数据库分布式架构巧设计,水平拆分不再难
Posted 猿人课堂
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据库分布式架构巧设计,水平拆分不再难相关的知识,希望对你有一定的参考价值。
在阿里云生态日,袋鼠云首席数据库架构师赵晓宏分享了《高容量大并发数据库服务——数据库分布式架构设计》。他从分布式需求、拆分原则、拆分难点及解决方案、数据库规范设计、运维相关五个方面进行了分享。在分享中,他主要介绍了水平拆分的原则以及解决方案,分享了DRDS的架构与实践。
以下内容根据直播视频整理而成。
分布式需求
为什么要做分布式?首先是因为高并发,分布式应用带来更大量的数据库请求;高容量,业务增长,产生大量在线数据,关系型数据库要支持业务就要支持大数据量的存储;资源向上扩展存在天花板,无法做到无限制的纵向扩展;支撑业务高速发展,平滑扩容。
拆分原则
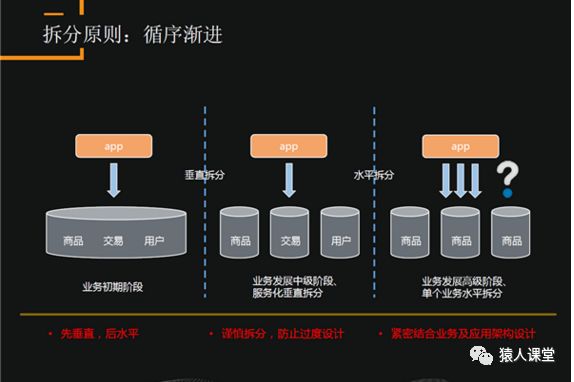
上图是数据库改造的进阶。业务初期,客户量比较少,可能在一个实例上把所有的服务、数据都能存放下来并且支持业务的发展。当客户量和数据量变大时,数据库很容易成为一个瓶颈,怎么去做改造?建议先做服务化的改造,不同的业务模块做一个垂直的梳理,不同服务的数据库相互隔离,中间的交互由业务去实现,这样数据库就可以分布在不同的实例上,并且可以支持相对较高的并发和容量。再往上发展时,单实例依然是一个瓶颈,此时要考虑做一个水平的拆分,把一个服务的数据分布在不同的实例上。拆分需要循序渐进,先垂直后水平,防止过度设计,紧密结合业务及应用架构设计。
拆分难点及解决方案
水平拆分难点
首先是系统复杂度增大,系统架构设计需要彻底的重构;技术挑战,应用需要处理复杂的分布式逻辑;稳定性挑战;分布式的局限性,不支持跨库join、分布式事务、全局sequence等。
解决方案:客户端实现数据路由
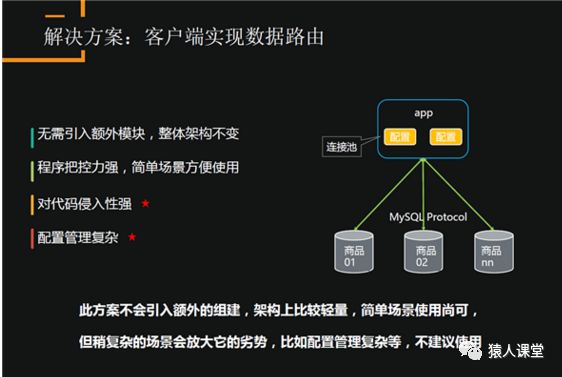
该方案的优点是不需要引入中间件,直接在客户端配置,程序把控力强,简单场景方便使用。缺点是对代码侵入性强,因为代码端要去管理路由;配置管理复杂,如果配置错误,数据可能完全乱掉,修复也会比较复杂。
解决方案:数据库中间件
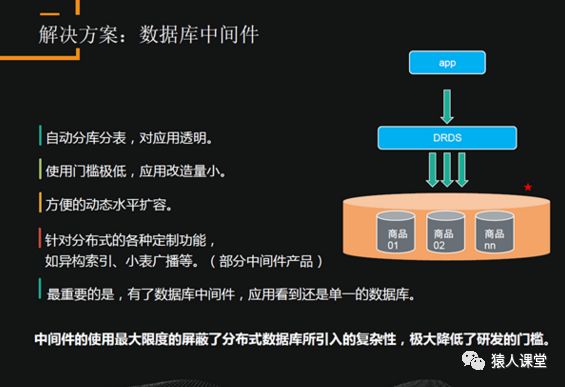
使用中间件可以实现自动的分库分表,对应用透明,使用类似于单实例;使用门槛低,应用只需要考虑分布式事务,跨库join,而不用考虑数据的路由;方便水平扩容。使用了中间件之后,应用看到的还是单实例数据库,不需要考虑分布式的情况,对开发来说是比较有优势的。
水平切分原理及设计原则
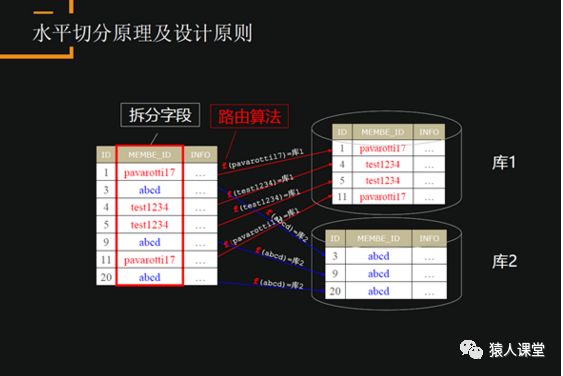
数据库拆分都是用字段hash把数据分配到不同的底层库。选择的原则是拆分尽量均匀并且一次查询尽量落到单实例库上,这样能够更快的返回,而且有更大的并发。那么,中间件怎么实现数据库的分布式?如上图所示,选择了MEMBE_ID字段,将字段值做一个hash分类到不同库中。比如发出查询test1234的请求,就会直接转到库1里。
数据访问——SQL转发
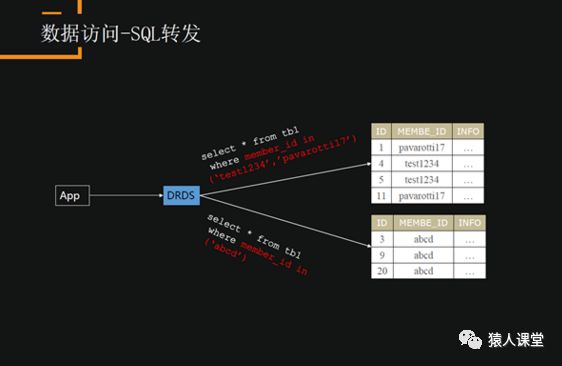
当我们输入一个SQL语句:select * from tb1 where member_id =‘test1234’,APP输入请求会转到中间件,中间件会对这条SQL语句进行解析,按照路由规则把这条请求分发到底层的数据库,库2还有一个请求是查询MEMBE_ID是1234的数据。最终的查询结果会返回DRDS层做一个聚合,速度也比较快。
DRDS
阿里云的DRDS是淘宝积累多年的产品。DRDS具有五大功能:分库分表,DRDS的核心功能,支持数据的多维度切分和路由访问;内建读写分离功能,可以灵活配置访问权重;自带全局唯一ID组件,DRDS层维护全局的sequence;小表广播,查询引擎识别和下推复杂查询,兼容98% mysql语法;弹性扩容组件实现自动化在线水平扩容。
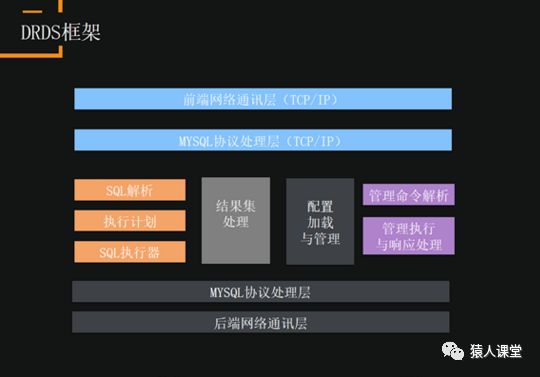
DRDS框架如上图所示。网络层完全兼容MySQL协议,可以做SQL解析、执行计划,实现路由功能来决定SQL分配到一个库还是多个库。结果集处理包括排序、聚合等动作,此外还支持一些管理工作。底层依赖MySQL协议和底层物理库通信。
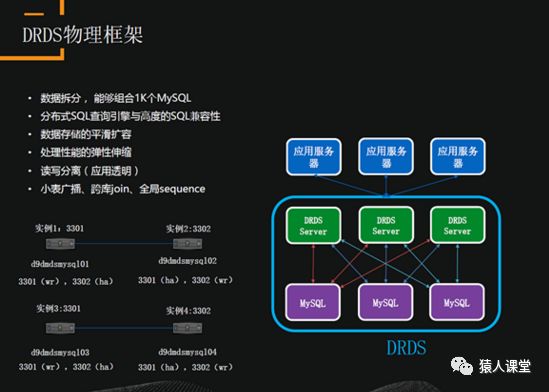
DRDS物理层框架上层是应用服务器,连接DRDS的一个集群。DRDS是集群式的,不是主备,保证了可扩展和高可用性。集群连接的是底层的MySQL。
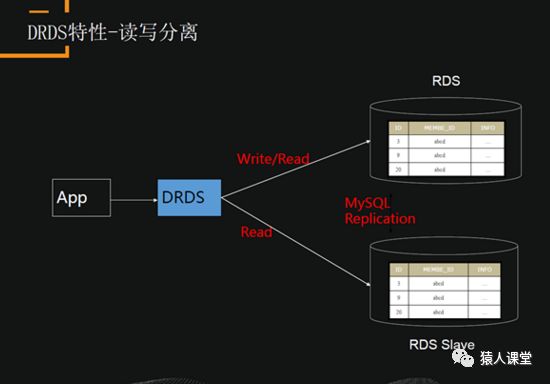
主库和读库是使用数据库的原生复制实现的,数据是强一致的。DRDS会自动判断请求,然后做一个分发,事务型的操作会全部路由到一个主库上。
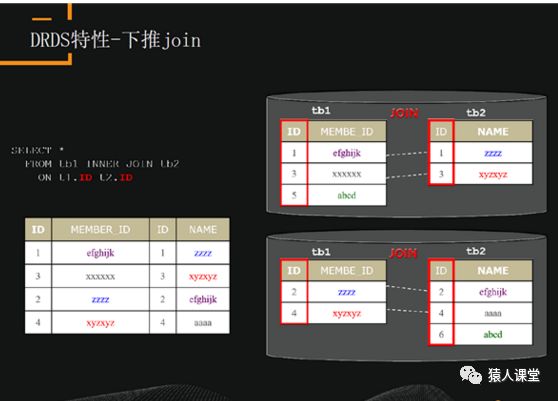
下推join是指把join从DRDS层往下,在MySQL层实现join。所以,在业务设计上要避免跨库join,比如有两张表join,则必须保证有相同的拆分原则,上图中table1和table2都是根据ID做拆分,相同的ID分配到相同的数据库。
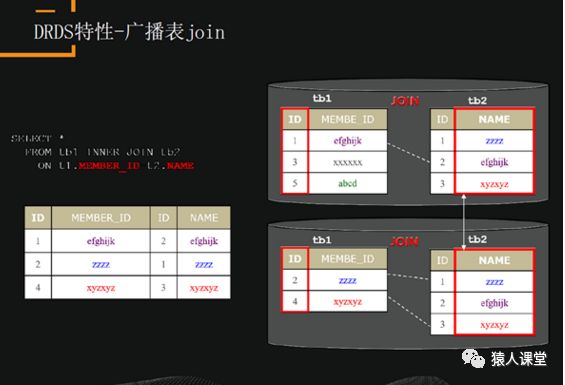
广播表也是避免跨库join的一个方法。上图中,table1已经做过拆分,table2没有做过拆分,它是一个小表,我们可以把它的数据完全冗余到每一个库里面,那么任何一个跟table2做join的查询都能在一个库去实现。最后,把结果在DRDS层做聚合。
数据库规范设计:最佳实践
查询应尽可能带上分库条件,如果说一个表拆分到底层10个库,每次查询如果都带上分库条件的话DRDS很轻易把这个请求路由到底层库上,如果没有分库条件,DRDS不知道数据到底存放在哪里,这样的话会分别从10个库取数据,然后在DRDS层做聚合,网络、计算的开销比较大。Join有几种解决方案:尽可能参与Join的每张表都带上相同的分库条件,这样就还会限定在一个库里面;分库键=分库键的Join;广播表Join。单库事务尽量限制在单库范围内,避免引入分布式事务。
运维相关
DRDS支持直接实例的创建、释放以及拆分库的创建、建表的接入。数据运维支持导入、扩容、小表复制(即小表广播,DRDS层自己实现数据的复制)、规格升级(纵向的升级)。数据服务包括分库分表、读写分离、异构索引(从不同的维度在大表中查询,如何选择拆分?异构索引底层也是做数据冗余,根据不同的拆分情况做查询)、DRDS指令。
EasyDB是数据库的自动化管理平台,支持Oracle和MySQL、Redis,能够实现基本的监控、审计、备份、高可用、一键切换、资源管理。
以上是关于数据库分布式架构巧设计,水平拆分不再难的主要内容,如果未能解决你的问题,请参考以下文章