金融大数据 实时计算引擎Flink
Posted 金凯聊数据
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了金融大数据 实时计算引擎Flink相关的知识,希望对你有一定的参考价值。
李胜敏|数据解决方案部高级工程师
背景:
Apache Flink是一个面向数据流处理和批量数据处理的可分布式的开源计算框架,它基于同一个Flink流式执行模型(streaming execution model),能够支持流处理和批处理两种应用类型。由于流处理和批处理所提供的SLA(服务等级协议)是完全不相同, 流处理一般需要支持低延迟、Exactly-once保证,而批处理需要支持高吞吐、高效处理,所以在实现的时候通常是分别给出两套实现方法,或者通过一个独立的开源框架来实现其中每一种处理方案。比较典型的有:实现批处理的开源方案有MapReduce、Spark;实现流处理的开源方案有Storm;Spark的Streaming 其实本质上也是微批处理。Flink的支持流批结合在批处理和流处理进行表关联方面提供了方便。
Flink的特性:
支持高吞吐、低延迟、高性能的流处理
支持有状态计算的Exactly-once语义
支持高度灵活的窗口(Window)操作,支持基于time、count、session,以及data-driven的窗口操作
支持基于轻量级分布式快照(Snapshot)实现的容错
一个运行时同时支持Batch on Streaming处理和Streaming处理
Flink在JVM内部实现了自己的内存管理
支持程序自动优化:避免特定情况下Shuffle、排序等昂贵操作,中间结果有必要进行缓存
支持迭代计算
技术架构:
Flink部署方式可以运行在Single JVM,Standalone,YARN,S3上。flink的核心是Distributed streaming Dataflow,基于flink core 是两大核心API DataStream API(流处理)&DataSet API(批处理),基于核心API,有一些扩展的library,例如基于DataStream API的CEP,Table&SQL,基于DataSet API的Flink ML (机器学习包),Gelly(图计算),Table&SQL,值得注意的是,Table&SQL可以同时运行流数据和批数据集合。
图1:flink整体架构图
Flink程序的入门开发:
设置环境
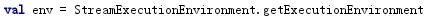
设置检查点

flink程序三个基本构建块:
source:数据源(如kafka、socket)
transformations:基于数据流的一组operate操作

sink:数据处理结果的目的地(如ES,关系型数据库,HDFS,redis等)

flink的应用场景有:
实时智能推荐、复杂事件处理、实施欺诈检测、实时数仓与ETL、流数据分析、实时报表分析
下面介绍集中常见的场景下的流计算:
统计每天从M点到N点的交易笔数,可以通过截取时间字段HH:mm:ss去掉冒号将String类型转换成int,在通过时间的大小进行比较。
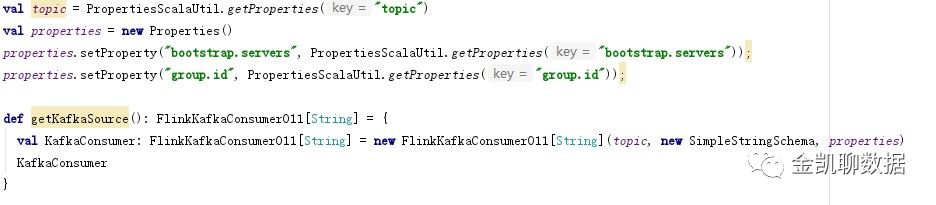
滚动窗口、滑动窗口、开窗函数的比较:
滚动窗口:固定相同间隔分配窗口,每个窗口之间没有重叠
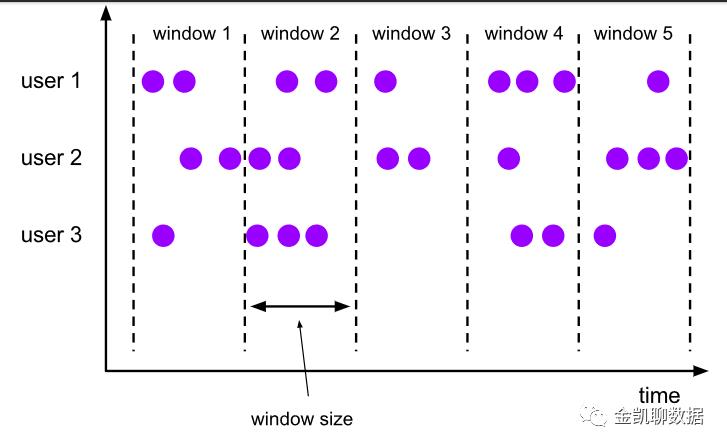
下面的例子定义了每隔3毫秒一个窗口的流:
WindowedStream<MovieRate, Integer, TimeWindow> Rates = rates
.keyBy(MovieRate::getUserId)
.window(TumblingEventTimeWindows.of(Time.milliseconds(3)));
滑动窗口:固定相同间隔分配窗口,只不过每个窗口之间有重叠。窗口重叠的部分如果比窗口小,窗口将会有多个重叠,即一个元素可能被分配到多个窗口里去。
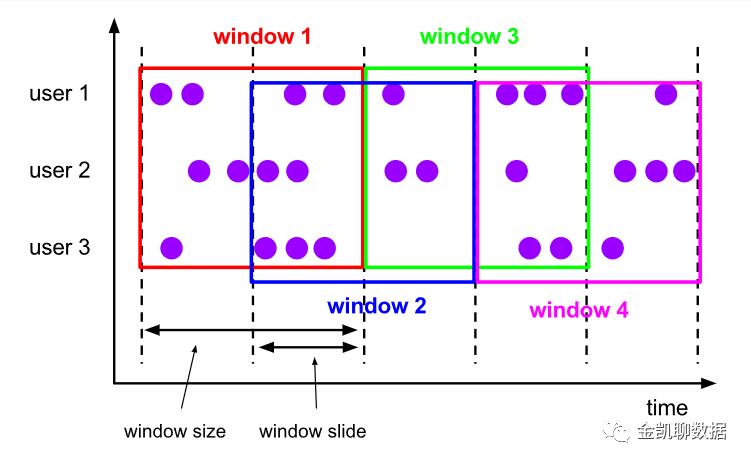
下面的例子给出窗口大小为10毫秒,重叠为5毫秒的流:
WindowedStream<MovieRate, Integer, TimeWindow> Rates = rates
.keyBy(MovieRate::getUserId)
.window(SlidingEventTimeWindows.of(Time.milliseconds(10), Time.milliseconds(5)));
开窗函数:根据时间进行排序,根据指定字段进行分区,每条记录都会触发一次进行统计,可以通过RANGE BETWEEN INTERNAL ‘1’DAY peceding AND CURRENT ROW 进行时间的过滤,比较适合风险监控的场景。
统计前一周(1分钟等)从交易笔数,先定义时间类型为事件时间,通过开窗函数进行统计,如下图:
技术应用:
目前flink实时流处理主要用于银行风险监控,其中其中频繁开销户、过期证件号批量发起开户、连续发生交易失败等对指定时间段内的操作进行计数,例如监控虚拟运营商手机号为预留手机号码,预留手机号码由行从运营商处购买,格式为文本格式,通过hive加工导入到ES中,从ES中查询出数据给flink生成表,使用flinksql将流数据的注册表与ES数据进行表关联统计出,将统计出的结果数据存储到redis中以供开源规则引擎进行判断(如图2所示)。
图2数据流向图
FLink常见问题:
1.flink1.8中sql日期函数不好用,只能将特定’yyyy-MM-dd’类型的数据进行转成日期类型,而不能将字段数据转换为日期类型。
2.flink在使用table转成stream流时使用toRetractStream方法
3.flink的滑动窗口和滚动窗口的时间一般设置为事件时间,很多场景下的滑动窗口延迟较大,不能满足要求,用开窗函数比如获取前10分钟的数据等。
4.flink部署目前生产上一般使用flink-on-yarn模式,我们使用yarn-session的方式进行作业提交。
5.flink的checkpoint文件放置在HDFS会产生许多小文件,建议可以直接放存放到服务器上。
结束语:
随着大数据时代的到来,数据量的不断增加和对数据时效性的要求越来越高,流式计算将会被应用在越来越多的领域和场景。flink作为目前最火的流处理工具不仅在银行实时监控的领域应用会越来越广,未来的的实时数仓,实时用户画像也将或得到越来越多的应用。
以上是关于金融大数据 实时计算引擎Flink的主要内容,如果未能解决你的问题,请参考以下文章