Flink 介绍
Posted 看0和1的故事
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flink 介绍相关的知识,希望对你有一定的参考价值。
Apache Flink® is an open-source stream processing framework for distributed, high-performing, always-available, and accurate data streaming applications.
Apache Flink是一个分布式高性能高可靠精确的数据处理的开源流式计算框架
Continuous Processing for Unbounded Datasets
Before we go into detail about Flink, let’s review at a higher level the types of datasets you’re likely to encounter when processing data as well as types of execution models you can choose for processing. These two ideas are often conflated, and it’s useful to clearly separate them.
First, 2 types of datasets
Unbounded: Infinite datasets that are appended to continuously
Bounded: Finite, unchanging datasets
Many real-world data sets that are traditionally thought of as bounded or “batch” data are in reality unbounded datasets. This is true whether the data is stored in a sequence of directories on HDFS or in a log-based system like Apache Kafka.
Examples of unbounded datasets include but are not limited to:
End users interacting with mobile or web applications
Physical sensors providing measurements
Financial markets
Machine log data
Second, 2 types of execution models
Streaming: Processing that executes continuously as long as data is being produced
Batch: Processing that is executed and runs to completeness in a finite amount of time, releasing computing resources when finished
It’s possible, though not necessarily optimal, to process either type of dataset with either type of execution model. For instance, batch execution has long been applied to unbounded datasets despite potential problems with windowing, state management, and out-of-order data.
Flink relies on a streaming execution model, which is an intuitive fit for processing unbounded datasets: streaming execution is continuous processing on data that is continuously produced. And alignment between the type of dataset and the type of execution model offers many advantages with regard to accuracy and performance.
对无界数据集的连续处理
在我们详细介绍Flink之前,我们先来看一下处理数据时可能遇到的数据集类型以及您可以选择处理的执行模型的类型。这两个想法经常被混淆,清楚地区分它们是有用的。
首先,两种类型的数据集
无界:连续追加的无限数据集
有界:有限的,不变的数据集
传统上被认为是有限或“批量”数据的许多实际数据集实际上是无界数据集。无论数据是存储在HDFS上的目录序列还是像Apache Kafka这样的基于日志的系统中,都是如此。
无界数据集的例子包括但不限于:
终端用户与移动或Web应用程序进行交互
物理传感器提供测量
金融市场
机器日志数据
其次,有两种执行模式
流式传输:只要数据正在生成,就会连续执行的处理
批处理:在有限的时间内执行处理并运行完成,完成后释放计算资源
尽管不一定是最佳的,但可以用任何一种类型的执行模型来处理任一类型的数据集。例如,尽管在窗口化,状态管理和无序数据方面存在潜在的问题,批处理执行早已应用于无界数据集。
Flink依赖流式执行模型,这是一个直观的适合处理无界数据集的模型:流式执行是连续处理连续产生的数据。数据集类型和执行模型类型之间的对齐在准确性和性能方面提供了许多优点。
Features: Why Flink?
Flink is an open-source framework for distributed stream processing that:
Provides results that are accurate, even in the case of out-of-order or late-arriving data
Is stateful and fault-tolerant and can seamlessly recover from failures while maintaining exactly-once application state
Performs at large scale, running on thousands of nodes with very good throughput and latency characteristics
Earlier, we discussed aligning the type of dataset (bounded vs. unbounded) with the type of execution model (batch vs. streaming). Many of the Flink features listed below–state management, handling of out-of-order data, flexible windowing–are essential for computing accurate results on unbounded datasets and are enabled by Flink’s streaming execution model.
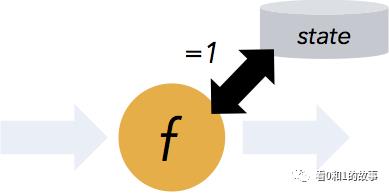
Flink guarantees exactly-once semantics for stateful computations. ‘Stateful’ means that applications can maintain an aggregation or summary of data that has been processed over time, and Flink’s checkpointing mechanism ensures exactly-once semantics for an application’s state in the event of a failure.
特点:为什么Flink?
Flink是一个分布式流处理的开源框架:
提供准确的结果,即使在无序或迟到数据的情况下也是如此
具有状态和容错功能,可以在保持一次应用程序状态的同时无缝地从故障中恢复
大规模执行,在数千个节点上运行,具有非常好的吞吐量和延迟特性
此前,我们讨论了将数据集的类型(有界还是无界)与执行模型的类型(批量与流媒体)进行对齐。下面列出的许多Flink功能 - 状态管理,无序数据的处理,灵活的窗口 - 对于在无界数据集上计算精确的结果非常重要,并且由Flink的流式执行模型来实现。
Flink保证有状态计算的一次语义。 “有状态的”意味着应用程序可以维护一段时间内已经处理的数据的汇总或汇总,并且Flink的检查点设置机制在发生故障时确保应用程序状态的一次语义。
Flink supports stream processing and windowing with event time semantics. Event time makes it easy to compute accurate results over streams where events arrive out of order and where events may arrive delayed.
Flink支持流处理和窗口事件时间语义。 事件时间可以轻松计算事件到达顺序,即使到达时间顺序不正确,事件可能延迟到达的流的精确结果。
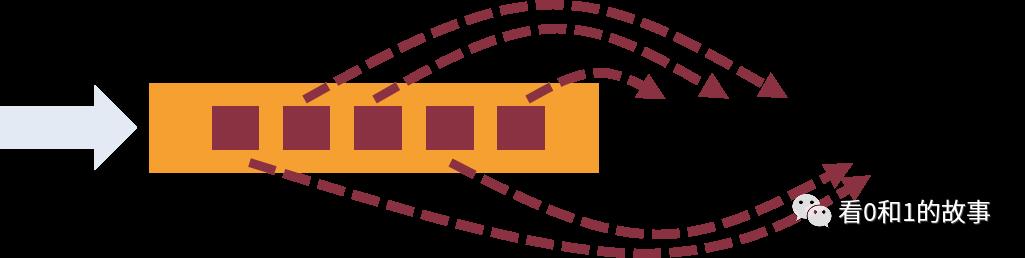
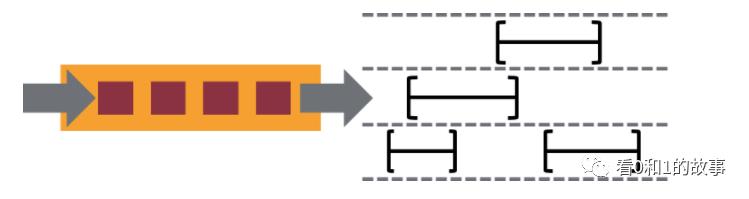
Flink supports flexible windowing based on time, count, or sessions in addition to data-driven windows. Windows can be customized with flexible triggering conditions to support sophisticated streaming patterns. Flink’s windowing makes it possible to model the reality of the environment in which data is created.
除了数据驱动的窗口,Flink还支持基于时间,计数或会话的灵活窗口。 Windows可以通过灵活的触发条件进行定制,以支持复杂的流模式。 Flink的窗口可以模拟数据创建环境的实际情况。
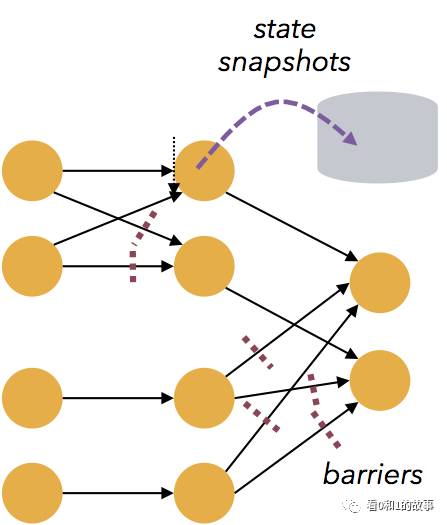
Flink’s fault tolerance is lightweight and allows the system to maintain high throughput rates and provide exactly-once consistency guarantees at the same time. Flink recovers from failures with zero data loss while the tradeoff between reliability and latency is negligible.
Flink的容错功能是轻量级的,可以让系统保持高吞吐率,同时提供一次性一致性保证。 Flink从零数据丢失的故障恢复,而可靠性和延迟之间的折衷可以忽略不计。
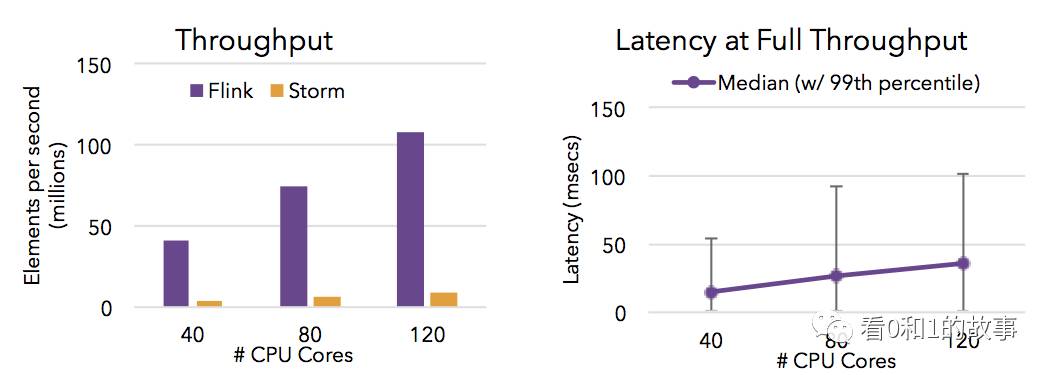
Flink is capable of high throughput and low latency (processing lots of data quickly). The charts below show the performance of Apache Flink and Apache Storm completing a distributed item counting task that requires streaming data shuffles.
Flink能够实现高吞吐量和低延迟(快速处理大量数据)。 下面的图表显示了Apache Flink和Apache Storm的性能,完成了需要流式数据混洗的分布式项目计数任务。
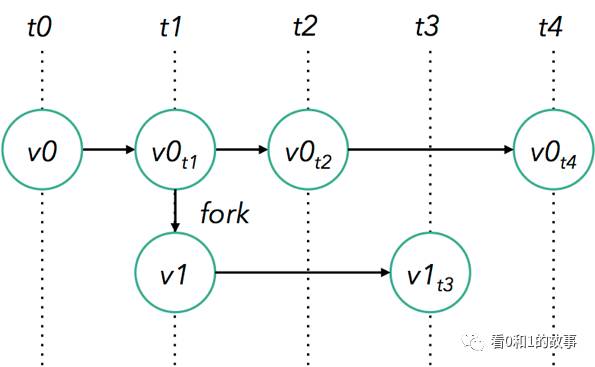
Flink’s savepoints provide a state versioning mechanism, making it possible to update applications or reprocess historic data with no lost state and minimal downtime.
Flink的保存点提供了一个状态版本管理机制,可以更新应用程序或重新处理历史数据,而且不会丢失状态,停机时间最短。
Flink is designed to run on large-scale clusters with many thousands of nodes, and in addition to a standalone cluster mode, Flink provides support for YARN and Mesos.
Flink设计用于在数千个节点的大型集群上运行,除了独立集群模式之外,Flink还提供对YARN和Mesos的支持。
Flink, the streaming model, and bounded datasets
If you’ve reviewed Flink’s documentation, you might have noticed both a DataStream API for working with unbounded data as well as a DataSet API for working with bounded data.
Earlier in this write-up, we introduced the streaming execution model (“processing that executes continuously, an event-at-a-time”) as an intuitive fit for unbounded datasets. So how do bounded datasets relate to the stream processing paradigm?
In Flink’s case, the relationship is quite natural. A bounded dataset can simply be treated as a special case of an unbounded one, so it’s possible to apply all of the same streaming concepts that we’ve laid out above to finite data.
This is exactly how Flink’s DataSet API behaves. A bounded dataset is handled inside of Flink as a “finite stream”, with only a few minor differences in how Flink manages bounded vs. unbounded datasets.
And so it’s possible to use Flink to process both bounded and unbounded data, with both APIs running on the same distributed streaming execution engine–a simple yet powerful architecture.
The “What”: Flink from the bottom-up
Deployment modes
Flink can run in the cloud or on premise and on a standalone cluster or on a cluster managed by YARN or Mesos.
Runtime
Flink’s core is a distributed streaming dataflow engine, meaning that data is processed an event-at-a-time rather than as a series of batches–an important distinction, as this is what enables many of Flink’s resilience and performance features that are detailed above.
部署模式
Flink可以运行在云环境中,也可以在内部环境中运行,也可以运行在独立的集群上,也可以运行在YARN或Mesos管理的集群上。
运行
Flink的核心是分布式流式数据流引擎,意味着数据一次处理而不是一系列批处理,这是一个重要的区别,因为这是Flink的许多弹性和性能特征。
APIs
Flink’s DataStream API is for programs that implement transformations on data streams (e.g., filtering, updating state, defining windows, aggregating).
The DataSet API is for programs that implement transformations on data sets (e.g., filtering, mapping, joining, grouping).
The Table API is a SQL-like expression language for relational stream and batch processing that can be easily embedded in Flink’s DataSet and DataStream APIs (Java and Scala).
Streaming SQL enables SQL queries to be executed on streaming and batch tables. The syntax is based on Apache Calcite™.
Libraries
Flink also includes special-purpose libraries for complex event processing, machine learning, graph processing, and Apache Storm compatibility.
API
Flink的DataStream API适用于实现数据流转换的程序(例如过滤,更新状态,定义窗口,聚合)。
DataSet API适用于在数据集上实现转换的程序(例如过滤,映射,连接,分组)。
Table API是用于关系流和批处理的SQL类表达式语言,可以轻松嵌入到Flink的DataSet和DataStream API(Java和Scala)中。
流式SQL使SQL查询能够在流式处理和批处理表上执行。 语法基于Apache Calcite™。
Libraries
Flink还包括用于复杂事件处理,机器学习,图形处理和Apache Storm兼容性的专用库
Flink and other frameworks
At the most basic level, a Flink program is made up of:
Data source: Incoming data that Flink processes
Transformations: The processing step, when Flink modifies incoming data
Data sink: Where Flink sends data after processing
Flink supports a wide range of connectors to third-party systems for data sources and sinks.
Flink支持多种数据源和接收器的第三方系统连接器。
以上是关于Flink 介绍的主要内容,如果未能解决你的问题,请参考以下文章
译文《Apache Flink官方文档》 Apache Flink介绍