通过Flink进行疲劳事件计算及优化
Posted G7Tech
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了通过Flink进行疲劳事件计算及优化相关的知识,希望对你有一定的参考价值。
编辑:西顿小编 | 人力资源中心
前言
本文主要介绍了疲劳事件这个相对复杂的业务,如何经过多次迭代之后在Flink分布式流数据处理引擎上平稳运行,并最终在6个container 24 task slots使用20G内存情况下,达到4.5万TPS处理能力。
什么是疲劳事件?
疲劳驾驶是公路交通事故的重要原因,简单说就是一个师傅,在连续开车几个小时或行驶超过一定距离以后,中间又没有休息,而产生司机疲劳驾驶的业务场景。对于一个成熟的货运物联网的疲劳计算,需要考虑诸多因素,比如司机可能更换,车辆可能走走停停,车辆可能离线,车辆还可能共享出去,甚至对车辆是否运动也需要支持各个客户的的计算逻辑都有可能改变。
传统疲劳事件计算方式
最早的疲劳事件计算架构如上图所示,在整个处理过程中,我们可以看到产生了多次的网络开销。依赖多个组件每个组件都需要保证高可用,运维难度管理难度较高。MGPS引用本身是整个平台事件,若疲劳事件有新需求上线,整个平台事件或多或少受影响。并且由于依赖组件过多,丢数据的可能性也教高。虽然在此结构下,MGPS应用消费能力有限,TPS在1万左右。虽具备横向扩展能力,但并发能力和分布式部署的可靠性都需要开发业务代码的工程师来保证,结构不清晰,编写业务代码需要考虑过多基础架构的内容。
使用FLink后,大致结构如下:
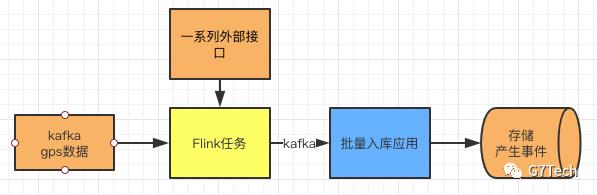
适当减少了额外的网络开销,减少了额外依赖的组件,运维难度大大降低。并且中间Flink自生提供了良好的特性,保证数据的不丢失。最重要的TPS峰值时能达到4.5万。而使用的资源是原有的三分之一。
那么,我们使用Flink来优化,是如何达到的呢?后续将讲解,我们是如何一步一步达到这个结果的。
关于Flink
为方便大家理解后面的业务处理,我们先简要的简绍一下Flink的基本知识。若您对Flink已经有一些认识,可跳过这一章节。我们在附录中也提供了一些比较好的介绍Flink的博客资源。
Flink是Apache开源基金会下面的一个流式计算引擎,它的基本数据模型是数据流。流可以是无边界的无限流,即一般意义上的流处理。也可以是有边界的有限流,这样就是批处理,Flink用一套架构同时支持了流处理和批处理。Flink还有一个特性,是支持有状态的计算。所谓有状态处理,就是结果还和之前处理过的事件有关,稍微复杂一点的数据处理,比如说基本的聚合,数据流之间的关联都是有状态处理,反之,处理一个事件(或一条数据)的结果只跟事件本身的内容有关,称为无状态处理。
持续优化
在疲劳事件的Flink业务处理中,我们也经历了三个阶段的优化过程。这里一一讲解,以便大家了解我们迭代的过程以及每个时期遇到的问题和解决案。
在处理过程中,我们用到了如下一些算子和组件,他们的作用如下:
- Kafka source:读取kafka中的数据,使用Flink自带adapter来实现
- String to location:将kafka中读取的json格式字符串转换成location对象,并将主从设备的打卡数据全部归属到主设备上
- Pad location:处理外部接口调用,并且过滤一些异常数据
- FatigueEvent:疲劳核心计算逻辑。过滤不需要疲劳计算的数据,计算车辆行驶是否疲劳等。
- NoSignEvent:并发处理未登签事件。
- Window:时间窗口,累积60s的数据,根据时间排序,处理设备教短时间内补传gps数据而造成的顺序错乱。
- 批量入库程序:spring boot程序,批量处理入库,下发语音等操作
阶段一

在此阶段,我们只是使用Flink,并不知道其中各种问题。因此将各种业务逻辑都揉进了LocationWindow这个滚动时间窗口中。最直接的后果就是,经常kafka积压。消费能力也不足,数据量稍微增加,就得维护调整并发度增加这个job占用Flink集群的资源。
阶段二
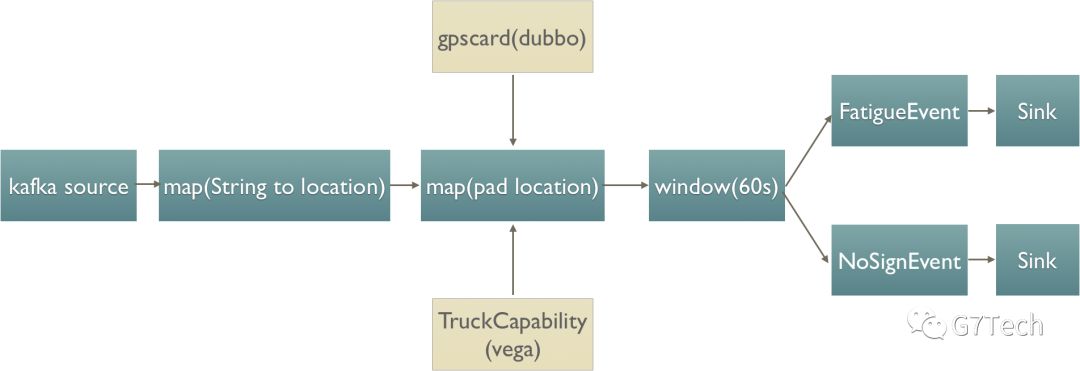
根据第一阶段的观察,我们发现性能瓶颈主要在调用外部接口上,并且业务糅合在一起,出现需求变更时,我们修改极度困难,因此我们将整个过程进行了拆分。
而在此阶段中,我们发现仍然有三个问题,需要进行优化:
我们发现入库时虽然数据量已经较少,但是因为此数据库本身压力较大,修改数据任然很慢。然后出现整个流程pending,造成反压。最后kafka中数据的积压
在pad location处,因为在Flink中,我们设置的并发度只有24,我们在调用外部接口时,还是不足,虽然加了缓存,但是每到缓存过期时,还是不可能避免的出现积压(导致此问题,有两方面原因:1-外部调用并发性不足,2-若大面积放开并发度,会让外部系统的压力过大,无法正常提供服务)
虽然相比阶段一,在FatigueEvent处,已经进行了适当的业务拆分,但是任然不够。在刚开始增加需求,还相对容易,开发一段时间后,又一次出现较难修改等问题
阶段三
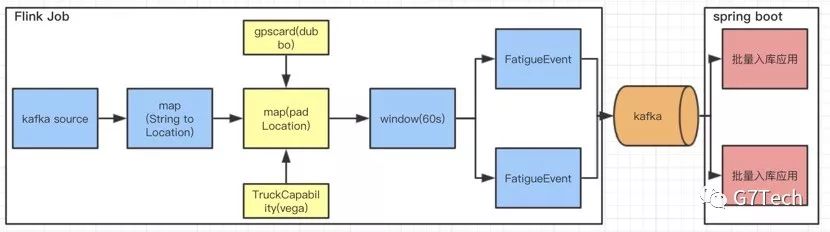
在此阶段,我们进行了充分考虑,并且相对较为务实的处理,使用了下面三种方案,解决阶段二遇到的问题:
1. 在上图pad location处,我们在此处集中处理对外部系统的调用,但是一个普通的spring cloud调用,耗时都在200ms左右,那么要保证5w左右的TPS,在有限的资源,外部接口性能短时间内也无法提升的前提下,几乎很难办到。因此,我们从两方面进行了优化。一、引入guava异步缓存刷新策略。在运行阶段,在缓存过期时间到达时,通过异步线程调用外部接口。在调用外部接口阶段,guava先返回旧值保证业务正常运行,刷新完成后下一次获取这个数据时返回新值。二、采用可以根据主键hash路由的线程池,适当增加并发度。
2. 在FatiguEvent处,由于疲劳业务的复杂,我们需要分拆多种需求,使业务场景更好的隔离,逻辑更加清晰。
如果我们想达到这样的目的,有两种方式。
方式一:使用Flink的方式,增加算子。将此处的FatigueEvent进一步拆分成多个算子,来承载不同的业务场景
方式二:不增加更多算子,只通过对代码良好的设计来处理,保证业务场景的拆分
若采用方式一,由于我们在多个业务场景中,都需要共享valuestate中车辆的状态,而valuestate是绑定在key和算子上的,因此增加一个算子就需要增加维护一套valuestate的状态。又由于需要使用valuestate,因此每一次算子流转过程中,他都需要再次根据key hash一次。这样就会带来不必要的网络开销,资源消耗等。
因此我们采用方式二,使用责任链模式来处理和分拆这块核心逻辑,分解类图如下:
3. 在最后的入库操作,是由spring boot程序来实现的。没有放入Flink中处理。在spring boot中,能更好的进行批量操作数据库,下发语音等。进一步减少Flink的IO操作。同时也在此处处理数据的幂等性,如果Flink在出现异常时,会通过checkpoint进行恢复,可能会有重复数据发送到下游。
使用建议
在整个开发过程中,我们也踩了许多的坑,这里共享出来供大家参考:
如果在我们的程序中,抛出了异常,会导致flink的重启,因此业务异常一定要自己catch住,并进行适当处理;
valuestate只能在本算子中使用,想多个算子之间共享valuestate程序,目前是无法做到,解决方案:引入redis等进行处理或在前一个算子中传递相关数据到后续算子中;
采用valuestate时该算子的输入必须进行keyby处理,导致网络流量增加,为了减少算子状态,以及减少keyby,rebalance等操作,让subtask进行合并,减少网络开销;
如果使用dubbo微服务框架,在dubbo在配置时,最好check属性为false,如果为true在发布到flink的时候,会导致报错;
checkpoint机制,采用ExactlyOnce的方式如果有一个subtask处理延迟,会导致其他subtask数据积压,进而引起整个集群处理缓慢,对于并行度太高的应用建议采用AtLeastOnce;
在放入valuestate的对象中,如果增加删除属性,在新发布的时候,会导致原有valuestate中的内容在反序列化到新valuestate中时报错。根源是flink使用教老版本kryo序列化工具,需要修改这个配置,实现自己的序列化工具;
Flink的valuestate中,最好只是使用较为简单常见的数据结构,若使用第三方包中提供的数据结构。例如:我在开发一个需求时,使用了guava中的EvictingQueue。但是这种数据结构在valuestate中,却不能很好的序列化和反序列化,根源原因和问题6相近。
改进方向
valuestate,目前来看还是黑盒状态,无法查看,无法监控。因此后期方向是能提供相应策略,能查看能监控;
Flink的发布程序方式目前和持续集成环境没有很好的兼容,需要自己来实现持续集成的方式。
写在最后
Flink并不是万能,它有自己适合的场景。我们认为,如果该业务,需要频繁调用外部数据,有大量的IO操作等。不太适合使用Flink,或者起码要进行足够的解耦,将这些操作分离出流计算的主流程;
Flink具有很多优秀的功能,基本可以保证数据不丢失,但是由于一些异常,它还是可能会产生重复数据,因此下游系统做好幂等性非常重要;
在此业务场景下,我们使用的是Flink stream的方式处理,Flink还提供了batch以及sql的方式。若非强状态业务,建议使用sql的方式来实现,代码量会大大减少,欢迎大家进一步研究,讨论。
【附】Flink的优秀博客
Apache Flink 之所以能越来越受欢迎,我们认为离不开它最重要的四个基石:Checkpoint/State/Time/Window。
更详细的参看blog:
http://wuchong.me/blog/2018/11/09/flink-tech-evolution-introduction/
CHECKPOINT
https://blog.csdn.net/hxcaifly/article/details/84673292
WATERMARK
https://yq.aliyun.com/articles/666056?spm=a2c4e.11155435.0.0.17c91b10tPbXm9
STATE
https://yq.aliyun.com/articles/667562?spm=a2c4e.11155435.0.0.17c91b10kNxIzF
WINDOW
https://yq.aliyun.com/articles/64820
高博
8+年JAVA方面工作经验
目前主要研究方向:物联网业务场景落地,Flink流式计算等
自诩有追求/有想法/有趣味的三有青年
喜欢踢球
喜欢热闹
偶尔装逼但经常失败
以上是关于通过Flink进行疲劳事件计算及优化的主要内容,如果未能解决你的问题,请参考以下文章