Flink or Spark?实时计算框架在K12场景的应用实践
Posted 芋道源码
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flink or Spark?实时计算框架在K12场景的应用实践相关的知识,希望对你有一定的参考价值。
| 字段 | 含义 | 举例 |
|---|---|---|
| student_id | 学生唯一ID | 学生ID_16 |
| textbook_id | 教材唯一ID | 教材ID_1 |
| grade_id | 年级唯一ID | 年级ID_1 |
| subject_id | 科目唯一ID | 科目ID_2_语文 |
| chapter_id | 章节唯一ID | 章节ID_chapter_2 |
| question_id | 题目唯一ID | 题目ID_100 |
| score | 当前题目扣分(0 ~ 10) | 2 |
| answer_time | 当前题目作答完毕的日期与时间 | 2019-09-11 12:44:01 |
| ts | 当前题目作答完毕的时间戳(java.sql.Timestamp) | Sep 11, 2019 12:44:01 PM |
{"student_id": "学生ID_16","textbook_id": "教材ID_1","grade_id": "年级ID_1","subject_id": "科目ID_2_语文","chapter_id": "章节ID_chapter_2","question_id": "题目ID_100","score": 2,"answer_time": "2019-09-11 12:44:01","ts": "Sep 11, 2019 12:44:01 PM"}
本篇将省略下游框架的操作,重点介绍Flink框架进行任务计算的过程(虚线框中的内容),并简述Spark的实现方法,便于读者理解其异同。
1.3.1 Flink 实践方案
1. 发送数据到 Kafka
{"student_id":"学生ID_16","textbook_id":"教材ID_1","grade_id":"年级ID_1","subject_id":"科目ID_2_语文","chapter_id":"章节ID_chapter_2","question_id":"题目ID_100","score":2,"answer_time":"2019-09-11 12:44:01","ts":"Sep 11, 2019 12:44:01 PM"}………
val env = StreamExecutionEnvironment.getExecutionEnvironmentenv.setParallelism(3)
val props = new Properties()props.setProperty("bootstrap.servers", "linux01:9092,linux02:9092,linux03:9092")props.setProperty("group.id", "group_consumer_learning_test01")val flinkKafkaSource = new FlinkKafkaConsumer011[String]("test_topic_learning_1", new SimpleStringSchema(), props)val eventStream = env.addSource[String](flinkKafkaSource)
val answerDS = eventStream.map(s => {val gson = new Gson()val answer = gson.fromJson(s, classOf[Answer])answer})
val tableEnv = StreamTableEnvironment.create(env)val table = tableEnv.fromDataStream(answerDS)tableEnv.registerTable("t_answer", table)
//实时:统计题目被作答频次val result1 = tableEnv.sqlQuery("""SELECT| question_id, COUNT(1) AS frequency|FROM| t_answer|GROUP BY| question_id""".stripMargin)//实时:按照年级统计每个题目被作答的频次val result2 = tableEnv.sqlQuery("""SELECT| grade_id, COUNT(1) AS frequency|FROM| t_answer|GROUP BY| grade_id""".stripMargin)//实时:统计不同科目下,每个题目被作答的频次val result3 = tableEnv.sqlQuery("""SELECT| subject_id, question_id, COUNT(1) AS frequency|FROM| t_answer|GROUP BY| subject_id, question_id""".stripMargin)
tableEnv.toRetractStream[Result1](result1).filter(_._1).map(_._2).map(new Gson().toJson(_)).addSink(new FlinkKafkaProducer011[String]("linux01:9092,linux02:9092,linux03:9092","test_topic_learning_2",new SimpleStringSchema()))tableEnv.toRetractStream[Result2](result2).filter(_._1).map(_._2).map(new Gson().toJson(_)).addSink(new FlinkKafkaProducer011[String]("linux01:9092,linux02:9092,linux03:9092","test_topic_learning_3",new SimpleStringSchema()))tableEnv.toRetractStream[Result3](result3).filter(_._1).map(_._2).map(new Gson().toJson(_)).addSink(new FlinkKafkaProducer011[String]("linux01:9092,linux02:9092,linux03:9092","test_topic_learning_4",new SimpleStringSchema()))
env.execute("Flink StreamingAnalysis")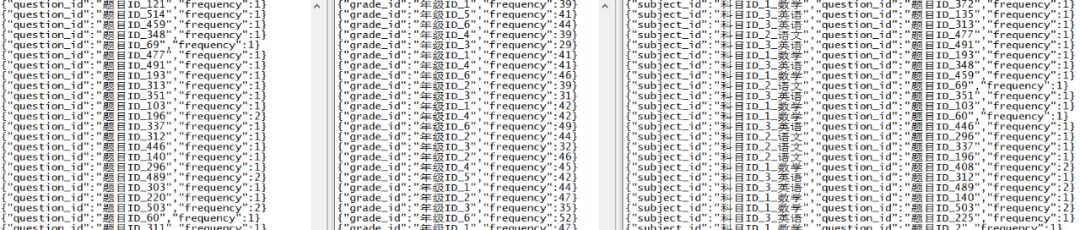
val sparkConf = new SparkConf().setAppName("StreamingAnalysis").set("spark.local.dir", "F:\temp").set("spark.default.parallelism", "3").set("spark.sql.shuffle.partitions", "3").set("spark.executor.instances", "3")val spark = SparkSession.builder.config(sparkConf).getOrCreate()
val inputDataFrame1 = spark.readStream.format("kafka").option("kafka.bootstrap.servers", "linux01:9092,linux02:9092,linux03:9092").option("subscribe", "test_topic_learning_1").load()
val keyValueDataset1 = inputDataFrame1.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)").as[(String, String)]val answerDS = keyValueDataset1.map(t => {val gson = new Gson()val answer = gson.fromJson(t._2, classOf[Answer])answer})
case class Answer(student_id: String,textbook_id: String,grade_id: String,subject_id: String,chapter_id: String,question_id: String,score: Int,answer_time: String,ts: Timestamp) extends Serializable
answerDS.createTempView("t_answer")//实时:统计题目被作答频次val result1 = spark.sql("""SELECT| question_id, COUNT(1) AS frequency|FROM| t_answer|GROUP BY| question_id""".stripMargin).toJSON
result1.writeStream.outputMode("update").trigger(Trigger.ProcessingTime(0)).format("kafka").option("kafka.bootstrap.servers", "linux01:9092,linux02:9092,linux03:9092").option("topic", "test_topic_learning_2").option("checkpointLocation", "./checkpoint_chapter11_1").start()

CREATE TABLE t_answer(student_id VARCHAR,textbook_id VARCHAR,grade_id VARCHAR,subject_id VARCHAR,chapter_id VARCHAR,question_id VARCHAR,score INT,answer_time VARCHAR,ts TIMESTAMP)WITH(type ='kafka11',bootstrapServers ='ukafka-mqacnjxk-kafka001:9092,ukafka-mqacnjxk-kafka002:9092,ukafka-mqacnjxk-kafka003:9092',zookeeperQuorum ='ukafka-mqacnjxk-kafka001:2181/ukafka',topic ='test_topic_learning_1',groupId = 'group_consumer_learning_test01',parallelism ='3');
CREATE TABLE t_result1(question_id VARCHAR,frequency INT)WITH(type ='kafka11',bootstrapServers ='ukafka-mqacnjxk-kafka001:9092,ukafka-mqacnjxk-kafka002:9092,ukafka-mqacnjxk-kafka003:9092',zookeeperQuorum ='ukafka-mqacnjxk-kafka001:2181/ukafka',topic ='test_topic_learning_2',parallelism ='3');CREATE TABLE t_result2(grade_id VARCHAR,frequency INT)WITH(type ='kafka11',bootstrapServers ='ukafka-mqacnjxk-kafka001:9092,ukafka-mqacnjxk-kafka002:9092,ukafka-mqacnjxk-kafka003:9092',zookeeperQuorum ='ukafka-mqacnjxk-kafka001:2181/ukafka',topic ='test_topic_learning_3',parallelism ='3');CREATE TABLE t_result3(subject_id VARCHAR,question_id VARCHAR,frequency INT)WITH(type ='kafka11',bootstrapServers ='ukafka-mqacnjxk-kafka001:9092,ukafka-mqacnjxk-kafka002:9092,ukafka-mqacnjxk-kafka003:9092',zookeeperQuorum ='ukafka-mqacnjxk-kafka001:2181/ukafka',topic ='test_topic_learning_4',parallelism ='3');
INSERT INTOt_result1SELECTquestion_id, COUNT(1) AS frequencyFROMt_answerGROUP BYquestion_id;INSERT INTOt_result2SELECTgrade_id, COUNT(1) AS frequencyFROMt_answerGROUP BYgrade_id;INSERT INTOt_result3SELECTsubject_id, question_id, COUNT(1) AS frequencyFROMt_answerGROUP BYsubject_id, question_id;
近期,UCloud针对高校学子及云计算从业者举办的“U创营”活动正在进行,欢迎各位感兴趣的小伙伴报名参与!
以上是关于Flink or Spark?实时计算框架在K12场景的应用实践的主要内容,如果未能解决你的问题,请参考以下文章