Spark 2.3重磅发布:欲与Flink争高下,引入持续流处理
Posted AI前线
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark 2.3重磅发布:欲与Flink争高下,引入持续流处理相关的知识,希望对你有一定的参考价值。
更多干货内容请关注微信公众号“AI 前线”,(ID:ai-front)
Spark 2.3 继续向更快、更易用、更智能的目标迈进,引入了低延迟的持续处理能力和流到流的连接,让 Structured Streaming 达到了一个里程碑式的高度;使用 Pandas UDF 提升 PySpark 的性能;为 Spark 应用程序提供 Kubernetes 原生支持。
除了继续引入 SparkR、Python、MLlib 和 GraphX 方面的新功能,这一版本主要在可用性和稳定性方面下了功夫,解决了 1400 多个 ticket。其他主要特性如下:
DataSource V2 API
向量化的 ORC Reader
包含键值存储的 Spark History Server V2
基于 Structured Streaming 的机器学习管道 API
MLlib 增强
Spark SQL 增强
下面将简单概括一些主要的特性和改进,更多信息可参看 Spark 2.3 发布通告(https://spark.apache.org/releases/spark-release-2-3-0.html)。
出于某些原因的考虑,Spark 2.0 引入的 Structured Streaming 将微批次处理从高级 API 中解耦出去。首先,它简化了 API 的使用,API 不再负责进行微批次处理。其次,开发者可以将流看成是一个没有边界的表,并基于这些“表”运行查询。
不过,为了给开发者提供更多的流式处理体验,Spark 2.3 引入了毫秒级延迟的持续流式处理模式。
从内部来看,Structured Streaming 引擎基于微批次增量执行查询,时间间隔视具体情况而定,不过这样的延迟对于真实世界的流式应用来说都是可接受的。
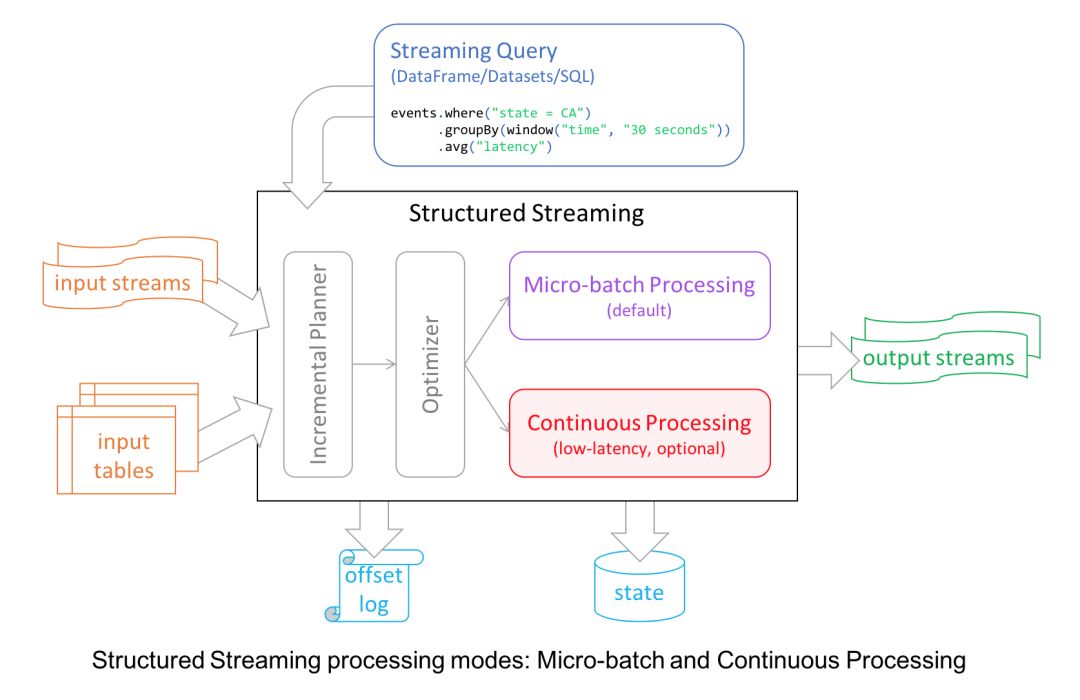
在持续模式下,流处理器持续不断地从数据源拉取和处理数据,而不是每隔一段时间读取一个批次的数据,这样就可以及时地处理刚到达的数据。如下图所示,延迟被降低到毫秒级别,完全满足了低延迟的要求。
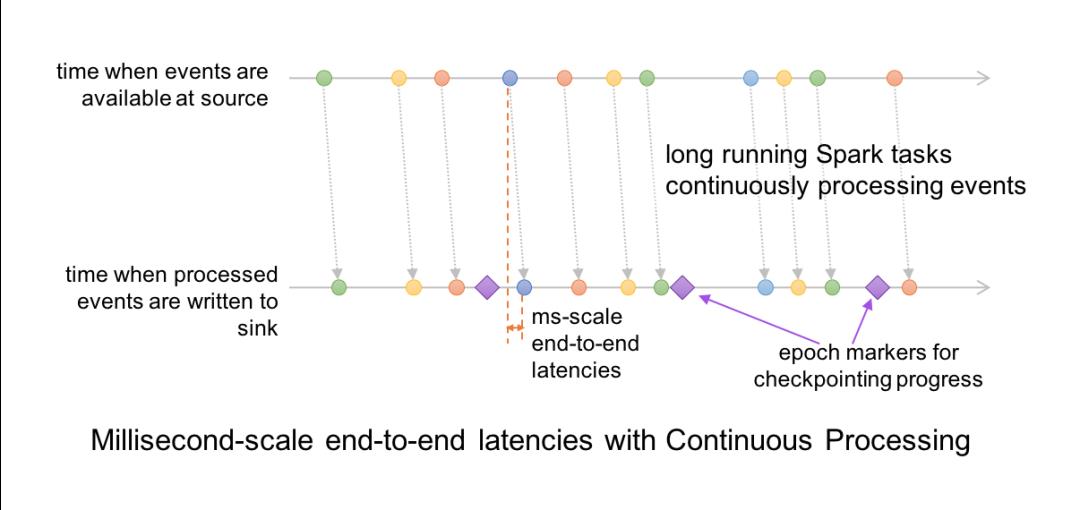
持续模式目前支持的 Dataset 操作包括 Projection、Selection 以及除 current_timestamp()、current_date()、聚合函数之外的 SQL 操作。它还支持将 Kafka 作为数据源和数据池(Sink),也支持将控制台和内存作为数据池。
开发者可以根据实际的延迟需求来选择使用持续模式还是微批次模式,总之,Structured Streaming 为开发者提供了容错和可靠性方面的保证。
简单地说,Spark 2.3 的持续模式所能做到的是:
端到端的毫秒级延迟
至少一次处理保证
支持 Dataset 的映射操作
Spark 2.0 的 Structured Streaming 已经可以支持 DataFrame/Dataset 的连接操作,但只是流到静态数据集的连接,而 Spark 2.3 带来了期待已久的流到流的连接,支持内连接和外连接,可用在大量的实时场景中。
广告变现是流到流连接的一个典型应用场景。例如,广告 impression 流和用户点击流包含相同的键(如 adld)和相关数据,而你需要基于这些数据进行流式分析,找出哪些用户的点击与 adld 相关。
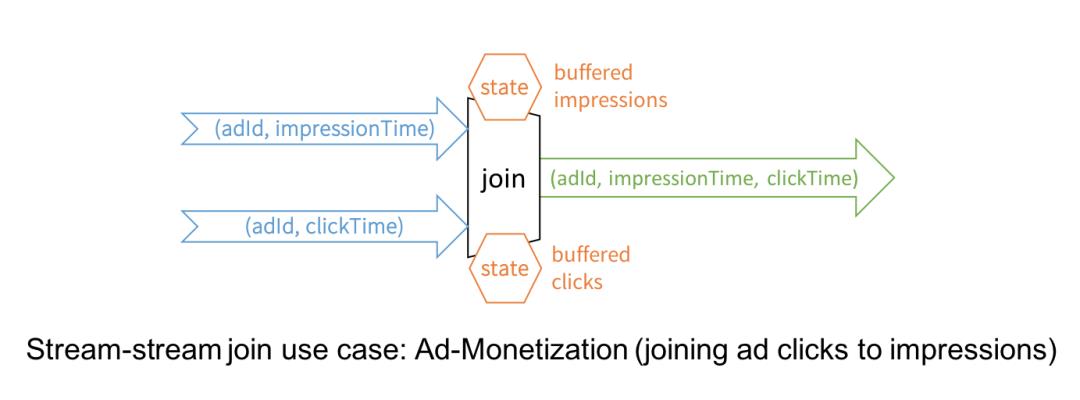
虽然看起来很简单,但实际上流到流的连接解决了一些技术性难题:
将迟到的数据缓冲起来,直到在另一个流中找到与之匹配的数据。
通过设置水位(Watermark)防止缓冲区过度膨胀。
用户可以在资源消耗和延迟之间作出权衡。
静态连接和流连接之间的 SQL 语法是一致的。
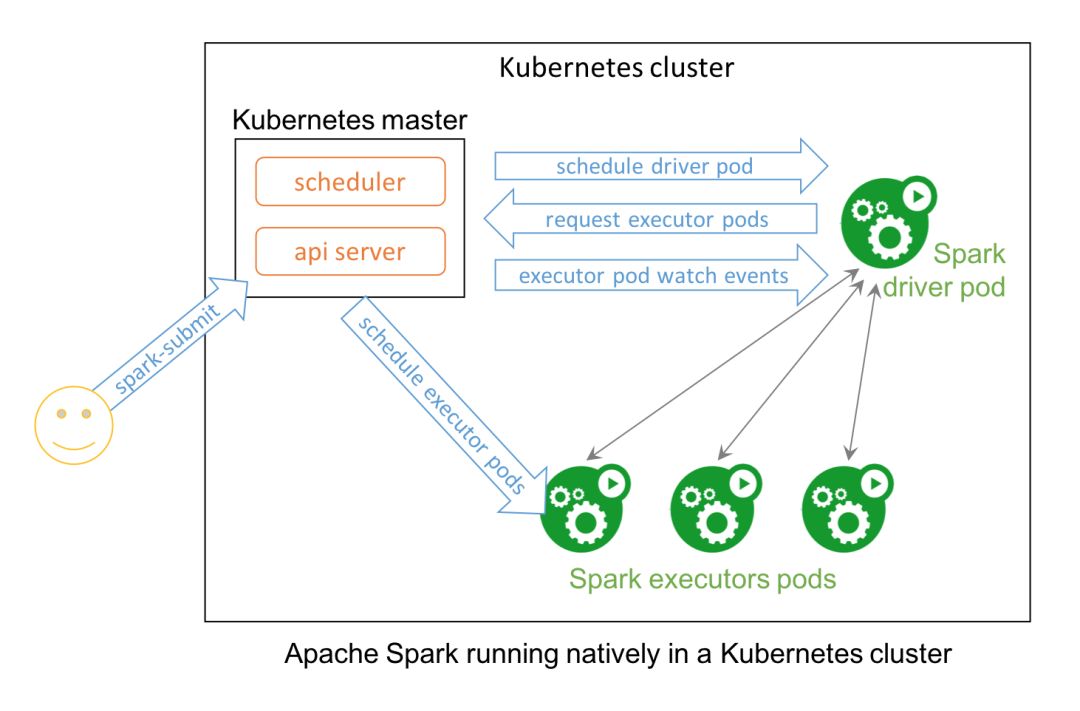
Spark 和 Kubernetes 这两个开源项目之间的功能组合也在意料之内,用于提供大规模分布式的数据处理和编配。在 Spark 2.3 中,用户可在 Kubernetes 集群上原生地运行 Spark,从而更合理地使用资源,不同的工作负载可共享 Kubernetes 集群。
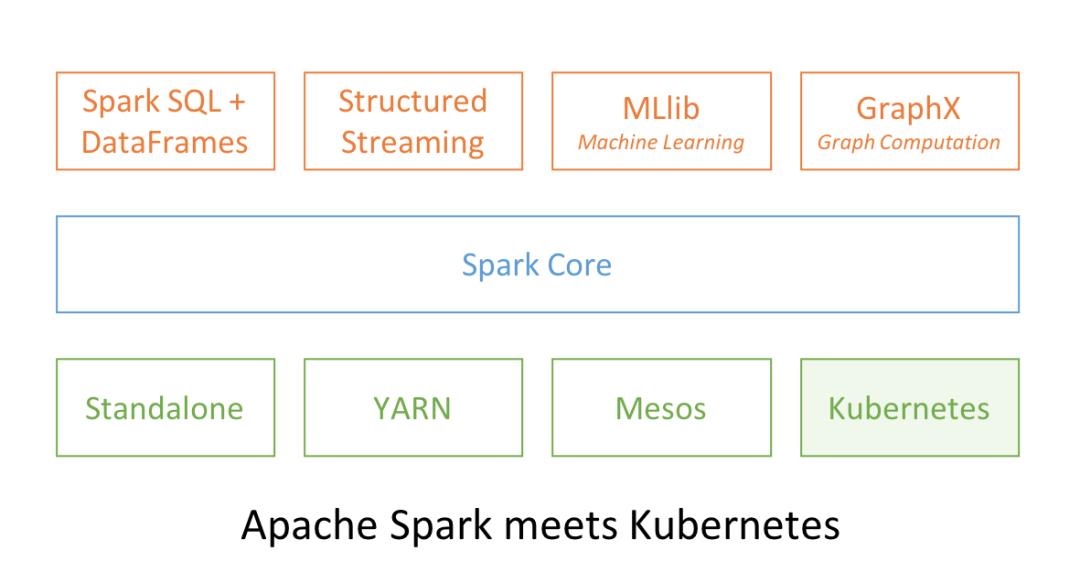
Spark 可以使用 Kubernetes 的所有管理特性,如资源配额、可插拔的授权和日志。另外,要在已有的 Kubernetes 集群上启动 Spark 工作负载就像创建一个 Docker 镜像那么简单。
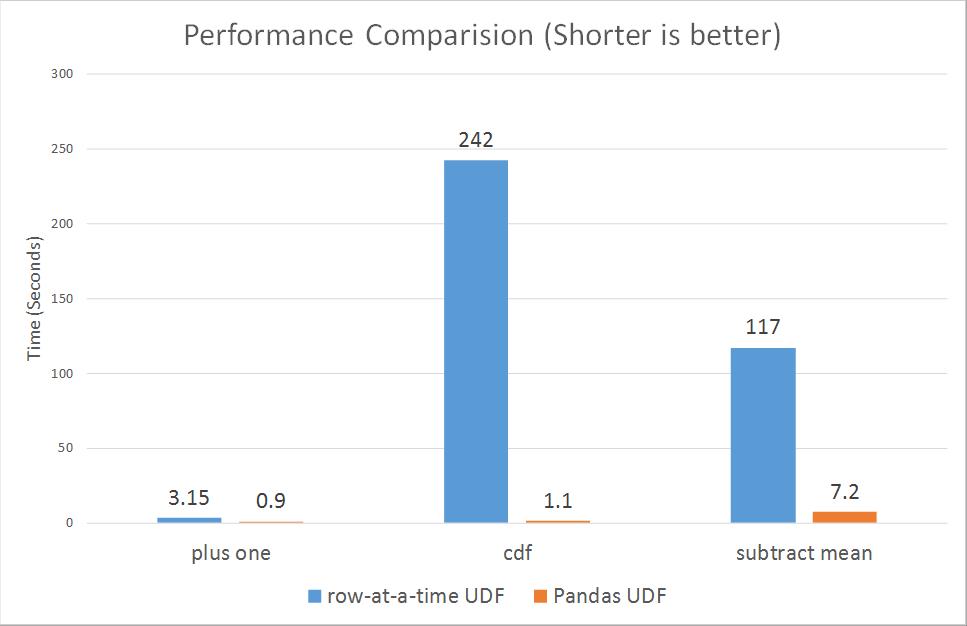
Pandas UDF,也被称为向量化的 UDF,为 PySpark 带来重大的性能提升。Pandas UDF 以 Apache Arrow 为基础,完全使用 Python 开发,可用于定义低开销、高性能的 UDF。
Spark 2.3 提供了两种类型的 Pandas UDF:标量和组合 map。来自 Two Sigma 的 Li Jin 在之前的一篇博客(https://databricks.com/blog/2017/10/30/introducing-vectorized-udfs-for-pyspark.html) 中通过四个例子介绍了如何使用 Pandas UDF。
一些基准测试表明,Pandas UDF 在性能方面比基于行的 UDF 要高出一个数量级。
包括 Li Jin 在内的一些贡献者计划在 Pandas UDF 中引入聚合和窗口功能。
Spark 2.3 带来了很多 MLlib 方面的改进,包括算法、特性、性能、伸缩性和可用性。
首先,可通过 Structured Streaming 作业将 MLlib 的模型和管道部署到生产环境,不过一些已有的管道可能需要作出修改。
其次,为了满足深度学习图像分析方面的需求,Spark 2.3 引入了 ImageSchema,将图像表示成 Spark DataFrame,还提供工具用于加载常用的图像格式。
最后,Spark 2.3 带来了改进过的 Python API,用于开发自定义算法,包括 UnaryTransformer 以及用于保存和加载算法的自动化工具。
原文链接:
https://databricks.com/blog/2018/02/28/introducing-apache-spark-2-3.html?from=timeline&isappinstalled=0
如果您觉得内容优质,记得给我们「留言」和「点赞」,给编辑鼓励一下!
今日荐文
福布斯重磅预测:机器学习之火愈烧愈烈,开发者甩开膀子干!
没有经历失败的架构师一定不是好的架构师,尤其在新领域与新技术的探索上,虽然失败如此必要,但你可以学习与借鉴他人的经验与教训,让你的苦难和坑无比缩短。
2018年 7月 6-9日,InfoQ将在深圳举行全球架构师峰会,此次大会已邀请来自 Google、Facebook、Netflix、Pinterest、eBay、BAT等资深架构师从云架构到边缘计算等诸多方面为大家一一解惑,而阿里达摩院、Microsoft、Amazon、IBM的分享内容正在筹备,敬请期待。
此次大会的 7折优惠仅剩一周,报名详请可咨询大会票务经理豆包(微信:aschina666),或直接致电 010-84780850。
以上是关于Spark 2.3重磅发布:欲与Flink争高下,引入持续流处理的主要内容,如果未能解决你的问题,请参考以下文章
Firefox 还没放弃自己,准备继续跟 Chrome 一争高下