对Flink的改进——Blink by 阿里巴巴
Posted Flink
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了对Flink的改进——Blink by 阿里巴巴相关的知识,希望对你有一定的参考价值。
本文是对阿里巴巴在最近刚刚过去的Hadoop Submit峰会上演讲的PPT解读。
PPT由Hadoop Submit官方在SlideShare上放出并开放下载。
1.主要应用场景在搜索上
2.演讲/参与人员简介

3.阿里及其搜索简介

4.议程

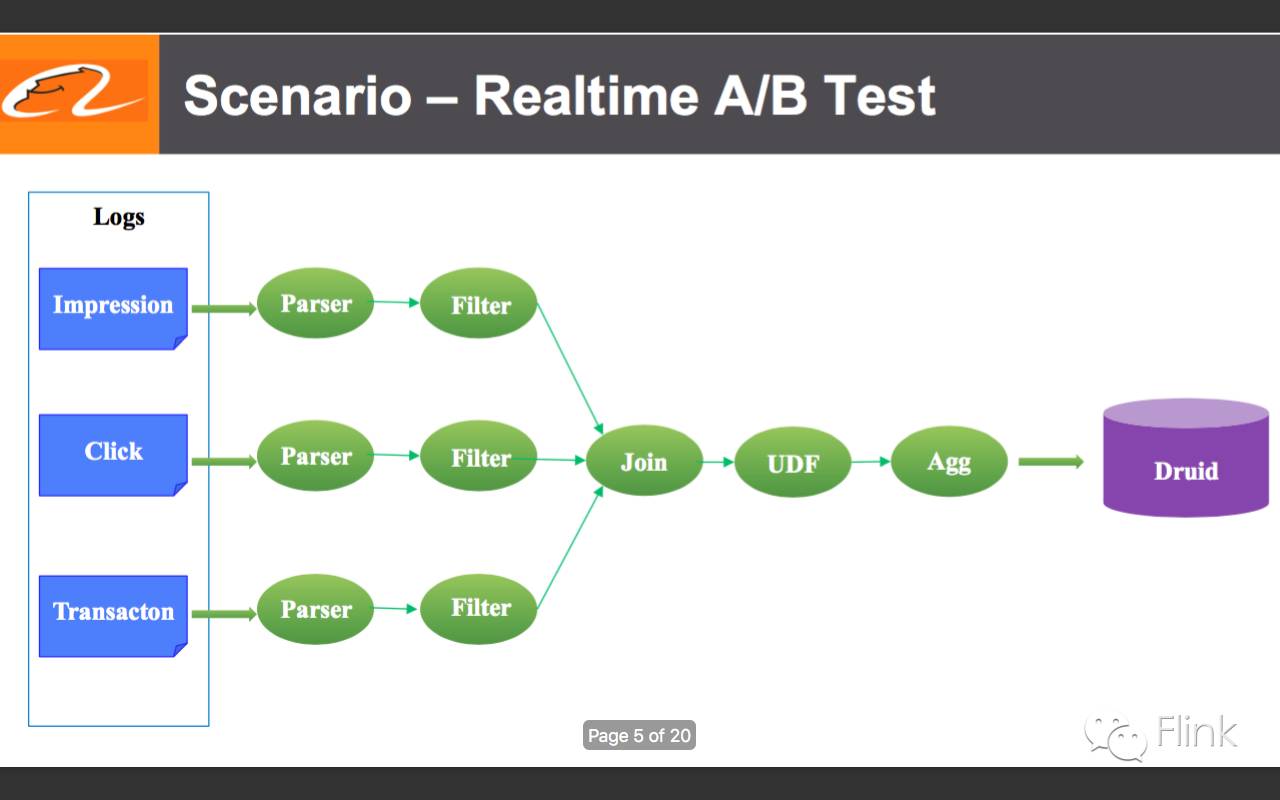
5.使用场景之一:实时A/B test;各种日志源的日志解析、过滤后进行计算最终数据打入Druid以供分析、查询。
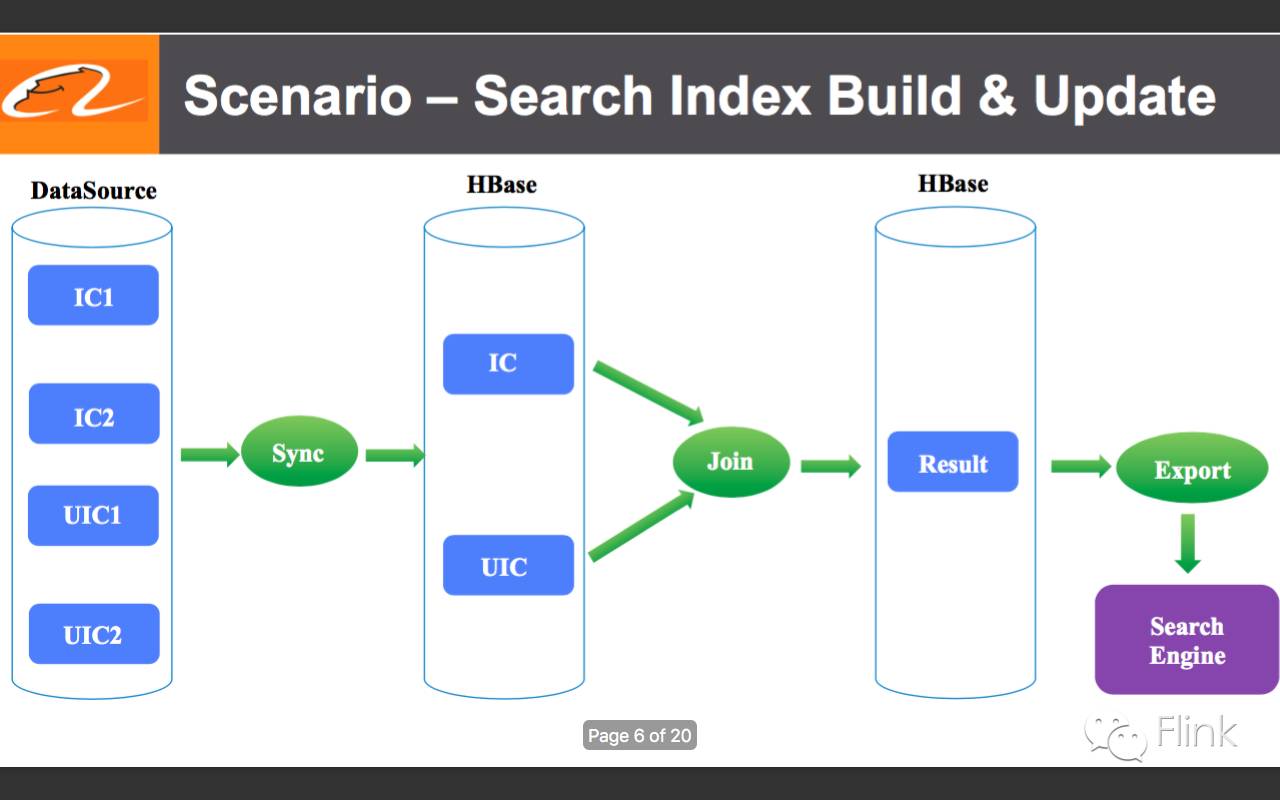
6.场景二:搜索的索引构建与更新。从数据库中将数据同步到HBase中,再从HBase中拉取多个有关联关系的数据流做join产生完整数据视图的数据流sink到HBase中,最终再将其导出到搜索引擎中去。
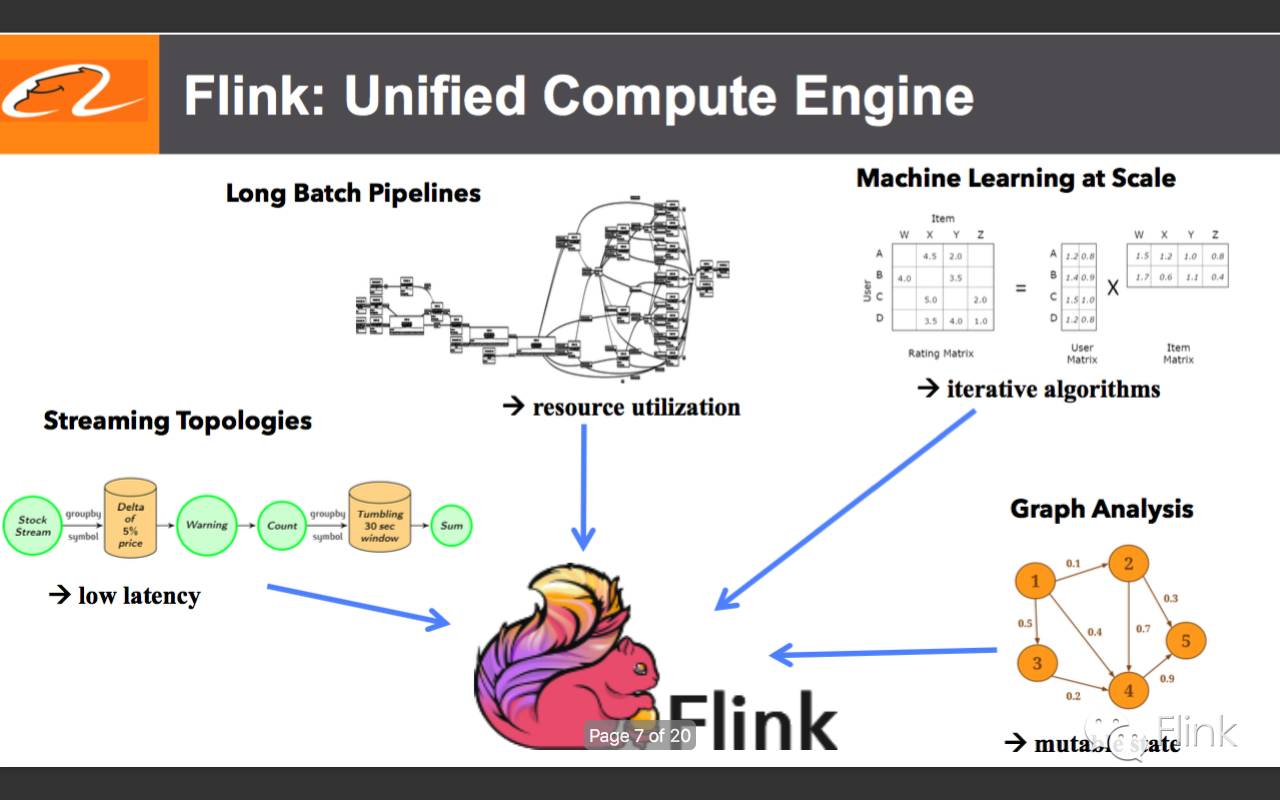
7.Flink简介:统一的(Batch&Streaming)计算引擎
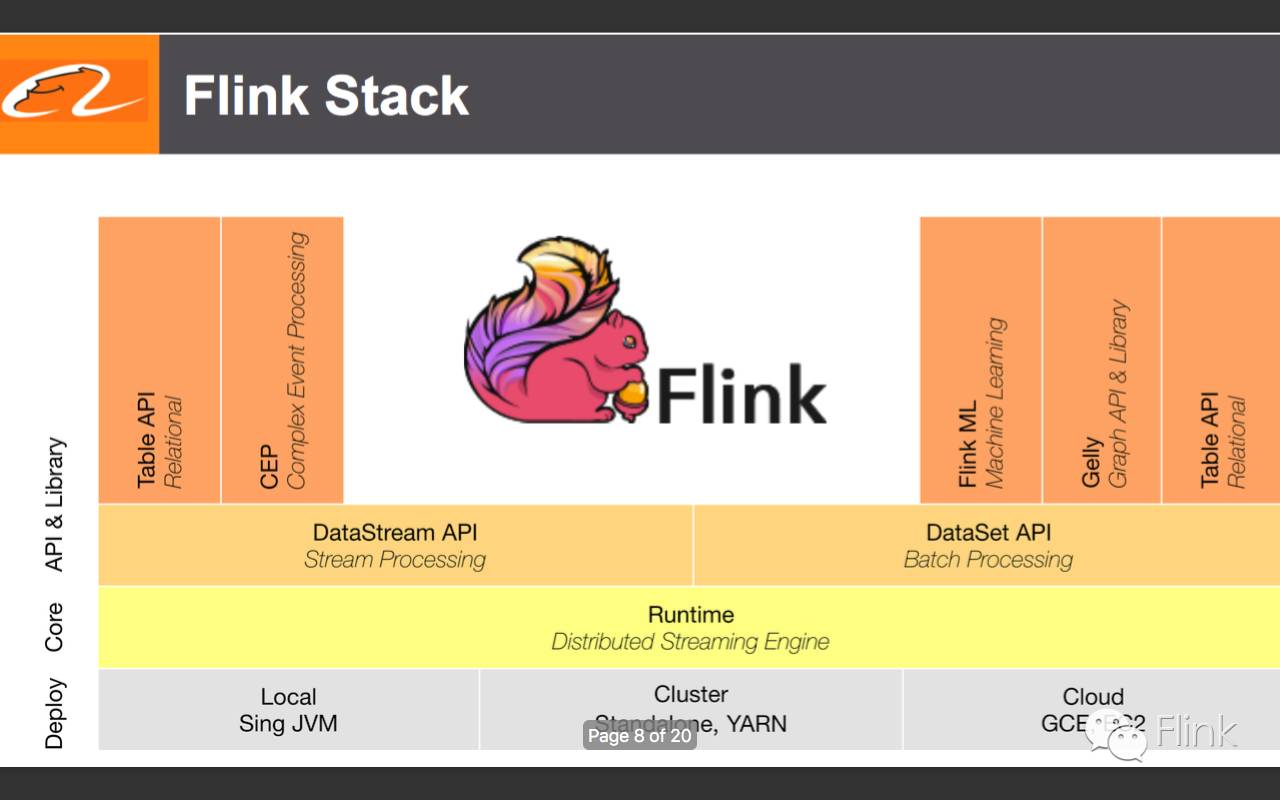
8.Flink软件栈(三个抽象层,这图Flink官网也有)
9.Blink简介。针对性地提升了Flink的Table API;增强了Flink API跟生态系统整合后运行时兼容性。

10.Table API的提升。目标对批处理和流处理提供统一的SQL层;哪些功能看图吧。不过Flink的SQL现在确实不成熟,比Spark SQL差远了。

11.运行时的哪些提升

12
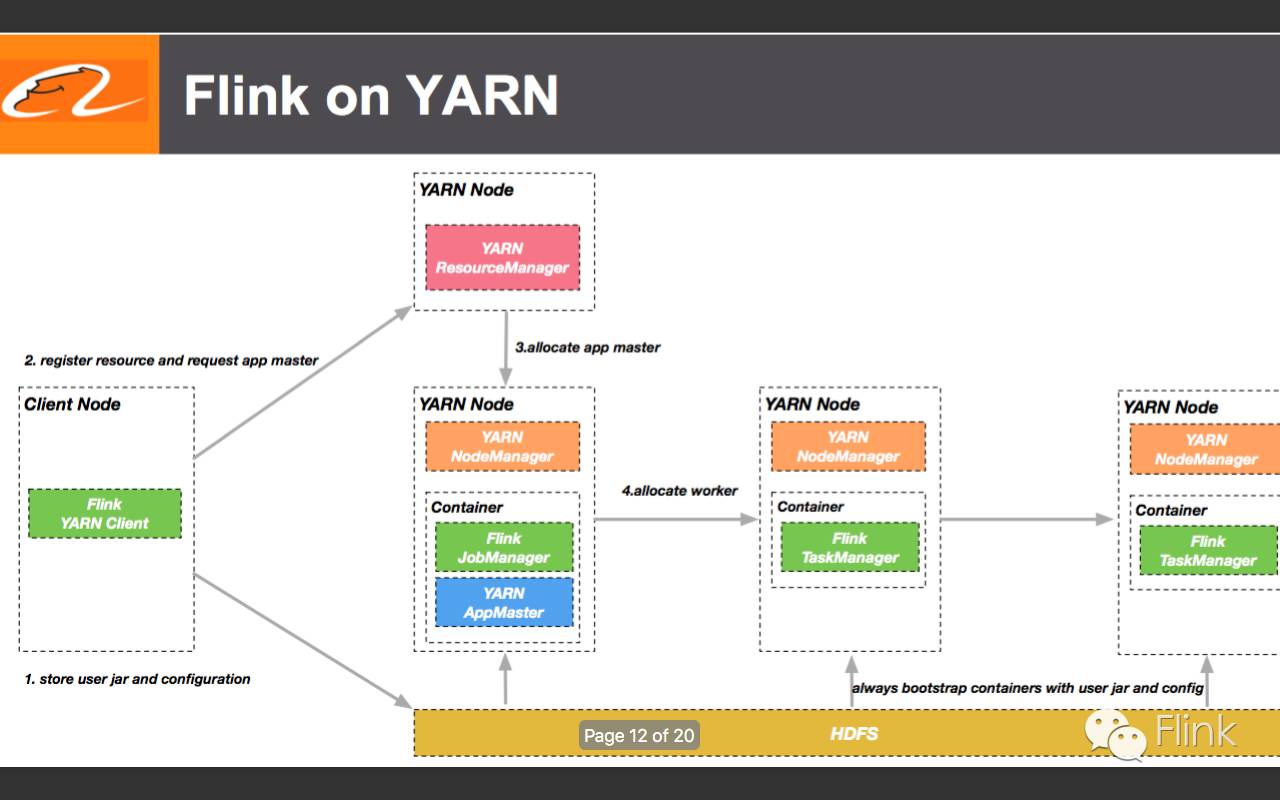
13.改进主要在第一个YARN NodeManager中的Container中,它将不再像Flink那样需要在JobManager所属的容器中跑一个AppMaster。
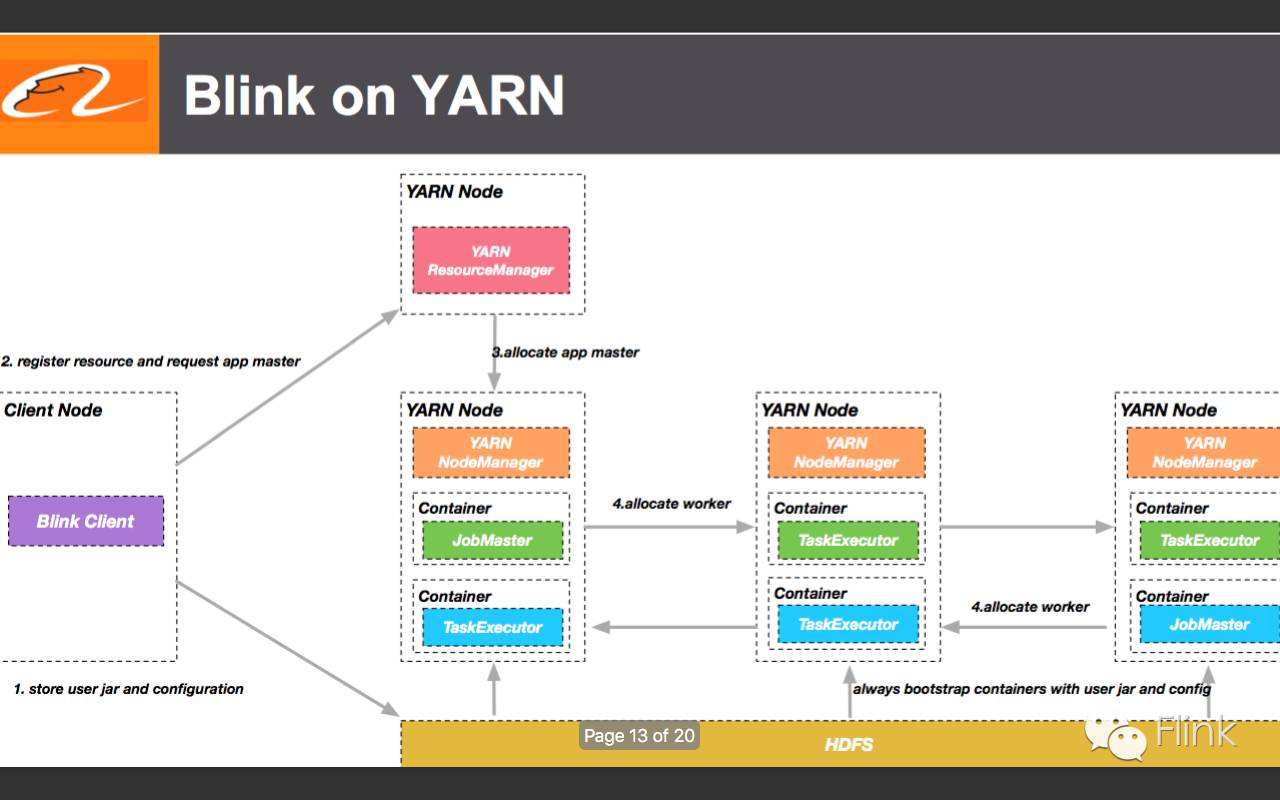
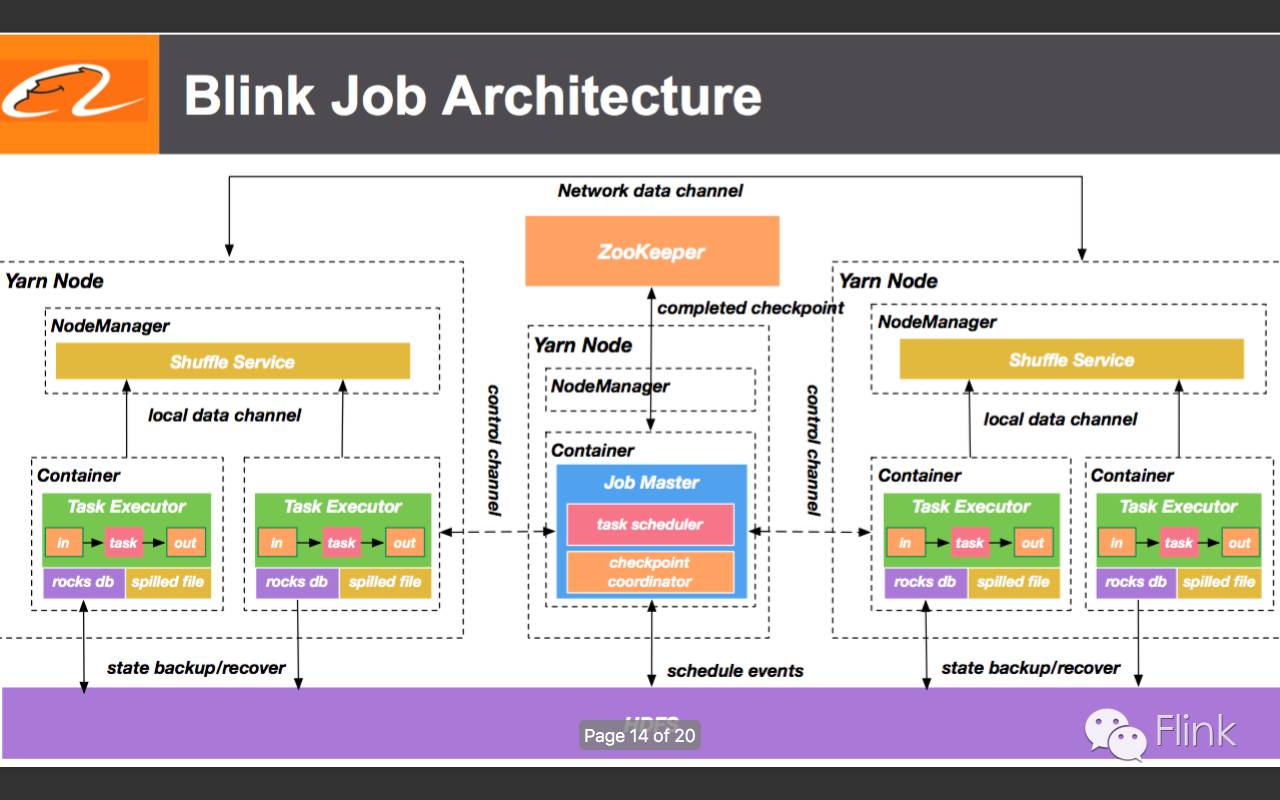
14.Blink on YARN Job架构(用RocksDB做state的backend,而HDFS作为RocksDB的文件系统)
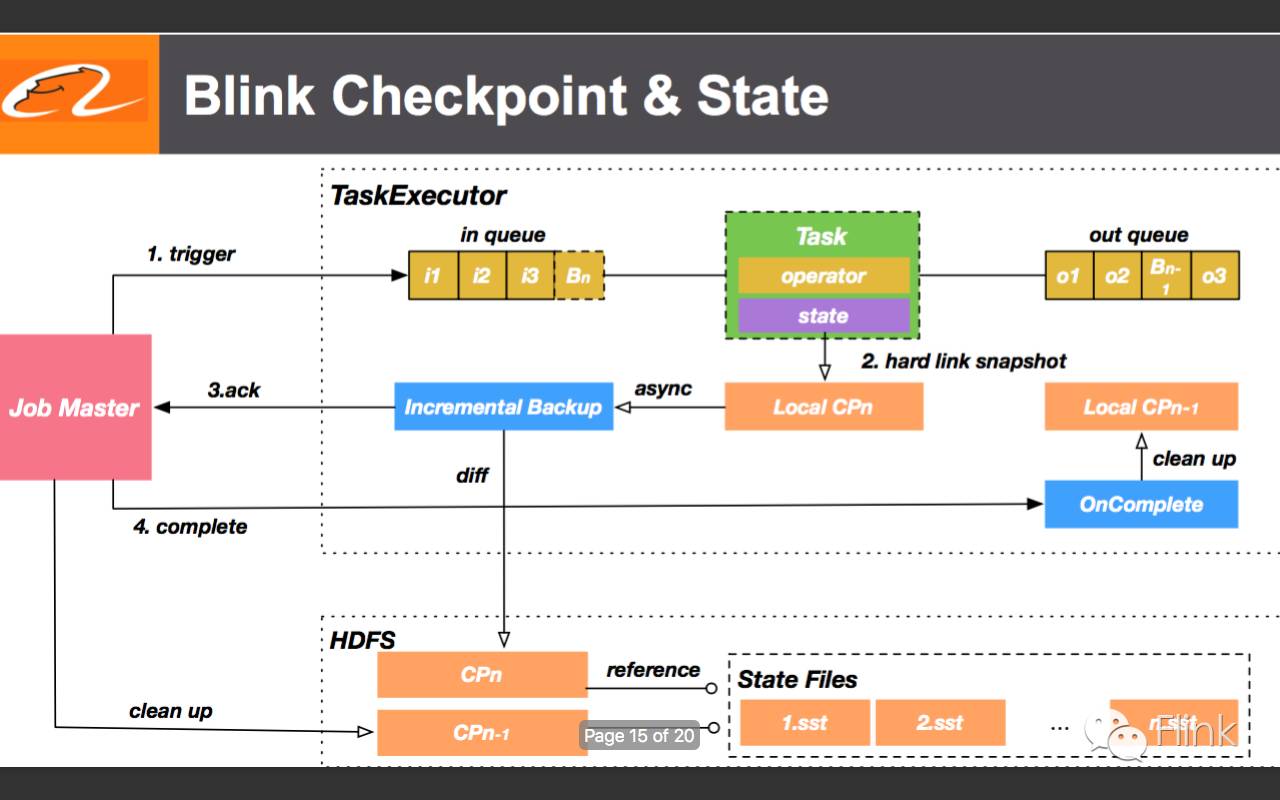
15.检查点和状态相关的改进(检查点状态数据的增量备份、状态数据的多检查点共享)
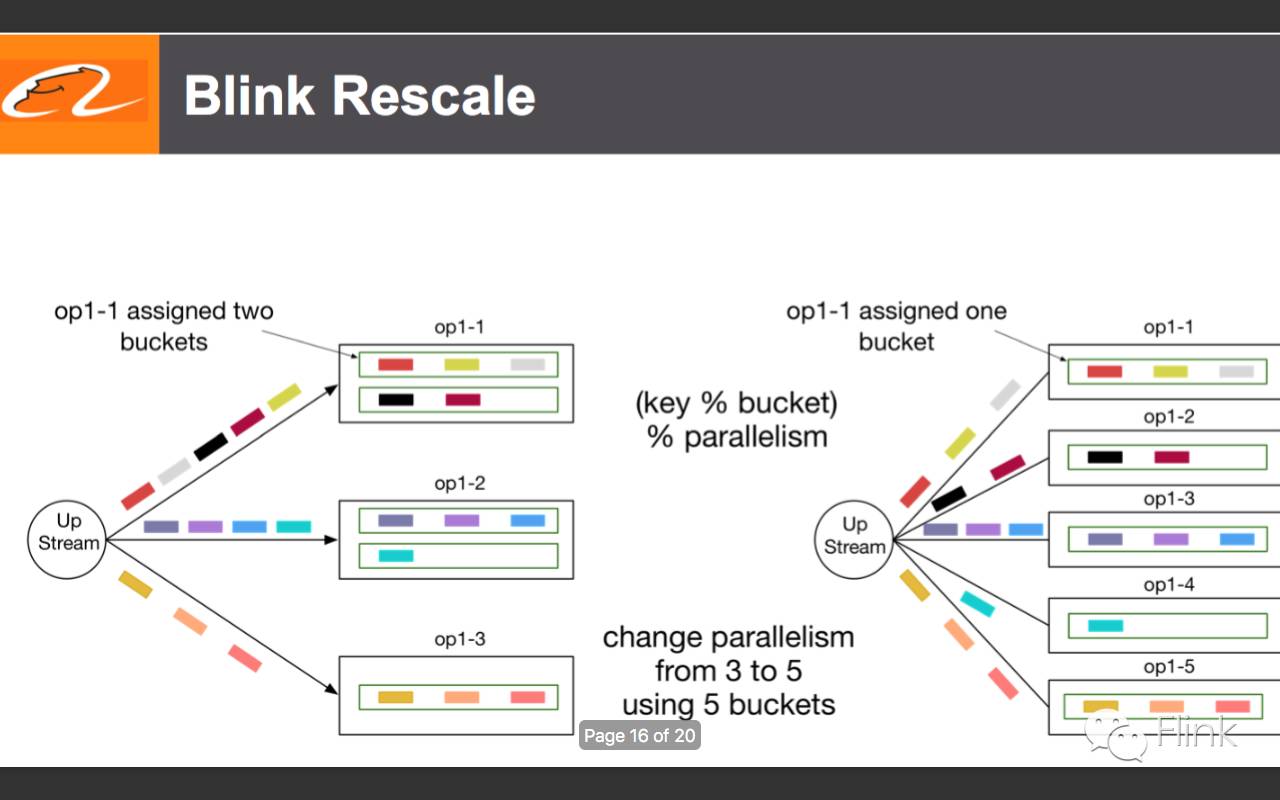
16.并行度改变引起的重新调整,调整某个特定分区的桶的数量
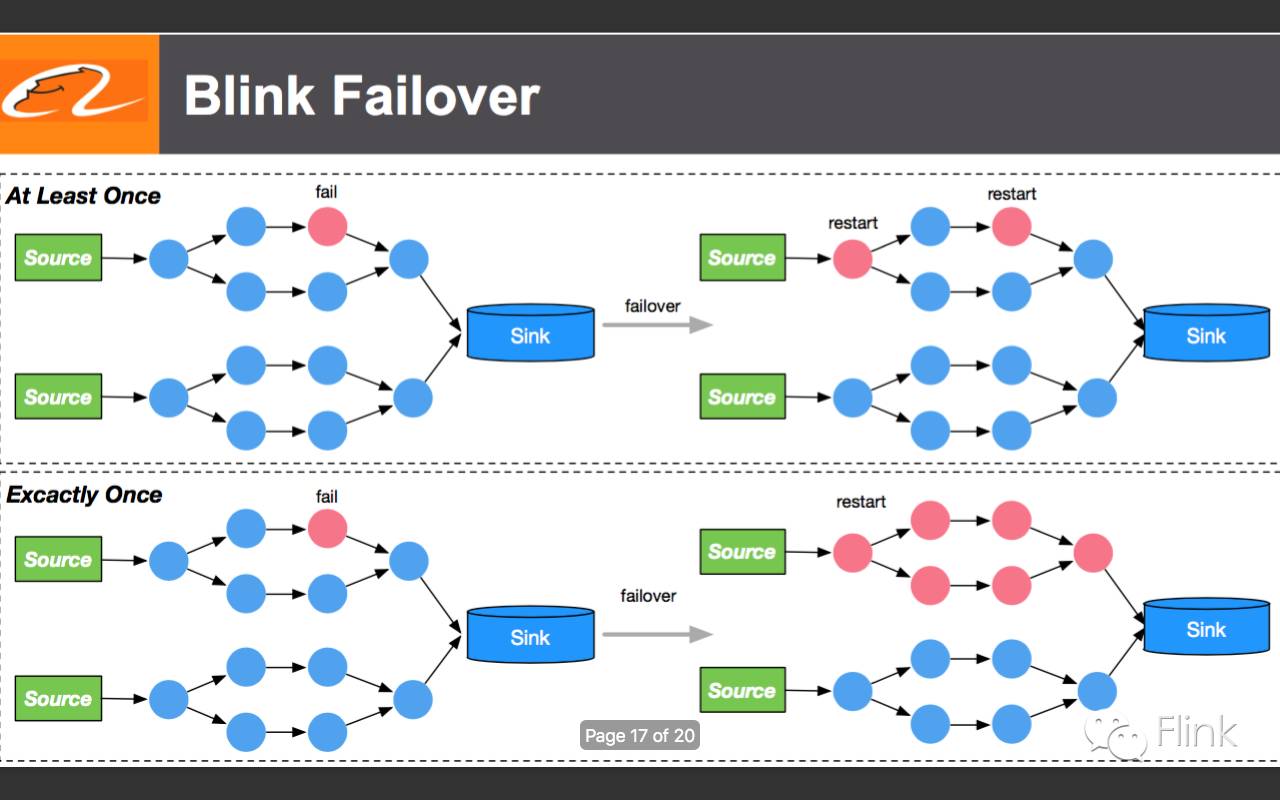
17.失败恢复(恰好一次场景下,失败的数据源整体replay?单从PPT看不出来)
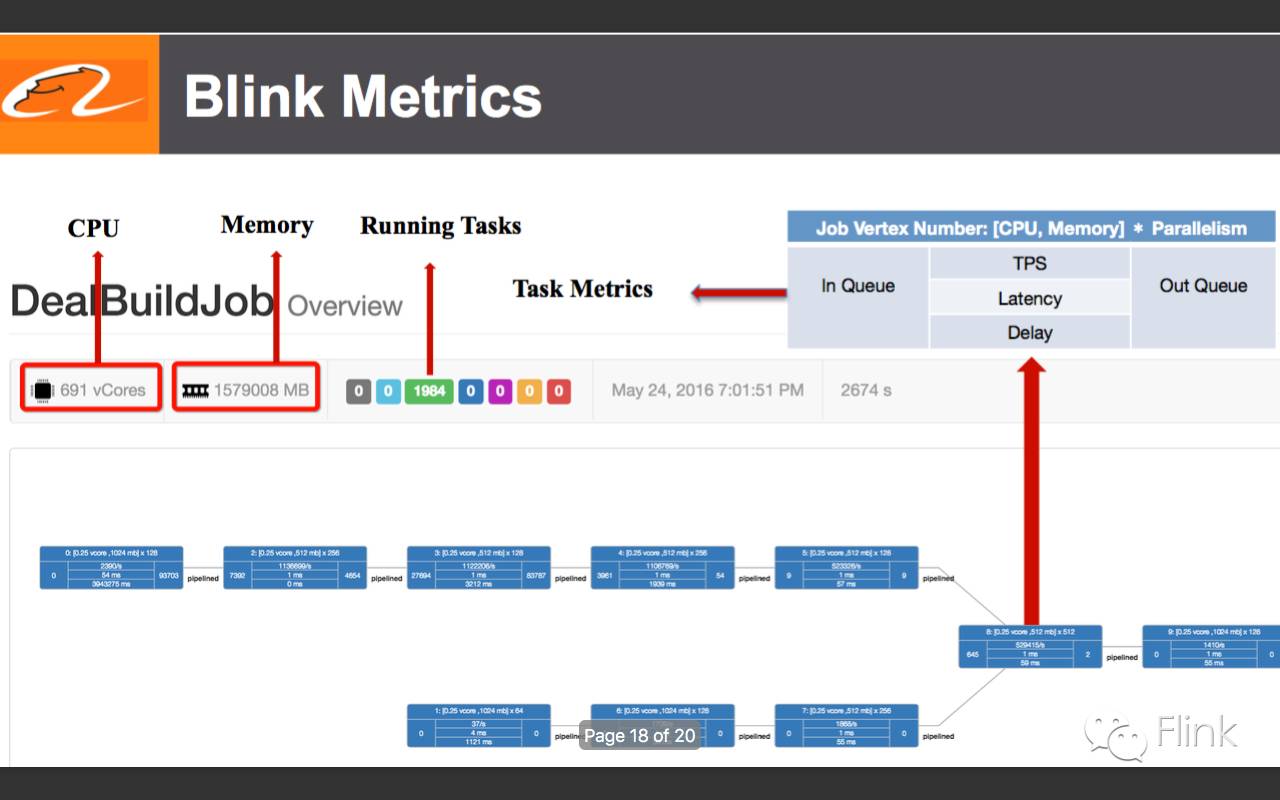
18.监控的增强(特别是单个task的详细metrics)
19.挑战&未来规划(提到回馈Flink)

20.Q&A
结束!
以上是关于对Flink的改进——Blink by 阿里巴巴的主要内容,如果未能解决你的问题,请参考以下文章
阿里正式向 Apache Flink 贡献 Blink 源码
终于等到你!阿里正式向 Apache Flink 贡献 Blink 源码