flink exectly-once系列之两阶段提交概述
Posted Flink 实战剖析
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了flink exectly-once系列之两阶段提交概述相关的知识,希望对你有一定的参考价值。
flink exactly-once系列目录:
一、两阶段提交概述
二、TwoPhaseCommitSinkFunction与FlinkKafkaProducer源码分析
三、StreamingFileSink源码分析
四、事务性输出实现
五、最终一致性实现
一、flink Exactly-Once与At-Least-Once
关于消息的消费、处理语义可以分为三类:
1. at most once : 至多一次,表示一条消息不管后续处理成功与否只会被消费处理一次,那么就存在数据丢失可能
2. exactly once : 精确一次,表示一条消息从其消费到后续的处理成功,只会发生一次
3. at least once :至少一次,表示一条消息从消费到后续的处理成功,可能会发生多次
在我们程序处理中通常要求能够满足exectly once语义,保证数据的准确性,flink 通过checkpoint机制提供了Exactly-Once与At-Least-Once 两种不同的消费语义实现, 可以将程序处理的所有数据都保存在状态内部,当程序发生异常失败重启可以从最近一次成功checkpoint中恢复状态数据,通过checkpoint中barrier对齐机制来实现这两不同的语义,barrier对齐发生在一
个处理节点需要接收上游不同处理节点的数据,由于不同的上游节点数据处理速度不一致,那么就会导致下游节点接收到 barrier的时间点也会不一致,这时候就需要使用barrier对齐机制:在同一checkpoint中,先到达的barrier是否需要等待其他处理节点barrier达到后在发送后续数据,barrier将数据流分为前后两个checkpoint(chk n,chk n+1)的概念,如果不等待那么就会导致chk n的阶段处理了chk n+1阶段的数据,但是在source端所记录的消费偏移量又一致,如果chk n成功之后,后续的任务处理失败,任务重启会消费chk n+1阶段数据,就会到致数据重复消息,如果barrier等待就不会出现这样情况,因此barrier需要对齐那么就是实现exectly once语义,否则实现的是at least once语义。由于状态是属于flink内部存储,所以flink 仅仅满足内部exectly once语义。
二、两阶段提交2PC
在分布式系统中,可以使用两阶段提交来实现事务性从而保证数据的一致性,两阶段提交分为:预提交阶段与提交阶段,通常包含两个角色:协调者与执行者,协调者用于用于管理所有执行者的操作,执行者用于执行具体的提交操作,具体的操作流程:
1. 首先协调者会送预提交(pre-commit)命令有的执行者
2. 执行者执行预提交操作然后发送一条反馈(ack)消息给协调者
3. 待协调者收到所有执行者的成功反馈,则发送一条提交信息(commit)给执行者
4. 执行者执行提交操作
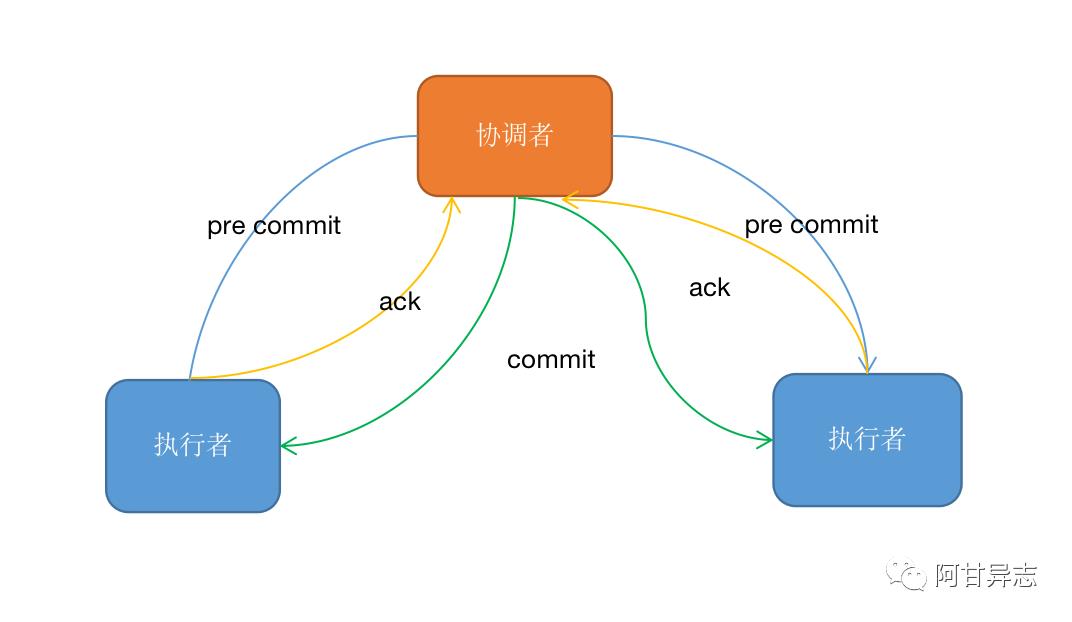
如果在流程2中部分预提交失败,那么协调者就会收到一条失败的反馈,则会发送一条rollback消息给所有执行者,执行回滚操作,保证数据一致性;但是如果在流程4中,出现部分提交成功部分提交失败,那么就会造成数据的不一致,因此后面也提出了3PC或者通过其他补偿机制来保证数据最终一致性,接下看看flink 是如何做到2PC,保证数据的一致性。
三、flink中两阶段提交
flink中两阶段提交是为了保证端到端的Exactly Once,主要依托checkpoint机制来实现,先看一下checkpoint的整体流程,
1. jobMaster 会周期性的发送执行checkpoint命令(start checkpoint);
2.当source端收到执行指令后会产生一条barrier消息插入到input消息队列中,当处理到barrier时会执行本地checkpoint, 并且会将barrier发送到下一个节点,当checkpoint完成之后会发送一条ack信息给jobMaster ;
3. 当DAG图中所有节点都完成checkpoint之后,jobMaster会收到来自所有节点的ack信息,那么就表示一次完整的checkpoint的完成;
4. JobMaster会给所有节点发送一条callback信息,表示通知checkpoint完成消息,这个过程是异步的,并非必须的,方便做一些其他的事情,例如kafka offset提交到kafka。
对比flink 整个checkpoint机制调用流程可以发现与2PC非常相似,JobMaster相当于协调者,所有的处理节点相当于执行者,start-checkpoint消息相当于pre-commit消息,每个处理节点的checkpoint相当于pre-commit过程,checkpoint ack消息相当于执行者反馈信息,最后callback消息相当于commit消息,完成具体的提交动作。那么我们应该怎么去使用这种机制来实现2PC呢?
flink 提供了CheckpointedFunction与CheckpointListener这样两个接口,CheckpointedFunction中有snapshotState方法,每次checkpoint触发执行方法,通常会将缓存数据放入状态中,可以理解为是一个hook,这个方法里面可以实现预提交,CheckpointListener中有notifyCheckpointComplete方法,checkpoint完成之后的通知方法,这里可以做一些额外的操作,例如FlinkKafakConsumerBase 使用这个来完成kafka offset的提交,在这个方法里面可以实现提交操作。
在2PC中提到如果对应流程2预提交失败,那么本次checkpoint就被取消不会执行,不会影响数据一致性,那么如果流程4提交失败了,在flink中可以怎么处理的呢? 我们可以在预提交阶段(snapshotState)将事务的信息保存在state状态中,如果流程4失败,那么就可以从状态中恢复事务信息,并且在CheckpointedFunction的initializeState方法中完成事务的提交,该方法是初始化方法只会执行一次,从而保证数据一致性。
还在等什么,点个关注呗~
以上是关于flink exectly-once系列之两阶段提交概述的主要内容,如果未能解决你的问题,请参考以下文章