字节跳动Jstorm 到Apache Flink 的迁移实践
Posted 极客前程
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了字节跳动Jstorm 到Apache Flink 的迁移实践相关的知识,希望对你有一定的参考价值。
本文将为大家展示字节跳动公司将 Jstorm 任务迁移到Apache Flink 上的整个过程以及后续计划。你可以借此了解到字节跳动公司引入Apache Flink 的背景,Apache Flink 集群的构建过程,如何兼容以前的 Jstorm 作业以及基于Apache Flink 构建一个流式任务管理平台,本文将一一为你揭开这些神秘的面纱。
本文内容如下:
• 引入 Apache Flink 的背景
• Apache Flink 集群的构建过程
• 构建流式管理平台
• 近期规划
一、以引入Apache Flink 的背景
下面这幅图展示的是字节跳动公司的业务场景
首先,应用层有广告,AB 测试,推送,数据仓库等业务;其次中间层针对 python 用户抽象出来一个模板,用户只需要在模板里写自己的业务代码,结合一个 yaml 配置将 spout, bolt 组成DAG 图;最后将其跑在 Jstorm 计算引擎上。
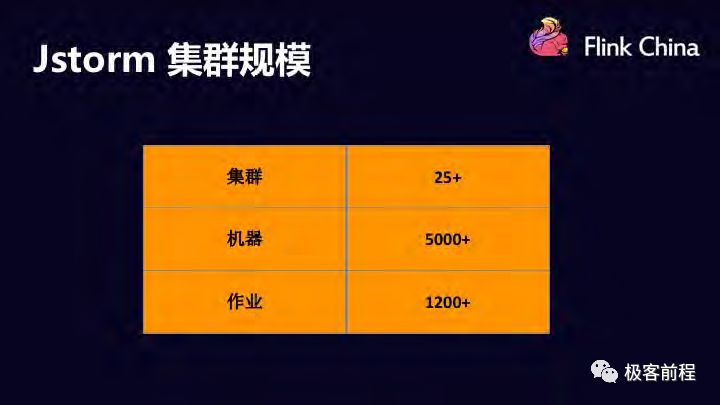
大概在17 年7 月份左右,当时 Jstorm 集群个数大概 20 左右,集群规模达到 5000 机器。
当时使用 Jstorm 集群遇到了以下几个问题:

• 第一个问题:单个 worker 没有内存限制,因此整个集群是没有内存隔离的。经常会出现单个作业内存使用过高,将整台机器的内存占满。
• 第二个问题:业务团队之间没有 Quota 管理,平台做预算和审核是无头绪的。当时几乎大部分业务方都跑在一个大集群上面,资源不足时,无法区分出来哪些作业优先级高,哪些作业优先级低。
• 第三个问题:集群过多,运维工具平台化做得不太好,都是靠脚本来运维的。
• 第四个问题:业务方普遍使用 python,某些情况下性能有些差。其次由于平台针对 JavaJstorm 的一些 Debug 工具,SDK 较弱,故推广 Java Jstorm 作业较难。
针对上面的问题,有两个解决方案:(1)在 Jstorm 的基础上支持内存限制,业务 Quota 管理,集群运维;(2)Flink on yarn,也能够解决内存限制,业务 Quota 管理,Yarn 队列运维。
最终选择方案(2)也是考虑到Apache Flink (以下简称Flink)除了解决上述问题之外,能将运维工作交付给 yarn,节省人力;Flink 在 exactly once,time window,table/sql 等特性上支持更好;一些公司,例如阿里,在 Flink 上已经有了生产环境的实践; Flink 可以兼容 Jstorm,因此历史作业可以无缝迁移到新框架上,没有历史包袱,不需要维护两套系统。

以上就是 Flink 的优势,于是我们就决定从 Jstorm 往 Flink 迁移。
二、Flink 集群的构建过程
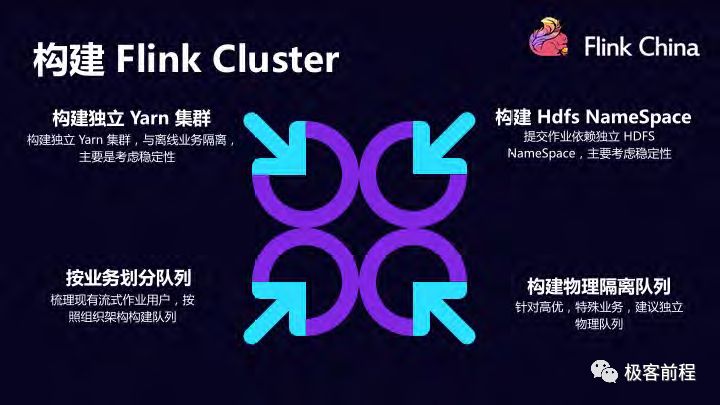
在迁移的过程中,第一件事情是要先把 Flink 集群建立起来。一开始肯定要是追求稳定性,需要把流式 yarn 集群和离线集群隔离开;提交作业,checkpoint 等依赖的 HDFS 也独立namespace;然后跟业务方梳理旧 Jstorm 作业,根据不同的业务团队,创建不同的 Yarn 队列;同时也支持了一下最重要的作业跑在独立 label yarn 队列上,与其他业务物理隔离。
三、Jstorm->Flink 作业迁移
兼容 Jstorm

当时使用的 Flink 版本是 1.3.2,Flink 官方提供了一个 flink-storm module,用来支持将一个Storm topology 转换为 Flink 作业,借鉴 flink-storm 实现了一个 flink-jstorm,完成将 Jstormtopology 转换为 Flink 作业。
仅仅做完这件事情还是不够的,因为有一批外围工具也需要修改。例如提交作业脚本;自动注册消费延迟报警;自动注册作业状态的 Dashboard 等。
完成上面事情后,还有一件最重要的事情就是资源配置的转换。Jstorm 和 Flink 在资源配置管理方面还是有些不同,Jstorm 没有 slot 的概念,Jstorm 没有 network buffer 等,因此为了方便用户迁移作业,我们完成了一个资源配置脚本,自动根据用户的资源使用情况,以及 Topology结构创建适合 Flink 作业的资源配置信息。
迁移 Jstorm
上述工作全部准备完成之后,开始推动业务迁移,截止到当前,基本已经完成迁移。
在迁移的过程中我们也有一些其他优化,比如说 Jstorm 是能够支持 task 和 work 维度故障恢复,Flink 这一块做得不是特别好,在现有 Flink 故障恢复的基础上,实现了 single task 和 singletm 维护故障恢复,这样就解决部分作业因为单 task 故障导致整个作业全部重启。
四、构建流式管理平台
在迁移过程中,开始着手构建了一个流式管理平台。这个平台和其他管理平台是一样的,主要提供作业配置管理,版本管理,监控,重启,回滚,Debug 功能,操作记录等功能。
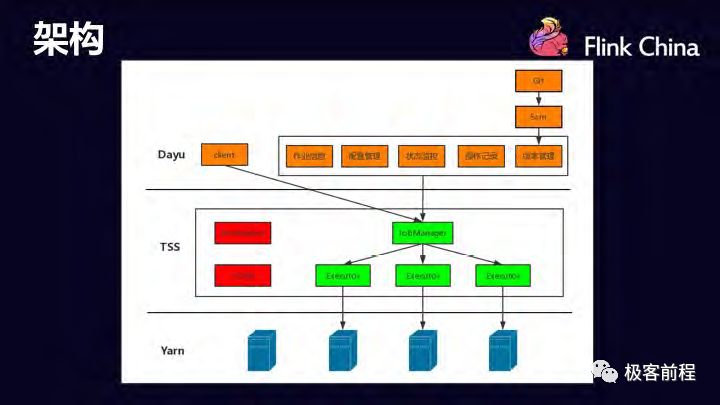
不同的是,我们在架构上分两层实现的,上面一层是面向用户端的产品,称作大禹(取自大禹治水);下面一层是用来执行具体和 Yarn,Flink 交互的工作,称作 TSS(Toutiao StreamingService)。这样的好处是,未来有一些产品也可以构造自己面向用户端的产品,这样他直接对接TSS 层就可以了。
下面给大家介绍一下,在字节跳动实现一个流式作业的流程。
创建流式作业
创建一个作业模板,使用 maven 提供的脚手架创建一个任务模板,重要内容是 pom.xml 文件。
生成的作业模板 pom.xml 已经将 Flink lib 下面的 Jar 包都 exclude 掉了,降低版本冲突的可能性。

测试作业
写完作业之后,可以测试作业。可以支持本地测试,也可以提交到 stage 环境测试。
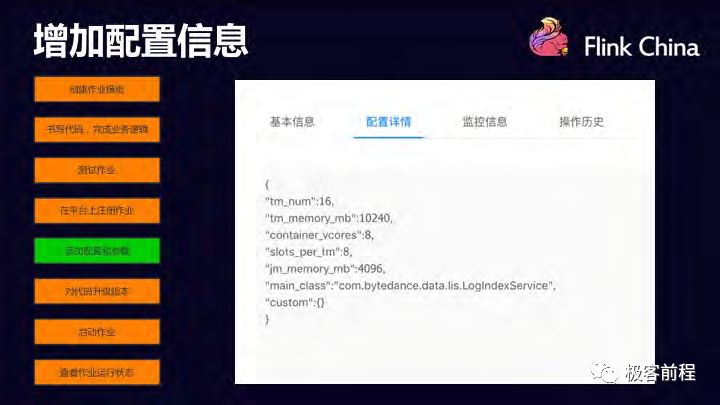
增加配置信息
测试完成后,需要在 dayu 平台上注册作业,添加一些配置信息。
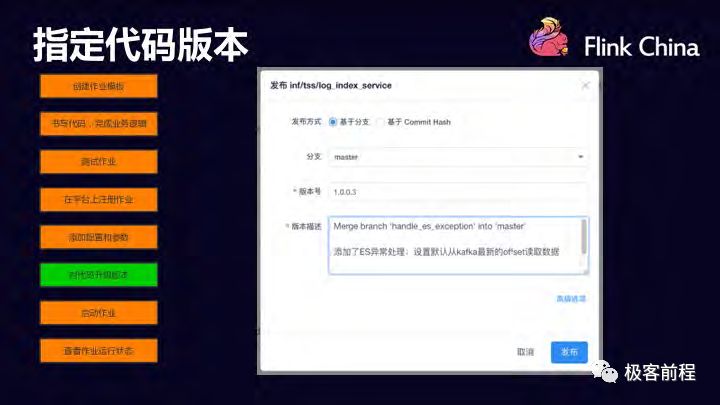
指定代码版本
将自己 git 上的代码,打包,升级到最新版本,在 dayu 页面上选择版本信息,方便回滚。
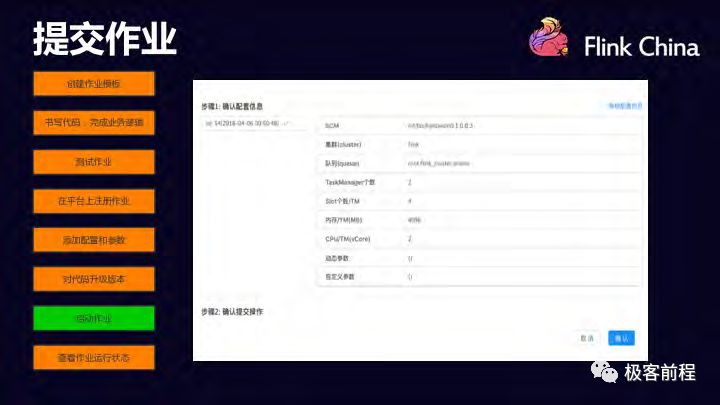
提交作业
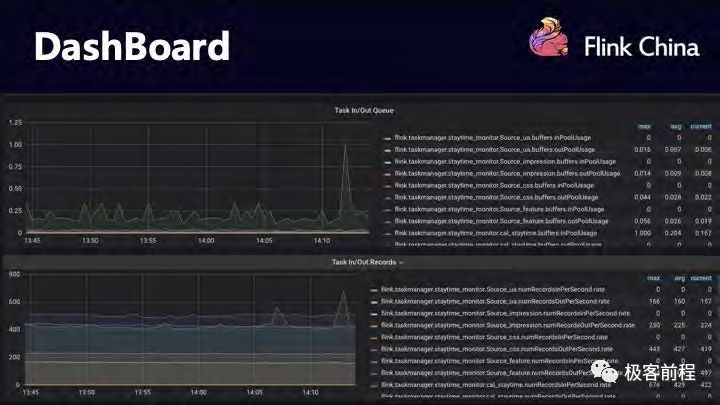
查看作业运行状态
提交完作业后,用户需要查看作业运行的状态怎么样,提供四种方式供用户查看作业状态

第一个是 Flink UI,也就是官方自带的 UI,用户可以去看。
第二个是 Dashboard,展示作业 task qps 和 latency 以及 task 之间的网络 buffer,将这些重要信息汇总到一个页面,追查问题时清晰明了。
第三个是错误日志,将作业的错误日志都收集在一起,写入到 ES 上,方便用户查看。
第四个是 Jobtrace 工具,就是把 Flink 框架层面产生的异常日志匹配出来,直接判断故障,告知用户处理方法。例如当作业 OOM 了,则告知用户如何扩大内存。
五、近期规划
最后跟大家分享一下近期规划
• 用户资源配置是否合理,一直是用户比较头疼的一件事,因此希望能够根据该作业的历史表现,告知用户合理的资源配置信息。
• Flink 1.3 -> 1.5 版本升级
• 优化作业重启速度,缩短用户重启作业数据流中断时间。
• Flink SQL 平台刚上线,需要投入一些精力去了解 SQL 工作机制。
以上就是我本次分享的主要内容,感谢Flink 的举办者和参与者,感谢我的同事,因为以上的分享内容是我和同事一起完成的。
以上是关于字节跳动Jstorm 到Apache Flink 的迁移实践的主要内容,如果未能解决你的问题,请参考以下文章
干货:字节跳动5000+节点的Jstorm集群向Flink迁移实践