聊聊线程模型:用户线程和内核线程
Posted 吉姆餐厅ak
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了聊聊线程模型:用户线程和内核线程相关的知识,希望对你有一定的参考价值。
概述
在以前的操作系统中,没有线程的概念。进程是资源分配和调度的最小单元。引入线程的概念以后,线程则是资源调度和分配的最小单元。引入线程的好处是可以提供并发量。在多核时代,一个进程可以做到真正的多线程并行。
线程又分为用户线程和内核线程。
用户线程:语言层面创建的线程,比如 java语言中多线程技术,通过语言提供的线程库来创建、销毁线程。
内核线程:内核线程又称为守护线程 或 Daemon线程,用户线程的运行必须依赖内核线程,通过内核线程调度器来分配到相应的处理器上。
多对一模型
用户级线程仅存在于用户空间中,此类线程的创建、撤销、线程之间的调度与通信,都无须通过内核来实现。用户进程利用语言层面提供的线程库来控制用户线程。由于线程在进程内切换的规则远比进程调度和切换的规则简单,不需要用户态/核心态切换,所以切换速度快。
优点:
在进程1中,线程的切换只需要依赖线程库,不需要依赖内核。相较于CPU在内核直接的切换,这种实现方式很轻量级,对系统资源消耗会小很多。所以,频繁的创建和销毁线程的成本也并不高。很明显,java中不是这么线程模型,java在使用线程时提倡避免创建和销毁线程。
缺点:
如果进程内的某一个线程发生阻塞,那整个进程就阻塞了。如上图,进程1绑定在内核线程1上,用户进程内只有线程2在运行。如果线程2阻塞,那整个进程1就阻塞了,因为内核并不知道线程1和线程3的存在。
一对一模型

在 1:1 模型中,启动一个用户线程,就会同时创建一个内核线程(注意,这里是启动线程,不是创建线程)。
每个用户线程在其整个生命周期内,都会被映射或绑定到一个内核线程上。当用户线程声明周期结束,两个线程则一起退出。无论是用户进程的线程,或者是系统进程的线程,他们的创建、撤销、切换都是依靠内核实现的。所以该模式下,CPU在线程的切换开销比较大。
Java 语言采用的便是这种线程模型。
优点:
1)在多处理器中,能够实现同一个进程中,多个线程同时并行。
2)当一个线程阻塞时,同一个进程中的其他线程可以继续运行,并发能力比较强。
缺点:
每个用户线程的启动和运行都必须创建一个内核线程,不适合频繁的创建和销毁。
多对多模型
多对多模型是从上面两种模型演进而来。线程创建完全在用户空间中完成,线程的调度和同步也在应用程序中进行. 一个应用程序中的多个用户级线程被映射到一些(小于或等于用户级线程的数目)内核级线程上。

如上图:线程1和线程2同时绑定到内核线程1上,如果线程1因为系统调用发生阻塞,进程1则会调度线程2执行,充分利用内核线程资源。多对多模型依赖自身调度与系统调度协同工作,而且并不是所有操作系统都支持多对多的混合模型,操作系统内核开发者一般不会使用,所以更多时候是作为第三方库的形式出现,而Go语言中的runtime调度器就是采用的这种实现方案。
协程
协程可以理解就是一种用户空间线程。拥有自己的寄存器上下文和栈。协程调度切换时,将寄存器上下文和栈保存到其他地方,在切回来的时候,恢复先前保存的寄存器上下文和栈,通过这种方式可以实现协程见的协作执行。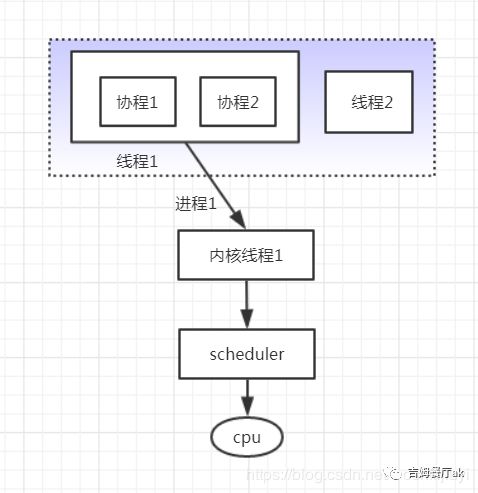
目前主流语言基本上都选择了多线程抢占式执行模型,抢占式调度执行顺序无法确定,所以使用线程时需要非常小心地处理同步问题,而协程完全不存在这个问题。协程可以由程序员自己写的调度策略,其通过协作而不是抢占来进行切换。另外协程是在用户态完成创建,切换和销毁,不需要绑定内核,成本相对较低。
用户线程和内核交互流程

其中第3、4、5、10步骤涉及到用户线程与内核交互:
3:应用程序收到响应。然后创建并启动用户线程来处理响应请求,同时也会创建一个内核线程,并将二者绑定。
4:系统调用。可以是网络io,也可以是磁盘io。这里是磁盘io。
5:内核调起驱动,查询磁盘数据并返回。
10:系统调用。应用程序处理完查询的数据之后,写入socket channel,进行返回。
总结
Java中的线程模型(1:1模型)之所以避免频繁创建线程,就是为了避免 cpu 在内核之间的切换。而 Go 语言中,如果用户线程发生阻塞,cpu 不需要切换内核线程,因为内核线程中有其他可运行的用户线程。

长按二维码关注
以上是关于聊聊线程模型:用户线程和内核线程的主要内容,如果未能解决你的问题,请参考以下文章