微服务架构模式: 大魏再学微服务系列1
Posted 大魏分享
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了微服务架构模式: 大魏再学微服务系列1相关的知识,希望对你有一定的参考价值。
比较同步和异步进程间通信
微服务通常是单独部署的,但是大多数企业级微服务体系结构要求这些服务以及其他外部服务相互交互。使用进程间通信(IPC)机制来实现此通信。根据应用程序的需求,微服务之间的通信可以是同步的也可以是异步的。
同步通讯
同步通信基于请求和响应模型。在此模型中,客户端等待服务的及时响应。一个基本的示例是通过HTTP与REST服务进行通信。
好处
易于编程和测试。
提供更好的实时响应。
防火墙友好,因为它使用标准端口。
无需中间代理或其他集成软件。
缺点
仅支持请求和响应样式的交互。
要求客户和服务在整个交换期间都可用。
强制客户端知道服务的URL(位置)或使用服务发现机制来定位服务实例。
基于异步消息的通信
微服务可以使用基于异步消息的通信(例如AMQP或MQTT协议)进行通信。微服务可以使用其他基于消息的模式,例如点对点、发布和订阅、请求和答复或请求和通知。异步通信是非阻塞的,因此客户端可以继续发出请求,而无需等待接收响应。
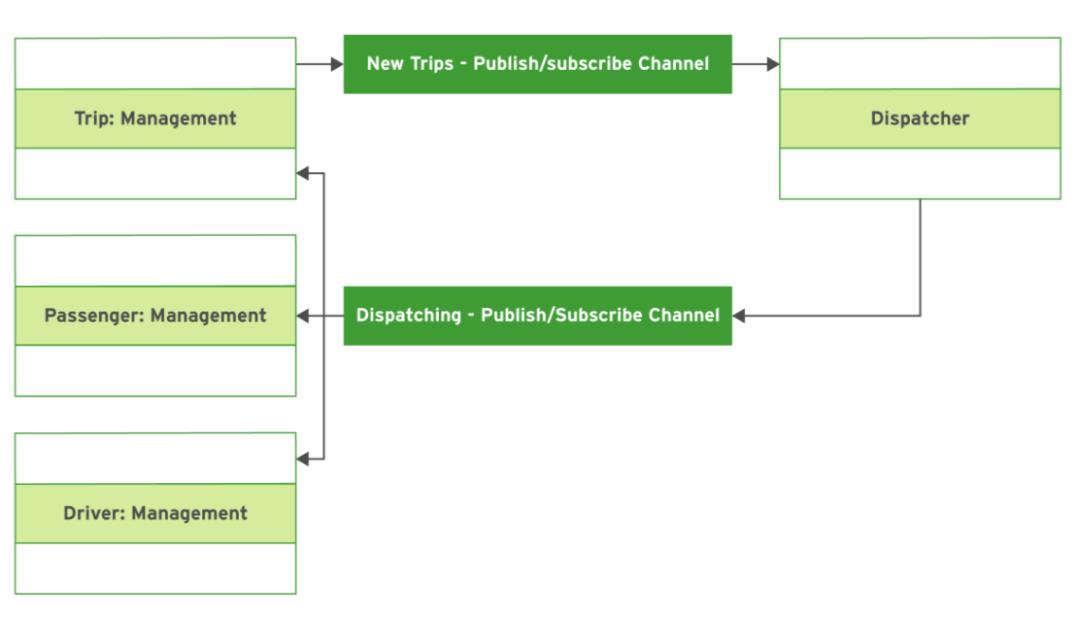
在上图中,行程管理、旅客管理和驾驶员管理这三种服务使用单个发布-订阅channel,从调度员接收消息。行程管理服务使用另一个发布-订阅channel将消息发送到调度程序。在此示例中,当提交新行程时,调度程序服务不会直接回复行程管理服务。而是,调度程序服务使用其他渠道来答复行程管理服务,并通知乘客和驾驶员管理服务。这种异步方法允许行程管理服务继续处理用户对更多新行程的请求,而无需等待调度程序的处理和后续响应。
好处
使客户端与服务脱钩:客户端不知道服务实例。无需发现机制。
实现消息缓冲:使用者慢或不可用时,消息代理将消息在消息缓冲区中排队。
支持灵活的客户端与服务交互:客户端与服务之间的通信非常灵活。客户端不必可用于接收消息。消息支持各种样式,以确保消息传递。
缺点
增加操作复杂性:消息组件还有其他配置。消息代理组件必须高度可用以确保系统可靠性。
难以实现基于请求和响应的交互:每个请求消息必须包含一个答复通道和一个关联标识符。该服务将响应和相关标识符写入回复通道。客户端使用该相关标识符来标识消息。
描述服务发现
在传统的分布式系统部署中,服务必须使用HTTP / REST或远程过程调用(RPC)机制相互调用,并且服务必须在已知的固定位置(主机和端口)上运行。
基于微服务的应用程序通常在虚拟化或容器化的云环境中运行。网络位置是动态分配给服务实例的,并且会因故障,自动扩展和升级而发生更改。微服务的客户端必须能够通过动态更改网络位置来发现这些服务实例,以进行API调用。这些频繁的更改使服务发现具有挑战性。
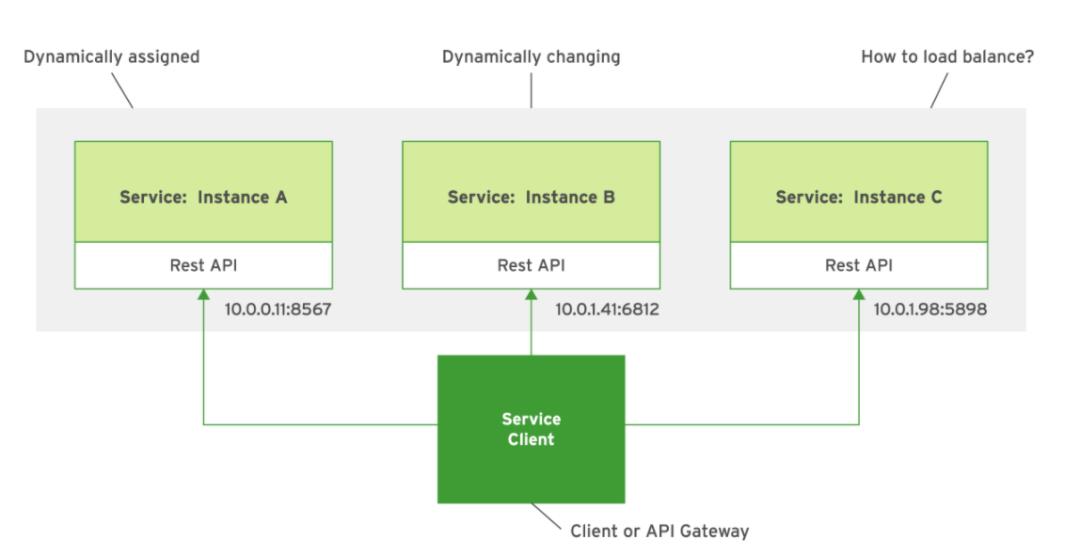
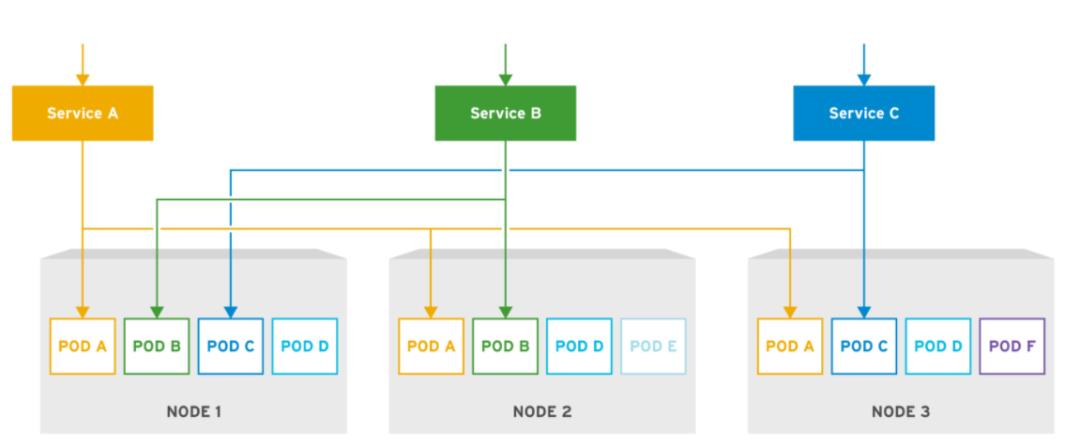
客户服务需要一种完善的机制来成功发现服务。有两种主要的服务发现模式:客户端发现和服务器端发现。
查看客户端服务发现模式
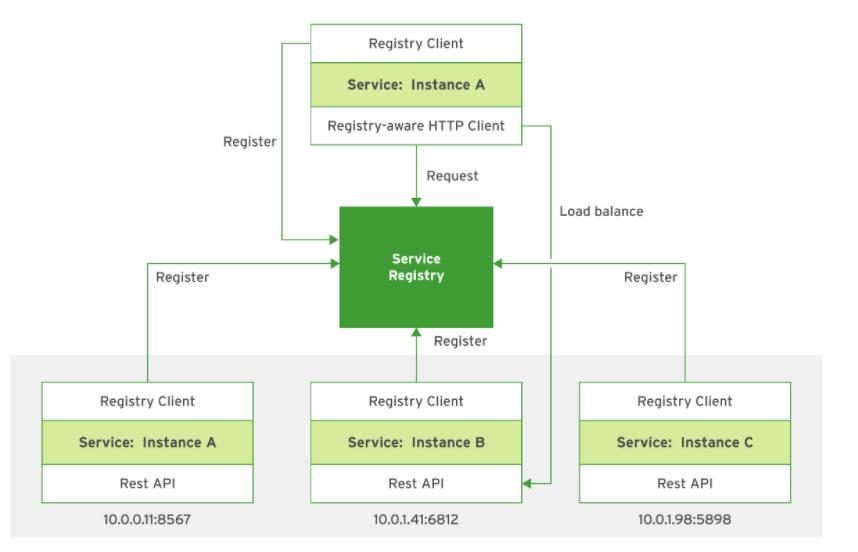
使用客户端服务发现模式时,客户端会在服务注册表数据库中查询可用的服务实例。然后,客户端使用负载平衡算法来选择可用的服务实例之一。客户端选择了服务后,便会向该服务发出请求。服务启动时,它将在服务注册表中注册其位置。服务实例终止时,其服务注册将从服务注册表中删除。服务注册表通过心跳机制定期更新。
查看服务器端服务发现模式
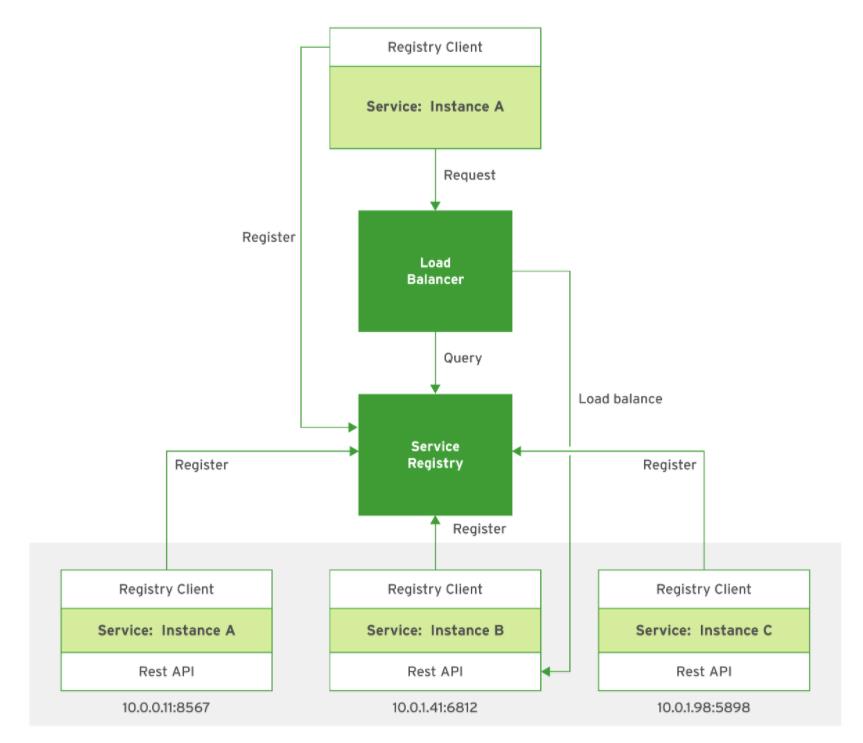
使用服务器端服务发现模式时,客户端通过负载平衡器向服务发出请求。负载平衡器查询注册表,然后将每个请求路由到可用的服务实例。与客户端服务发现类似,服务仍必须在注册表中注册自己。注册表负责监视已注册服务的运行状况和就绪状态,并删除所有不可用的服务。
查看Kubernetes和OpenShift中的服务发现
REDIS_MASTER_SERVICE_HOST=10.0.0.11
REDIS_MASTER_SERVICE_PORT=6379
REDIS_MASTER_PORT=tcp://10.0.0.11:6379
REDIS_MASTER_PORT_6379_TCP=tcp://10.0.0.11:6379
REDIS_MASTER_PORT_6379_TCP_PROTO=tcp
REDIS_MASTER_PORT_6379_TCP_PORT=6379
REDIS_MASTER_PORT_6379_TCP_ADDR=10.0.0.11
集群级DNS内置在Kubernetes中。群集DNS指向Service IP。Service IP是在创建服务对象时分配给服务的虚拟IP。服务IP是固定IP,因此DNS缓存没有问题。
内部DNS服务器为每个服务创建一组DNS记录。DNS服务器使用的命名系统是层次结构和逻辑树,其中服务条目的父级以服务的命名空间(在OpenShift Container Platform中也称为项目)命名。在同一个名称空间中,服务使用其名称进行解析。其他名称空间中的Pod可以通过将名称空间添加到DNS路径来访问服务,如以下示例所示:
my-service.my-namespace.svc.cluster.localKubernetes / OCP服务类型
服务资源中的Kubernetes类型条目指定服务的类型。Kubernetes定义以下ServiceType:
ClusterIP
NodePort
LoadBalancer
ExternalName
描述API网关模式
解决开发微服务时服务发现问题的另一种方法是使用API网关模式。基于微服务的应用程序的客户面临许多挑战,包括:
微服务提供了细粒度的API。基于微服务的应用程序的客户端用于与不同的服务进行交互。
不同的客户端需要不同的数据。例如,产品详细信息页面的桌面浏览器版本通常比移动版本更为复杂。
对于不同类型的客户端,网络性能是不同的。例如,移动和LAN客户端通常要经受不同的网络性能。
服务实例的数量及其位置(主机名和端口号)是动态变化的。
将上下文划分为服务可能会随时间而变化,应该对客户端隐藏。
服务使用各种协议集,其中某些协议(例如AMQP,gRPC,Thrift)可能对网络不友好。
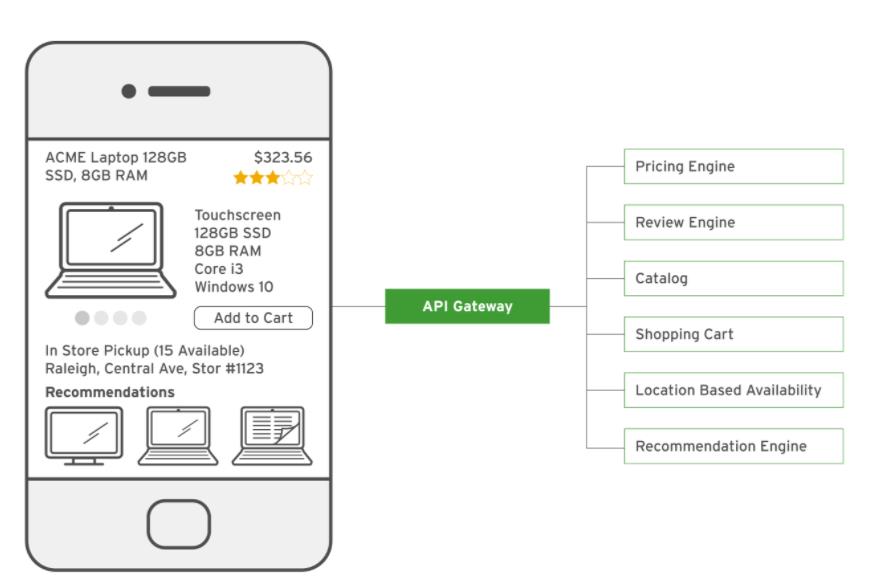
API网关模式通过提供充当后端微服务和客户端(例如Web应用程序或移动应用程序)之间的直通层的中介服务,解决了所有这些问题。
使用API网关
API网关是一项服务,它是一个或多个微服务的主要入口点。网关通过将请求代理到预期的微服务来处理请求。API网关负责请求路由,组合,协议转换,安全性,缓存和分析。
好处
减少客户端与服务的耦合:将客户端与应用程序结构隔离。
简化的服务发现:将客户端与服务实例位置隔离。
特定于客户端的API:为每种类型的客户端提供最佳的API,从而简化了客户端开发。
缺点
增加的复杂性:代表另一个必须开发,部署和管理的高可用性组件(API网关)。
响应时间增加:通过API网关添加另一个网络跃点。
潜在的开发瓶颈:每当网关公开新的微服务或API时,都需要进行更新。
描述容错
基于微服务的应用程序仍然可能像任何其他分布式应用程序一样失败。该失败可能发生在单个服务或服务链中。如果依赖项链中的一项服务失败,那么所有上游客户端都会受到影响。这会导致级联故障。
容错意味着服务可以处理故障,并且最终用户体验不会受到单个服务故障的影响。在基于微服务的应用程序中,容错是必不可少的,因为存在太多的故障点。
容错实现的重点是五个主题:
超时
当一个服务请求另一个服务时,后面的服务可能会花费过多的时间来响应,从而使第一个服务没有响应。超时定义了等待响应时客户端服务的时间限制。
重试
服务可能正遭受短暂的环境,无法正常运行。遇到暂时失败的服务的客户端可以在一段时间后重复相同的请求,以期望失败的服务能够恢复。
倒退
服务失败并不表示客户端直接失败。在某些情况下,客户端可以将请求还原到另一个服务,甚至可以提供以前构建的响应。
Circuit Breaker
如果客户端或网关知道服务失败,则可以避免将请求定向到该服务。客户端可以通过使用后备响应将请求重定向到其他服务来进行响应,也可以通过立即返回失败响应而无需请求失败的服务。
Bulkhead (or Connection Pools)
服务可以限制并发请求数和等待响应的请求数。此限制可避免服务被淹没或过度使用基础资源。
描述Circuit Breaker模式
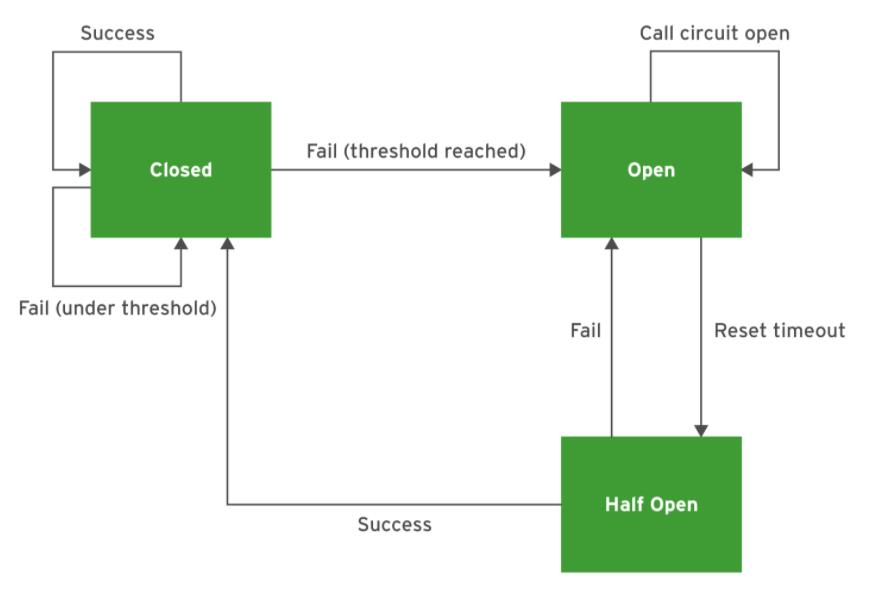
断路器模式有助于确保微服务可以正常处理其所依赖的服务的下游故障。断路器对象将函数调用包装到相关服务,并监视调用的成功。
当一切正常并且呼叫成功时,断路器处于闭合状态。当故障数量(呼叫期间的异常或超时)达到预先配置的阈值时,断路器将跳闸断开。当断路器断开时,不会对相关服务进行任何调用,但是会返回回退响应。经过一段可配置的时间后,断路器将移至半开状态。在半开状态下,断路器定期执行服务调用以检查从属服务的运行状况。如果服务再次正常运行,并且测试调用成功,则电路状态将切换回关闭状态。下图显示了断路器的寿命周期:
描述 Bulkhead Pattern
使用隔板模式可以将依赖关系彼此隔离,并限制尝试访问每个依赖关系的并发线程的数量。这种隔离意味着该调用不能使用超过这些线程的线程,如果调用变得不饱和或从属服务运行不正常,则将影响服务其他部分的性能。
当应用程序请求连接到隔板后面的组件时,隔板检查到所请求组件的连接是否可用。如果与组件的并发连接数低于阈值,则隔板将分配连接。如果不再允许并发连接,则隔板将等待预定义的时间间隔。如果在此持续时间内没有连接可用,则隔板将拒绝该呼叫。
在上图中,一个客户端(或一组客户端)对应用程序组件A,E和F执行10个并发请求。这些组件中每个组件的隔板分别限制为10、15和5个并发请求。组件A和E可以处理所有并发请求,但是组件E只能处理5个并发请求,因此隔板拒绝其中的一些请求。
查看容错实施
Quarkus依赖于Eclipse Microprofile Fault Tolerance规范的SmallRye实现。Eclipse Microprofile Fault Tolerance最初基于Hystrix,它定义了注释,以启用Java微服务中的容错功能。
容错功能的其他实现可在以下位置找到:
Hystrix,来自Netflix的容错实现。
红帽OpenShift服务网格及其上游项目Istio,可在网络通信级别提供容错功能。
Vert.x的断路器组件。
Camel容错EIP。
Apache Commons Circuit Breaker接口和实现。
描述分布式跟踪
在整体应用程序中,可以通过隔离应用程序的单个实例并重现问题来跟踪单个用户与系统的交互。基于微服务的应用程序很复杂;单个微服务无法提供整个应用程序的行为,性能或正确性。
分布式跟踪是一种工具,可在请求通过多个服务时提供有关应用程序行为的完整信息。分布式跟踪工具可以概要分析正在运行的服务以进行报告。这些工具在中央聚合器中收集数据,以进行存储,报告和可视化。
分布式跟踪为每个请求分配唯一的请求ID或跟踪ID。跟踪ID传递给处理请求所涉及的所有服务,并且跟踪ID包含在所有日志消息中。每个服务都会在跟踪中添加一个新的跨度ID。跨度数据由中央聚合器收集或发送到中央聚合器以进行存储和可视化。
跟踪中涉及的服务可以向跨度中添加元数据,例如开始和停止时间戳以及与业务相关的数据。
展示OpenTracing API
OpenTracing API是与供应商无关的开放式跟踪标准。OpenTracing以最小的工作量提供了对应用程序的分布式跟踪。它在许多语言(例如Java,javascript和Go)中都受支持。它在Twitter的Zipkin,Uber的Jaeger和Red Hat的Hawkular APM中实现。
使用聚合日志
大多数基于微服务的应用程序包含许多独立的微服务。这些服务负责执行独特的业务任务。此外,每个服务实例可以在多台计算机上运行,也可以在单独的容器中运行。这些正在运行的服务实例中的每一个都有自己的日志。当服务在容器中运行时,日志将写入stdout和stderr,并且容器和日志都是短暂的。
有效地管理和监视所有这些日志是一个很大的挑战。使用日志聚合机制将所有日志放入中央存储,并使用可以适当地解析日志数据的工具。为了提供最大价值,服务应以标准化和结构化的格式编写日志。应用程序记录器应在日志消息中添加上下文,例如日期和时间,类名或线程号。日志应可索引,可分析,可过滤和可搜索。日志编码器可用于生成JSON日志消息。
OpenShift平台使用称为EFK(Elasticsearch,fluentd和Kibana)的堆栈进行日志聚合。使用fluentd(日志收集器守护程序)收集日志,该守护程序监视节点上所有正在运行的pod的容器日志。Elasticsearch用于存储,索引和查询日志。Kibana是用于日志可视化的Web UI。
维护微服务的安全性
在一系列基于微服务的应用程序中,通过一系列独立的服务维护身份和访问管理可能是一个真正的挑战。要求每个服务呼叫都包括验证步骤是不理想的。幸运的是,有许多可能的解决方案,包括:
单点登录
一种用于身份验证和授权的通用方法,该方法允许客户端使用一组登录凭据来访问多个服务。
分布式会话
一种在微服务和整个系统之间分配身份的方法。
客户端令牌
客户端请求令牌并使用此令牌访问微服务。令牌由身份验证服务签名。微服务无需调用身份验证服务即可验证令牌。JSON Web令牌(JWT)是基于令牌的身份验证的示例
具有API网关的客户端令牌
API网关缓存客户端令牌。令牌的验证由API网关处理
以上是关于微服务架构模式: 大魏再学微服务系列1的主要内容,如果未能解决你的问题,请参考以下文章