首发!Apache Flink 干货合集打包好了,速来下载
Posted 阿里技术
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了首发!Apache Flink 干货合集打包好了,速来下载相关的知识,希望对你有一定的参考价值。
最近的一份市场调查报告显示,Apache Flink 是2018年开源大数据生态中发展“最快”的引擎,和2017年相比增长了125% 。为了让大家更为全面地了解Flink,我们制作了一本电子干货合集:《不仅仅是流计算:Apache Flink实践》,融合了Apache Flink在国内各大顶级互联网公司的大规模实践,希望对大家有所帮助。
在这本合集里,你可以了解到:
Flink如何为整个阿里集团平稳度过双十一立下汗马功劳?
如何为满足滴滴极为复杂的业务需求提供简单直观的API支持?
如何在字节跳动逐步取代原有的JStorm引擎,成为公司内部流式数据处理的唯一标准?

《不仅仅是流计算:Apache Flink实践》目录一览

Apache Flink已经被业界公认是最好的流计算引擎。然而Flink的计算能力不仅仅局限于做流处理。Apache Flink的定位是一套兼具流、批、机器学习等多种计算功能的大数据引擎。在最近的一段时间,Flink在批处理以及机器学习等诸多大数据场景都有长足的突破。此次专刊,旨在对Flink在大数据智能计算方面做一些简要的介绍。后续我们还将发布更多关于Flink在新场景的应用干货。
下面,我们邀请阿里资深技术专家、Apache Flink Committer 王绍翾老师(花名“大沙”),带领大家走进Flink的世界。

在全面介绍Flink的新进展之前,我先来介绍一些大数据和人工智能计算的背景。大数据计算的种类非常多,比较典型的,且被大规模使用的主要是3种类型:
批计算
流计算
交互式分析计算
批计算的特点是要计算的数据量比较大,但是往往对延迟不是特别敏感。流计算对延迟的要求非常高,这些作业的查询query往往是固定的。因此流计算作业往往需要提前调度起来,一旦数据到来就可以做快速的处理,节省了调度的开销。
最后一种是交互式分析,这种类型的大数据计算的特点是用户的查询query是不固定的,这些query往往是由用户随机的发出的。虽然查询不固定,在这种场景下,用户对查询的返回时间是有一定的要求的,这个时间介于批处理和流处理之间,越快越好,最好能做到秒级。
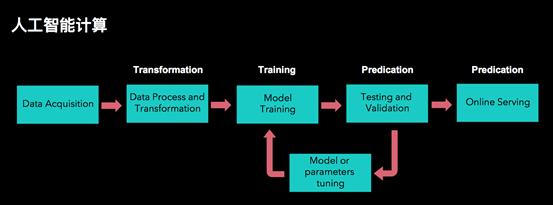
人工智能计算的种类很多,但是整体架构大多和上图所描述的类似。一个常见的ML pipeline通常涉及一系列的数据预处理、特征提取和转换、模型训练以及验证。如果验证后的效果符合预期,就可以将模型推到线上服务。如果不符合预期,算法工程师就需要调整算法模型或者参数,然后再做一次模型的训练和验证,直到对结果满意后,再将训练好的模型推上线服务。整个计算过程可以是对一个确定大小的数据按照批计算模式计算,也可以接入实时数据按照流计算模式进行计算。上面这个pipeline是人工智能计算最基础的流程,如果算法工程师对数据以及业务特点非常熟悉,他们就能设计出合理的算法模型和参数。但是往往更常见的情况是,算法工程师需要分析工具帮助他们理解数据。只有在很好地理解了数据特点之后,才能提取出更有用的特征,设计出更好的模型。因此,如下图所示,做好人工智能计算,不可或缺的一部分就是交互式分析。有了交互式分析,算法工程师可以对数据做各种ad-hoc query,从而帮助他们更好地理解数据。
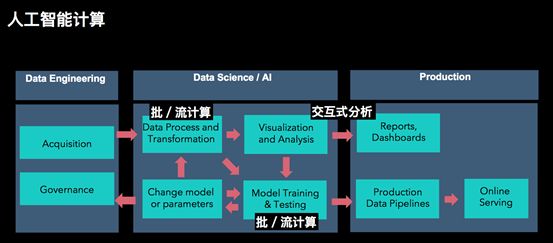
综上所述,可以看出人工智能计算和大数据计算是密不可分的。虽然人工智能计算变得越来越炙手可热,人们越来越多的提及人工智能而不是大数据,但是我们不能忘记,人工智能计算的基础是大数据计算,没有大数据计算提供算力和功能,人工智能计算只能停留在纸上谈兵的阶段。接下来,我把基于大数据计算的人工智能计算简称为“大数据智能计算”。

大数据和AI全景–2018(来源:http://mattturck.com/bigdata2018/)
那么怎么来搭建一套大数据智能计算系统呢?http://mattturck.com收集了所有大数据和AI的软件和平台。上面提到的每一种大数据计算场景都有好几种软件的选择,调研和选型这些软件本身就是一项巨大的工程。即使最后为每一套场景都选型了一种软件,那么后期的开发迭代和运维也难做到高效。因为每一套软件都需要专门的开发和运维团队负责,无论是在人力还是机器资源上都不能横向打通,势必会造成浪费。
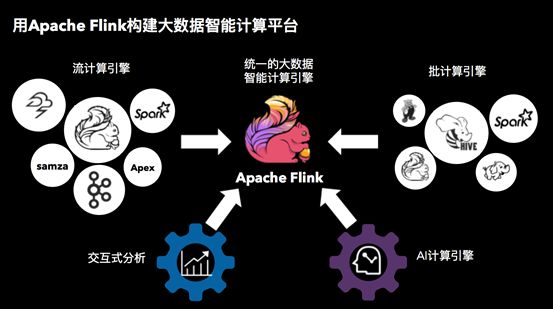
因此,阿里巴巴一直在思考是否可能有一套计算引擎解决如上的所有问题。经过仔细的选型,我们选择了Apache Flink,并围绕着Flink在打造一款通用计算引擎。Flink已经被业界公认是最好的流计算引擎。
它所具有的低延迟、高吞吐、保障Exactly-once的计算模式,使得它具有金融级的大数据处理能力。在批处理方面,基于流式的flow来处理批数据有着潜在的优势和扩展性。阿里巴巴利用Flink的天然特性,做了若干批计算方面的优化,使得Flink也成为了一款性能卓越的批计算引擎。在人工智能和交互式分析方面,我们也在逐步地完善Flink的易用性,生态,以及性能。另外,不得不提的是,Flink的流处理架构还天然的适合于正在快速崛起的本质更像流计算的IoT的场景。
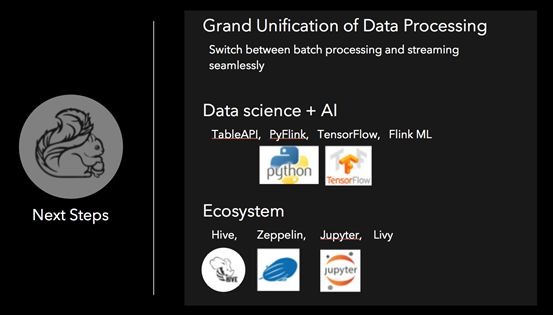
Flink的社区和生态一直在壮大。在流计算和批计算等场景慢慢使用Flink成为主流的同时,我们期望设计和推广出更多更完善的批流融合的场景。所有对Lamda架构有诉求的应用应该都可以用Flink完美的解决。早期的Lamda架构的设计也许很快会成为历史。
在易用性和生态方面,我们一方面帮助Flink社区在tableAPI,Python,以及ML等诸多领域发力,持续提升用户做Data science和AI计算的体验。另一方面,我们也在努力完善Flink和其他开源软件的融合,包括Hive,以及Notebook(Zeppelin, Jupyter)等等。这些诸多的努力,都是为了最终实现我们“一套引擎完美解决大数据智能计算”的初衷。Apache Flink自2014年开源至今也才4年,我们期待更多的企业和开发者们和我们一起参与到Apache Flink的社区和生态建设中来,共同把它打造成为全球最一流的开源大数据引擎。
为了让中国的开发者更近距离的接触Apache Flink,阿里巴巴在2018年12月20日到21日,在北京国家会议中心将承办Flink Forward China峰会。这是Flink Forward大会第一次在亚洲举行。届时将有超过1000名开发人员,系统/数据架构师,数据科学家,Apache Flink核心贡献者齐聚一堂,交流他们使用Flink的经验和体验。参会者也将有机会近距离聆听和了解阿里巴巴、滴滴、美团、字节跳动、以及Uber等诸多top互联网公司使用Apache Flink的最佳实践。

识别上方二维码,或者点击文末“阅读原文”,即可报名首届Flink Forward China峰会。
你可能还喜欢
关注「阿里技术」
把握前沿技术脉搏
以上是关于首发!Apache Flink 干货合集打包好了,速来下载的主要内容,如果未能解决你的问题,请参考以下文章
Flink流处理API大合集:掌握所有flink流处理API技术,看这一篇就够了
Flink流处理API大合集:掌握所有flink流处理API技术,看这一篇就够了
干货 | 如何使用功能强大的 Apache Flink SQL
bug记录: 本地idea运行没有问题,打包后出现ClassNotFoundException: org.apache.flink.util.OptionalFailure。