技术分享Flink应用开发入门
Posted 唯品会安全应急响应中心
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了技术分享Flink应用开发入门相关的知识,希望对你有一定的参考价值。
鸣 谢
VSRC感谢业界小伙伴——大榕树投稿精品原创类文章。VSRC欢迎精品原创类或翻译类文章投稿,优秀文章一旦采纳发布,将有好礼相送,我们已为您准备好了丰富的奖品!(活动最终解释权归VSRC所有)
引言
随着业务和分布式技术的发展越来越多的业务需要对分布式流数据进行快速的计算输出,比如实时推荐,系统运行监控,安全业务防刷等等,对于一些只关注低延时不需要关注数据状态的需求storm是一个不错的选择,但是及要求低延迟又要求数据状态的需求则可以试试Flink 。(当然如果你还需要进行图像操作或机器学习那就用spark吧,这里主要介绍下Flink的应用开发)。
Flink 简介:Flink是分布式流数据批计算框架,在实现流处理和批处理时,与传统的一些方案完全不同,它从另一个视角看待流处理和批处理,将二者统一起来:Flink是完全支持流处理,也就是说作为流处理看待时输入数据流是无界的;批处理被作为一种特殊的流处理,只是它的输入数据流被定义为有界的。基于同一个Flink运行时(Flink Runtime),分别提供了流处理和批处理API,而这两种API也是实现上层面向流处理、批处理类型应用框架的基础。
大概了解了Flink后,那么如何开发一个Flink应用呢?其实开发起来也非常的简单 (工程创建部分这里不再详细的描述,大家可以从https://github.com/apache/flink/tree/master/flink-examples 下载样例代码工程)。
Flink的应用开发
1、首先创建被配置Flink执行环境
1StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();//禁止输出job的状态更新日志,默认是会输出的
2env.getConfig().disableSysoutLogging();//job失败后使用延迟重启策略,延迟10秒重启job,最多重启4次
3env.getConfig().setRestartStrategy(RestartStrategies.fixedDelayRestart(4, 10000));
4//启用checkPoint,每5秒执行一次CheckPoint 注:当遇到故障时,flink会停止分布式数据流。系统会重启所有的operator,重至到最近成功的checkpoint。输入重置相应的状态快照位置,来保证重置位置的正确性。
5env.enableCheckpointing(5000);
2、构建数据源,添加数据源
数据源是Flink的数据流入口,目前flink已经包含了一些常用的数据源组件,可以直接从文件,文件目录,hdfs文件系统、socket、Kafka(需要单独引入flink-connector-kafka包)消息等源头中读取数据。
不过所有的数据源组件都要实现SourceFunction接口(SourceFunction是Flink stream source的根接口)
它继承自一个标记接口(空接口) Function 。
SourceFunction 定义了两个接口方法:
1、run : 启动一个source,即对接一个外部数据源然后emit元素形成stream(大部分情况下会通过在该方法里运行一个while循环的形式来产生stream)。
2、cancel : 取消一个source,也即将run中的循环emit元素的行为终止。
正常情况下,一个 SourceFunction 实现这两个接口方法就可以了。其实这两个接口方法也固化了一种实现模板。
对于一些需要打开和关闭的数据源可以继承RichSourceFunction抽象类,具体需要重写RichSourceFunction中open和close方法。
1SourceFunction<String> source = ...;//构建自己的数据源。
2DataStream<String> input = env.addSource(source);//添加数据源到Flink执行环境中。
3、清洗转换数据
为了后续方便后续计算数据,拿到数据源的数据流后使用FlatMapFunction将数据流中的数据格式转成map。
1DataStream<Map<String, String>> baseDataStream = input
2 .flatMap(new FlatMapFunction<String, Map<String, String>>() {
3
4 private static final long serialVersionUID = 1L;
5
6 @Override
7 public void flatMap(String value, Collector<Map<String, String>> out) {
8
9 /**
10 * 处理数据转换
11 */
12 Map<String, String> data = ... ;//将source流出的value数据转成map;
13 if (data != null) {
14 out.collect(data);//收集转换后的数据
15 }
16 }
17 });4、构建窗口数据流并聚合计算
Flink的窗口可以是时间驱动的(Time Window,例如:每30秒钟),也可以是数据驱动的(Count Window,例如:每一百个元素)。一种经典的窗口分类可以分成:翻滚窗口(Tumbling Window,无重叠),滚动窗口(Sliding Window,有重叠),和会话窗口(Session Window,活动间隙)。
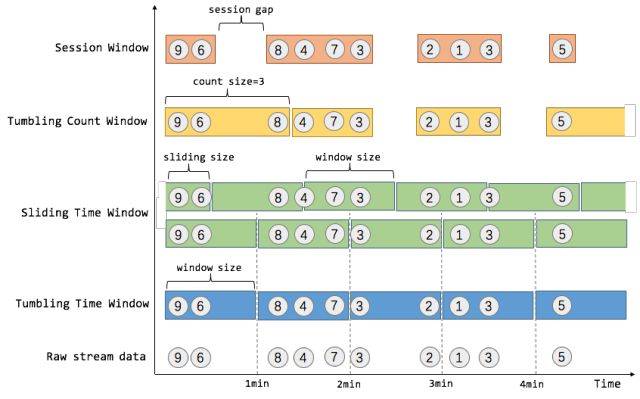
1//在这里我们生成一个业务系统中比较常用的窗口,基于时间的滑动窗口。
2WindowedStream<ReduceBean, Tuple, TimeWindow> windowedStream = null;
3windowedStream = outputDataStream.keyBy("keyField") //使用指定的字段对窗口进行分组,keyField为ReduceBean中的字段名称,当然也可以使用下标位置(int值)来指定分组字段。
4.timeWindow(Time.seconds(60) , Time.seconds(10)); //使用滑动时间窗口,窗口大小为60秒,窗口中每10秒一个窗格(每10秒计算最近60秒的数据)。
5//使用reduce function处理自定义汇集计算
6SingleOutputStreamOperator<ReduceBean> outputStream = null;
7outputStream = windowedStream.reduce(new ReduceFunction<ReduceBean>() {
8@Override
9public ReduceBean reduce(ReduceBean a, ReduceBean b) {
10return new ReduceBean(a.keyField, a.value+b.value); // reduce函数中实现求和计算,根据自己的业务需求可以自己实现这里的reduce处理逻辑,返回一个计算后的ReduceBean即可(ReduceBean为自己定义的一个序列化类)
11 }
12 });5、构建自定义SinkFunction实现自己的数据存储功能
继承RichSinkFunction<T> 编写自己的SinkFunction,重写invoke(T),open()和close() 方法。
open()是在任务的线程启动的时候会调用,用于初始一些资源信息,比如打开连接。
close()对应的就可以实现关系连接资源的动作。
invoke(T)对流中的对象进行存储处理。
1//构建好自定义sinkFunction后,追加到Flink的执行计划中
2outputStream.addSink(sinkFunction);
3//最后启动执行job即可
4env.execute(jobName);参考
http://blog.csdn.net/wwwxxdddx/article/details/51706900
http://blog.csdn.net/lmalds/article/details/53736836
http://blog.csdn.net/lmalds/article/details/54291527
2018唯品会第三届安全电商峰会想要得到免费参会资格,就赶紧拿起手机扫描下方二维码即可报名!
。
。
精彩原创文章投稿有惊喜!
VSRC欢迎精品原创类文章投稿,优秀文章一旦采纳发布,将为您准备的丰富奖金税后1000元现金或等值礼品,上不封顶!如若是安全文章连载,奖金更加丰厚,税后10000元或等值礼品,上不封顶!可点击“阅读原文”了解规则。(最终奖励以文章质量为准。活动最终解释权归VSRC所有)
不知道,大家都喜欢阅读哪些类型的信息安全文章?
不知道,大家都希望我们更新关于哪些主题的干货?
精彩留言互动的热心用户,将有机会获得VSRC赠送的精美奖品一份!
同时,我们也会根据大家反馈的建议,选取热门话题,进行原创发布!
点击阅读原文进入 为了挣到10000块,他在VSRC投了一篇稿!
以上是关于技术分享Flink应用开发入门的主要内容,如果未能解决你的问题,请参考以下文章