flink超越Spark的Checkpoint机制
Posted 浪尖聊大数据
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了flink超越Spark的Checkpoint机制相关的知识,希望对你有一定的参考价值。
前面,已经有一篇文章讲解了spark的checkpoint:
同时,浪尖也在知识星球里发了源码解析的文章。spark streaming的Checkpoint仅仅是针对driver的故障恢复做了数据和元数据的Checkpoint。而本文要讲的flink的checkpoint机制要复杂了很多,它采用的是轻量级的分布式快照,实现了每个操作符的快照,及循环流的在循环的数据的快照。详细的算法后面浪尖会给出文章。
欢迎点击阅读原文,加入浪尖知识星球,更深入学习spark等大数据知识。


Apache Flink提供容错机制,以持续恢复数据流应用程序的状态。该机制确保即使存在故障,程序的每条记录只会作用于状态一次(exactly-once),当然也可以降级为至少一次(at-least-once)。
容错机制持续地制作分布式流数据流的快照。对于状态较小的流应用程序,这些快照非常轻量级,可以频繁产生快照,而不会对性能产生太大影响。流应用程序的状态存储的位置是可以配置的(例如存储在master节点或HDFS)。
如果程序失败(由于机器,网络或软件故障),Flink将停止分布式数据流。然后,系统重新启动操作算子并将其重置为最新的成功checkpoint。输入流将重置为状态快照记录的位置。 作为重新启动的并行数据流的一部分被处理的任何记录都保证不会成为先前checkpoint状态的一部分。
注意:默认情况下,禁用checkpoint。
注意:要使容错机制完整,数据源(如消息队列或者broker)要支持数据回滚到历史记录的位置。 Apache Kafka具有这种能力,Flink与Kafka的连接器利用了该功能。
注意:由于Flink的checkpoint是通过分布式快照实现的,因此快照和checkpoint的概念可以互换使用。
Flink的容错机制的核心部分是制作分布式数据流和操作算子状态的一致性快照。 这些快照充当一致性checkpoint,系统可以在发生故障时回滚。 Flink用于制作这些快照的机制在“分布式数据流的轻量级异步快照”中进行了描述。 它受到分布式快照的标准Chandy-Lamport算法的启发,专门针对Flink的执行模型而定制。
Flink分布式快照的核心概念之一是barriers。 这些barriers被注入数据流并与记录一起作为数据流的一部分向下流动。 barriers永远不会超过记录,数据流严格有序。 barriers将数据流中的记录分为进入当前快照的记录和进入下一个快照的记录。每个barriers都带有快照的ID,并且barriers之前的记录都进入了该快照。 barriers不会中断流的流动,非常轻量级。 来自不同快照的多个barriers可以同时在流中出现,这意味着可以同时发生各种快照。
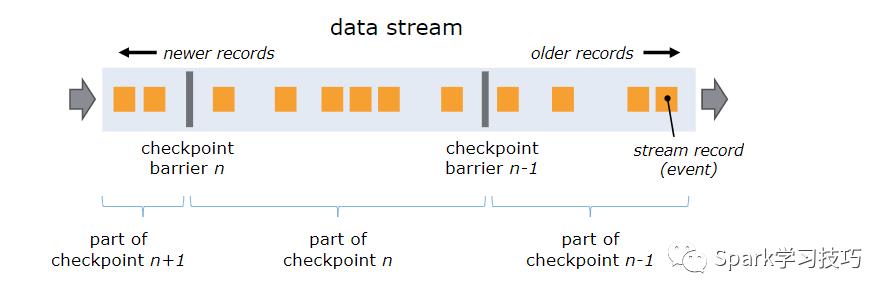
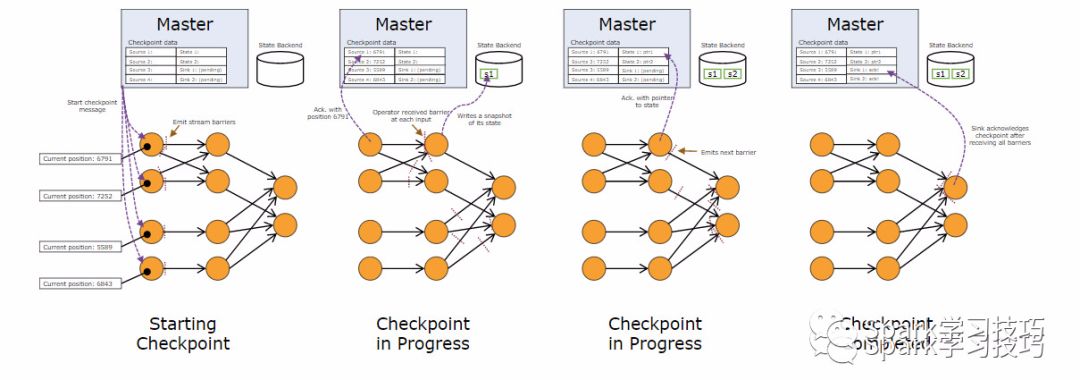
barriers在数据流源处被注入并行数据流中。快照n的barriers被插入的位置(我们称之为Sn)是快照所包含的数据在数据源中最大位置。例如,在Apache Kafka中,此位置将是分区中最后一条记录的偏移量。 将该位置Sn报告给checkpoint协调器(Flink的JobManager)。
然后barriers向下游流动。当一个中间操作算子从其所有输入流中收到快照n的barriers时,它会为快照n发出barriers进入其所有输出流中。 一旦sink操作算子(流式DAG的末端)从其所有输入流接收到barriers n,它就向checkpoint协调器确认快照n完成。在所有sink确认快照后,意味快照着已完成。
一旦完成快照n,job将永远不再向数据源请求Sn之前的记录,因为此时这些记录(及其后续记录)将已经通过整个数据流拓扑,也即是已经被处理结束啦。
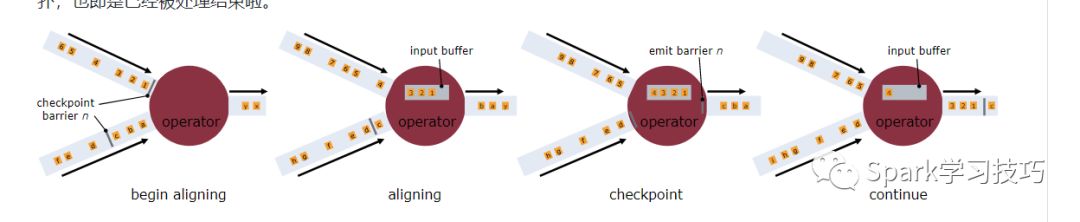
接收多个输入流的运算符需要基于快照barriers对齐输入流。 上图说明了这一点:
一旦操作算子从一个输入流接收到快照barriers n,它就不能处理来自该流的任何记录,直到它从其他输入接收到barriers n为止。 否则,它会搞混属于快照n的记录和属于快照n + 1的记录。
barriers n所属的流暂时会被搁置。 从这些流接收的记录不会被处理,而是放入输入缓冲区。
一旦从最后一个流接收到barriers n,操作算子就会发出所有挂起的向后传送的记录,然后自己发出快照n的barriers。
之后,它恢复处理来自所有输入流的记录,在处理来自流的记录之前优先处理来自输入缓冲区的记录。
当运算符包含任何形式的状态时,此状态也必须是快照的一部分。操作算子状态有不同的形式:
用户定义的状态:这是由转换函数(如map()或filter())直接创建和修改的状态。
系统状态:此状态是指作为运算符计算一部分的数据缓冲区。此状态的典型示例是窗口缓冲区,系统在其中收集(和聚合)窗口里的记录,直到窗口被计算和抛弃。
操作算子在他们从输入流接收到所有快照barriers时,以及在向其输出流发出barriers之前,会对其状态进行写快照。此时,在 barrier 之前的数据对状态的更新已经完成,barrier 之后的数据不会更新状态。 由于快照的状态可能很大,因此它存储在可配置的状态后端中。默认情况下,是存储到JobManager的内存,但对于生产使用,应配置分布式可靠存储(例如HDFS)。 在存储状态之后,操作算子确认checkpoint完成,将快照barriers发送到输出流中,然后继续。
生成的快照现在包含:
对于每个并行流数据源,创建快照时流中的偏移/位置
对于每个运算符,存储在快照中的状态指针
对齐步骤可能增加流式程序的等待时间。通常,这种额外的延迟大约为几毫秒,但也会见到一些延迟显着增加的情况。 对于要求所有记录始终具有超低延迟(几毫秒)的应用程序,Flink可以在checkpoint期间跳过流对齐。一旦操作算子看到每个输入流的checkpoint barriers,就会写 checkpoint 快照。
当跳过对齐时,即使在 checkpoint n 的某些 checkpoint barriers 到达之后,操作算子仍继续处理所有输入。这样,操作算子还可以在创建 checkpoint n 的状态快照之前,继续处理属于checkpoint n + 1的数据。 在还原时,这些记录将作为重复记录出现,因为它们都包含在 checkpoint n 的状态快照中,并将作为 checkpoint n 之后数据的一部分进行重复处理。
注意:对齐仅适用于具有多个输入(join)的运算符以及具有多个输出的运算符(在流重新分区/shuffle之后)。 正因为如此,对于只有map(),flatMap(),filter()等操作,实际上即使在至少一次模式下也能提供一次保证。
注意,上述机制意味着操作算子在将状态的快照存储在状态后端时,停止处理输入记录。每次写快照时,这种同步状态快照操作都会引入延迟。
可以让操作算子在存储状态快照时继续处理,高效地让状态快照存储在后台异步发生。为此,操作算子必须能够生成一个状态对象,该状态对象应以某种方式存储,以便对操作算子状态的进一步修改不会影响该状态对象。 例如,RocksDB中使用的写时复制(copy-on-write)数据结构具有这种能力。
在接收到输入的checkpoint的barriers后,操作算子启动其状态的异步快照复制。它立即释放其barriers到输出,并继续进行常规流处理。后台复制过程完成后,它会向checkpoint协调器(JobManager)确认checkpoint完成。 checkpoint仅在所有sink都已收到barriers并且所有有状态操作算子已确认其完成备份(可能在barriers到达sink之后)之后才算完成。
在这种机制下的恢复是很直接的:当失败时,Flink选择最新完成的checkpoint k。 然后,系统重新部署整个分布式数据流,并为每个操作算子重置作为checkpoint k的一部分的快照的状态。 数据源设置为从位置Sk开始读取。 例如在Apache Kafka中,这意味着告诉消费者从偏移量Sk开始读取。
如果状态以递增方式写快照,则操作算子从最新完整快照的状态开始,然后对该状态应用一系列增量快照更新。
在创建操作算子快照时,有两部分:同步部分和异步部分。
操作算子和状态后端将其快照提供为Java FutureTask。 该任务包含同步部分已完成且异步部分处于挂起状态的状态。 然后,异步部分由该checkpoint的后台线程执行。
完全同步的checkpoint返回已经完成的FutureTask的运算符。 如果需要执行异步操作,则在FutureTask的run()方法中执行。
任务是可取消的,可以释放流和其他资源消耗的句柄。
推荐阅读:
1.
2.
以上是关于flink超越Spark的Checkpoint机制的主要内容,如果未能解决你的问题,请参考以下文章
Flink中的Checkpoint和Spark中的Checkpoint区别