基于Flink SQL构建实时数据仓库
Posted 大数据技术与架构
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于Flink SQL构建实时数据仓库相关的知识,希望对你有一定的参考价值。
1.需求背景
根据目前大数据这一块的发展,已经不局限于离线的分析,挖掘数据潜在的价值,数据的时效性最近几年变得刚需,实时处理的框架有storm,spark-streaming,flink等。想要做到实时数据这个方案可行,需要考虑以下几点:1、状态机制 2、精确一次语义 3、高吞吐量 4、可弹性伸缩的应用 5、容错机制,刚好这几点,flink都完美的实现了,并且支持flink sql高级API,减少了开发成本,可用实现快速迭代,易维护等优点。
2.离线数仓和实时数仓对比
离线数仓的架构图:
实时数仓架构图:
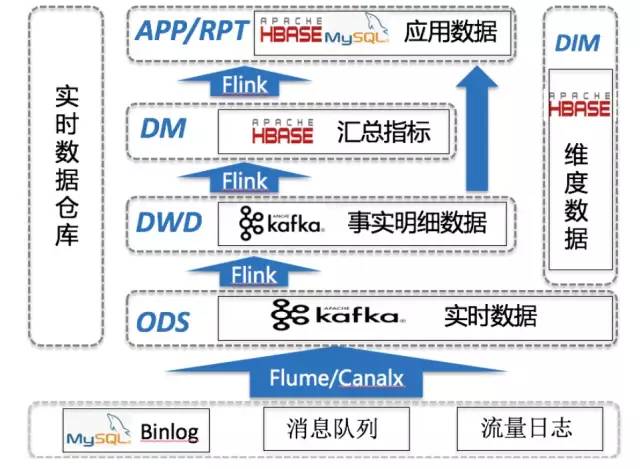
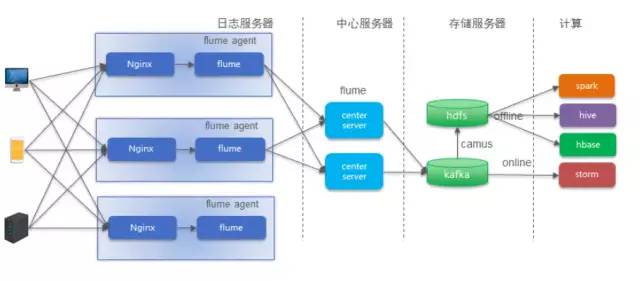
3.1.数据接入(source)
目前实时这边用到的数据,主要是流量日志和binlog,以流量日志为例,打点日志上报到nginx服务器,使用flume进行数据采集,sink进kafka,目前kafka只保留最近一天的数据,考虑到流量日志的数据量大,并且也没有保留多天的意义,如果是要查看昨天的数据情况,完全可以用离线的。所以整套实时数仓体系建设都是为了保障近一天的数据分析。
3.2.数据计算(transform)
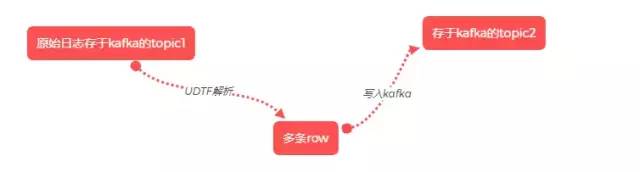
使用flink sql对接kafka,使用自定义的udtf函数解析kafka当中的原始log,产生结构化数据,并且在次写入kafka的另一个topic当中,这就是我们的实时ods层数据了。
为了校验实时数据的准确性,还需要将存于kafka的ods层数据,写入hdfs上,使用hive和hdfs的文件进行映射,产生实时的hive表(目前是小时级别),该hive表可用于和离线hive表进行数据校正。
dwd层的数据是从ods层读取,然后根据需求进行逻辑处理,包括关联相应的维度表,即进行降维操作。
DM/RPT/APP层都是同样的原理,使用flink进行窗口计算,然后存于kafka当中,在写入HDFS上,使用hive与HDFS文件做映射,产生实时的hive表(目前是小时级别),供上层使用。
3.3.数据存储(sink)
目前是将实时维度表存于hbase当中,实时公共层都存于kafka当中,并且以写滚动日志的方式写入HDFS。
4.实时数仓难点讨论
4.1 如何保证接入数据的准确性
4.1.1实时和离线数据接入的差异性
实时数据的接入其实在底层架构是一样的,就是从kafka那边开始不一样,实时用flink的UDTF进行解析,而离线是定时(目前是小时级)用camus拉到HDFS,然后定时load HDFS的数据到hive表里面去,这样来实现离线数据的接入。实时数据的接入是用flink解析kafka的数据,然后在次写入kafka当中去。
4.1.2如何建立实时数据和离线数据的可比较性
由于目前离线数据已经稳定运行了很久,所以实时接入数据的校验可以对比离线数据,但是离线数据是小时级的hive数据,实时数据存于kafka当中,直接比较不了,所以做了相关处理,将kafka的数据使用flink写HDFS滚动日志的形式写入HDFS,然后建立hive表小时级定时去load HDFS中的文件,以此来获取实时数据。
4.1.3如何确定比较的时间区间
完成以上两点,剩余还需要考虑一点,都是小时级的任务,这个时间卡点使用什么字段呢?首先要确定一点就是离线和实时任务卡点的时间字段必须是一致的,不然肯定会出问题。目前离线使用camus从kafka将数据拉到HDFS上,小时级任务,使用nginx_ts这个时间字段来卡点,这个字段是上报到nginx服务器上记录的时间点。而实时的数据接入是使用flink消费kafka的数据,在以滚动日志的形式写入HDFS的,然后在建立hive表load HDFS文件获取数据,虽然这个hive也是天/小时二级分区,但是离线的表是根据nginx_ts来卡点分区,但是实时的hive表是根据任务启动去load文件的时间点去区分的分区,这是有区别的,直接筛选分区和离线的数据进行对比,会存在部分差异,应当的做法是筛选范围分区,然后在筛选nginx_ts的区间,这样在跟离线做对比才是合理的。
4.2如何保证接入数据的时延
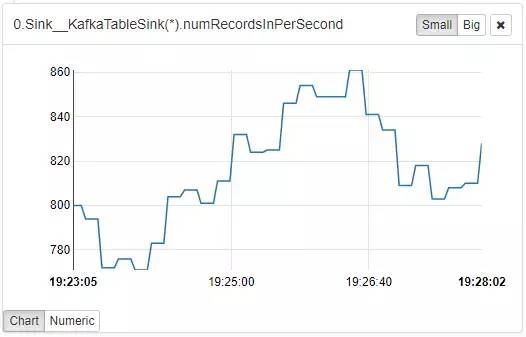
目前实时数据接入层的主要时延是在UDTF函数解析上,实时的UDTF函数是根据上报的日志格式进行开发的,可以完成日志的解析功能。
该图还不是在峰值数据量的时候截的,目前以800记录/second为准,大概一个记录的解析速率为1.25ms。
目前该任务的flink资源配置核心数为1,假设解析速率为1.25ms一条记录,那么峰值只能处理800条/second,如果数据接入速率超过该值就需要增加核心数,保证解析速率。
4.3 维度表设计成实时的复杂度过高
4.3.1实时维表背景介绍
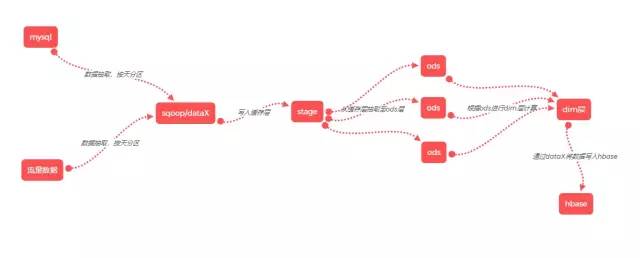
介绍一下目前离线维度表的情况,就拿商品维度表来说,全线记录数将近一个亿,计算逻辑来自40-50个ods层的数据表,计算逻辑相当复杂,如果实时维度表也参考离线维度表来完成的话,那么开发成本和维护成本非常大,对于技术来讲也是很大的一个挑战,并且目前也没有需求要求维度属性百分百准确。所以目前(伪实时维度表)准备在当天24点产出,当天的维度表给第二天实时公共层使用,即T-1的模式。伪实时维度表的计算逻辑参考离线维度表,但是为了保障在24点之前产出,需要简化一下离线计算逻辑,并且去除一些不常用的字段,保障伪实时维度表可以较快产出。
4.3.2在实施的过程当中的细节点
1.根据实时维度表需要的属性字段对离线维度表进行简化操作,并且裁剪ods层的计算逻辑,理顺实时维度表的计算逻辑。
2.实时维度表使用到的stage和ods层数据表保存周期都不需要太长,一般保存数天就好。
3.由于实时维度表需要在24点之前产出并写入到hbase当中,所以要考虑将任务定于几点开始跑,比如所有抽取任务和ods计算任务都从23点开始跑,当然要看具体任务耗时来定,如果耗时过长需要在提前一点。
4.根据以上步骤去完成,感觉剩下来只要将数据写入hbase就好了,但是这里也有一个巨坑。如果将rowkey设计成md5(pt+维度表主键),然后hbase保存近两天的数据,这样当实时数据出现问题,我们还可以进行重刷数据。但是我们不管是商品维度表还是用户维度表都达到了数千万的级别,如果每天全量写入hbase的话,我们做了压测计算hbase的写入速率,大概400百万条/10min,如果同步以一亿条记录的话,大概就需要250分钟,对于时效要求这么高的实时维度表,这个时间肯定是接收不了的,所以row的设计不能将pt放入,但是这样的话就无法保存历史数据,如果实时数据发生异常,重刷数据时部分实时公共层关联的维度信息是不准确的,所以我们在这点上做了取舍,放弃重刷数据,毕竟出现数据异常的概率很小,就算出现了,关联的维度信息不准确的部分也很少(维度信息每天只会有部分发生变化,可能不到百分之一)。既然这种全量走不通,就要考虑增量同步,如果区分该条记录是否发生了属性变化,我们采用的是将全字段做md5处理,只要任一一个字段发生变化,md5就会发生变化,在使用一个flag字段来做标识,flag的计算逻辑就是拿当天的md5和昨天的md5进行比较,相同为0(表示未变化),不同为1(表示发生变化),到时候我们只将flag=1的数据同步到hbase就好了,rowkey设计为md5(维度表主键),这样每天只会把变化差异维度记录同步到hbase,大概每天有几百万,这样的同步时间是可以接受的。其实这里还有一个小点没有考虑到,实时维度表假设是在23:50产出,那么23:50到24:00使用的就是最新的实时维度表了,而不是昨天的实时维度表,这也是存在部分差异的点,但是从目前这个情况考虑,暂时需要做一些取舍。
链接:https://www.jianshu.com/p/18e21bd352b7
文章不错?点个【在看】吧! 以上是关于基于Flink SQL构建实时数据仓库的主要内容,如果未能解决你的问题,请参考以下文章