为什么分布式架构一定要考虑容错?
Posted 架构师社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了为什么分布式架构一定要考虑容错?相关的知识,希望对你有一定的参考价值。
来自:石杉的架构笔记
目录
(1)原始架构:TB级数据放在一台机器上
(2)到底啥是分布式存储?
(3)那啥又是分布式存储系统呢?
(4)某台机器宕机了咋办?
(5)Master节点如何感知到数据副本消失?
(6)如何复制副本保持足够副本数量
(7)删除多余副本又该怎么做呢?
(8)全文总结
咱们就用分布式存储系统举例,来聊一下容错架构的设计。首先,我们来瞧瞧,到底啥是分布式存储系统呢?
其实特别的简单,咱们就用数据库里的一张表来举例。
比如你手头有个数据库,数据库里有一张特别大的表,里面有几十亿,甚至上百亿的数据。
更进一步说,假设这一张表的数据量多达几十个TB,甚至上百个TB,这时你觉得咋样?
当然是内心感到恐慌和无助了,因为如果你用mysql之类的数据库,单台数据库服务器上的磁盘可能都不够放这一张表的数据!
咱们就来看看下面的这张图,来感受一下。
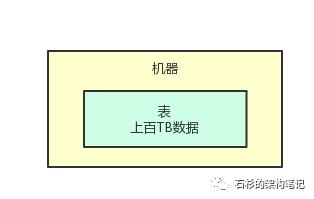
2、到底啥是分布式存储?
所以,假如你手头有一个超大的数据集,几百TB!那你还是别考虑传统的数据库技术来存放了。
因为用一台数据库服务器可能根本都放不下,所以我们考虑一下分布式存储技术?对了!这才是解决这个问题的办法。
咱们完全可以搞多台机器嘛!比如搞20台机器,每台机器上就放1/20的数据。
举个例子,比如总共20TB的数据,在每台机器上只要把1TB就可以了,1TB应该还好吧?每台机器都可以轻松加愉快的放下这么多数据了。
所以说,把一个超大的数据集拆分成多片,给放到多台机器上去,这就是所谓的分布式存储。
咱们再看看下面的图。
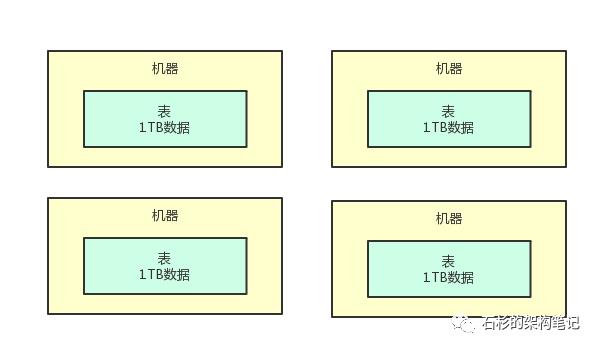
3、那么啥又是分布式存储系统呢?
那分布式存储系统是啥呢?
分布式存储系统,当然就是负责把一个超大数据集拆分成多块,然后放到多台机器上来存储,接着统一管理这些分散在多台机器上存储的数据的一套系统。
比如说经典的hadoop就是这类系统,然后fastdfs也是类似的。
如果你可以脑洞打开,从思想本质共通的层面出发,那你会发现,其实类似elasticsearch、redis cluster等等系统,他本质都是如此。
这些都是基于分布式的系统架构,把超大数据拆分成多片给你存放在多台机器上。
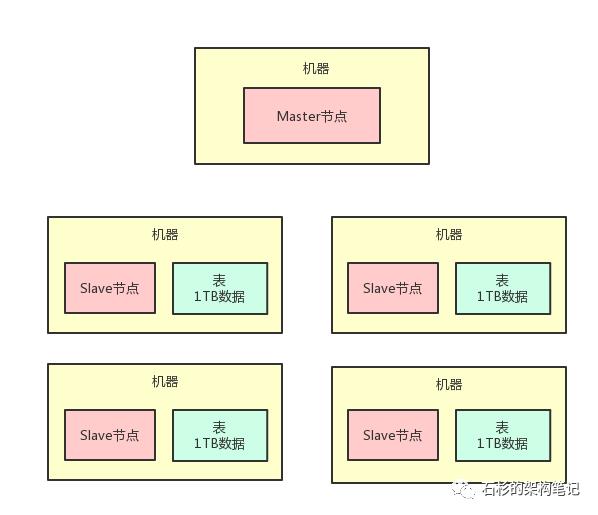
咱们这篇文章是从分布式系统架构层面出发,不拘泥于任何一种技术,所以姑且可以设定:这套分布式存储系统,有两种进程。
一个进程是Master节点,就在一台机器上,负责统一管控分散在多台机器上的数据。
另外一批进程叫做Slave节点,每台机器上都有一个Slave节点,负责管理那台机器上的数据,跟Master节点进行通信。
咱们看看下面的图,通过图再来直观的看看上面的描述。
4、那某台机器宕机了咋办?
这个时候又有一个问题了,那么万一上面那20台机器上,其中1台机器宕机了咋整呢?
这就尴尬了,兄弟,这会导致本来完整的一份20TB的数据,最后有19TB还在了,有1TB的数据就搞丢了,因为那台机器宕机了啊。
所以说你当然不能允许这种情况的发生,这个时候就必须做一个数据副本的策略。
比如说,我们完全可以给每一台机器上的那1TB的数据做2个副本的冗余,放在别的机器上,然后呢,万一说某一台机器宕机,没事啊,因为其他机器上还有他的副本。
我们来看看这种多副本冗余的架构设计图。
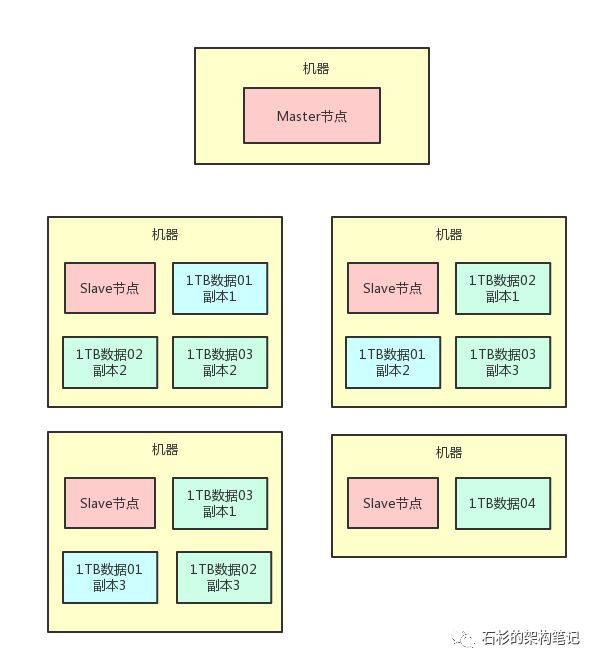
上面那个图里的浅蓝色的“1TB数据01”,代表的是20TB数据集中的第一个1TB数据分片。
图中可以看到,他就有3个副本,分别在三台机器中都有浅蓝色的方块,代表了他的三个副本。
这样的话,一份数据就有了3个副本了。其他的数据也是类似。
这个时候我们假设有一台机器宕机了,比如下面这台机器宕机,必然会导致“1TB数据01”这个数据分片的其中一个数据副本丢失。如下图所示:
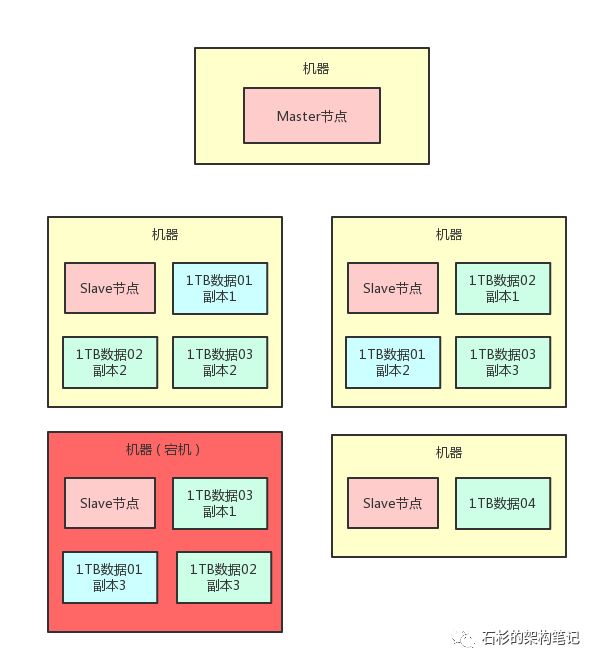
那这个时候要紧吗?不要紧,因为“1TB数据01”这个数据分片,他还有另外2个副本在存活的两台机器上呢!
所以如果有人要读取数据,完全可以从另外两台机器上随便挑一个副本来读取就可以了,数据不会丢的,不要紧张,大兄弟。
5、Master节点如何感知数据副本消失?
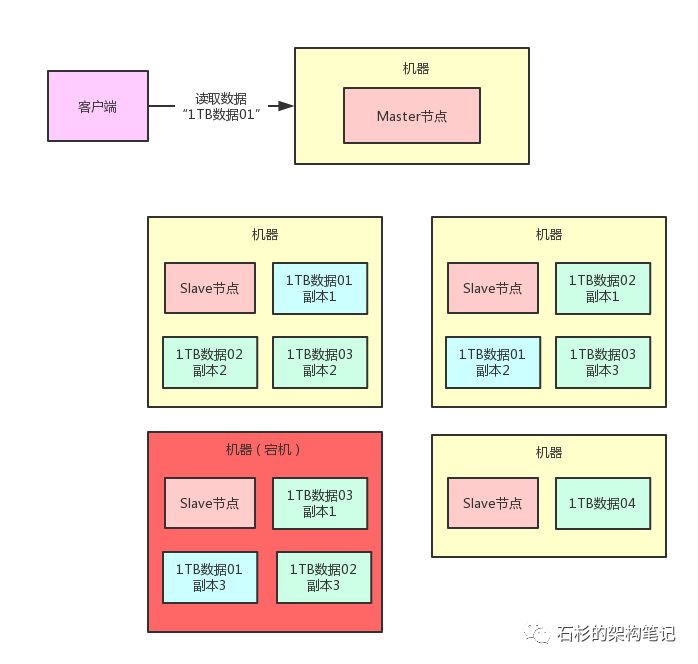
现在有一个问题,比如说有个兄弟要读取“1TB数据01”这个数据分片,那么他就会找Master节点,说:
“你能不能告诉我“1TB数据01”这个数据分片人在哪里啊?在哪台机器上啊?我需要读他啊!”
我们来看看下面的图。
那么这个时候,Master节点就需要从“1TB数据01”的3个副本里选择一个出来,告诉人家说:
“兄弟,在哪台哪台机器上,有1个副本,你可以去那台机器上读“1TB数据01”的一个副本就ok了。”
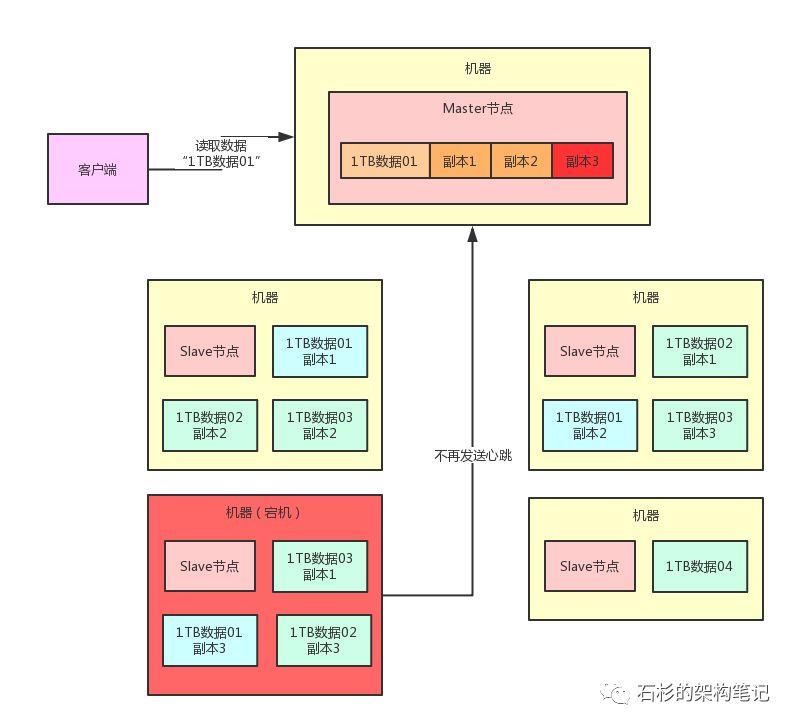
但是现在的问题是,Master节点此时还不知道“1TB数据01”的副本3已经丢失了,那万一Master节点还是通知人家去读取一个已经丢失的副本3,肯定是不可以的。
所以,我们怎么才能让Master节点知道副本3已经丢失了呢?
其实也很简单,每台机器上负责管理数据的Slave节点,都每隔几秒(比如说1秒)给Master节点发送一个心跳。
那么,一旦Master节点发现一段时间(比如说30秒内)没收到某个Slave节点发送过来的心跳,此时就会认为这个Slave节点所在机器宕机了,那台机器上的数据副本都丢失了,然后Master节点就不会告诉别人去读那个丢失的数据副本。
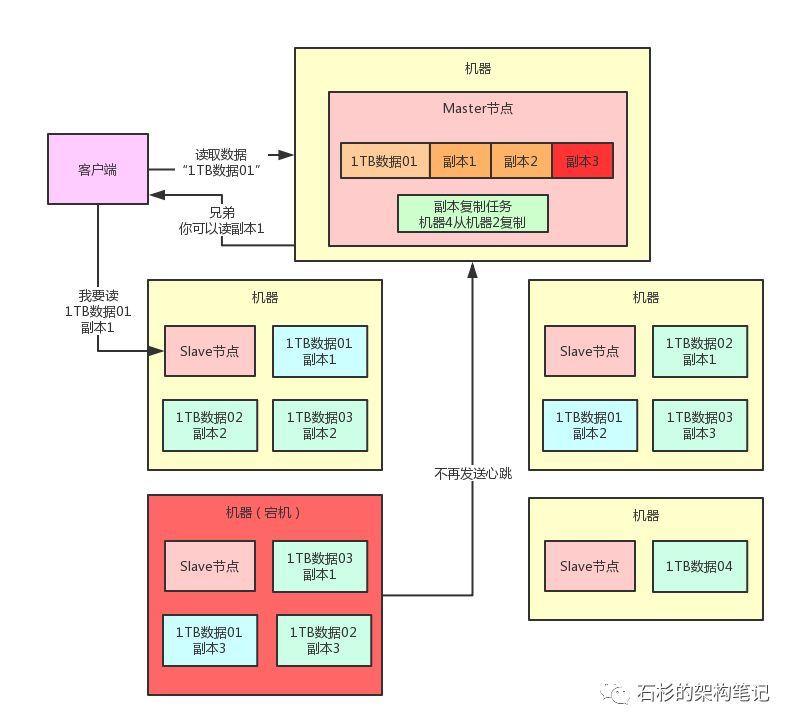
大家看看下面的图,一旦Slave节点宕机,Master节点收不到心跳,就会认为那台机器上的副本3就已经丢失了,此时绝对不会让别人去读那台宕机机器上的副本3。
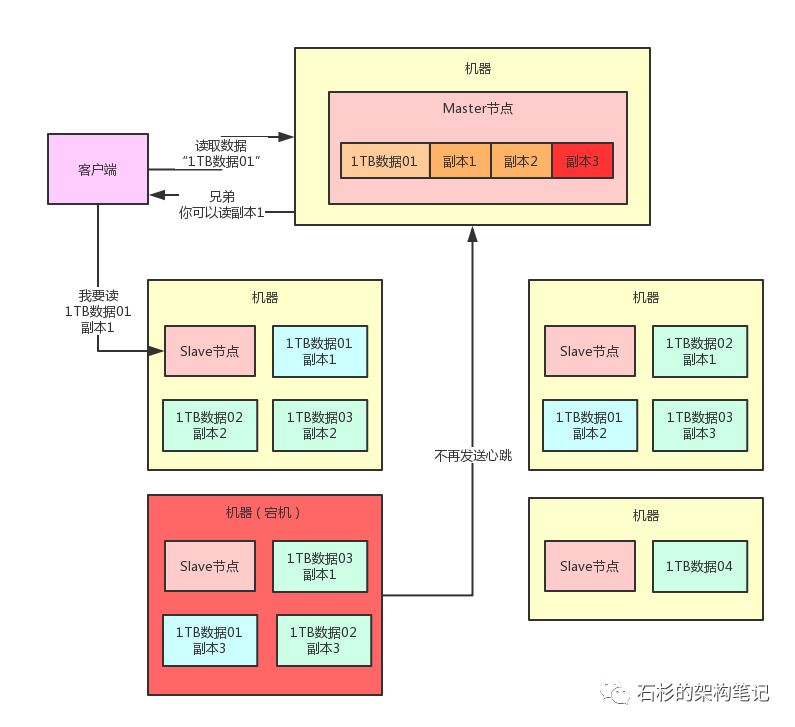
那么此时,Master节点就可以通知人家去读“1TB数据01”的副本1或者副本2,哪个都行,因为那两个副本其实还是在的。
举个例子,比如可以通知客户端去读副本1,此时客户端就可以找那台机器上的Slave节点说要读取那个副本1。
整个过程如下图所示。
6、复制副本以保持足够副本数量
这个时候又有另外一个问题,那就是“1TB数据01”这个数据分片此时只有副本1和副本2这两个副本了,这就不足够3个副本啊。
因为我们预设的是每个数据分片都得有3个副本的。大家想想,此时如何给这个数据分片增加1个副本呢?
很简单,Master节点一旦感知到某台机器宕机,就能感知到某个数据分片的副本数量不足了。
此时,就会生成一个副本复制的任务,挑选另外一台机器来从有副本的机器去复制一个副本。
比如看下面的图,可以挑选第四台机器从第二台机器去复制一个副本。
但是,现在这个复制任务是有了,我们怎么让机器4知道呢?
其实也很简单,机器4不是每秒都会发送一次心跳么?当机器4发送心跳过去的时候,Master节点就通过心跳响应把这个复制任务下发给机器4,让机器4从机器2复制一个副本好了。
同样,我们来一张图,看看这个过程:
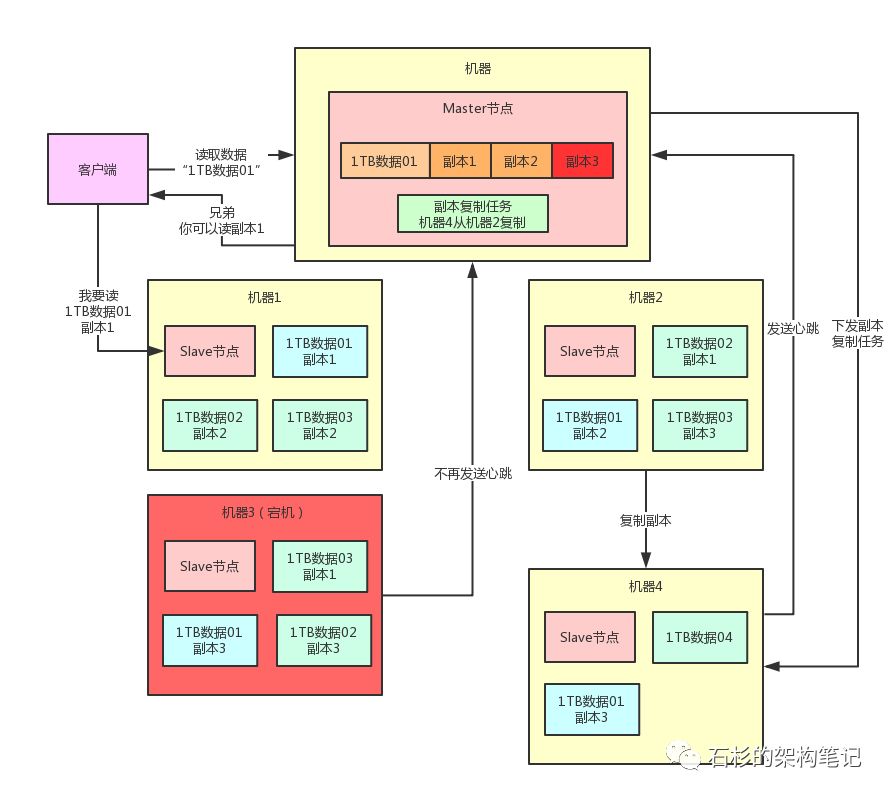
看上图,现在机器4上是不是又多了一个“1TB数据01”的副本3 ?那么“1TB数据01”这个数据分片是不是又变成3个副本了?
7、删除多余副本
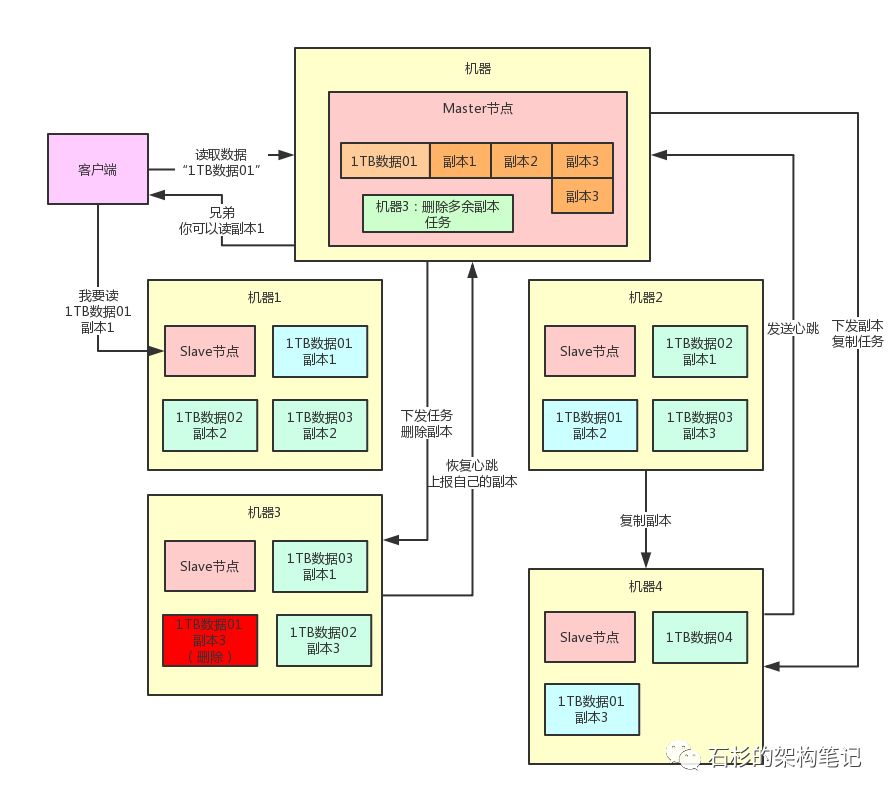
那反过来,如果说此时机器3突然恢复了,他上面也有一个“1TB数据01”的副本3,相当于此时“1TB数据01”就有4个副本了,副本不就多余了吗?
没关系,一旦Master节点感知到机器3复活,会发现副本数量过多,此时会生成一个删除副本任务。
他会在机器3发送心跳的时候,下发一个删除副本的指令,让机器3删除自己本地多余的副本就可以了。这样,就可以保持副本数量只有3个。
一样的,大家来看看下面的图。
8、总结
好了,到这里,通过超级大白话的讲解,还有十多张图的渐进式演进说明,相信大家以前即使不了解分布式系统,都绝对能理解一个分布式系统的完整的数据容错架构是如何设计的了。
实际上,这种数据分片存储 、多副本冗余、宕机感知、自动副本迁移、多余副本删除,这套机制,对于hadoop、elasticsearch等很多系统来说,都是类似的。
所以笔者在这里强烈建议大家,一定好好吸收一下这种分布式系统、中间件系统底层数据容错架构的思想。
这样,以后学习类似的一些技术的时候,对他们的原理、思想都会感到一种似曾相识的感觉。
作者:中华石杉,十余年 BAT 架构经验倾囊相授。个人微信公众号:石杉的架构笔记( ID : shishan100 )
长按订阅更多精彩▼
如有收获,点个在看,诚挚感谢
以上是关于为什么分布式架构一定要考虑容错?的主要内容,如果未能解决你的问题,请参考以下文章
您如何设计基于 Erlang/OTP 的分布式容错多核系统的架构?