响应。
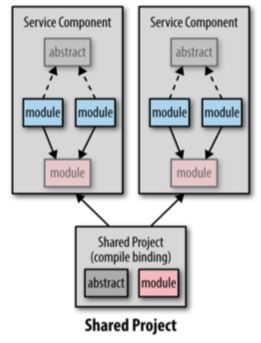
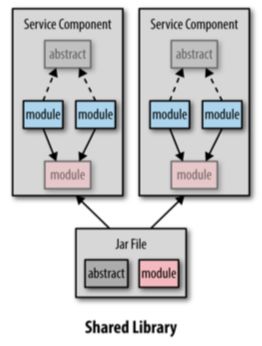
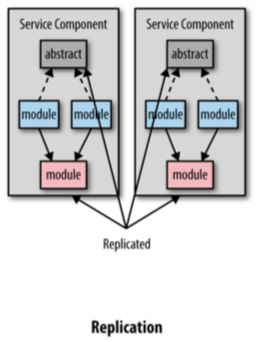
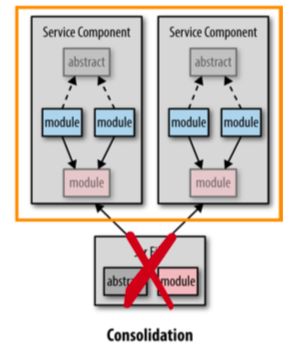
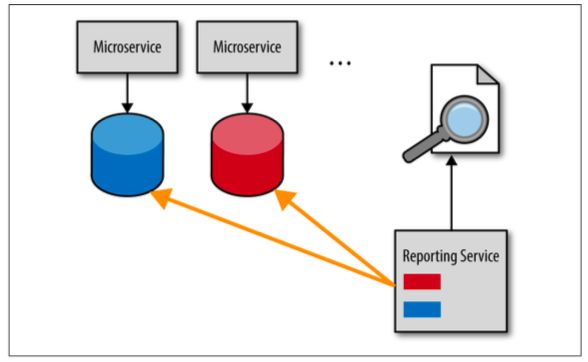
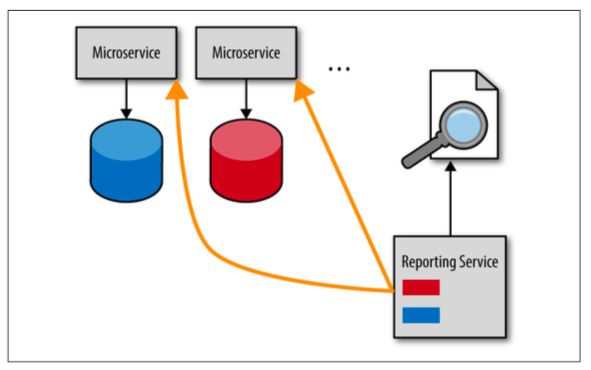
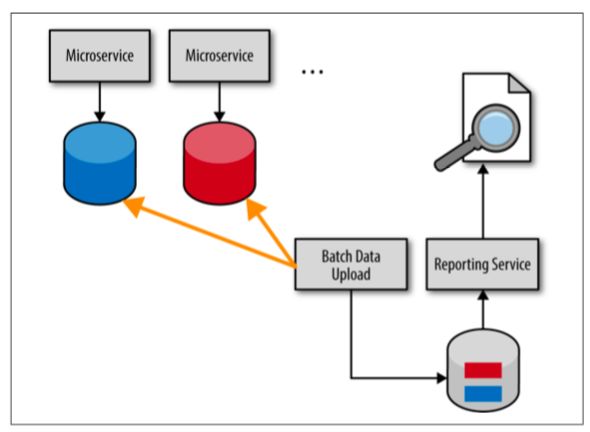
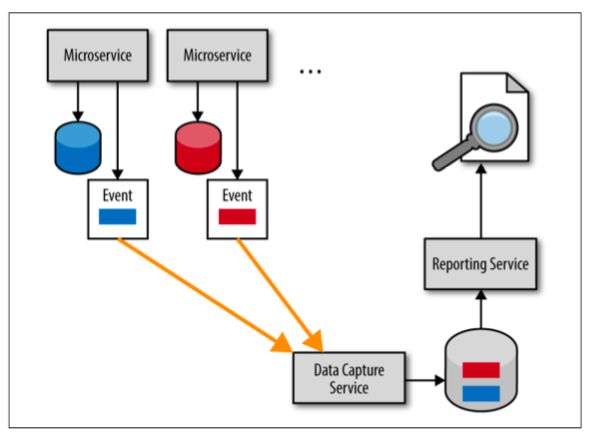
添加顾客
更新顾客信息
获取顾客信息
通知顾客
记录顾客评论
获取顾客评论
为什么要使用微服务?
最重要的业务驱动是什么?
架构中的哪一点是最为重要的?
易部署:容易部署是微服务的一个很大的优点。毕竟相比起一个庞大的单体应用,一个小并且职责单一的微服务的部署非常简单并且带来的风险也会小很多。而持续部署技术则进一步放大了这个优点。
易测试:职责单一、共享依赖少使得测试一个微服务是很容易的。而基于微服务做回归测试与单体大应用相比也是很容易的。 控制变更:每个服务的范围和边界上下文使得很容易控制服务的功能变动。
模块化:微服务就是一个高度模块化的架构风格。这种风格也是一种敏捷方式的表达,能够很快的响应变化。一个系统模块化程度越高,就越容易测试、部署和发布变更。一个服务粒度划分合理的微服务系统是所有架构中模块化程度最高的架构形式。
可扩展性:由于每一个服务都是一个职责单一的细粒度服务,因此此种架构风格是所有架构分隔中可扩展性最高的。其非常容易扩展某一个或者某几个功能从而满足整体系统的需求。而得益于服务的容器化特性以及各种运维监控工具,服务也能够自动化进行启动和关闭。
组织变动:微服务需要组织在很多层面进行变动。研发团队需要包含UI、后端开发、规则处理、数据库处理建模等多种职位,从而使得一个小的团队能够具有实现微服务的所有技术栈。同时,传统的单体、分层应用架构的软件发布流程也需要更新为自动化、高效的部署流水线。
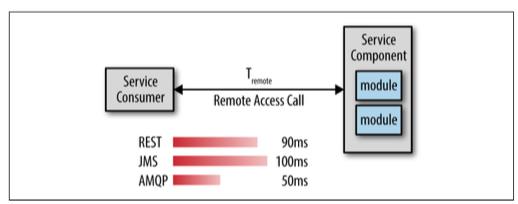
性能:由于服务都是隔离的,因此发起对服务的远程调用肯定是会影响性能的。服务编排、运行环境都是影响性能的很大因素。了解远程调用的延迟、需要与多少服务通信都是与性能相关的需要掌握的信息。
可靠性:和性能一样。服务的远程调用越多,那么失败的几率就越高,总体的可靠性就会越低。
DevOps:随着微服务架构而来的是成千上百的服务。手动管理这么多的服务是很不现实的。这就对于自动化运维部署、协作提出了很高的挑战。需要依赖非常多的操作工具和实践,是一个非常复杂的工作。目前差不多有12种类型的操作工具(监控工具、服务注册、发现工具、部署工具等)和框架在微服务架构中被使用,其中每一种又包含了很多具体的工具和产品供选择。对于这些工具和框架的选择一般都会需要将近数月的研究、测试、权衡分析才能做出最适合的技术选型。
业务和技术的目标是什么?
使用微服务是为了完成什么?
目前和可预知的痛点是什么?
应用的最关键的技术特性是什么?(性能、易部署性、易测试性、可扩展性)
基于服务的架构(Service-Based)
面向服务的架构(Service-Oriented)
分层架构(Layered)
微内核架构(Microkernel)
基于空间的架构(Space-Based)
事件驱动架构(Event-Driven)
流水线架构(Pipeline)
POST /trade/buy
Accept: application/vnd.svc.trade.v2+json
String msg = createJSON("acct","12345","sedol","2046251","shares","1000");
jsmContext.createProducer()
.setProperty("version",2)
.send(queue,msg);
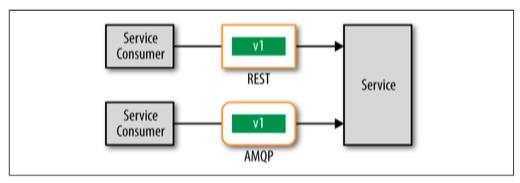
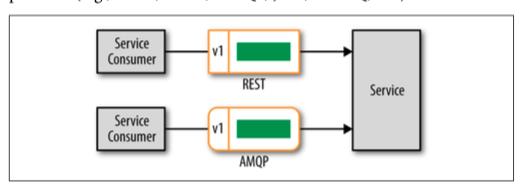
因此对于服务消费者需要合并多个远程请求到一个事务中的场景可以选择事务消息。
往期推荐
以上是关于想要落地微服务架构,这些设计的陷阱你了解吗的主要内容,如果未能解决你的问题,请参考以下文章