Flink批处理中的增量迭代
Posted Flink
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flink批处理中的增量迭代相关的知识,希望对你有一定的参考价值。
前几天有网友咨询增量迭代的问题,答应发一篇文章,这篇还是很久之前写的,重新整理了一下~
对某些迭代而言并不是单次迭代产生的数据集的每个元素都需要重新参与下一轮迭代,有时只需要重新计算部分数据同时选择性地更新解集,这种形式的迭代就是增量迭代。增量迭代能够使得一些算法执行得更高效,它可以让算法专注于工作集中的“热点”数据部分,这导致工作集中的绝大部分数据冷却得非常快,因此随后的迭代面对的数据规模将会大幅缩小。增量迭代的示意图如下:
我们来梳理一下上图中的流程:
Iteration Input:从source或之前的运算符中读取的初始工作集与解集作为首次迭代的输入;
Step Function:也即步函数,将会在每次迭代时被执行。它可以是由map、reduce等运算符组成的任意数据流形成的逻辑体;
Next Workset/Update Solution Set:下一个工作集驱动着迭代计算并且将会被反馈给迭代头。除此之外,解集将会被更新并间接地向前推进。这两个数据集都可以通过步函数的不同的运算符进行更新;
Iteration Result:在最后一次迭代之后产生最终的解集被写入到sink或者被用于后续运算符的输入;
增量迭代可以指定三种终止条件:
空工作集收敛标准;
最大迭代次数;
自定义的聚合器收敛;
在1.1版本中,没有发现可定义收敛标准的地方;
跟批量迭代一样,对于增量迭代我们同样先结合案例来分析解决方案并给出代码实现。
现在给定一系列的事件以及它们两两之间的关联关系(连接起来是多个树结构),找到每个事件对应的根节点。事件之间的关联关系如下图:
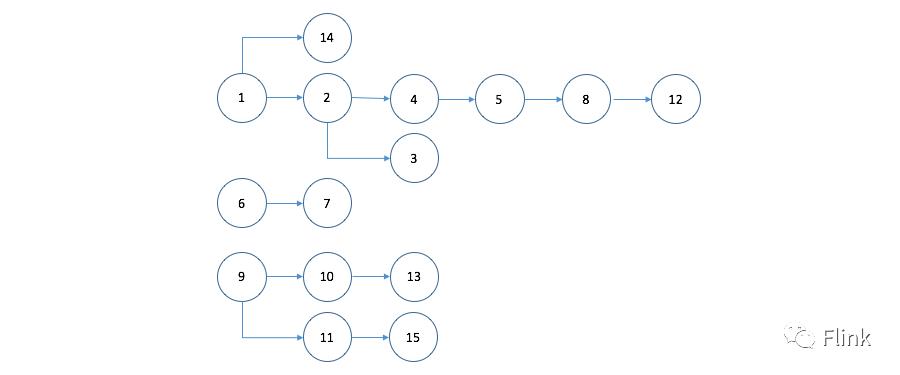
给定顶点数组和边数组作为输入,顶点和边都以二元组来表示。上图对应的顶点和边如下所示:
| Vertex | Edge |
|---|---|
| <1,1> | <1,2> |
| <2,2> | <2,3> |
| <3,3> | <2,4> |
| <4,4> | <4,5> |
| <5,5> | <6,7> |
| <6,6> | <5,8> |
| <7,7> | <9,10> |
| <8,8> | <9,11> |
| <9,9> | <8,12> |
| <10,10> | <10,13> |
| <11,11> | <1,14> |
| <12,12> | <11,15> |
| <13,13> | |
| <14,14> | |
| <15,15> |
最终我们期望得到的结果数据集如下,其中第一个元素表示事件编号,第二个元素表示对应的根节点编号:
| Final DataSet |
|---|
| <1,1> |
| <2,1> |
| <3,1> |
| <4,1> |
| <5,1> |
| <6,6> |
| <7,6> |
| <8,1> |
| <9,9> |
| <10,9> |
| <11,9> |
| <12,1> |
| <13,9> |
| <14,1> |
| <15,9> |
由于增量迭代比批量迭代更抽象、复杂,这里我们会将每个迭代步骤图形化,以方便理解。
首先第一步是初始化顶点数据集以及边数据集,这两个数据集中的元素就是上文我们第一个表格里的二元组集合,这里顶点的二元组集合同时也是增量迭代的工作集:
DataSet<Tuple2<Long, Long>> verticesAsWorkset = generateWorksetWithVertices(env);
DataSet<Tuple2<Long, Long>> edges = generateDefaultEdgeDataSet(env);接下来会构建一个增量迭代对象DeltaIteration的实例变量iteration,这里会以verticesAsWorkset作为初始化工作集,并指定最大迭代次数以及用于分区的键。
int vertexIdIndex = 0;
DeltaIteration<Tuple2<Long, Long>, Tuple2<Long, Long>> iteration = verticesAsWorkset
.iterateDelta(verticesAsWorkset, MAX_ITERATION_NUM, vertexIdIndex);别看这里区区两行代码,但其内部经历了一系列的初始化过程,示意如下图:

下文进行源码解读时,会看到iterateDelta方法会触发对初始解集的构建。
在上文我们阐述增量迭代原理时,我们知道在每次迭代过程中会执行步函数,增量迭代在步函数执行之后会产生增量解集(delta solution set),该增量解集会更新或者合并到解集中来。
接下来是一个完整的步函数,我们会将其进行拆分,第一步将工作集(顶点集合)与边集合进行连接:
DataSet<Tuple2<Long, Long>> delta = iteration.getWorkset()
.join(edges).where(0).equalTo(0)
.with(new NeighborWithParentIDJoin())对于连接所匹配的结果,将会应用一个特定的函数:NeighborWithParentIDJoin。该函数会对连接匹配上的顶点和边产生一个新的顶点元组,第一个字段是边的目的顶点,而第二个字段是匹配顶点的父顶点:
public static final class NeighborWithParentIDJoin implements
JoinFunction<Tuple2<Long, Long>, Tuple2<Long, Long>, Tuple2<Long, Long>> {
public Tuple2<Long, Long> join(Tuple2<Long, Long> vertexAndParent,
Tuple2<Long, Long> edgeSourceAndTarget) throws Exception {
return new Tuple2<Long, Long>(edgeSourceAndTarget.f1, vertexAndParent.f1);
}
}我们以事件编号1和事件编号2为例,展示连接的过程,图示如下:
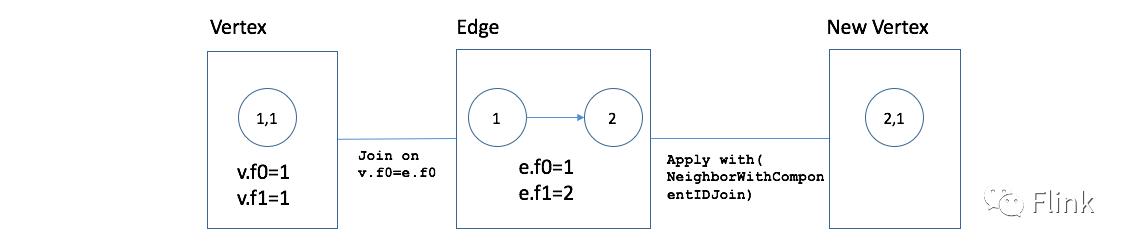
接下来,建立在上面连接产生的数据集的基础上跟解集进行连接,然后在连接产生的数据上应用FlatJoinFunction函数的实现:RootIdFilter。
DataSet<Tuple2<Long, Long>> delta = ......
.join(iteration.getSolutionSet()).where(0).equalTo(0)
.with(new RootIdFilter());
DataSet<Tuple2<Long, Long>> finalDataSet = iteration.closeWith(delta, delta);RootIdFilter是个过滤器的实现,它会对Join后的结果集进行过滤,它会选择性地输出源节点相同但父节点更小的节点元组。因为从以上树中元素的规律来看,父节点越小,越靠近真正的根节点。注意,它实现的是FlatJoinFunction函数,而不是JoinFunction函数。因为FlatJoinFunction支持输出零个或若干个元素(在这个案例里,该过滤器有可能不输出记录):
public static final class RootIdFilter implements FlatJoinFunction<Tuple2<Long, Long>,
Tuple2<Long, Long>, Tuple2<Long, Long>> {
public void join(Tuple2<Long, Long> candidate, Tuple2<Long, Long> old,
Collector<Tuple2<Long, Long>> collector) throws Exception {
if (candidate.f1 < old.f1) {
collector.collect(candidate);
}
}
}我们仍然以事件编号1及事件编号2作为示例,分析两个连接的过程。首先拿上一步新生成的顶点<2,1>跟解集进行连接(初始解集为原始的顶点数据集,随着迭代越接近最终的解集),以元组的第一个字段作为连接条件,在进行连接之后对于事件编号2产生两个元组,分别是<2,1>,<2,2>。再应用RootIdFilter过滤器,<2,2>被过滤而<2,1>被输出。该输出就对应着生产的delta。随后处于增量解集中的<2,1>会初始解集中的<2,2>进行替换。这段过程,图示如下:
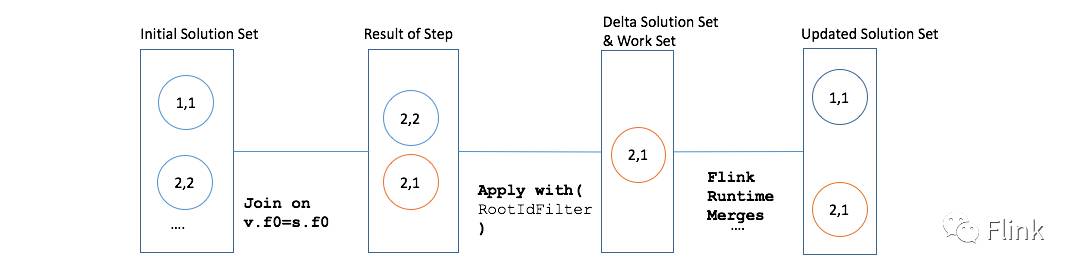
回过头来看这个完整的步函数,所产生的是一个增量解集delta(也就是RootIdFilter过滤后的输出,比如上面的<2,1>元组),它将会被更新到最终的解集。
增量迭代最终会调用closeWith方法来关闭一个迭代逻辑并得到最终的结果集finalDataSet。先解释一下closeWith的两个参数的含义:
solutionSetDelta:也即增量解集,在每次迭代之后,它将会被更新到解集中去;
newWorkset:新的工作集,它将会被反馈给下一次迭代作为输入;
这里得到的delta变量不仅仅是增量解集,同时也是新的工作集。所以上图中的<2,1>将会被用来更新<2,2>。
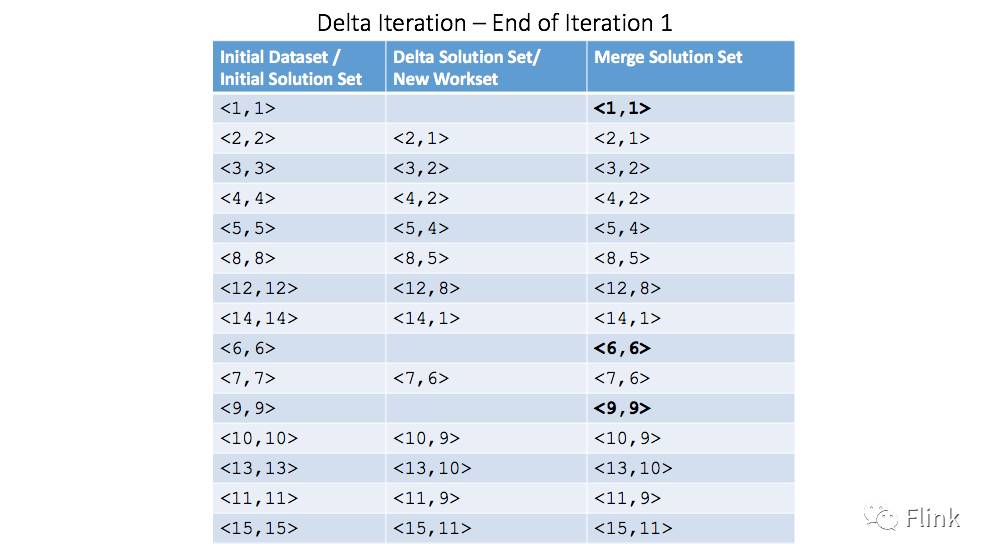
接下来,我们来分步展示迭代的执行过程以及各个数据集产生的变化。首先,第一次迭代之后:
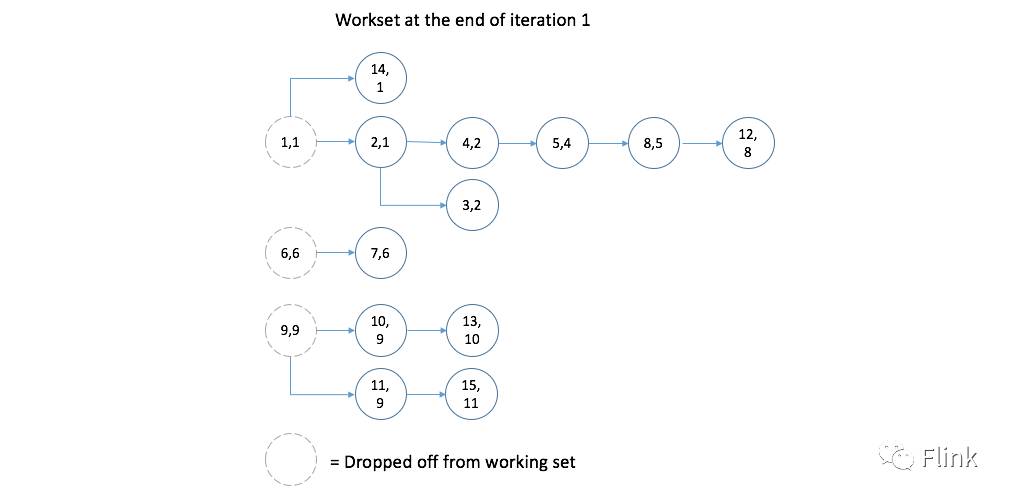
对应的数据集变化:
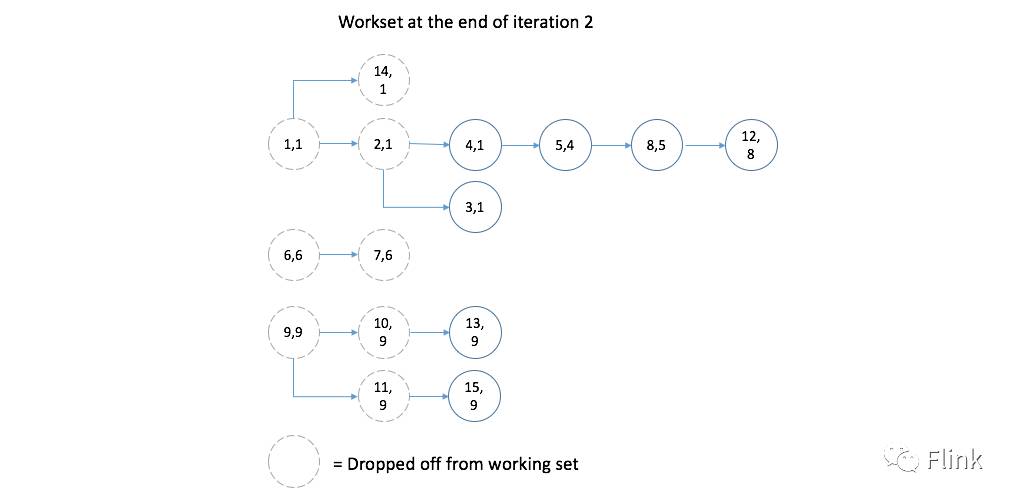
第二次迭代之后:
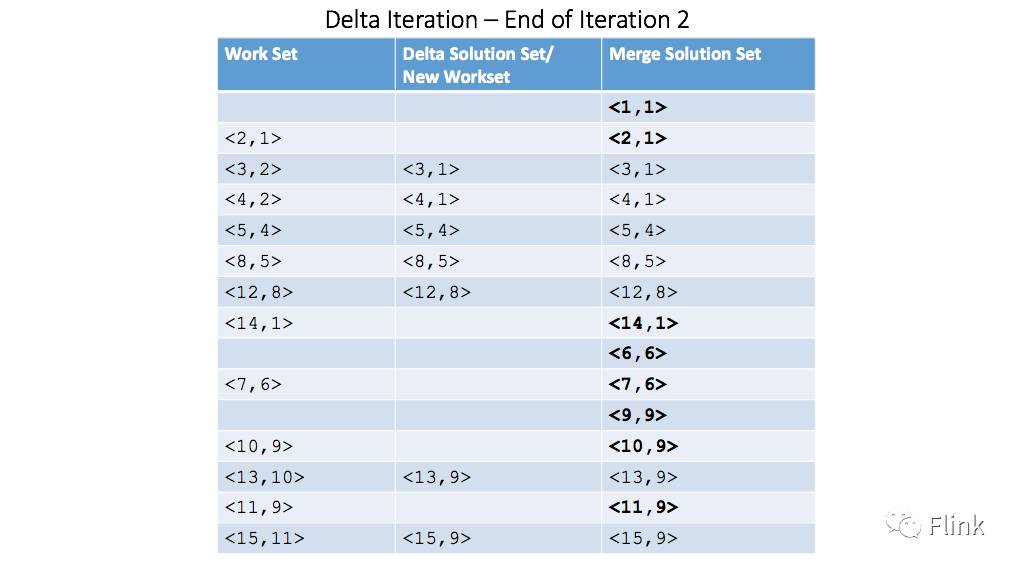
对应的数据集变化:
因篇幅受限,我们略去第三次、第四次迭代产生的变化图示,进入到第五次迭代后:
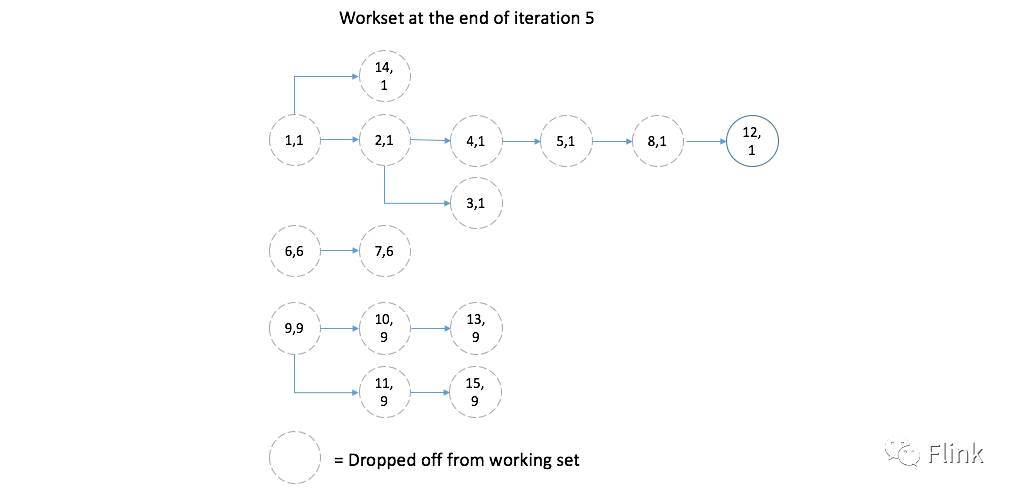
与此同时,数据集的变化:
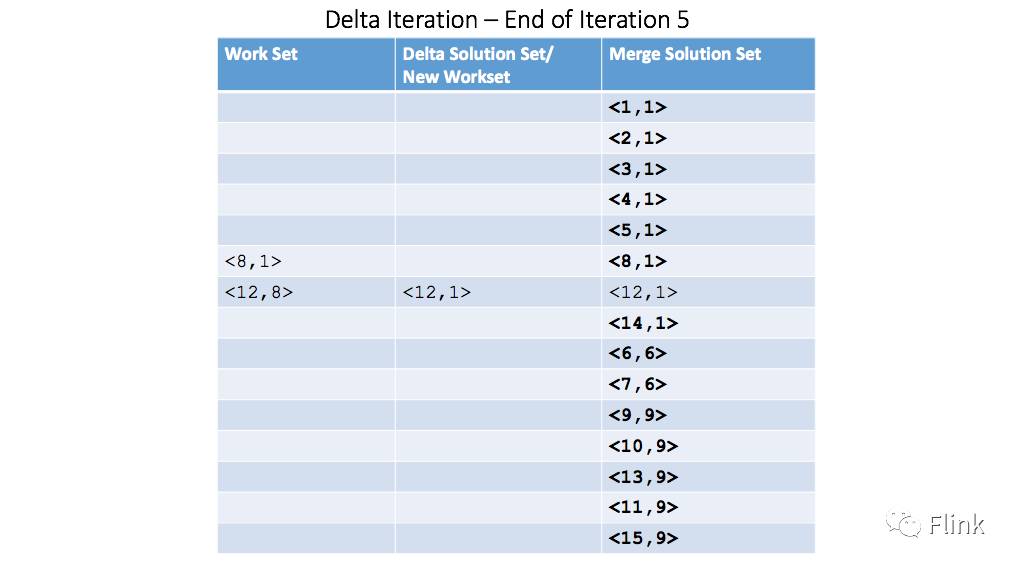
可以看到这里新的工作集已经逐渐减少到只剩下一个元组元素<12,1>。当执行完第六次迭代,工作集变为空:
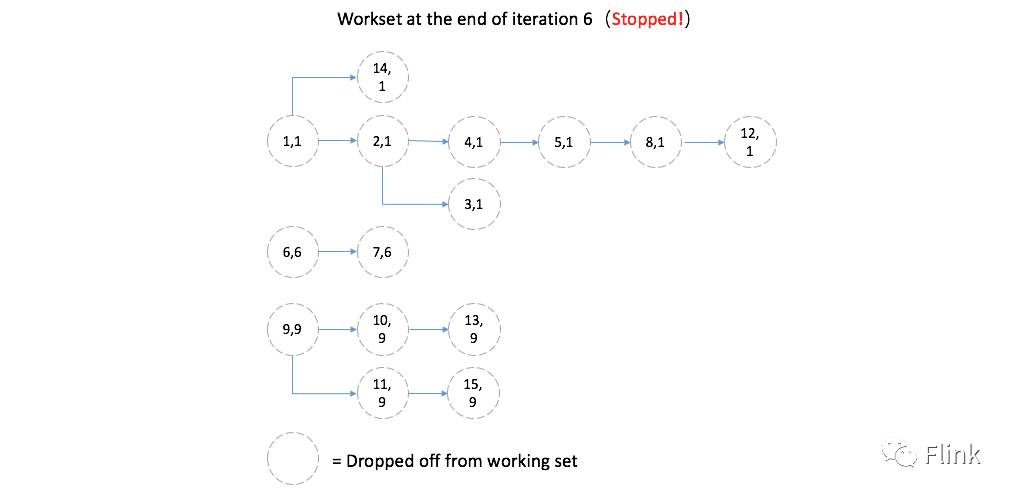
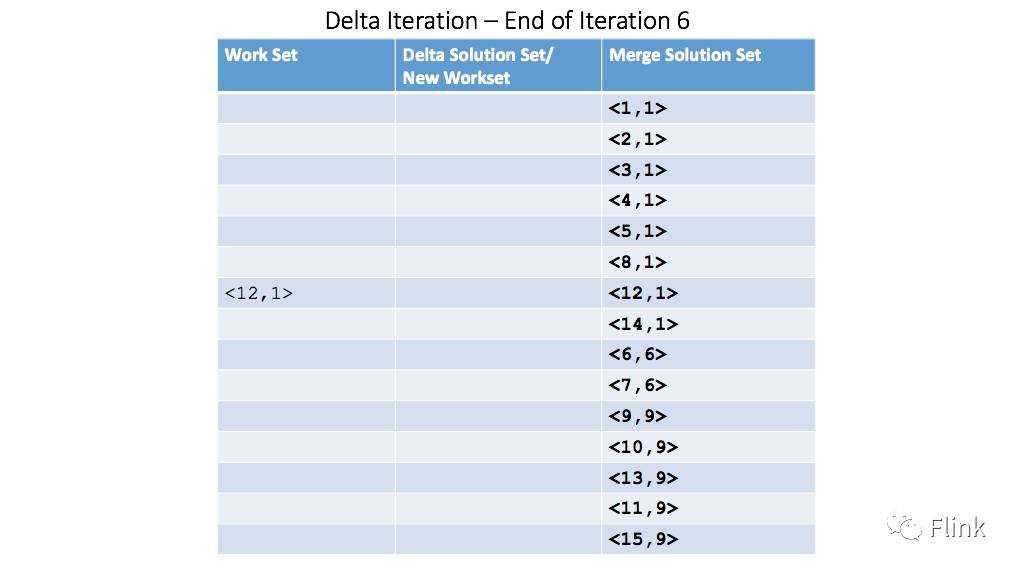
对应的新工作集为空,意味着增量迭代将会终止执行:
完整的实现代码如下:
public static void main(String[] args) throws Exception {
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
DataSet<Tuple2<Long, Long>> verticesAsWorkset = generateWorksetWithVertices(env);
DataSet<Tuple2<Long, Long>> edges = generateDefaultEdgeDataSet(env);
int vertexIdIndex = 0;
DeltaIteration<Tuple2<Long, Long>, Tuple2<Long, Long>> iteration = verticesAsWorkset
.iterateDelta(verticesAsWorkset, MAX_ITERATION_NUM, vertexIdIndex);
DataSet<Tuple2<Long, Long>> delta = iteration.getWorkset()
.join(edges).where(0).equalTo(0)
.with(new NeighborWithParentIDJoin())
.join(iteration.getSolutionSet()).where(0).equalTo(0)
.with(new RootIdFilter());
DataSet<Tuple2<Long, Long>> finalDataSet = iteration.closeWith(delta, delta);
finalDataSet.print();
}接下来我们分析一下增量迭代的API,由于增量迭代与批量迭代设计上的差异,它们的实现也迥然不同。增量迭代用DeltaIteration来表示迭代的数据集对象,而批量迭代用IterativeDataSet来表示。DeltaIteration是一个独立的类,而IterativeDataSet本质上是DataSet的特例。这两者都是通过DataSet的实例方法来进行初始化,IterativeDataSet通过iterate方法,而DeltaIteration则通过iterateDelta方法。
我们来看一段示例代码:
DeltaIteration<Tuple2<Long, Long>, Tuple2<Long, Long>> iteration =
initialState.iterateDelta(initialFeedbackSet, 100, 0);
DataSet<Tuple2<Long, Long>> delta = iteration.groupBy(0).aggregate(Aggregations.AVG, 1)
.join(iteration.getSolutionSet()).where(0).equalTo(0)
.flatMap(new ProjectAndFilter());
DataSet<Tuple2<Long, Long>> feedBack = delta.join(someOtherSet).where(...).equalTo(...).with(...);
// close the delta iteration (delta and new workset are identical)
DataSet<Tuple2<Long, Long>> result = iteration.closeWith(delta, feedBack);上述代码中initialState是DataSet的实例,iterateDelta以初始化一个DeltaIteration对象iteration。它接收三个参数:
initialFeedbackSet:它是DataSet的实例,表示参与迭代的初始数据集。在Flink中称之为工作集(workset);
100:整型值,表示最大迭代次数为100次;
0:元组中字段的下标,该下标所表示的字段将会作为解集的键;
解集是迭代所处的当前状态,通过iteration的getSolutionSet实例方法来进行访问的。解集从何而来?回到DeltaIteration类中,我们看到它内部封装了初始的工作集和初始的解集两个字段:
private final DataSet<ST> initialSolutionSet;
private final DataSet<WT> initialWorkset;它们都是通过DeltaIteration的构造器进行设置的。在DataSet的iterateDelta方法中,我们来看一下这两个参数所传递的值,代码如下:
public <R> DeltaIteration<T, R> iterateDelta(DataSet<R> workset,
int maxIterations, int... keyPositions) {
//...
return new DeltaIteration<>(getExecutionEnvironment(), getType(), this, workset, keys, maxIterations);
}从代码段可见,工作集对象是通过参数从外部传入,而初始的解集则为当前DataSet的实例(this引用)。因此对于上面的示例而言,初始的解集就是initialState对象,随着迭代的进行,步函数一轮轮被执行,解集也会被增量地更新从而向前演进,同时作为下一轮迭代的输入。
iteration通过对一系列转换函数的调用形成了任意数据流组成的步函数最终产生delta这一数据集。增量迭代跟批量迭代类似,都是通过迭代对象的closeWith方法来关闭迭代逻辑。跟批量迭代类似,这里的closeWith方法也返回表示增量迭代结果数据集DeltaIterationResultSet的实例,它也充当迭代尾的角色。
虽然我们没有应用到聚合器以及收敛标准,而是以空的工作集作为迭代的执行的终止条件。但是,在增量迭代中聚合器、收敛标准同样适用。
以上是关于Flink批处理中的增量迭代的主要内容,如果未能解决你的问题,请参考以下文章
flink 实现ConnectedComponents 连通分量,增量迭代算法(Delta Iteration)实现详解