分布式架构整体介绍下
Posted JudyGirl
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分布式架构整体介绍下相关的知识,希望对你有一定的参考价值。
前言
目录
分布式系统高扩展架构设计:session共享,CDN,业务逻辑性能优化,存储性能优化。
分布式系统高扩展架构设计
从有状态转换为无状态
什么有状态?
指的是进程在本地内存或者磁盘上存储自己代码逻辑数据,在进程启动的时候需要把数据加载到内存中或者要求数据文件在本地磁盘上存在才能正常运行的服务。
下面是针对有状态的说明
例如缓存用户的信息,当查询的时候直接从本地获取, 这个时候看起来还不错哦,获取数据不用走DB,减少了IO。但是如何这个是扩充节点呢?由于目前是有状态的服务, 对于扩展就非常不容易,针对不同的用户针对路由到具体的机器, 非常麻烦╭(╯^╰)╮,所以这个时候无状态部署就要比有状态部署好很多了哦
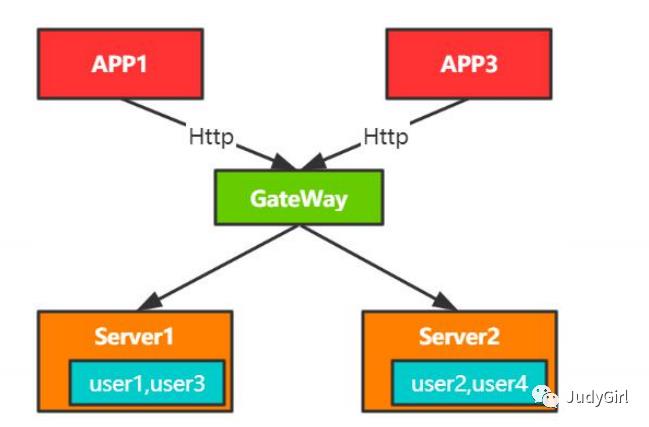
无状态部署
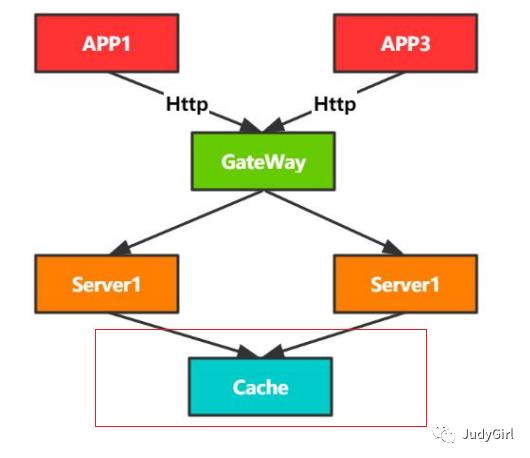
有状态部署和无状态部署的优缺点
有状态:1扩展性差,实现复杂,抗灾能力不足(万一挂了怎么办)
无状态:1 按需随时扩展,抗灾能力强,可靠性高
CDN
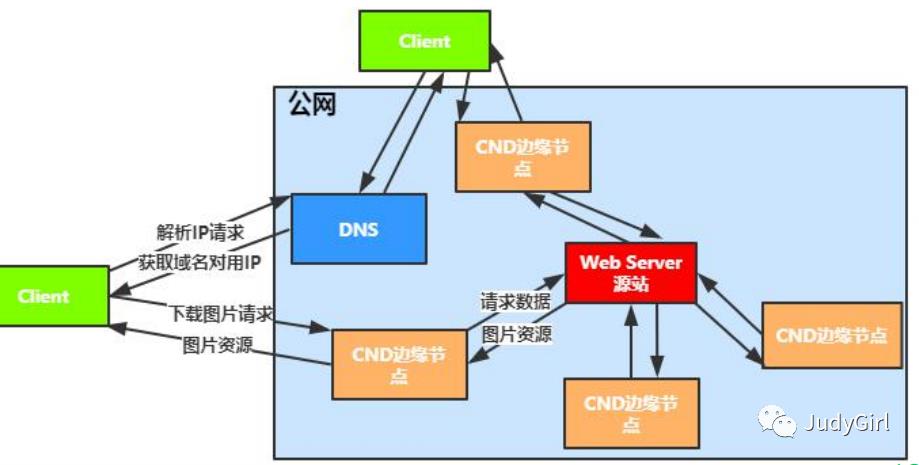
全程是:Content Delivery NetWork 内容分发网络,可以把他理解为公网上的缓存,一般我们会缓存图片等资源,为什么会有CDN, CDN在全国各地,如果不在全国各地,假设只有北京有, 难道还让上海访问北京的CDN吗,肯定会很慢点。如果在上海CDN拉取那就很快了。 依靠部署在各地的边缘服务器, 由于用户访问的时候就近获取的数据,所以网络减低了网络阻塞,提供用户命中率和访问速度。
根据下面的图也可以看出访问的距离自己最近的服务器,
访问步骤:
2 访问最近的CDN节点服务
3 判断是否需要回源,判断是否有数据,如果没有去源站拉取
4 返回数据
业务逻辑优化
1 RPC异步调用优化
看到这张图我想大家应该就能明白了吧。如果是串行访问可以看出时间很长
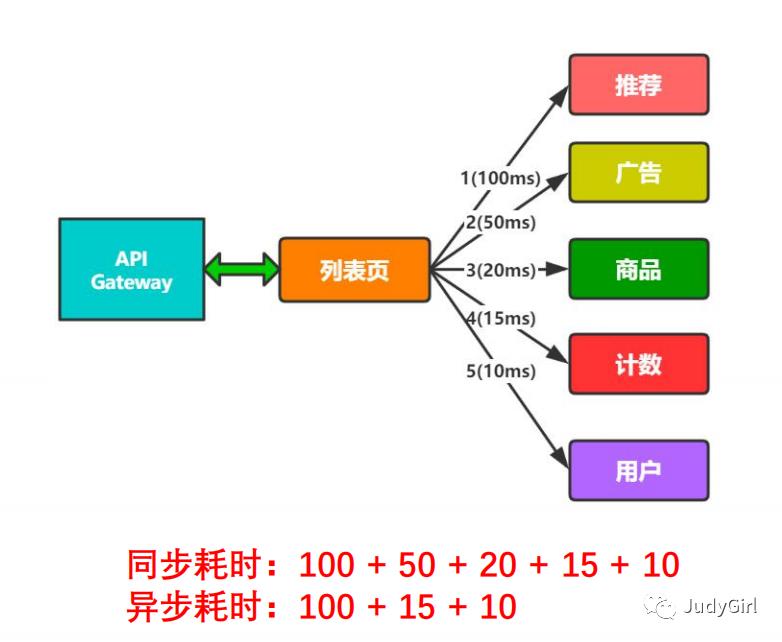
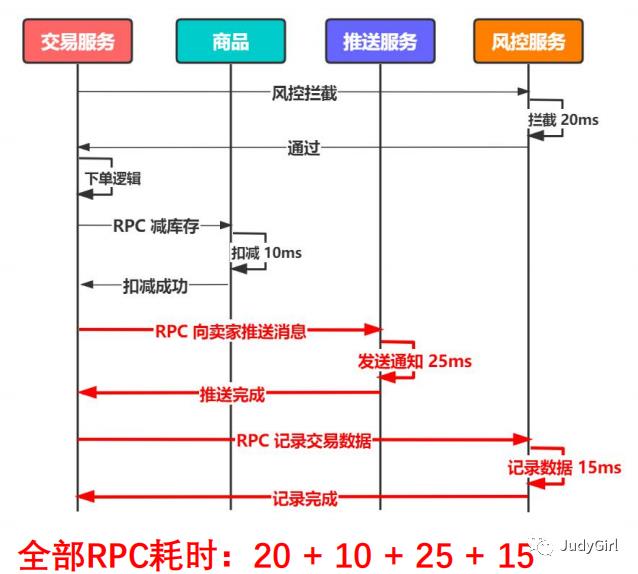
2 消息队列
通过放到消息队列里面也可以节省时间,以前的文章提到过
3 参数调优
1 线程池
2 超时时间:越往下游走,超时时间越要少和严格,防止上游超时
3 JVM优化
4 增加服务节点 :提升吞吐量。对于上游来说发现下游的堆积少了。
缓存性能优化
1 使用缓存
例如redis,在读取数据的时候使用缓存,减少访问DB调来IO
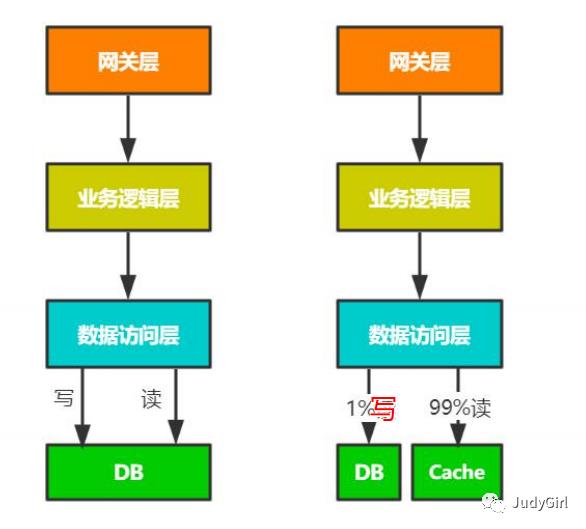
读业务逻辑:1读Redis 2 Redis没有则读DB 3 读到的数据再次刷新到缓存中
写业务逻辑:1 写DB 2 写Redis, 那么整个时候需要考虑一个问题? 如何保证写DB和写Redis如何保证原子性 (这里解决的是分布式事务问题)
更改写业务逻辑:1 清除Redis数据, 2 更新DB数据, 3 填充Redis数据 , 这个是1 和2 之间就不存在原子性关系了,如果失败则直接返回给用户失败。
假如目前是并发的情况,可能会导致在没有更新的时候有新的用户访问了,导致数据到redis里, 这个时候可以使用分布式锁问题解决(从一致性问题到并发问题)
mysql索引优化
在mysql索引优化这块你需要了解什么是聚簇索引,非聚簇索引,覆盖索引,联合索引, 什么时候会回表查询, 什么时候不会回表查询 ? 覆盖索引和联合索引的区别是什么?为什么非聚簇索引会导致回表查询,为什么覆盖索引不会回表查询, 为什么非聚簇索引叶子节点存放的是聚簇索引的指针?把这些问题弄明白应该就差不多了, 你是不是会问我,你为啥只提问题,不回答呢? 因为我都会啊~ 就是不告诉你呀 ~ 你要自己查(#^.^#)

举一个联合索引比较有意思的例子
假如a是2,b是4 ,索引是ab 那么当a=value and b>value会用到索引吗?这个时候是会用到索引的, 因为a不是范围查找
假如b>value and a=value 这个时候会用到索引吗,答案是可以用到,在sql解析的时候可以调整索引的位置
分库分表
1 垂直拆分
一个表拆分为两个表,两个表分配到两个库里
2 水平拆分
把有张表进行水平拆分,也就是多个表存储的是一个表的结构,存储数据量和访问量也差不多。
3 冷热数据
冷热数据分离,最近的数据在热库里,旧数据存放在冷库中。
完
以上是关于分布式架构整体介绍下的主要内容,如果未能解决你的问题,请参考以下文章