阿里Uber谷歌苹果的大牛都来了,Apache Flink技术盛宴有何魅力?
Posted 阿里技术
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了阿里Uber谷歌苹果的大牛都来了,Apache Flink技术盛宴有何魅力?相关的知识,希望对你有一定的参考价值。
阿里妹注:今年4月,第三届Flink Forward大会在旧金山举行。Google,Uber,Airbnb,Amazon,Apple,Facebook等公司大牛齐聚一堂。下面由阿里工程师、同时也是演讲嘉宾的大沙为你带来精彩的参会感受。
王绍翾,淘宝花名"大沙",2015年加入阿里巴巴集团,加入阿里之前,曾在Facebook开发分布式图关系数据库TAO。目前在阿里计算平台事业部,负责实时计算查询和优化。
以下是参会记录全文:
Apache Flink是德国柏林工业大学的几个博士生和研究生从学校开始做起来的项目,之前叫做Stratosphere。他们在2014年开源了他们的项目,起名为Flink,并且成立了公司,起名为dataArtisans。
Flink forward@San Francisco 于2017年4月11日在旧金山市内举行。这是第三届Flink Forward大会,前两次分别于2015和2016年的秋天在德国的Berlin举行(Blink团队曾代表阿里巴巴参加了2016年的大会并做了分享)。这是第一次在德国之外举行的Flink Forward大会,选在创业公司林立的旧金山举行这次会议,很显然Flink团队期望通过这次会议让全世界了解从而使用Flink。这同时也彰显了flink团队对其在流计算方面的优势和实力充满了信心。


下面我给大家介绍一下我认为比较重要的几个session,另外再分享一下自己参会的感受和思考,希望对大家有帮助。
议题分享
我第一个介绍的session,自然是来自于Stephan Ewen(Flink技术带头大哥兼dataArtisans CTO)。因为工作的原因我和Stephan接触过几次,最切身的体会这人非常谦虚,而且很会解释问题。就算你提出再小白的问题,他能耐心的听完你的问题,理解你的困惑,再耐心的给你讲解。
Stephan在这届Flink Forward大会一共给了两个talk,一个是关于大规模部署和运行Flink的经验分享,一个是在大会结束时候做的总结性的talk,包括了stephan本人对流计算的展望。为了方便与大家由浅入深的了解Flink,我先分享他对Flink计算整体总结的session,再介绍他的一个比较偏技术的关于大规模部署和使用Flink的经验分享。
DataArtisans -Stephan做Flink计算的概要总结
Session名字:
Convergence of real-time analytics & data-driven applications
Session视频链接:
https://www.youtube.com/watch?v=i6RY9GFdlg4&list=PLDX4T_cnKjD2UC6wJr_wRbIvtlMtkc-n2
Stephan认为2016年越来越多的公司和业务场景开始使用流计算,而在2017年流计算会在更多的场景全面释放异彩。

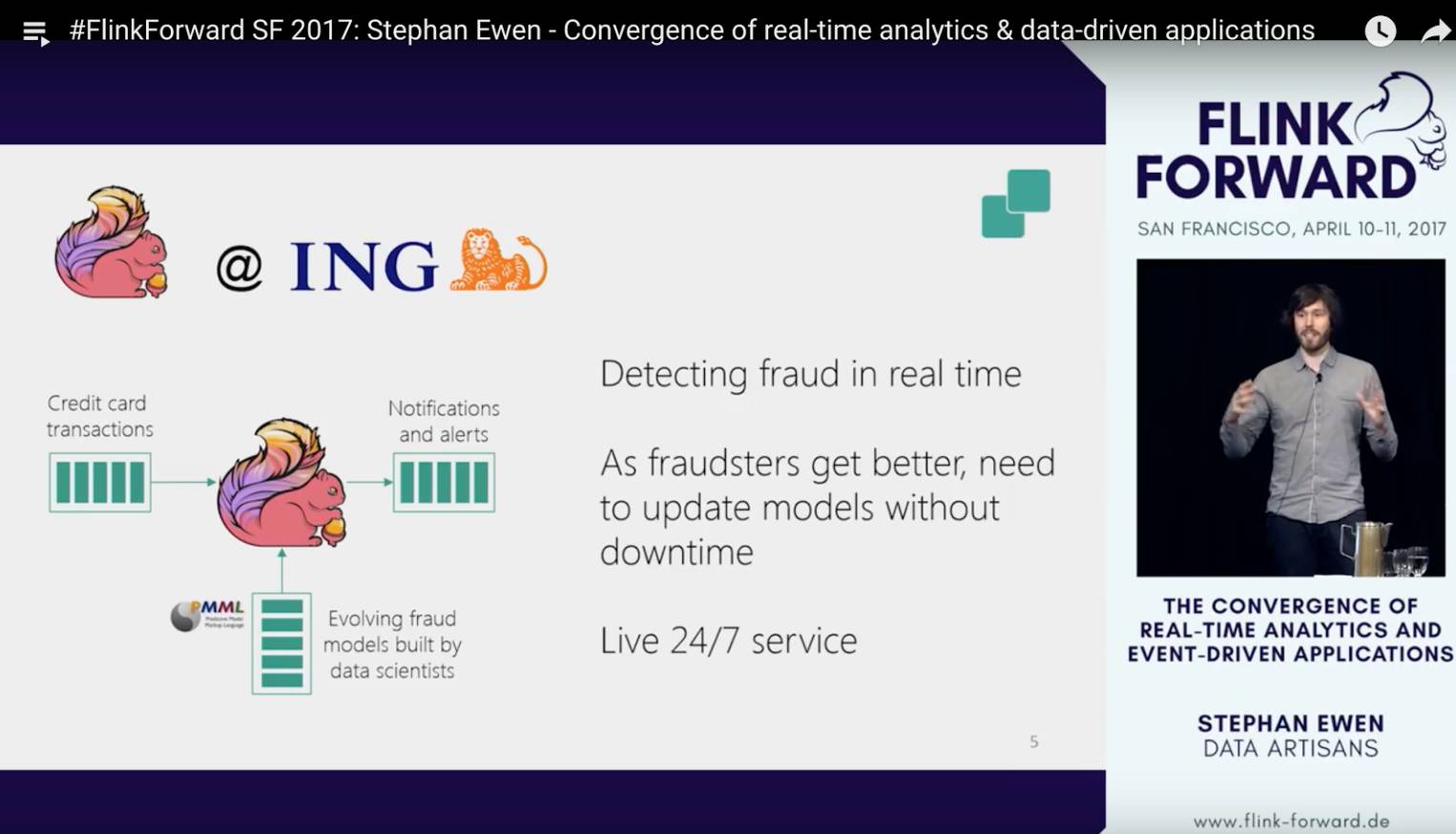
接下来stephan开始介绍他所熟悉的Flink应用场景,第一个use case是ING。这家金融服务公司利用Flink来实时的检测并(通过离线训练或者设计好的model)识别信用卡被盗刷的情况,从而能够及时发出报警。

第二个应用场景是Uber基于Flink新开发的实时数据分析平台,Athena X。这个数据平台会被用来给机器学习提供数据,做大数据分析,做算法的abtest,以及实时反作弊检测。另外值得一提的是AthenaX只提供Flink SQL这一种用户接口,顿时觉得Uber的业务小哥们很幸福,从此再也不用为优化job而担忧。这次Flink forward,Uber也派出强大的阵容,他们有两个talk,我下面会详细介绍。
第三个应用场景是NetFlix,他们开发了一个系统叫做Keystone pipeline, 是现在已知的最成功的Flink on 亚马逊AWS的案例。作为一个SPaaS(Stream Processing as a Service),Keystone pipeline有着非常友好的用户可视化操作界面。一个流计算业务在web UI上拖拖拽拽几下就能完成的设计。NetFlix这个项目的manager Monal 在这次Flink forward做了一个keynote分享,我下面也会介绍。

接下来终于到阿里集团的Blink了。Blink是我们从2015年开始基于Flink为咱们阿里集团内部的搜索,推荐,机器学习平台等各种场景量身打造的一个全新的实时计算引擎。在过去的一年中,我们和Flink社区深度合作,在实时计算的runtime和API等各个方面取得了非常多的成果。正如Stephan下面的ppt所示,阿里巴巴现在是整个Flink社区最活跃且贡献最多的contributor, 我们相信和开源社区世界一流的工程师合作,基于阿里大数据业务场景,一定能做出世界领先的流计算平台。

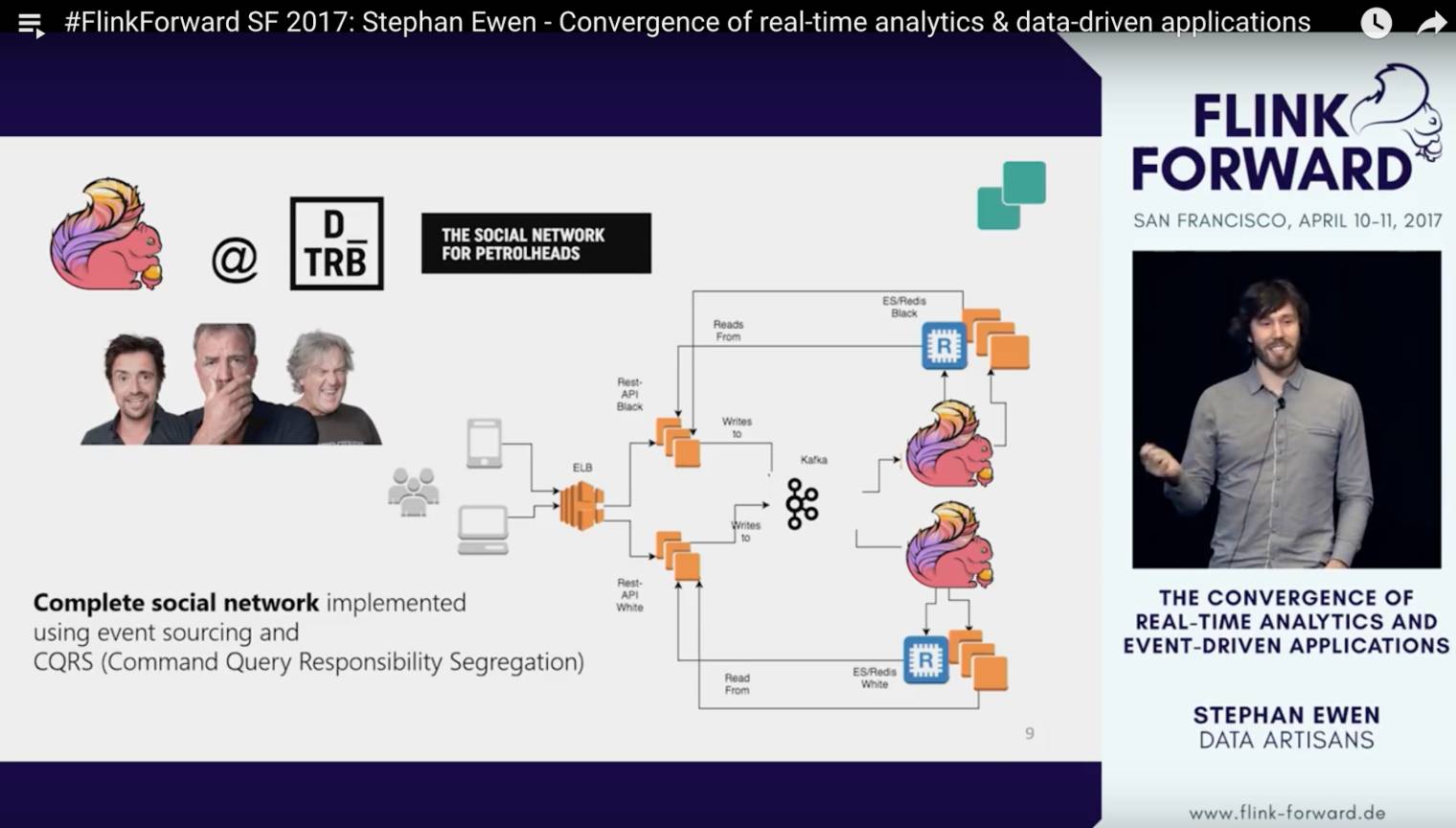
最后一个案例,stephan介绍了一个social network创业公司。这家公司单单依靠Kafka,Flink,ElasticSearch等几个组件就搭起了整个服务的后端,也是蛮神奇的。像stephan这种tech geek肯定对这种黑科技倍加喜爱,也难怪会专门在大会的结束的session里专门提一下。
然后,stephan缓缓道出这个session的重头戏:流计算的前世,今生,和未来。
最早的流计算是给batch job做嫁衣的。早期的计算大量的都是batch job,例如搜索索引index的build。早期搜索引擎的更新可能需要T+1的时间。慢慢的,这种T+1的更新模式已经无法满足业务和用户的需求。技术开发者们就开始用增量计算的模式同步一些比较重要的实时更新。这种流计算架构叫做lambda。
随着软硬件的不停的迭代进步,Flink流计算框架在合适的时间点诞生了(这点非常类似于沉睡多年的deap learning的崛起,没有新一代的软硬件计算的升级,deap learning也只能停留在书本上)。在Flink的流计算框架下,streaming process可以既满足低延迟的需求,又能满足数据的正确性(exactly once),这种特性能够很好的满足实时数据分析的需求。
在这种框架下,批作业可以看作是流计算作业的一个特例,核心的区别是有界的(bounded),还是无界的(unbounded),这个映射到计算架构里面的本质区别是计算优化的策略不同。OK,这是流计算的今天。那么明天呢?
Stephan认为流计算可以被用于更为广阔的场景,例如event-driven applications。事实上,在阿里集团内部,我们早已不是仅仅用流计算做实时数据的统计和分析,而早已经广泛的将流计算应用于event-driven application中了。例如,在搜索和推荐场景中,我们将Blink使用在实时机器学习平台上,根据采集到用户的行为,触发机器学习算法,更新算法模型,从而反馈新的搜索和推荐结果给用户。具体Flink是如何能够closely match流计算这些个趋势的,各位看官请移步youtube video查看细节吧。

DataArtisans - Stephan对大规模部署和运行Flink的总结
Session名字:
Experiences running Flink at Very Large Scale applications
Session视频链接:
https://www.youtube.com/watch?v=Sm5nHu7Mfsk&index=28&list=PLDX4T_cnKjD2UC6wJr_wRbIvtlMtkc-n2
这是本次大会Stephan的另外一个session,主要分享了大规模部署和使用Flink上遇到的一些问题和经验教训。这个session介绍了非常多的Flink runtime相关的技术细节,包括checkpoint的一些基础知识(这应该是我见过对Flink checkpoint解释最好的视频之一),以及Flink backend state和存储state的file system等相关知识。对Flink runtime感兴趣的同学可以去仔细听听。


Uber - 基于Flink的实时数据分析
Session名字:
Real Time Analytics in the Real World
Session视频链接:
https://www.youtube.com/watch?v=-3OVXCkrm-w&list=PLDX4T_cnKjD2UC6wJr_wRbIvtlMtkc-n2
这个session是这次Flink Forward一个keynote session,Chinmay是Uber实时计算平台的技术负责人。他介绍了Uber实时计算架构的演变的心路历程,包括早期的Artemis(基于storm),Apollo (基于memSQL),和Athena(基于Samza) 三个平台,以及近期在开发的Athena(Flink)。

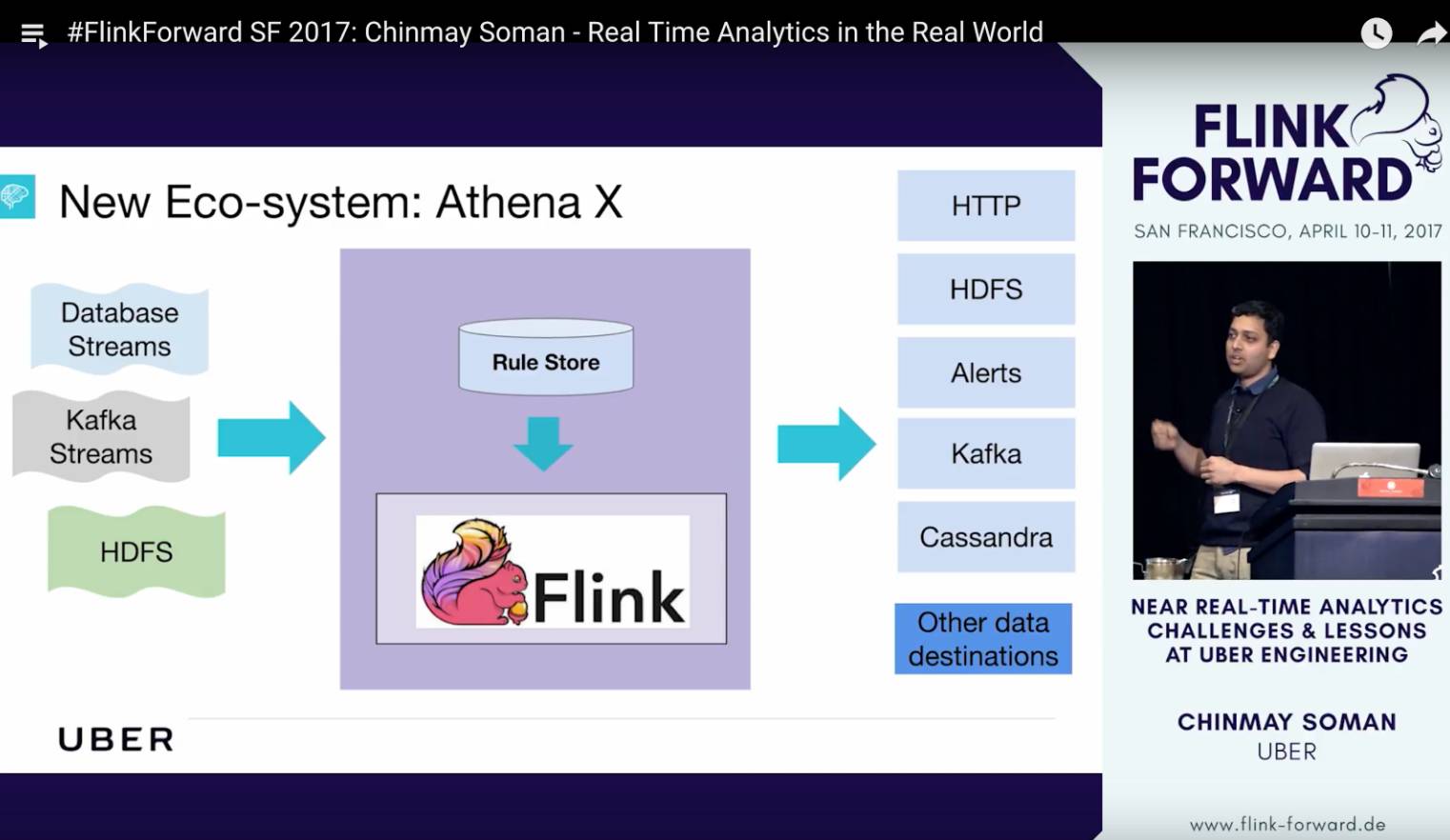
值得一提的是,Uber几乎所有的实时计算的job都可以用SQL写出来,苦在之前一直都没有能很好支持SQL的流计算引擎。Flink支持SQL,提供实时,准确的数据计算。Chinmay觉得Flink完美的满足了Uber所有的数据计算的需求。
Uber - 实时数据计算平台AthenaX
Session名字:
AthenaX: Uber’s streaming processing platform on Flink
Session视频链接:
https://www.youtube.com/watch?v=VURuT8GbExo&index=16&list=PLDX4T_cnKjD2UC6wJr_wRbIvtlMtkc-n2
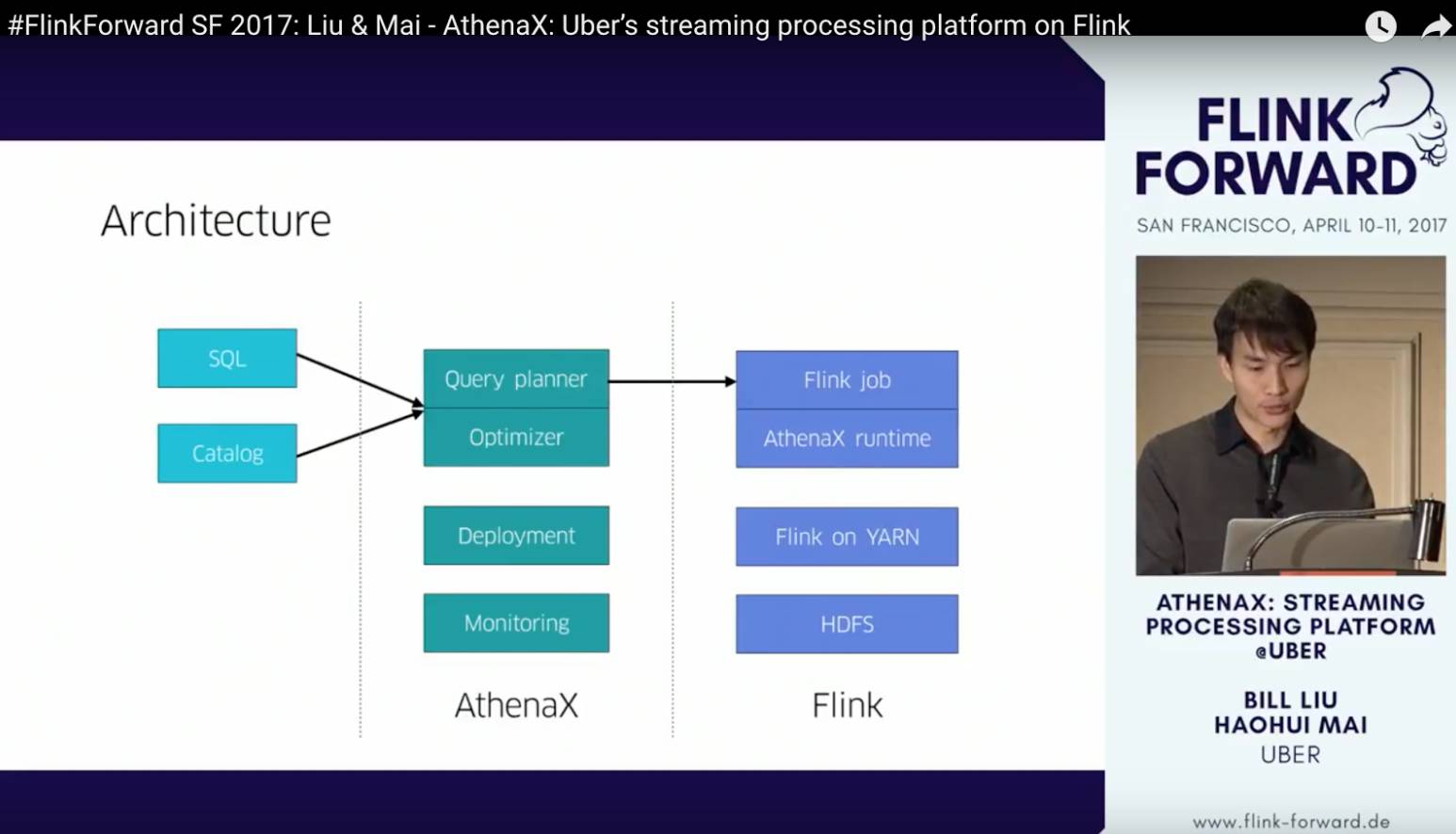
Haohui Mai和Bill Liu是Uber的流计算平台开发工程师。他们从2016年年底开始参与社区开发完善SQL。最近要发布的最新的Flink release1.3,有不少SQL的feature是这俩Uber的哥们开发的。这个Session是一个比较偏技术的session,他们介绍了不少AthenaX的实现细节。
AthenaX的整体技术架构如下图所示。AthenaX位于Flink job(我的理解这里指的是dataStream job)和用户的SQL query之间,主要负责完成SQL的编译,优化。同时AthenaX作为一个平台还开发了Flink job的部署和监控组件。
值得注意的是,Flink自身基于calcite有原生的SQL的编译和优化的阶段。看起来这部分逻辑在Uber被上提到AthenaX平台内部中做了,我猜测Uber应该是基于原生的Flink+Calcite之上,加了一些独特的SQL的解析和优化的规则。另外,Uber公司内部对所有的数据接口的数据存储(例如kafka和memTable)都有一个很好的catalog元数据管理服务。
Flink SQL现在对catalog支持的并不是特别好,所以AthenaX自然会做一些这些方面的桥接。我猜想对flink table的DML管理都应该是通过AthenaX平台的接口来做的。除此之外,haohui还提到,Uber对数据使用了lazy deserialization技术(只对要用的数据进行反序列化,从而节省CPU)。

Netflix - Flink on AWS的实时数据分析服务
Session名字:
Stream Processing with Flink at Netflix
Session视频链接:
https://www.youtube.com/watch?v=sPB8w-YXX1s&index=4&list=PLDX4T_cnKjD2UC6wJr_wRbIvtlMtkc-n2
Netflix的Monal指出现在科技公司对实时流计算的需求已经从nice to have到了must to have。Netflix这个看似只提供流媒体服务的公司,其实类似于其他所有大公司一样,它的业务增长现在越来越依赖于数据驱动。

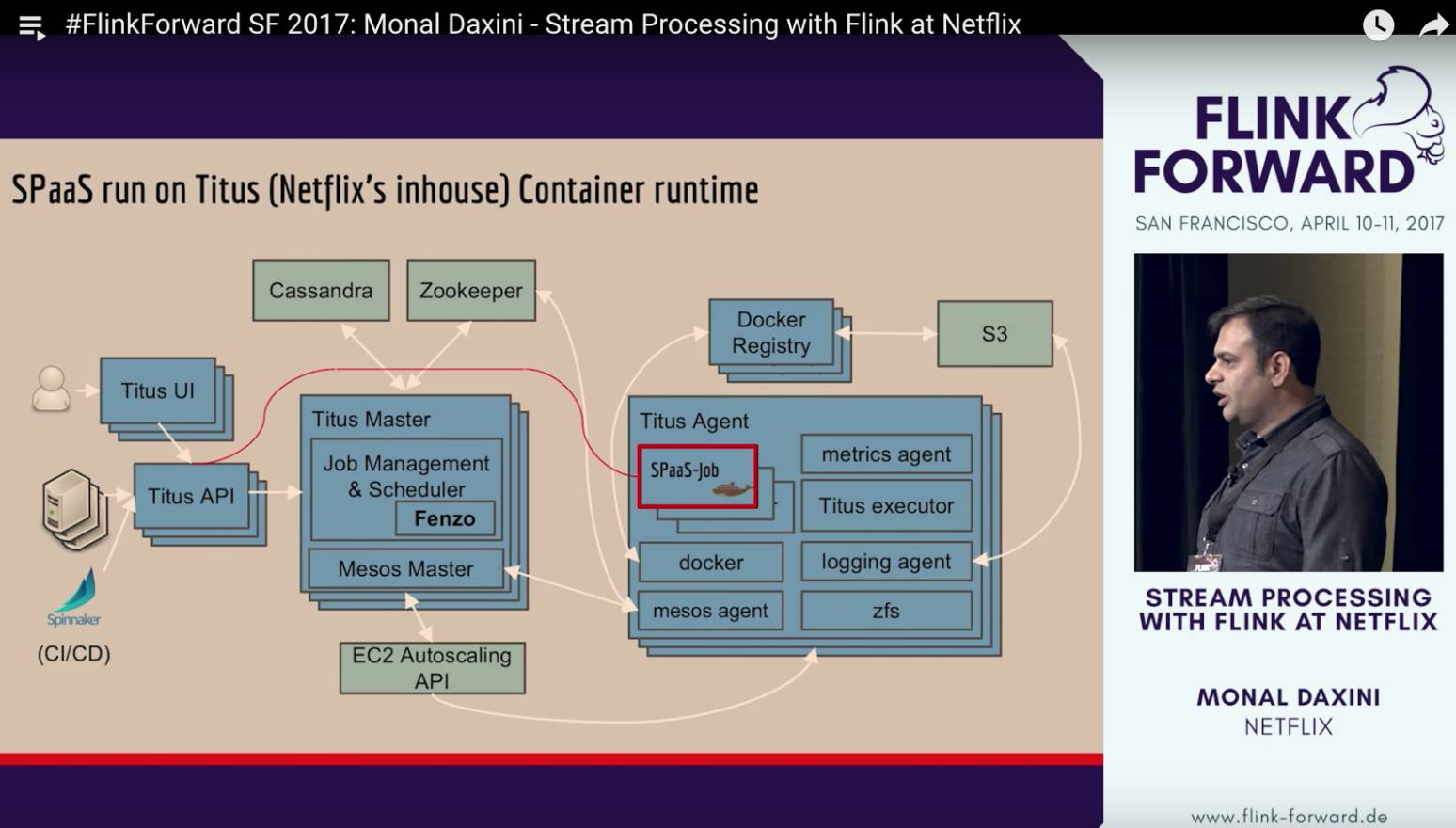
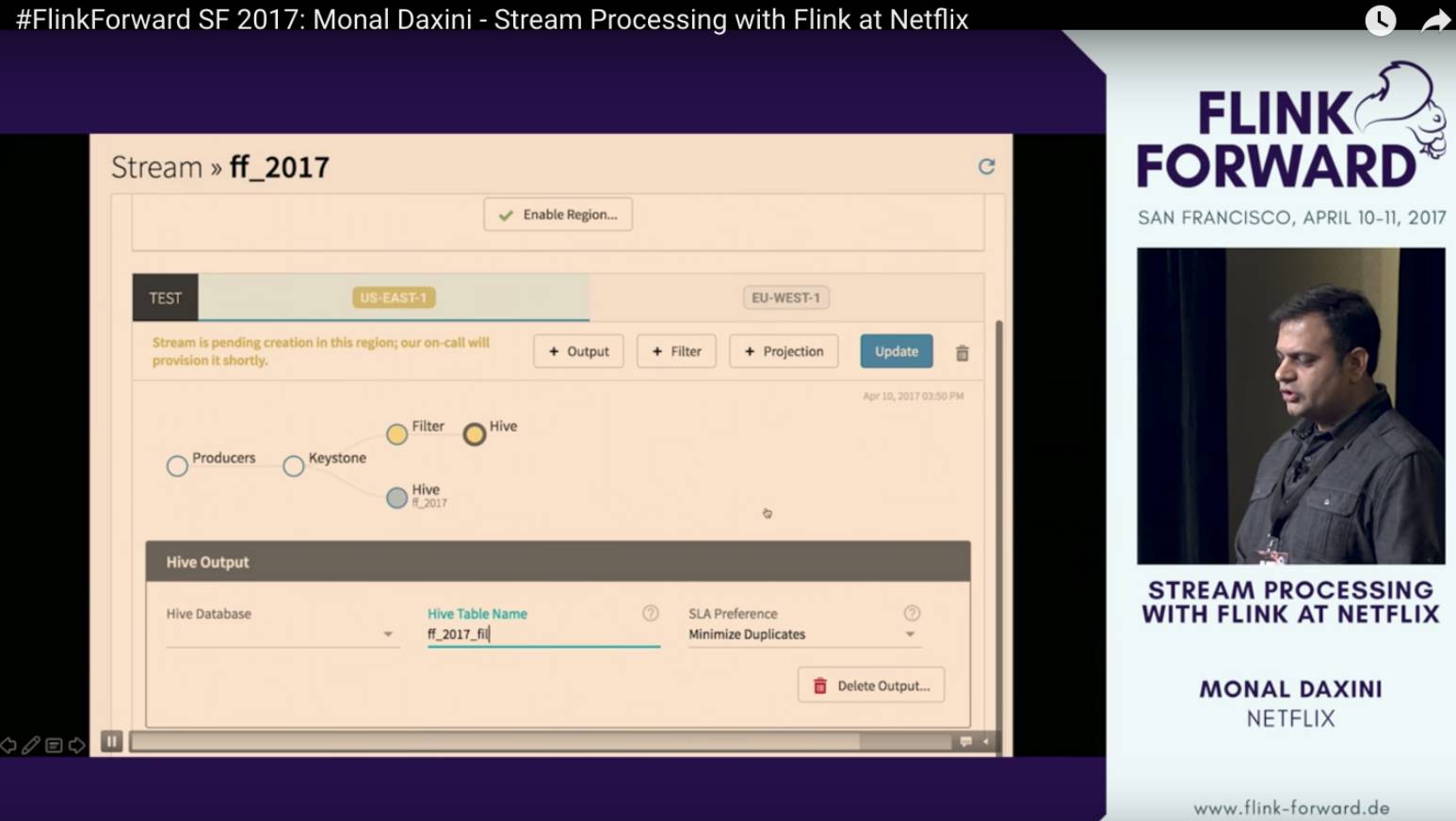
Netflix每天要处理1兆流计算事件,数据体量达到每天3PB。为了提升流计算性能并且让用户只专注于数据分析,Netflix基于Flink构建了一个能够自助服务的,可扩展的,容错的,多租户的以“流处理为服务”的平台,叫做Keystone。NetFlix Keystone的最大的亮点就是它真正的做到了流计算的服务化,用户可以在web-UI上完成一个流计算的所有配置,并且这个流计算任务可以通过Netflix Titus服务直接部署到全美多个亚马逊AWS服务器上。
Alibaba - Blink在Flink runtime上的改进
Session名字:
Runtime Improvements in Blink for Large Scale Streaming at Alibaba
Session视频链接:
https://www.youtube.com/watch?v=-19fvqcZstI&index=17&list=PLDX4T_cnKjD2UC6wJr_wRbIvtlMtkc-n2
王峰(花名“莫问”)和王治江(花名“淘江”)在分享中对历史做了一个简单的回顾:阿里从2015年开始调研Flink,在2016年初开始运行生产业务。目前Blink已经在阿里巴巴生产环境运行将近一年时间,支持了阿里巴巴多条核心业务线。现在最大的生产集群机器数已经超过1500台,每秒支持数十亿次的实时计算(全天过100兆的计算量),最大的生产任务已经超过5000个并发,包含10TB级的State,亿级TPS。

Blink在去年阿里巴巴双11购物节中完成了第一次正式的挑战,搜索和推荐全实时链路全天稳定运行,不仅保证了淘宝、天猫商品实时更新无延迟,同时基于Blink的在线机器学习平台Porsche由于能够较好的将用户和商品行为实时分析,进行及时的算法处理和更新,最终大幅的提升了双11的商品成交转化率。

为了和全球优秀工程师一起打造世界一流的计算引擎,我们在一年前决定和将Blink的一些核心代码与Flink社区代码merge。凡是和Flink共享的基础核心框架,Blink在这些框架、协议和接口上的改进都会回馈给社区,保证兼容性。一些阿里集团特有的,诸如:资源管理,状态存储,运维监控、Debug工具,输入输出层等,Blink都会根据阿里巴巴技术生态和业务场景进行定制开发,使得Blink能够在和Flink共享基础内核和生态的前提下,依然能够灵活支持阿里巴巴自身的场景需求。
Alibaba - Blink在Flink TableAPI & SQL上的改进
Session名字:
Blink’s Improvements for Flink TableAPI & SQL
Session视频链接:
https://www.youtube.com/watch?v=WrO48xCr4pw&index=9&list=PLDX4T_cnKjD2UC6wJr_wRbIvtlMtkc-n2
蒋晓伟(花名“量仔”)和我分享的另一个主题是介绍过去的一年Blink团队在流计算SQL领域的工作和进展。Table API大家可以简单的理解为scala/java版的SQL,当标准SQL无法支持某些特定的流计算场景的时候,我们可以使用TableAPI来扩展,所以TableAPI实际上就是Flink的DSL-SQL。

2016年初的时候Blink正式上线,我们开始迁移业务。初期的Blink业务都是基于Flink dataStream实现的。很快我们发现要迁移的业务如果用全部都用DataStream重新编写一遍将是一个很大的工程。于是,我们就开始尝试更简洁的Flink SQL API。不幸的是当时的TableAPI 和 SQL功能非常有限(只支持SELECT和WHERE子句)。因此,我们决定自己动手来开发诸如Join,UDF,UDTF,UDAGG,window聚合,和撤回等等流计算所必须的功能。
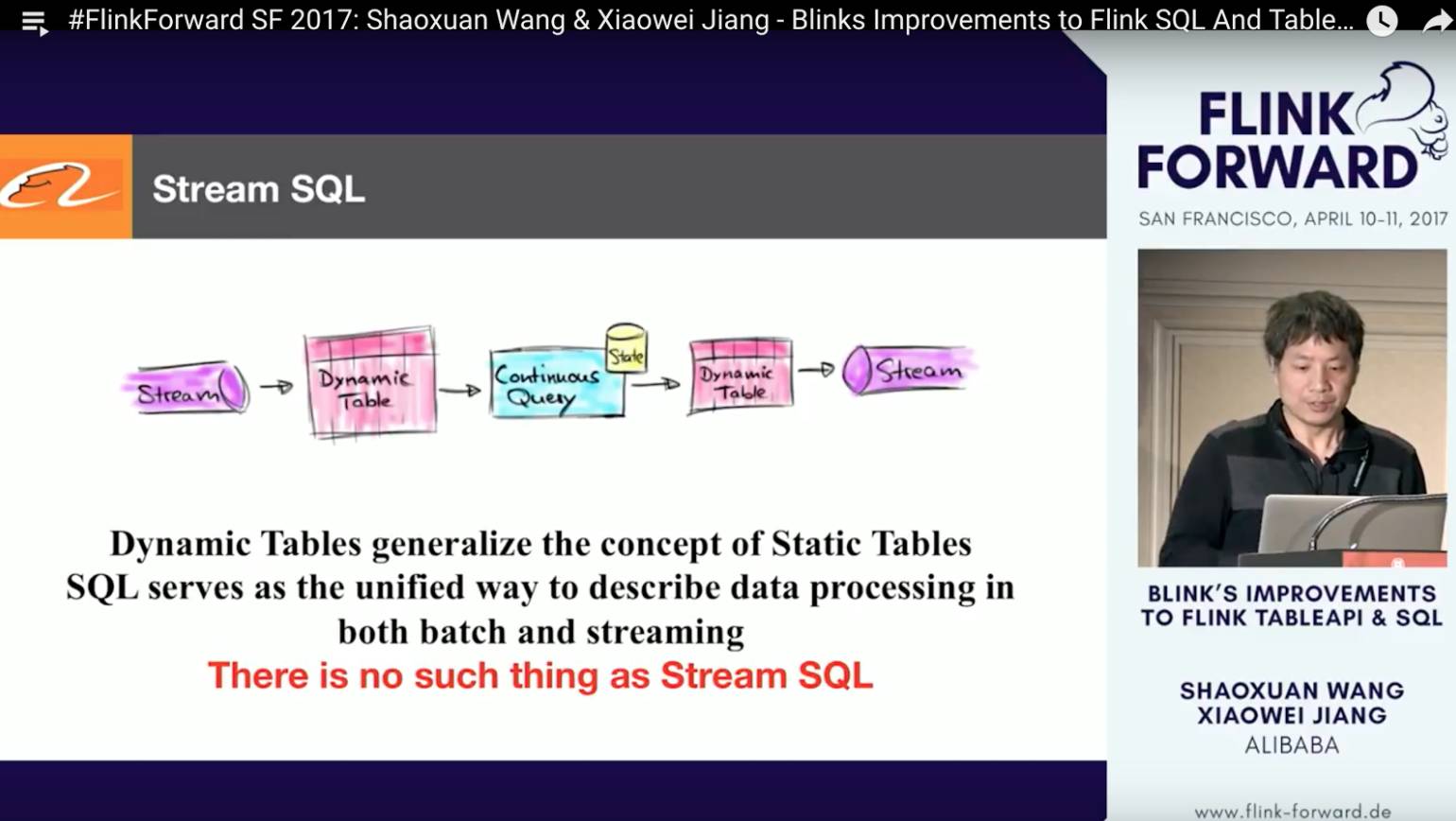
随着Blink SQL的逐步完善,我们成功的接入的大量的业务需求,我们真正的意识到Table API / SQL在抽象和统一用户业务逻辑上的强大之处。另外一方面,我们也意识到本质上并不存在特殊的streaming SQL,流和批的计算可以自然而然的在传统SQL这一层统一。

流计算所特有的unbounded的特性其实本质只是何时观测抽样计算结果,这种属性可以作为job config来设置而无需去改变用户的business query logic。
为了更好抽象语义从而达到流和批的统一,我们和Flink社区一起引入了dynamic table的概念。感兴趣的同学,可以去听一下我们session视频,或者移步去阅读一下我们今年在Flink官方blog上发表的这方面的介绍:
https://flink.apache.org/news/2017/04/04/dynamic-tables.html
总结
由于篇幅和时间的原因,本文我只挑选了一些我参加的或者比较熟悉的session介绍。除了这些之外还有很多比较有意思的session,例如如何用Flink来做机器学习,包括built-in的libraries和非built-in(例如tensorFlow) 的,大家感兴趣的都可以用文末的链接找到相关的视频。
总体来讲,今年的Flink Forward较往年相比,多了很多公司来分享,尤其有很多湾区的知名的科技公司,例如Google,Uber,Netflix等等。参加会议的公司就更多了,按照官方的报名表来看有90+公司参加了这次大会(包括Airbnb,Amazon,Apple,Facebook,Hortonworks,MapR等等)。 作为局内人,可以明显的感觉到随着Flink的性能和功能的进一步完善,在未来的1-2年内,Flink必将会迎来更大范围的adoption。
我们在与Flink开源社区的合作也摸索的度过了近一年,收获颇丰。一方面双方建立了良好的信任,Flink社区对我们的任何一个proposal都非常重视,另一方面我们的设计以及代码也得到整个社区全世界范围内的优秀工程师的review,整体的设计水平得到了质的提升。
正如stephan分享中所说,阿里巴巴是Flink现在的最大的contributor,在runtime方面,我们帮助社区贡献了若干从大规模部署到性能,再到failover方面的优化。这些优化使得Flink的易用性和性能得到了大大的提升。在用户API方面,过去的一年时间里,我们和社区合作,把Blink tableAPI & SQL从一个prototype做到了一个production ready的状态。一个强大完备的tableAPI & SQL必将会对整个Flink生态的推广起到极大的推动作用。
还有,给攻城狮们推荐一篇5月19日量仔刚在国外dataversity网站发表的署名博文,“A Year of Blink at Alibaba: Apache Flink in Large Scale Production” (by Xiaowei Jiang, http://www.dataversity.net/year-blink-alibaba),这边文章详细介绍了我们是如何一步一步优化Flink到今天的Blink的心路历程。里面不乏在面对各种选型(包括runtime,和API接口)的时候的思考,也介绍了我们是如何一步一步解决各种大规模部署和使用Blink的问题的。
最后,不免落俗一下,阿里巴巴实时计算团队(杭州,北京,美国)诚邀各种牛人(存储,计算,分布式,大数据,甚至前端)加入。对技术充满热情,极限编程,敏捷开发者,优先考虑。如果有对流计算SQL & Table API(流计算的SQL在开源范围内我们应该是比较领先的,你来了就是头几个吃螃蟹的)感兴趣的兄弟,可以直接联系我:shaoxuan.wsx@alibaba-inc.com
实时计算的问题远没有全部解决,我们的脚步并没有放缓,Blink & Flink is still forwarding,未来的分享会更加精彩,敬请期待。

附:几个有用的链接
Flink forward @ SF官网:
http://sf.flink-forward.org/
大会session列表:
http://sf.flink-forward.org/kb_day/day2/
所有session的ppt slides:
https://www.slideshare.net/FlinkForward/presentations
所有session视屏:
https://www.youtube.com/playlist?list=PLDX4T_cnKjD2UC6wJr_wRbIvtlMtkc-n2
推荐阅读
关注「阿里技术」
把握前沿技术脉搏
转载 l 合作 l 投稿
lunalin.lpp@alibaba-inc.com
以上是关于阿里Uber谷歌苹果的大牛都来了,Apache Flink技术盛宴有何魅力?的主要内容,如果未能解决你的问题,请参考以下文章
来都来了,你确定不看看,阿里云Centos8安装Docker!!(图文并茂版!!!)