Redis之分布式架构
Posted 畅游DT时代
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Redis之分布式架构相关的知识,希望对你有一定的参考价值。
简介
随着信息化时代的快速发展,各个系统中的数据量和业务量与日俱增,传统的关系数据库在性能方面已经不能够支持当代系统的需求,Redis的出现打破了关系型数据库垄断而又尴尬的局面。Redis是以事件驱动的、运行在内存中的key-value数据库,顺应时代的需求,Redis不仅仅支持做缓存,而且支持集群构架和持久化存储。本文主要介绍Redis分布式集群的构建以及其运作原理。
分布式是当业务量、数据量增加时,集群可任意增加减少服务器数量来解决问题。Redis集群架构图如下:
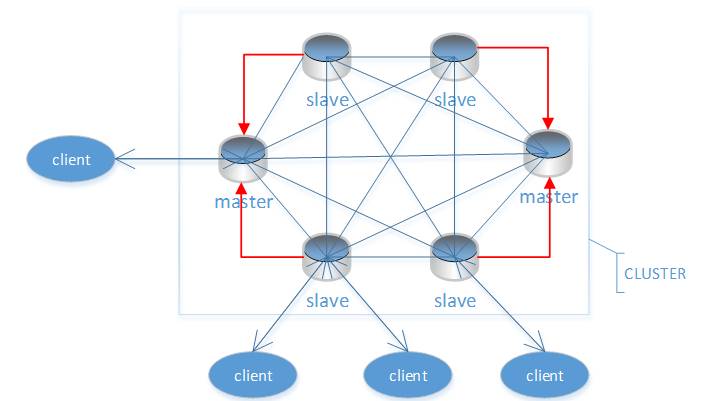
Redis中的每个node节点之间是可以相互连接的,并且连接任何一个节点操作都可以转发到其他任意的一个节点。
Redis容错机制
Redis的节点之间可以相互发送PING命令,接收到PING命令的健康redis节点会返回一个PONG字符串,使用该方法可测试每个节点的健康状态。Redis提供了投票机制的策略,过程如下:如果一个节点1发送给2没有得到PONG返回,那么1节点就会通知其他节点再次给2节点发送PING命令,如果集群中有超过一半的节点给节点2发送PING命令都没有得到回应,那么说明节点2确定为不健康的节点。为了避免因为节点故障造成客户端操作故障,redis为每一个节点提供一个备份节点,发现某节点挂掉之后Redis立刻该启动节点的备份节点,使得该集群可以正常工作。
Redis集群存储
关于集群存储,我们首先想到的便是主备的方式,也就是将数据分散到各个节点上进行存储。
Redis持久化机制
redis有snapshotting和AOF两种持久化存储方式。
Snapshotting定时将redis内存的当前状态保存到RDB文件中,并且存储到硬盘上。
AOF(append-only file):将所有的command操作保存到aof文件中,AOF的同步频率相对比较高,即便是数据丢失,粒度也很小,但是这是特性要牺牲redis的性能。默认为2s同步一次,也可以进行配置改变同步的频率。
基于Redis的分布式集群
为了提高系统响应速度,当今最常用的办法是把热点数据保存到内存中,避免客户端程序直接访问数据库。Redis是一个很好的cache工具,大型系统中热点数据量巨大,仅仅依靠cookie或者session满足不了当代的需求,故Redis分布式集群应运而生。首先一台主机的内存是非常有限的,当数据量增加时,一味地增加主机内存大小是非常不理智的,但是我们可以将内存横向扩展,也就是增加节点,即分布式多个Redis实例协同运行。另外Redis的主进程是单线程工作的,而当今硬件的成本较低,大多数主机都是多核CPU的,如果该主机只运行一个Redis实例是非常浪费,考虑到实际情况,通常一台机器上同时跑多个Redis实例。
Redis官方集群方案Redis Cluster
RedisCluster是由多个同时服务于一个数据集合的redis实例组成的整体。其架构中所有的节点都是相互连接的,所以需要维护好集群架构中所有的节点信息,一旦某一个节点损坏,可能会导致整个集群无法工作。其通信为总线通信,集群总线端口大小为客户端服务端+10000,这个10000是固定值,节点和节点之间通过二进制协议进行通信,客户端与节点之间的通信大多数通过文本协议进行。Redis Cluster的特点如下:
客户端可以任意连接一个节点;
redis-trib.rb脚本为集群的管理工具,比如自动添加减少节点,规划槽位等等(ruby语言);
用对用户来说,用户只是关注这个数据集合,而数据集合存储在哪个节点对于用户是透明的;
该分布式CAP(一致性、可用性和分区容错性),牺牲了C数据的强一致性原则,最大程度追求redis的特性还原。
下图为redis cluster的结构图:
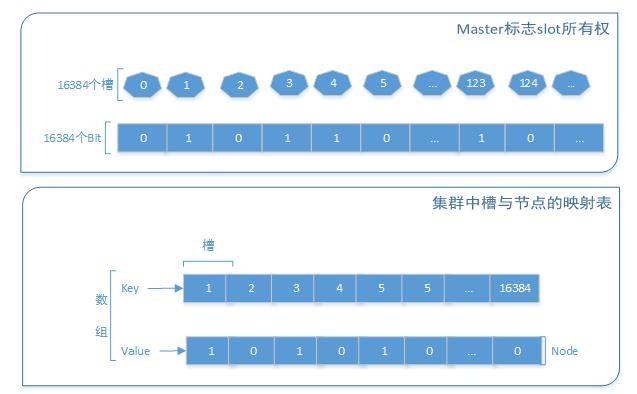
redisCluster实现原理之槽(slot)
RedisCluster是一种服务器Sharding技术。Sharding采用slot(槽)的概念,Redis Cluster一共分成16384个槽,该槽是虚拟的。正常工作时,Redis Cluster中的每个master都会负责一部分槽,当某个key被映射到某个master负责的槽,那么该master将为这个key服务,关于key的分配权可以是用户,也可以是初始化时由reids-trib.rb自动生成。
redisCluster实现原理之位序列结构
在redis Cluster中只有Master才有slot的所有权,slave只有slot的使用权。Master基于位序列结构来判断slot的归属问题。Master节点中维护着一个16384/8字节的位序列,master节点用位来标识某个槽是否为自己所有,也就是说,对于槽1,只需要判断master序列位的第1位即可。同时集群中也有一个关于槽和节点之间的映射表,它是用长度为16384的数组实现的,数组下标为槽编号,数组内容为集群的节点,该设计简约空间且操作简单,如下图所示。
redisCluster实现原理之键空间分布算法
对于每个进入redis的键值对,根据key进行散列分配到这16384个slot中的某一个里面,其使用的hash算法是CRC16后16384取模,得到的数值为key所存储的slot。表达式为crc16(key) & 0x3FFF。
redisCluster实现原理之键哈希标签原理
当向cluster提交了一批key时,如果按照键空间分配的处理方法,这些key可能会存储到不同的slot中,如果我们使用键哈希标签的算法,就可以让用户指定将一批键都能够存储在同一个slot中。
因为redis在计算槽编码的时候只会获取{}之间的字符进行槽标号设计,用户只需要需要按照既定的生成规则生成key即可。也就是说key{abcd}1和key{abcd}2可存储在同一个slot中。
RedisCluster实现原理之重定向客户端
客户端重定向是节点用来处理当客户端访问的key不存在节点的情况的方法。如果访问的key所属的槽并不属于本节点,则会返回错误请求信息”GET msg-MOVED 200 127.0.0.1:3000”,该错误信息表示客户端想要请求200槽由运行在127.0.0.1,端口为3000的Master实例服务。另外客户端缓存连接可以避免多次访问该key时所造成的多次往返通信造成的资源浪费。
RedisCluster实现原理之重新分片
重新分片的意思是集群节点映射关系的改变,但是当重新分片的时候,槽中的键值也是要被移动到新的节点的。重新分片非常重要的事情便是槽迁移,槽迁移分为两个状态,MIGRATING状态和IMPORTING状态,如下图所示。
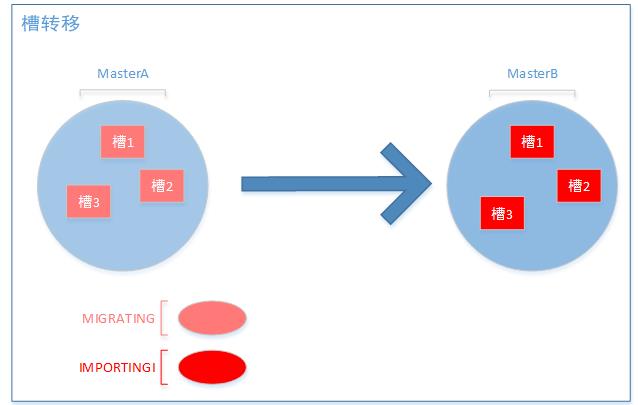
MIGRATING是预备迁移状态,该状态下节点访问key,如果存在则直接返回,不存在则返回客户端ASK,但是这次请求并不会刷新映射关系表,当再次方位该key的时候依然会访问当前节点。当key中包含多个请求的时候,如果都存在则全部返回,如果不存在返回ASK,如果存在一部分,那么则返回客户端TRYAGAIN,通知客户端重试。当迁移完毕,再次进行访问的时候则会进行重定向,并改变客户端node的映射表。
IMPORTING状态是节点迁移的目的节点,处于该状态的节点,正常的命令会被重定向,ASK命令会执行,这样做是为了让key在没有在老节点已经被迁移到新节点的情况下顺利访问。
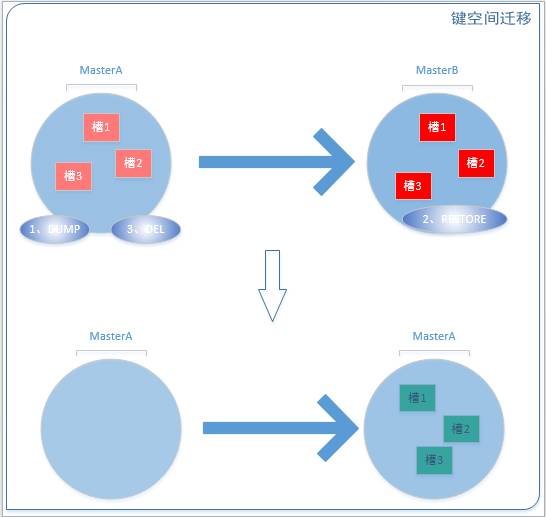
键空间迁移是指当满足槽迁移的前提条件下,可以用命令将槽中的键空间从源节点到目的节点,也就是进行数据转移。命令分为三步DUMP(导出键空间)、RESTORE(将键空间存储到目的master)和DEL(删除源master键空间)。数据迁移成功后,处于MIGRATING和IMPORTING状态的槽变为常态,从而完成整个分片过程。键空间迁移如下图所示。
基于RedisCluster的redis集群设计
搭建环境:一台服务器
设计思路:集群中有A、B、C三个节点,其分别是服务器中三个不同的接口3000、3001和3002;接下来我们平均分配哈希槽的范围,节点A负责槽的范围是0-5460,B负责槽的范围是5461-10922,C负责槽的范围是10923-16383;然后为每个节点设计一个备份节点,也就是从节点,增加集群的容错能力;当新增主节点的时候,将每个已有节点前面部分添加到新增节点中,删除节点同理。下图为设计图。
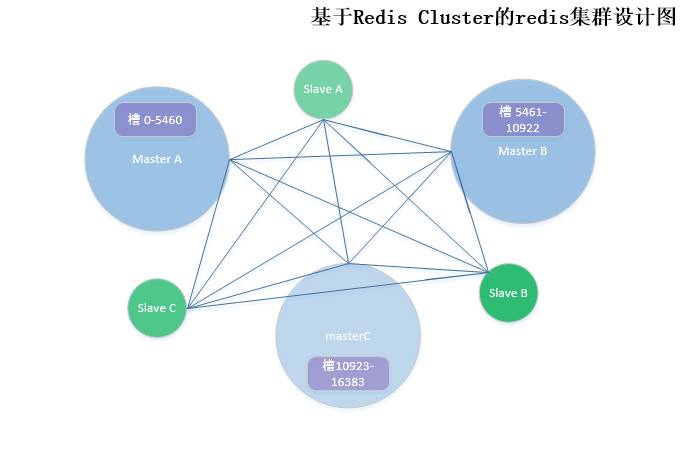
该集群因采用一台机器,避免了带宽对节点之间信息传递的影响,但是硬盘的容量有限。因其可以自由的增删节点,故有足够的灵活性。适用于高并发数据的存取。
结束语
本文讲述了基于redis的分布式架构,从最基本的架构原理到比较实用的Redis官方集群方案Redis Cluster,进行了详细的剖析,包括redis容错机制,集群存储、持久化机制、redis cluster详细结构和redis cluster详细实现原理。全民信息时代,分布式更有待发展和创新,让我们一起投入分布式发展的浪潮吧。
-END-
声明:
本文为中国联通网研院网优网管部IT技术研究团队独家提供。
如需转载或合作,请联系管理员(luxin@dimpt.com)
长按既可添加关注
以上是关于Redis之分布式架构的主要内容,如果未能解决你的问题,请参考以下文章