Flink StreamSQL 原理介绍
Posted 大数据和云计算技术
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flink StreamSQL 原理介绍相关的知识,希望对你有一定的参考价值。
前面群里面同学说对flink感兴趣,特别邀请资深流专家张如聪给大家深入分析下Flink里面最重要部分:Flink SQL。
本文对Flink SQL深入浅出,相当有深度的技术分析文章,希望大家会喜欢,对Flink技术上有疑问的也可以联系专家帮忙解答。
一、Flink SQL简介
Flink SQL 是Fllink提供的SQL的SDK API。SQL是比Table更高阶的API,集成在Table library中提供,在流和批上都可以用此API开发业务。本文主要侧重于SQL在Stream上的能力,也就是介绍StreamSQL的能力。
二、 StreamSQL能力概述
Flink SQL的语法采用Apache Calcite的语法.很多开源组件如Samza、Storm、Apex都使用Calcite的语法作为其SQL的语法。
在Flink 1.3.0版本中流上的操作支持SELECT, FROM, WHERE,UNION、聚合和自定义能力,join能力预计在Flink 1.4.0(预计在9月份发布)版本中提供。详细的语法能力,请参见第6章节。
三、用户使用StreamSQL开发业务流应用流程
在使用StreamSQL开发业务流应用前,需要在pom.xml增加引用flink-table lib的依赖,具体如下:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table_2.10</artifactId>
<version>1.2-SNAPSHOT</version></dependency>使用StreamSQL开发流应用的过程如下:
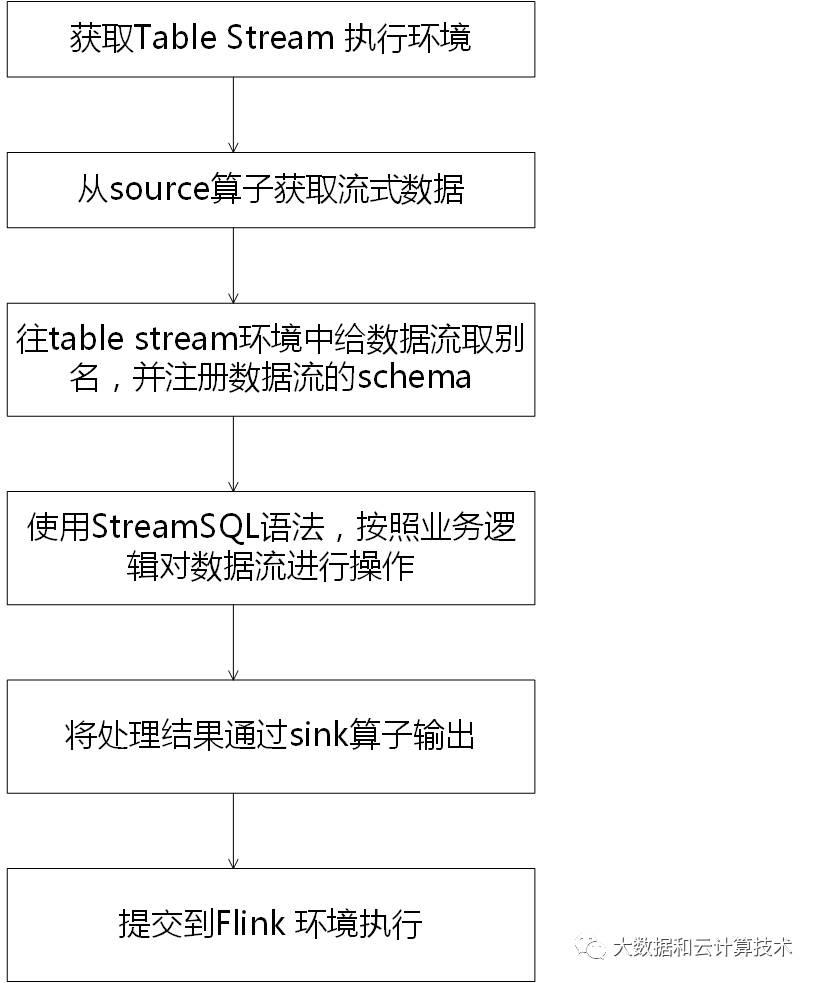
1、获取table stream 环境;
val env = StreamExecutionEnvironment.getExecutionEnvironment
val tEnv = TableEnvironment.getTableEnvironment(env)2、从source算子获取流式数据,并定义数据的schema:
val orderA: DataStream[Order] = env.fromCollection(Seq(
Order(1L, "beer", 3),
Order(1L, "diaper", 4),
Order(3L, "rubber", 2)))
tEnv.registerDataStream("OrderA", orderA, 'user, 'product, 'amount) 其中order类的定义为:
case class Order(user: Long, product: String, amount: Int)当前StreamSQL支持的source算子包含公共的kafka source、CSV file source,以及自定义的source。 3、用StreamSQL书写数据处理逻辑,即定义业务应用:
val result = tEnv.sql(
"SELECT * FROM OrderA WHERE amount > 2 + 3")4、定义处理结果的输出,即sink算子:
result.toAppendStream[Order].print()5、提交到Flink系统执行:
env.execute()四、StreamSQL 执行原理介绍

如上图所示,StreamSQL API的执行原理如下:
1、用户使用对外提供Stream SQL的语法开发业务应用;
2、用calcite对StreamSQL进行语法检验,语法检验通过后,转换成calcite的逻辑树节点;最终形成calcite的逻辑计划;
3、采用Flink自定义的优化规则和calcite火山模型、启发式模型共同对逻辑树进行优化,生成最优的Flink物理计划;
4、对物理计划采用janino codegen生成代码,生成用低阶API DataStream 描述的流应用,提交到Flink平台执行;
五、StreamSQL 编译执行流程介绍

1、使用calcite对Sql进行编译,在编译的过程中对语法进行校验,如果语法符合要求,编译结果为calcite的一个逻辑树,如:第四章节中的SQL“SELECT * FROM OrderA WHERE amount > 2 + 3”编译后为:
LogicalFilter(condition=[>($2, 2+3)])
LogicalTableScan(table=[[DataStreamTable1]])2、首先用如下规则集将table scan节点转化为关系表达式。
val TABLE_CONV_RULES: RuleSet = RuleSets.ofList(
TableScanRule.INSTANCE,
EnumerableToLogicalTableScan.INSTANCE)3、再用如下规则集,将逻辑计划树标准化。
val DATASET_NORM_RULES: RuleSet = RuleSets.ofList(
// simplify expressions rules
ReduceExpressionsRule.FILTER_INSTANCE,
ReduceExpressionsRule.PROJECT_INSTANCE,
ReduceExpressionsRule.CALC_INSTANCE,
ReduceExpressionsRule.JOIN_INSTANCE,
ProjectToWindowRule.PROJECT,
// Transform window to LogicalWindowAggregate
DataSetLogicalWindowAggregateRule.INSTANCE,
WindowStartEndPropertiesRule.INSTANCE
)4、再使用如下规则,将逻辑树进行优化,生成最优的逻辑计划树.
val LOGICAL_OPT_RULES: RuleSet = RuleSets.ofList(
// push a filter into a join
FilterJoinRule.FILTER_ON_JOIN,
// push filter into the children of a join
FilterJoinRule.JOIN,
// push filter through an aggregation
FilterAggregateTransposeRule.INSTANCE,
// aggregation and projection rules
AggregateProjectMergeRule.INSTANCE,
AggregateProjectPullUpConstantsRule.INSTANCE,
// push a projection past a filter or vice versa
ProjectFilterTransposeRule.INSTANCE,
FilterProjectTransposeRule.INSTANCE,
// push a projection to the children of a join
ProjectJoinTransposeRule.INSTANCE,
// merge projections
ProjectMergeRule.INSTANCE,
// remove identity project
ProjectRemoveRule.INSTANCE,
// reorder sort and projection
SortProjectTransposeRule.INSTANCE,
ProjectSortTransposeRule.INSTANCE,
// join rules
JoinPushExpressionsRule.INSTANCE,
// remove union with only a single child
UnionEliminatorRule.INSTANCE,
// convert non-all union into all-union + distinct
UnionToDistinctRule.INSTANCE,
// remove aggregation if it does not aggregate and input is already distinct
AggregateRemoveRule.INSTANCE,
// push aggregate through join
AggregateJoinTransposeRule.EXTENDED,
// aggregate union rule
AggregateUnionAggregateRule.INSTANCE,
// expand distinct aggregate to normal aggregate with groupby
AggregateExpandDistinctAggregatesRule.JOIN,
// reduce aggregate functions like AVG, STDDEV_POP etc.
AggregateReduceFunctionsRule.INSTANCE,
// remove unnecessary sort rule
SortRemoveRule.INSTANCE,
// prune empty results rules
PruneEmptyRules.AGGREGATE_INSTANCE,
PruneEmptyRules.FILTER_INSTANCE,
PruneEmptyRules.JOIN_LEFT_INSTANCE,
PruneEmptyRules.JOIN_RIGHT_INSTANCE,
PruneEmptyRules.PROJECT_INSTANCE,
PruneEmptyRules.SORT_INSTANCE,
PruneEmptyRules.UNION_INSTANCE,
// calc rules
FilterCalcMergeRule.INSTANCE,
ProjectCalcMergeRule.INSTANCE,
FilterToCalcRule.INSTANCE,
ProjectToCalcRule.INSTANCE,
CalcMergeRule.INSTANCE,
// scan optimization
PushProjectIntoTableSourceScanRule.INSTANCE,
PushFilterIntoTableSourceScanRule.INSTANCE,
// Unnest rule
LogicalUnnestRule.INSTANCE,
// translate to flink logical rel nodes
FlinkLogicalAggregate.CONVERTER,
FlinkLogicalWindowAggregate.CONVERTER,
FlinkLogicalOverWindow.CONVERTER,
FlinkLogicalCalc.CONVERTER,
FlinkLogicalCorrelate.CONVERTER,
FlinkLogicalIntersect.CONVERTER,
FlinkLogicalJoin.CONVERTER,
FlinkLogicalMinus.CONVERTER,
FlinkLogicalSort.CONVERTER,
FlinkLogicalUnion.CONVERTER,
FlinkLogicalValues.CONVERTER,
FlinkLogicalTableSourceScan.CONVERTER,
FlinkLogicalTableFunctionScan.CONVERTER,
FlinkLogicalNativeTableScan.CONVERTER
)如逻辑计划
LogicalFilter(condition=[>($2, 2+3)])
LogicalTableScan(table=[[DataStreamTable1]])优化为:
LogicalProject.NONE(input=rel#19:LogicalFilter.NONE(input=rel#10:LogicalTableScan.NONE(table=[OrderA]),condition=>($2, 5)),user=$0,product=$1,amount=$2)主要做了如下几点优化: 1)过滤下压到tablescan节点,直接在输入的时候进行判断; 2)表达式提前预计算,如“2+3”之间计算出结果5; 5、再使用如下规则并使用janino codegen生成用DataStream API描述的物理执行计划;
val DATASTREAM_OPT_RULES: RuleSet = RuleSets.ofList(
// translate to DataStream nodes
DataStreamSortRule.INSTANCE,
DataStreamGroupAggregateRule.INSTANCE,
DataStreamOverAggregateRule.INSTANCE,
DataStreamGroupWindowAggregateRule.INSTANCE,
DataStreamCalcRule.INSTANCE,
DataStreamScanRule.INSTANCE,
DataStreamUnionRule.INSTANCE,
DataStreamValuesRule.INSTANCE,
DataStreamCorrelateRule.INSTANCE,
StreamTableSourceScanRule.INSTANCE
)6、最后使用如下规则对物理执行计划进行优化。主要是对聚合操作的优化。
val DATASTREAM_DECO_RULES: RuleSet = RuleSets.ofList(
// retraction rules
DataStreamRetractionRules.DEFAULT_RETRACTION_INSTANCE,
DataStreamRetractionRules.UPDATES_AS_RETRACTION_INSTANCE,
DataStreamRetractionRules.ACCMODE_INSTANCE
)7、最后提交到Flink平台执行;
六、StreamSQL 语法介绍
整体语法范式如下:
query:
values
| {
select
| selectWithoutFrom
| query UNION [ ALL ] query
| query EXCEPT query
| query INTERSECT query
}
[ ORDER BY orderItem [, orderItem ]* ]
[ LIMIT { count | ALL } ]
[ OFFSET start { ROW | ROWS } ]
[ FETCH { FIRST | NEXT } [ count ] { ROW | ROWS } ONLY]
orderItem:
expression [ ASC | DESC ]
select:
SELECT [ ALL | DISTINCT ]
{ * | projectItem [, projectItem ]* }
FROM tableExpression
[ WHERE booleanExpression ]
[ GROUP BY { groupItem [, groupItem ]* } ]
[ HAVING booleanExpression ]
selectWithoutFrom:
SELECT [ ALL | DISTINCT ]
{ * | projectItem [, projectItem ]* }
projectItem:
expression [ [ AS ] columnAlias ]
| tableAlias . *
tableExpression:
tableReference [, tableReference ]*
| tableExpression [ NATURAL ] [ LEFT | RIGHT | FULL ] JOIN tableExpression [ joinCondition ]
joinCondition:
ON booleanExpression
| USING '(' column [, column ]* ')'
tableReference:
tablePrimary
[ [ AS ] alias [ '(' columnAlias [, columnAlias ]* ')' ] ]
tablePrimary:
[ TABLE ] [ [ catalogName . ] schemaName . ] tableName
| LATERAL TABLE '(' functionName '(' expression [, expression ]* ')' ')'
| UNNEST '(' expression ')'
values:
VALUES expression [, expression ]*
groupItem:
expression
| '(' ')'
| '(' expression [, expression ]* ')'
| CUBE '(' expression [, expression ]* ')'
| ROLLUP '(' expression [, expression ]* ')'
| GROUPING SETS '(' groupItem [, groupItem ]* ')'语法操作
1)Scan、Projection、Filter以及自定义函数
| Operators | Description |
|---|---|
| Scan/Select/As | SELECT a, c AS d FROM Orders; |
| Where/Filter | SELECT * FROM Orders WHERE a % 2 = 0; |
| User-defined Scalar Functions (Scalar UDF) | SELECT TimestampModifier(user) FROM Orders; |
对于自定义函数,需要注册到table 的stream环境中。如:
object TimestampModifier extends ScalarFunction {
def eval(t: Long): Long = {
t % 1000
}
val tableEnv = TableEnvironment.getTableEnvironment(env)
tableEnv.registerFunction("TimestampModifier", TimestampModifier)2)Aggregations及用户自定义的聚合函数
| Operators | Description |
|---|---|
| GroupBy Aggregation | SELECT a, SUM(b) as d FROM Orders GROUP BY a; |
| **GroupBy Window Aggregation ** | SELECT user, SUM(amount) FROM Orders GROUP BY TUMBLE(rowtime, INTERVAL '1' DAY), user; |
| Over Window aggregation | SELECT COUNT(amount) OVER (PARTITION BY user ORDER BY proctime ROWS BETWEEN 2 PRECEDING AND CURRENT ROW) FROM Orders; |
| Having | SELECT SUM(amount) FROM Orders GROUP BY users HAVING SUM(amount) > 50; |
| User-defined Aggregate Functions (UDAGG) | SELECT MyAggregate(amount) FROM Orders GROUP BY users; |
说明: a)window当前支持group window和row window。group window就是所谓的跳跃窗口,固定周期触发输出。row window就是所谓的滑动窗口,每个数据流过来,都会触发输出;group window当前支持:
| Group Window Function | Description |
|---|---|
| TUMBLE(time_attr, interval) | Defines a tumbling time window. A tumbling time window assigns rows to non-overlapping, continuous windows with a fixed duration (interval). For example, a tumbling window of 5 minutes groups rows in 5 minutes intervals. Tumbling windows can be defined on event-time (stream + batch) or processing-time (stream). |
| HOP(time_attr, interval, interval) | Defines a hopping time window (called sliding window in the Table API). A hopping time window has a fixed duration (second interval parameter) and hops by a specified hop interval (first interval parameter). If the hop interval is smaller than the window size, hopping windows are overlapping. Thus, rows can be assigned to multiple windows. For example, a hopping window of 15 minutes size and 5 minute hop interval assigns each row to 3 different windows of 15 minute size, which are evaluated in an interval of 5 minutes. Hopping windows can be defined on event-time (stream + batch) or processing-time (stream). |
| SESSION(time_attr, interval) | Defines a session time window. Session time windows do not have a fixed duration but their bounds are defined by a time interval of inactivity, i.e., a session window is closed if no event appears for a defined gap period. For example a session window with a 30 minute gap starts when a row is observed after 30 minutes inactivity (otherwise the row would be added to an existing window) and is closed if no row is added within 30 minutes. Session windows can work on event-time (stream + batch) or processing-time (stream). |
b)聚合自定义函数和普通自定义函数类似。 3)Set
| Operators | Description |
|---|---|
| UnionAll | SELECT * FROM ((SELECT user FROM Orders WHERE a % 2 = 0)UNION ALL(SELECT user FROM Orders WHERE b = 0)); |
StreamSQL支持的数据类型
StreamSQL支持的数据类型如下:
以上是关于Flink StreamSQL 原理介绍的主要内容,如果未能解决你的问题,请参考以下文章