Flink 1.5版本网络栈重构技术分析
Posted Flink
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flink 1.5版本网络栈重构技术分析相关的知识,希望对你有一定的参考价值。
overview
基于Flink近期的官方声明,明年的1.5版本将会发布三个较大feature,其中之一就是对于网络栈的重构。具体而言,就是将基于配置的、固定间隔的网络I/O改进为基于事件驱动的I/O。这种改进预期将会带来如下这些优势:
提供应用程序级别的流控,以更好地处理反压(backpressure);
降低Flink的网络延迟;
更好地处理检查点的对齐(alignments);
当buffer不够时,不会造成通信链路(wire)被消息阻塞;
虽然,相关的工作仍在进行中,但我们可以先大致了解一下该改进的实现机制。
我们将分三个部分来进行介绍。首先,回顾一下当前最新的 1.3.x系列的网络栈。然后,介绍一下Flink新采用的基于Credit的流控机制。最后,分析一些事件驱动的I/O。在分析的过程中,我们将结合Flink Forward之前介绍该Feature的Slide中的截图。
1.3系列版本的网络栈
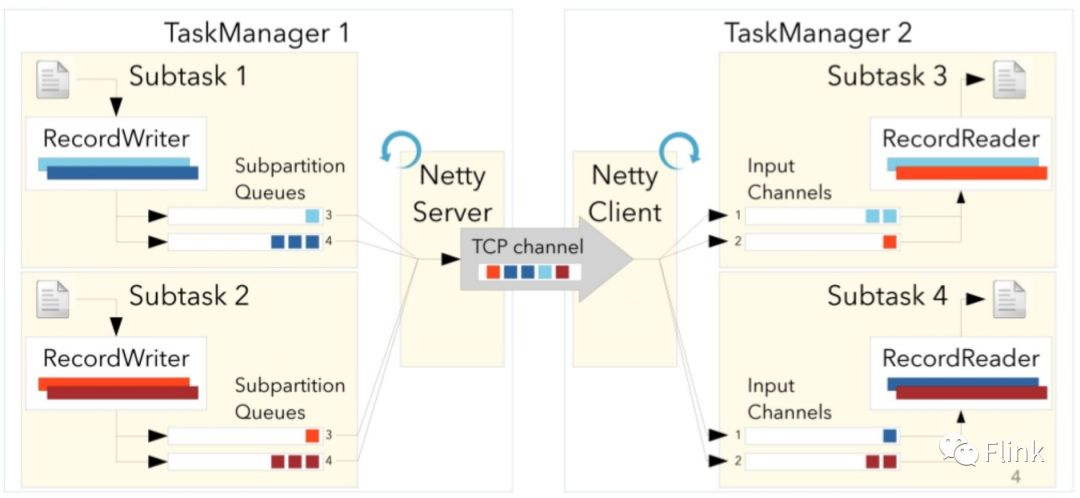
从很高的抽象层级上来看,Flink TM之间基于Netty的NIO通信,同一个Job中不同Task的实例(subtask)之间根据物理DAG的连接关系进行通信(Netty Channel多路复用Netty Connection),形如下图:
当放大技术细节后可见,每个物理DAG的上游subtask都拥有各自的消息发送队列,由上层通过 RecordWriter(序列化后)写入。对下游subtask,它们通过input channel接收上游的消息,然后通过 RecordReader读取(以及反序列化)。大致是如下过程:
为了实现 Exactly-Once的消息分发语义,Flink采用定期从source端发送barrier在网络中向下游流动并采用对齐(align)来分隔不同检查点的数据,从而使得快照结果得以符合语义。而barrier其实只是混杂在用户数据中的一种特殊的事件。但对齐带来的副作用就是它将占用本地buffer池的可用资源,当buffer资源不够时,将会导致backpressure的产生:
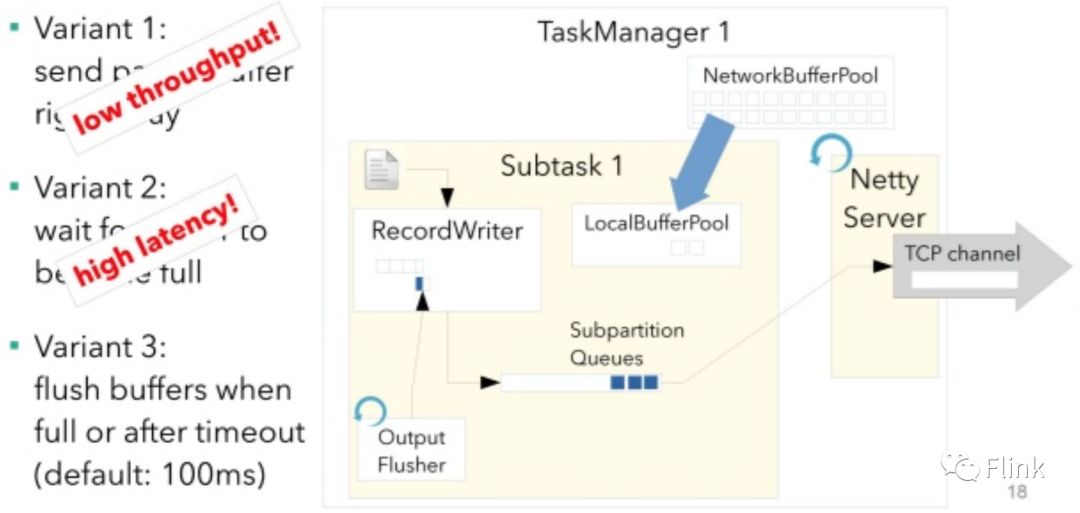
为了尽量达到高吞吐、低延迟的目标,Flink采用了一种弹性、可配置的方式来决定何时flush本地的数据给下游,它的flusher是定时工作的:
基于1.3系列的这种网络栈的技术实现,由于上游subtask并不了解下游subtask的处理能力以及是否有可用的buffer资源,所以它只能是被动地响应backpressure的产生,一旦它发现自己本地发送队列保留的消息越来越多,它才意识到下游产生了backpressure,但此时它其实已经多发了很多下游subtask无法接收的数据,而这些数据将阻塞通信链路而无法被顺利消费,形如下图:
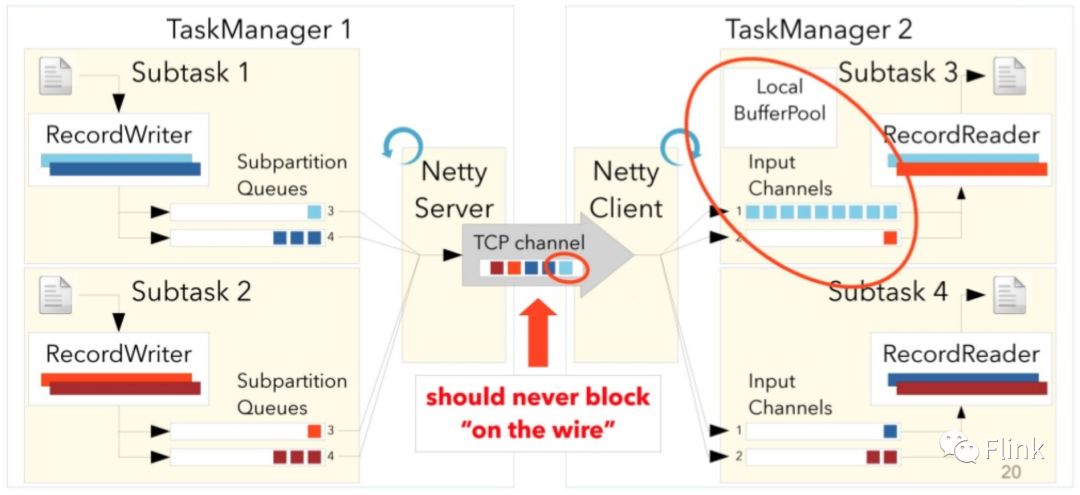
下面一节我们将分析,在未来的版本中,Flink是如何重构它的网络栈使得它更好地控制backpressure问题。
基于Credit的流控
Flink应用了在解决网络拥塞时一种经典的流控方式——基于Credit的流量控制。关于它的实现思路,描述于1995年的一篇论文——《Credit-Based Flow Control for ATM Networks》。论文中的示意图如下:
简单地描述其原理就是"基于信用"的消费,所谓的信用即为下游能够继续消费数据的“容量”, RemoteInputChannel会通知上游它还有多少“信用”,如果没有信用了,则认为下游不再具备消费的能力了,这有效地防止了链路拥塞。
每个 RemoteInputChannel拥有固定大小的额外的buffer数目作为初始信用,并且每个 SingleInputGate也有固定大小的buffer pool来作为其拥有的 RemoteInputChannel的浮动信用池。为了使得 RemoteInputChannel估算自己要去申请的信用,上游也会通过携带一个 backlog信息,告诉下游它本地已经缓存了多少等待下游消费的数据,这样 RemoteInputChannel可以及时评估它需要申请的buffer(信用)大小。
将buffer类比于信用卡的额度来理解。
通过从下游向上游反馈Credit(里面携带了下游的buffer信息),从而让上游感知下游的消费能力。
目前已知的采用这种流控的方式有:RabbitMQ以及Twitter的Heron论文的4.3节
Flink subtask之间基于credit的通信示意图如下:
再次列举一下基于Credit的流控所带来的好处:
一旦下游消费者没有buffer,将不会再有消息造成链路拥塞;
细粒度的backpressure控制;
提升了检查点的alignments
额外的成本:
额外发送通知消息;
事件驱动的I/O
Flink承载数据的buffer,在1.3版本,其发送机制兼顾(可配置)了buffer容量(吞吐)与超时(延迟)。当发送倾向于低延迟(通常配置为很短的超时时间),采用一个定时的flusher来发送buffer。
在Flink未来的改进中,考虑移除flusher,而是尽快直接将数据写到发送队列(subpartition queue),从而保证了更低的传输延迟,与此同时,其输出将尽可能利用网络channel的容量,从而保证高吞吐能力。
这种方案,肯定能将延迟最小化,但对吞吐会造成一定程度的影响,具体定量的影响,目前还没有数据可以反应。
以上是关于Flink 1.5版本网络栈重构技术分析的主要内容,如果未能解决你的问题,请参考以下文章