海盒大数据平台流处理平台--Flink介绍与展望
Posted 东方金信
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了海盒大数据平台流处理平台--Flink介绍与展望相关的知识,希望对你有一定的参考价值。
在如今数据爆炸的时代,企业的数据量与日俱增,大数据产品层出不穷。今天给大家分享一款产品—— Flink,该项目目前已融合在海盒大数据流处理平台。
很多人可能都是在 2015 年才听到 Flink 这个词,其实早在 2008 年,Flink 的前身已经是柏林理工大学一个研究性项目, 在 2014 被 Apache 孵化器所接受,然后迅速地成为了 ASF(Apache Software Foundation)的顶级项目之一。
目前,海盒大数据监控管理系统能够对Flink进行统一的安装与监管,实现向导式的一键安装部署,实时监控、报警,界面化服务启停、配置管理,实现与海盒大数据平台完美融合,大大提升大数据平台的处理能力,提高处理效率。
Flink 是一个针对流数据和批数据的分布式处理引擎,它主要是由 Java 代码实现,目前主要还是依靠开源社区的贡献而发展。对 Flink 而言,其所要处理的主要场景就是流数据,再换句话说,Flink 会把所有任务当成流来处理,这也是其最大的特点。Flink 可以支持本地的快速迭代,以及一些环形的迭代任务,并且 Flink 可以定制化内存管理。在这点,如果要对比 Flink 和 Spark 的话,Flink 并没有将内存完全交给应用层,这也是为什么 Spark 相对于 Flink,更容易出现 OOM 的原因(out of memory)。就框架本身与应用场景来说,Flink 更相似于 Storm。如果之前了解过 Storm 或者 Flume 的读者,可能会更容易理解 Flink 的架构和很多概念,下面让我们先来看下 Flink 的架构图。
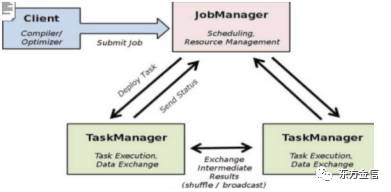
从上面的图中我们可以了解到 Flink 几个最基础的概念,Client、JobManager 和 TaskManager。Client 用来提交任务给 JobManager,JobManager 分发任务给 TaskManager 去执行,然后 TaskManager 会汇报任务状态。看到这里,有的人应该已经有种回到 Hadoop 一代的错觉。确实,从架构图去看,JobManager 很像当年的 JobTracker,TaskManager 也很像当年的 TaskTracker。然而有一个最重要的区别就是 TaskManager 之间是流(Stream)。其次,Hadoop 一代中,只有 Map 和 Reduce 之间的 Shuffle,而对 Flink 而言,可能是很多级,并且在 TaskManager 内部和 TaskManager 之间都会有数据传递,而不像 Hadoop,是固定的 Map 到 Reduce。
Apache Flink 是一个面向分布式数据流处理和批量数据处理的开源计算平台,它能够基于同一个Flink运行时(Flink Runtime),提供支持流处理和批处理两种类型应用的功能。现有的开源计算方案,会把流处理和批处理作为两种不同的应用类型,因为他们所提供的SLA是完全不相同的:流处理一般需要支持低延迟、Exactly-once保证,而批处理需要支持高吞吐、高效处理,所以在实现的时候通常是分别给出两套实现方法,或者通过一个独立的开源框架来实现其中每一种处理方案。例如,实现批处理的开源方案有MapReduce、Tez、Crunch、Spark,实现流处理的开源方案有Samza、Storm。 Flink在实现流处理和批处理时,与传统的一些方案完全不同,它从另一个视角看待流处理和批处理,将二者统一起来:Flink是完全支持流处理,也就是说作为流处理看待时,输入数据流是无界的;批处理被作为一种特殊的流处理,只是它的输入数据流被定义为有界的。基于同一个Flink运行时(Flink Runtime),分别提供了流处理和批处理API,而这两种API也是实现上层面向流处理、批处理类型应用框架的基础。
提到Flink,就不得不说Spark,Spark在处理批处理任务,可以使用 RDD,而对于流处理,可以使用 Streaming,然其实际还是 RDD,所以本质上还是 RDD 抽象而来。但是,在 Flink 中,批处理用 DataSet,对于流处理,有 DataStreams。思想类似,但却有所不同:其一,DataSet 在运行时表现为 Runtime Plans,而在 Spark 中,RDD 在运行时表现为 Java Objects。在 Flink 中有 Logical Plan ,这和 Spark 中的 DataFrames 类似。因而,在 Flink 中,若是使用这类 API ,会被优先来优化(即:自动优化迭代)。如下图所示:
而在 Spark 中,RDD 就没有这块的相关优化,如下图所示:
Flink的核心是一个分布式基于流的数据处理引擎,他的核心竞争力有以下几点,高吞吐、低延时、事件窗口。其对于流式计算和迭代计算支持力度将会更加增强,日后Flink的发展重点,将是数据科学和平台API化,Flink 栈中提供了很多高级 API 和满足不同场景的类库:机器学习、图分析、关系式数据处理等,除了传统的统计算法外,还包括学习算法,同时使其生态系统越来越完善,随着Flink的不断强大,相信以后会定义第四代数据引擎,为大家带来更高效方便的数据处理工具。
以上是关于海盒大数据平台流处理平台--Flink介绍与展望的主要内容,如果未能解决你的问题,请参考以下文章