Flink开启流处理技术新潮流:解决流处理event time和消息乱序
Posted 神机喵算
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flink开启流处理技术新潮流:解决流处理event time和消息乱序相关的知识,希望对你有一定的参考价值。
写在之前:此文翻译自:,做了少许改动,感谢原作者。
摘要:速度是成功的一重要要素,流处理技术的速度使得其越来越受青睐。在现实世界中,数据产品总是以持续不断的处理面目示人,比如,web服务日志,移动应用用户行为,或者传感器数据。
到目前为止,大部分数据处理架构技术栈都建立在有限的、静态的数据假设之上。现代流处理技术在不断地努力,通过模拟和处理现实世界的event,而最理想的模拟情况是把数据看作“streams”。Flink不但实现“streams”流,而且具有开创性的技术点。本篇先来讲述Flink解决消息乱序和event time窗口。
消息乱序和event time窗口
在讨论解决消息乱序问题之前,需先定义时间和顺序。在流处理中,时间的概念有两个:
Event time :Event time是事件发生的时间,经常以时间戳表示,并和数据一起发送。带时间戳的数据流有,Web服务日志、监控agent的日志、移动端日志等;
Processing time :Processing time是处理事件数据的服务器时间,一般是运行流处理应用的服务器时钟。
许多流处理场景中,事件发生的时间和事件到达待处理的消息队列时间有各种延迟:
各种网络延迟;
数据流消费者导致的队列阻塞和反压影响;
数据流毛刺,即,数据波动;
事件生产者(移动设备、传感器等)离线;
上述诸多原因会导致队列中的消息频繁乱序。事件发生的时间和事件到达待处理的消息队列时间的不同随着时间在不断变化,这常被称为时间偏移(event time skew),表示成:“processing time – event time”。
对大部分应用来讲,基于事件的创建时间分析数据比基于事件的处理时间分析数据要更有意义。Flink允许用户定义基于事件时间(event time)的窗口,而不是处理时间。
Flink使用事件时间 clock 来跟踪事件时间,其是以watermarks来实现的。watermarks是Flink 源流基于事件时间点生成的特殊事件。 T 时间点的watermarks意味着,小于 T 的时间戳的事件不会再到达。Flink的所有操作都基于watermarks来跟踪事件时间。
下图描述Flink是如何计算事件时间窗口。当watermarks到达时窗口计算会被触发,并更新事件时间clock:
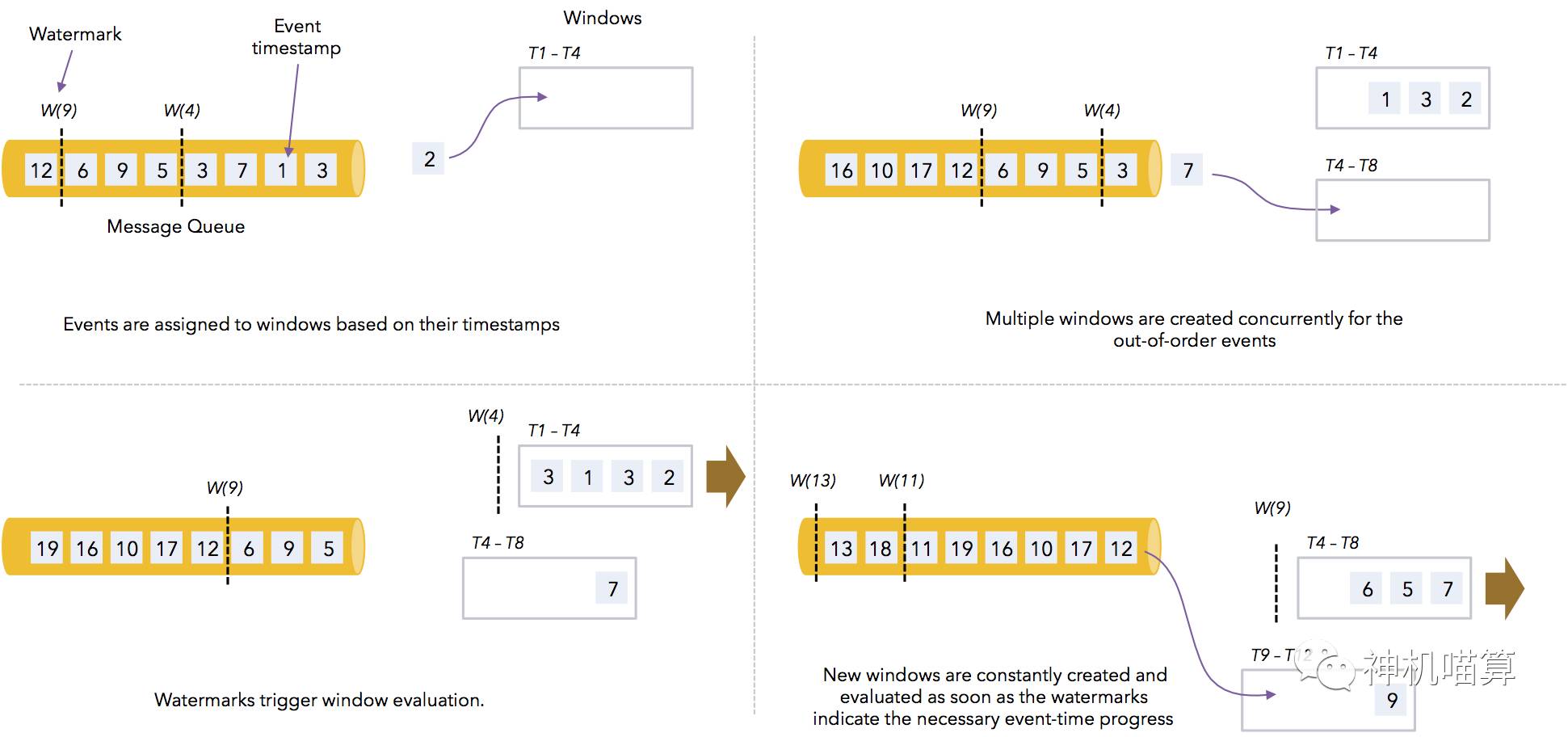
很明显,左上角watermarks W(4)快要到达,出现计算窗口T1-T4;右上角因为消息有乱序(事件时间为3的事件排在事件时间为7的后面),同时出现两个计算窗口T1-T4和T4-T8;左下角watermarks W(4)触发计算窗口演化,小于事件时间4的事件不再到达;右下角参考前面解读。
基于事件时间的Pipeline会产生更精确的结果,因为一旦有相应事件时间的事件到达会尽快计算;而相对于周期性的批量处理来讲,基于事件时间的数据流pipeline会更早的计算出结果,并且更精确(批量处理不能很好的处理跨batch的消息乱序)。
结合事件时间和实时pipeline
事件时间pipeline会因为必要的事件时间过程而导致一定的延迟。有时延迟太大导致无法获得实时结果,这时就得增加延迟短的结果。
Flink是一个流处理框架,能毫秒级处理事件,它能在同一个应用中综合低延迟的实时pipeline和事件时间pipeline,列子如下:
基于单个事件的低延迟报警。如果某类事件被识别,需要发出报警信息;
基于处理时间窗口的实时dashboard,能够聚合秒级的事件数;
基于事件时间的精确统计
/** * Main entry point. */ public static void main(String[] args) throws Exception { // create environment and configure it final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.registerType(Statistic.class); env.registerType(SensorReading.class); env.setParallelism(4); env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime); // create a stream of sensor readings, assign timestamps, and create watermarks DataStream<SensorReading> readings = env .addSource(new SampleDataGenerator()) .assignTimestamps(new ReadingsTimestampAssigner()); // path (1) - low latency event-at a time filter readings .filter(reading -> reading.reading() > 100.0) .map( reading -> "-- ALERT -- Reading above threshold: " + reading ) .print(); // path (2) - processing time windows: Compute max readings per sensor group // because the default stream time is set to Event Time, we override the trigger with a // processing time trigger readings .keyBy( reading -> reading.sensorGroup() ) .window(TumblingTimeWindows.of(Time.seconds(5))) .trigger(ProcessingTimeTrigger.create()) .fold(new Statistic(), (curr, next) -> new Statistic(next.sensorGroup(), next.timestamp(), Math.max(curr.value(), next.reading()))) .map(stat -> "PROC TIME - max for " + stat) .print(); // path (3) - event time windows: Compute average reading over sensors per minute // we use a WindowFunction here, to illustrate how to get access to the window object // that contains bounds, etc. // Pre-aggregation is possible by adding a pre-aggregator ReduceFunction readings // group by, window and aggregate .keyBy(reading -> reading.sensorId() ) .timeWindow(Time.minutes(1), Time.seconds(10)) .apply(new WindowFunction<SensorReading, Statistic, String, TimeWindow>() { @Override public void apply(String id, TimeWindow window, Iterable<SensorReading> values, Collector<Statistic> out) { int count = 0; double agg = 0.0; for (SensorReading r : values) { agg += r.reading(); count++; } out.collect(new Statistic(id, window.getStart(), agg / count)); } }) .map(stat -> "EVENT TIME - avg for " + stat) .print(); env.execute("Event time example"); }
Flink提供的窗口触发条件包括处理时间clock,事件时间clock,以及数据流内容。
Flink是如何度量时间?
下面看下Flink是如何处理时间的,在这点上与其它老的流处理系统有啥不同。
一般意义上讲,时间是用clock度量的。最简单的clock称为wall clock,它是集群中服务器执行流处理作业的间隔clock。wall clock是用来跟踪处理时间的。
为了跟踪事件时间,我们需要集群机器间相同的clock。Flink是通过watermarks机制实现的。一个watermarks是指在真实事件流时间点发生的事件(比如,上午10点),那么到现在为止上午10点前的事件不会再到达。事件时间clock(event time clock)跟踪时间比wall clock要粗粒度,但是更准确。
还有第三种clock,叫做system clock。它是用来保证流处理系统的“exactly-once“语义的。Flink跟踪作业的处理是通过barriers(栏栅),并进行snapshot。barriers与watermarks类似,不同之处在于,barriers是由Flink的master机器的wall clock 生成, 而watermarks是由真实世界的时间生成。同样,Spark Streaming的micro-batche schedule是基于Spark receiver的wall clock 。
下图完美展现刚才讲的各种时间:
Worker 1和Worker 2机器上并行执行对数据源和窗口的操作作业。事件上的数字代表时间戳,方块的颜色代表不同的key(灰色流向窗口1,紫色流向窗口2)。数据源从队列中读取事件(有分区,通过key分区),把他们分发到正确的窗口。窗口定义为基于事件时间的时间窗口(Flink包含时间窗口和count窗口)。我能看到Worker 1、Worker 2和Master机器的wall clock不同(缺乏时间同步,具体看ntp),分别为10,8,7。数据源发出watermarks,当前的watermarks时间戳为4。这意味着,event time clock是4,这时进行并行计算。Master(JobManager)对数据源做barriers,并对计算做snapshot。系统时间此时为7,checkpoint为第七个。
下面对流处理框架中的三种clock进行总结:
event time clock:度量事件流的时间,粗粒度;
system clock:度量计算的过程。实际上是协调者机器的wall clock;
wall clock :度量处理时间。
下面也给出老的流处理系统的弊端:
计算不准确:因为真实世界的事件发生顺序与处理的顺序经常不一致;
计算结果强依赖当前时间;
系统参数配置会影响程序的语义:比如,增加checkpoin的间隔。
老的流处理系统的这些缺点让它们没法获得准确的结果(至少是可控的准确度)。
而Flink完全分离这三种clock:
基于event time clock的watermarks跟踪事件流时间,允许用户定义基于事件时间的窗口;
system clock与event time clock完全解藕,跟踪计算过程和全局snapshot,不对外暴露api,仅仅用来分布式系统的协调;
处理时间是用的机器的wall clock,暴露给用户支持处理时间窗口。
相关文章:
以上是关于Flink开启流处理技术新潮流:解决流处理event time和消息乱序的主要内容,如果未能解决你的问题,请参考以下文章
Flink流处理API大合集:掌握所有flink流处理API技术,看这一篇就够了