实战手把手 | Flink安装指南
Posted 中兴大数据
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了实战手把手 | Flink安装指南相关的知识,希望对你有一定的参考价值。
这是中兴大数据第222篇原创文章

Flink是Apache 下面的新的一个顶级项目,他是一个计算框架,与Spark非常类似,都是基于内存的计算框架,速度相对于MR有优势。其中核心概念有DataSet、DataStream等,与Spark中的RDD、DStream类似,提供的接口如Map、flatMap等也非常类似。也是从高阶的抽象来实现任务的优化,非自底而上的抽象底层算子的方式。


从Flink官网 下载Flink源码,flink-release-0.7.0.zip
解压缩后进入相关目录运行如下命令:
mvn cleanpackage -DskipTests -Dhadoop.profile=2 -Dhadoop.version=2.3.0

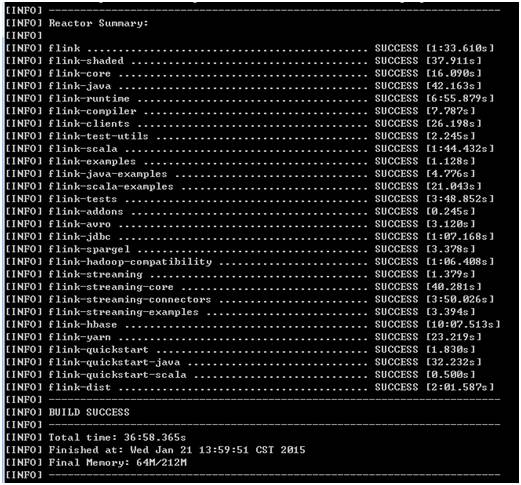
编译完成之后,在flink-dist argetflink-0.7.0-incubating-bin生成分别基于非YARN和YARN的两个版本,本次将非YARN的版本压缩成zip包,传到集群。

将zip文件上传至mr用户目录下,然后解压:

主要的配置文件有以下2个:
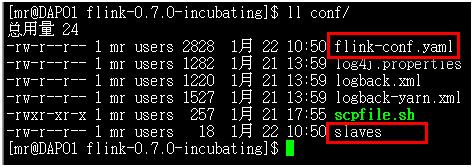
Slaves文件主要定义工作节点,在我们的环境中有三台机器,都加入工作节点中:

核心配置文件是flink-conf.yaml
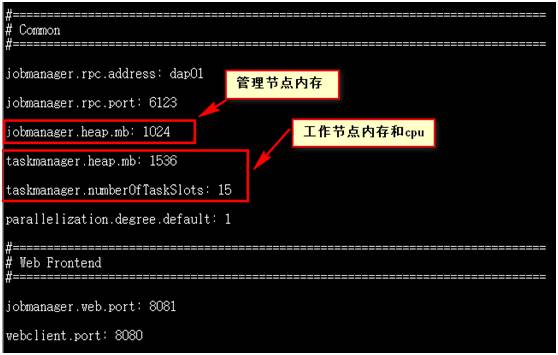

配置好上述文件之后将配置文件同步到另外2台机器。
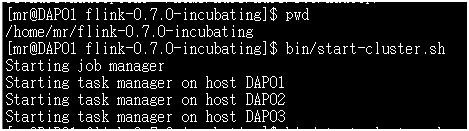
启动执行Flink的bin目录下的start-cluster.sh脚本
停止执行Flink的bin目录下的stop-cluster.sh脚本
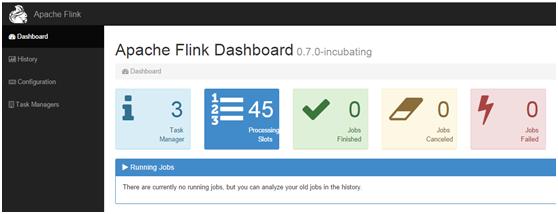
启动完成,可以看见8081端口的内容:
命令提交需要进入如下/home/mr/flink-0.7.0-incubating/bin目录,运行Flink进行提交:
./flink run-p 45 ../examples/flink-java-examples-0.7.0-incubating-WordCount.jar hdfs://haCluster/zyf/wordcountsourcehdfs://haCluster/zyf/wordcountsourceresultflink15
-p表示并行多少个,然后指定jar包

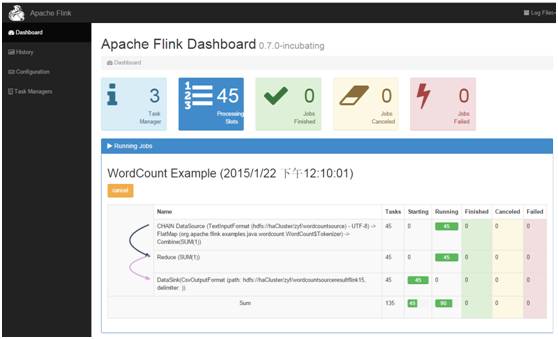
提交后web界面如下:
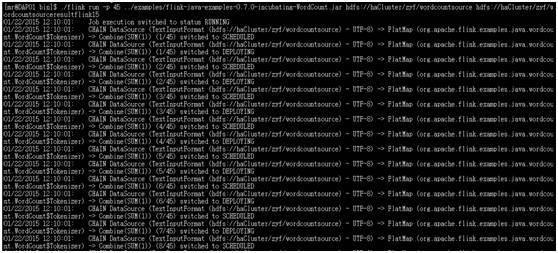
执行过程:
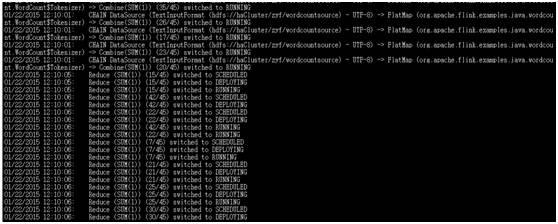
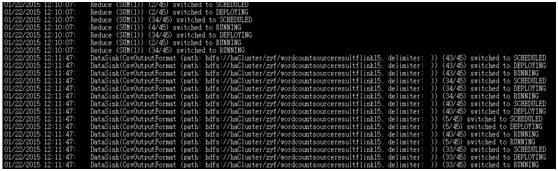
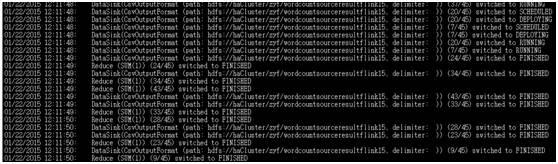
10G数据wordcount大概在1min50s,spark10G数据同样集群在70s。
Wordcount代码如下:

读取、写入 HDFS文件非常类似Spark,从HDFS上读取文件生成DataSet对象
然后调用DataSet对象的转换方法进行变换,最终进行相关数据收集写入。
以上是关于实战手把手 | Flink安装指南的主要内容,如果未能解决你的问题,请参考以下文章
Redis 技术探索「数据迁移实战」手把手教你如何实现在线 + 离线模式进行迁移 Redis 数据实战指南(scan模式迁移)
Redis 技术探索「数据迁移实战」手把手教你如何实现在线 + 离线模式进行迁移 Redis 数据实战指南(数据检查对比)