分布式架构数据存储设计与实践
Posted JudyGirl
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分布式架构数据存储设计与实践相关的知识,希望对你有一定的参考价值。
自我思考
好久没有写文章,内心很是自责,总是给自己找很多借口推辞写文章,导致这篇文章在思考的时候,不知道应该如何贯穿整个文章思路,也不知道怎么下笔, 一个星期一篇,让我们重新约定吧~ 拉钩哦(#^.^#)
目录
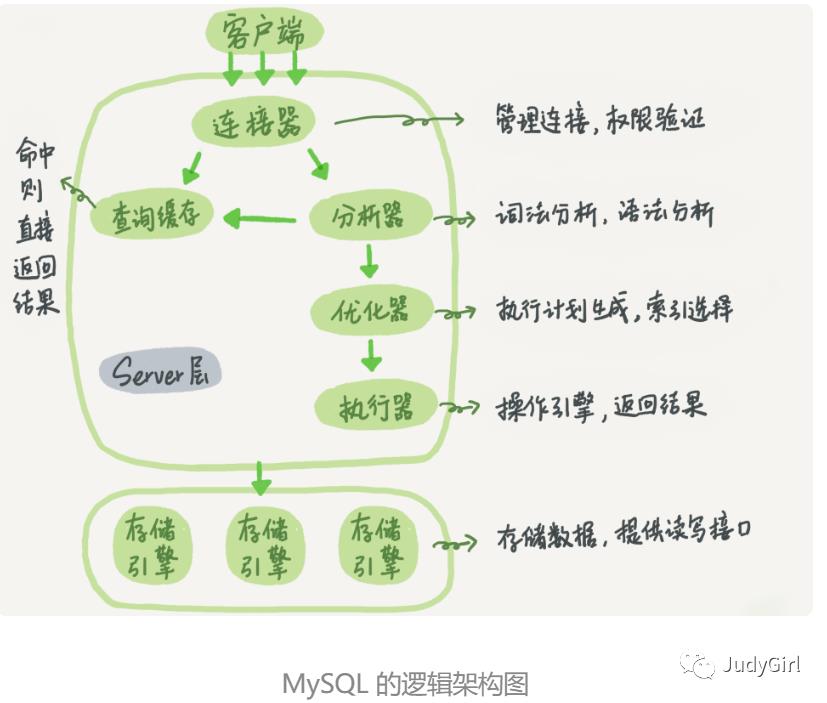
当提到这个问题的时候,我们应该思考的是MySQL的组织部分区域划分,看下面的MySQL逻辑架构图, 通过图我们从宏观划分server和存储引擎两部分。无论存储引擎使用的是MYSAM还是INNODB 对应的Server的逻辑都是相同的。
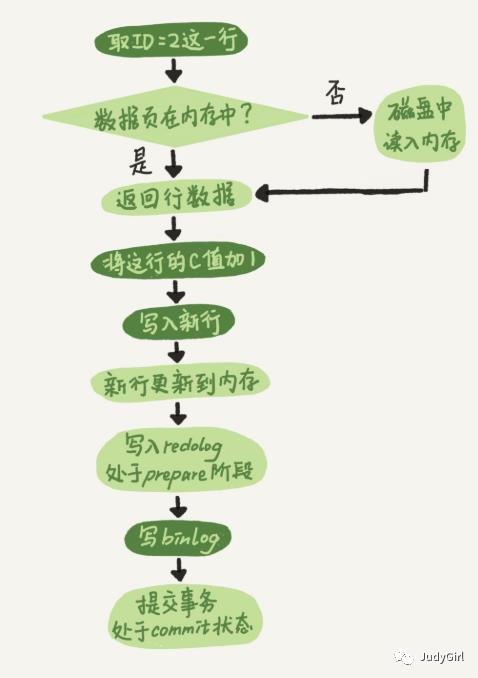
再讲解一条sql更新的过程,我们首先有两个名词需要大家明白,我会使用3W5H的学习讨论给大家讲解~
不知道你是否有一个疑惑, 为什么有bin.log 还会有redo.log 出现,下面我们一点点的解答疑问哦~
我在学习的时候看到一个栗子,假如餐厅可以赊账,掌柜是直接记录用户的赊的账,还是先查询一遍是否有存在的记录,然后再在原来的基础上进行累加?不用想肯定是后一种,所以推理到MYSQL 也是一样的,我们首先记录到日志中redo.log,等空闲的时候再更新到磁盘上,redo.log出现的原因是因为MYSQL本身是没有这种机制的,自带的存储引擎是Myisam,binlog本身只是用于做归档使用,redo.log只有在INNODB才可以使用,binlog日志是存在与Server层,所以无论什么存储引擎都可以使用。
1 redo.log是物理日志记录的是在某一页上做的修改是什么
2 binlog日志是逻辑日志,给某一个ID做了什么操作
1 先存储redo.log ,状态处于prepare状态
3 redo.log 状态更改为提交commit状态
从上面精简的介绍中我们可以看出redo.log 分为两种状态prepare和commit 这个过程叫做两阶段提交, 这个过程必须使用两阶段提交,保障数据的一致性,假设不适用两阶段提交,先执行redo.log 再执行 binlog,或者反过来,然后一方没有成功,最终都会导致数据不一致
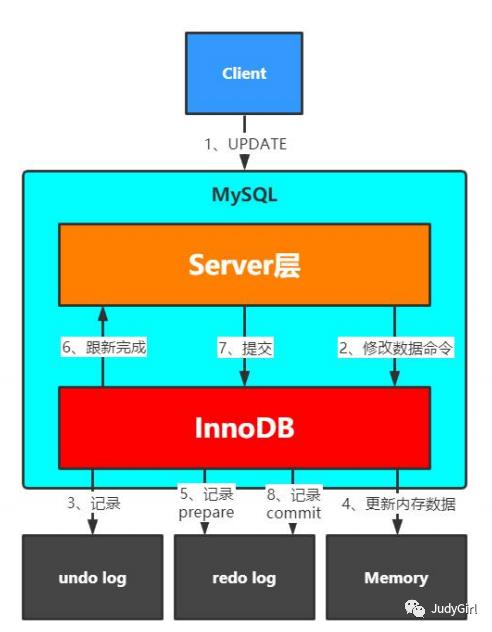
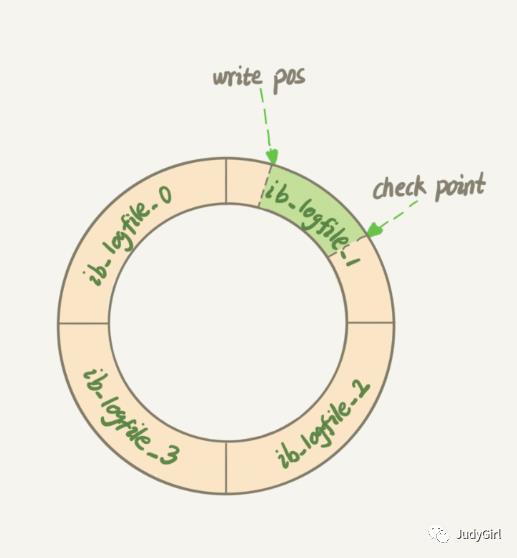
他的作用就是起到持久化,记录每一页修改的数据,他是循环写入文件,write pos:写入位置, Check point : 刷盘位置 ,write pos 到 check point之间的距离是待落盘数据。
通过上面的描述是否是对MySQL又亲近了一步,下面这一份也是mysql很重要的一部分哦。有一点需要提示,MYISAM是不支持事物的,INNODB支持事物。
提到事物不得不提的是ACID,东哥把他重新排列AIDC,嘻嘻我感觉这样排更加提现出他们的依次的作用,C:一致性是通过AID来进行保证的。
2 不可重复读 :A在第一次读和第二次读取的结果不一样
3 幻读:在解决不可重复读的情况下可能出现无法进行后续业务操作,例如B插入数据,但是A没有读取到,所以A在插入数据的时候会提示主键冲突问题。
因为出现并发的问题,所以我们通过不同等级的隔离级别来进行并发带来的问题。
3可重复读:一个事物从开始到结束都是读到想听内容,不可以读到其他事物提交的数据
3串行读 :在读和写的时候加上读锁和写锁,当读锁和写锁冲突的时候,事物必须等待另一个事物执行完成才可以继续执行。
读未提交:别人改数据的事务尚未提交,我在我的事务中也能读到。读已提交:别人改数据的事务已经提交,我在我的事务中才能读到。可重复读:别人改数据的事务已经提交,我在我的事务中也不能读。串行:我的事务尚未提交,别人就别想改数据。这4种隔离级别,并行性能依次降低,安全性依次提高。
我们知道了隔离级别的实现的效果,但是有没有想过隔离级别是如何实现的?
在MySQL中我们进行更新操作的时候都会记录一条回滚操作,通过回滚操作可以得到前一个状态的值
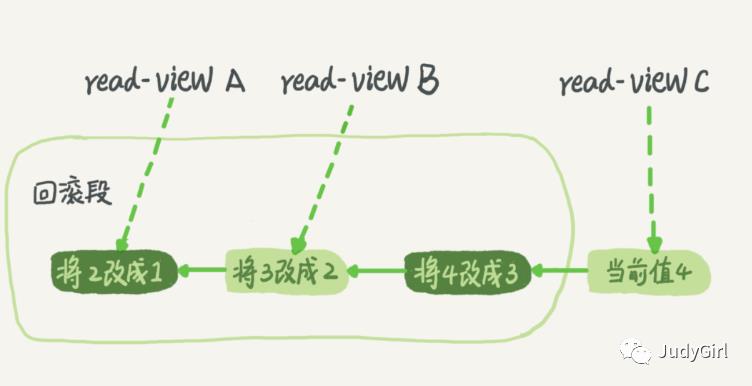
在ABC视图相当于数据库的多版本控制MVCC,可以多版本控制我们可以回滚到指定的视图 , 这也是为什么可以实现可重复读的原因
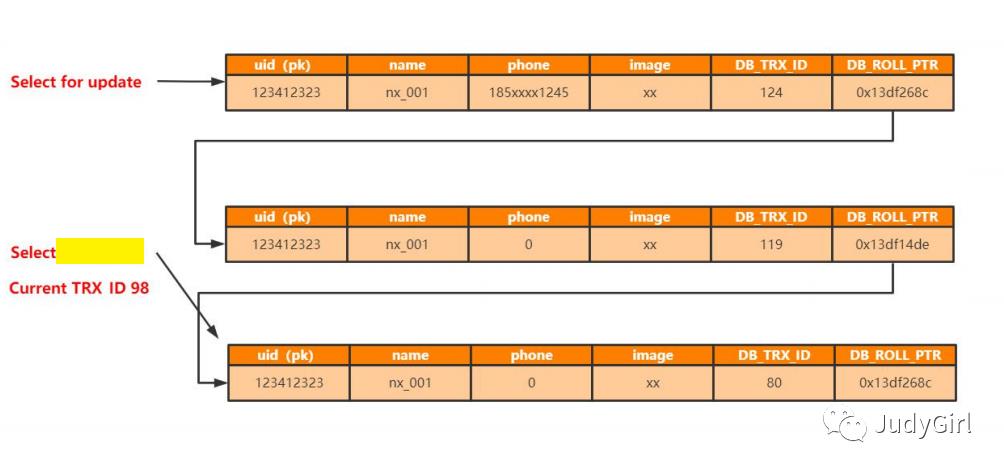
1 当前读:select for update 直接读当前数据就尅
2 快照读:指的就是
可重复读,根据事物id来判断当前的版本
2 判断事物ID是否比最大事物ID还要大,如果大则说明不可见,回退到上一个版本
3 是否在事物活跃列表中,表示事物没有提交,则不可见
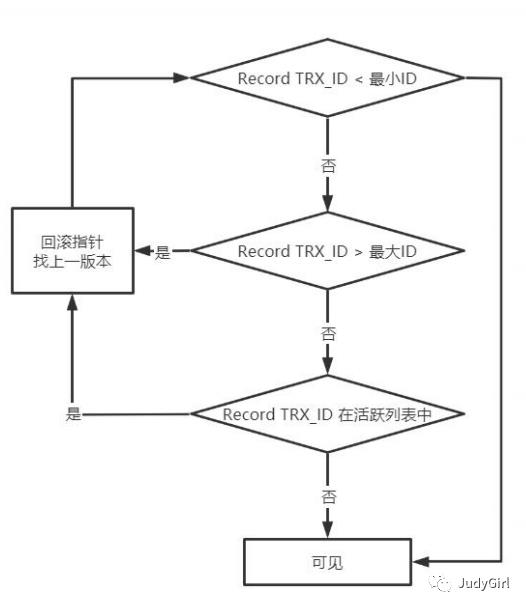
上面所说的都是思想,实现是由Undo.log来实现的。提供回滚,多个行版本控制MVCC,undo的意思为取消,以撤销操作为目的,返回指定某个状态的操作
mysql> create table T(id int primary key, k int not null, name varchar(16),index (k))engine=InnoDB;
(ID,k) 值分别为 (100,1)、(200,2)、(300,3)、(500,5) 和 (600,6),索引组织结构
索引类型分为主键索引和非主键索引,在INNODB中主键索引的叶子节点存储的行数据, 主键索引也叫做聚簇索引
非主键索引的叶子节点内容是主键值,非主键索引也叫做二级索引或者聚合索引
主键索引和非主键索引的区别?
非主键索引会产生回表操作, 例如 ,select * from judy where name =‘ju’, 先查询到索引id,然后再根据id查索引树,找到具体的值。这个过程叫做回表操作
覆盖索引
如果执行select id from judy where k between 3 and 5 ,这个时候只查询ID的值,并且ID的索引已经在索引树上,所以不用回表就可以查找到数据,覆盖索引的是索引k覆盖了我们查询需要也就是id,索引是覆盖索引
索引使用技巧
联合索引:优于独立索引,查找范围会缩小
索引顺序:选择性高的在前面
覆盖索引:二级索引存储主键值,减少回表次数
使用建议
数据库字符集使用UTF8mb4
VARCHAR按照实际需要分配长度
文本字段建议使用VACHAR
时间字段使用long
bool使用tinyint
枚举使用tinyint
禁止使用“%”前置查询
禁止在索引列上信息数学运算,索引会失效
(完)
以上是关于分布式架构数据存储设计与实践的主要内容,如果未能解决你的问题,请参考以下文章