结合Flink,国内自研,大规模实时动态认知图谱平台——AbutionGraph |博文精选
Posted AI科技大本营
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了结合Flink,国内自研,大规模实时动态认知图谱平台——AbutionGraph |博文精选相关的知识,希望对你有一定的参考价值。
Flink:目前最受关注的大数据技术,最活跃 Apache 项目之一。
AbutionGraph:北京图特摩斯科技自研的国内首个准实时多维图形数据库,首个将实时/离线/指标聚合/图挖掘/AI框架等热门技术线深度整合在一起的认知图谱平台,本文仅对实时性的相关优势做分析。
AbutionGraph 具有以下主要特征:
为分析而设计——AbutionGraph 是为准实时的OLAP工作流的探索性分析而构建,它支持各种过滤、聚合和查询等类;
快速的交互式查询——AbutionGraph 的低延迟数据摄取架构允许事件在它们创建后毫秒内可被查询到;
高可用性——AbutionGraph 的数据在系统更新时依然可用,规模的扩大和缩小都不会造成数据丢失;
可扩展——AbutionGraph 已实现每天能够处理数十亿事件和TB级数据。
AbutionGraph 典型应用场景包括深度关系探索、关联分析、路径搜索、特征抽取、数据聚类、社区检测、 知识图谱、用户画像等,适用业务领域有如网络安全、电信诈骗、金融风控、广告推荐、社交网络和智能机器人等。
引言
大数据时代的到来,为收集数据带来了新的契机。传统基于Hadoop生态的离线数据存储计算方案已在业界形成统一的默契,当能够收集到的数据越来越多时,受制于离线计算的时效性制约,越来越多的数据应用场景已从离线转为实时。
随着物联网时代的逼近,“万物互联”的概念以及人工智能技术的发展一定程度的促进了知识图谱技术的发展,从2017年到2020年,知识图谱技术的使用率增长了400%,但目前市场上多以Neo4j和JanusGraph两款图形数据库为主进行业务拓展,它们难以做到稍大吞吐的准实时应用。MIT的一个性能测试报告显示,在一个8节点的集群上,Cassandra后端的单点摄入量为3.6w/s,Hbase的单点摄入量为6w/s,而今我们需要应对数倍于此摄入量的行业应用,比如一批物联网设备,一家银行、一个省级电信运营商、一款手机APP的实时交互事件等 的数据量可轻松过亿,将这些交互数据抽象成图形数据存储与计算需要我们的数据存储后端具有强大的吞吐量与稳定性,同时要求计算框架能够快速的依据历史记录得出业务指标结果。
AbutionGraph实时数据分析平台以此为背景进行设计与构建。其实现结合了实时数据流、实时指标计算、数据仓库的大吞吐等优势为一体,其端到端的架构可以直接从输入到输出进行映射,相当于一个纯经验的事物,流经数据库时,AbutionGraph内部自动做了关联计算、指标汇总等,即查即用,从而绕开数据直接解决问题,充分发挥了用大数据解决问题的作用。
既往平台的问题
AbutionGraph之所以要实现大规模准实时图形数据分析平台,是因为以往的图形数据存储平台大多数都为离线式系统,少量的实时系统也存在一些问题。比如:
较高的延迟,导入数据无法满足准实时查询的要求;
流式数据导入性能不足,无法支撑大规模的在线数据实时摄入,IO出现瓶颈;
批量导入数据前需要将原始数据依据Schema规整为gson/gxml等指定文件格式,数据ETL大多是高延迟且多日多步的;
此外,以往平台支持的数据源较为单一,无法多源数据同时入库。
实时技术选型
Apache Flink相比于Apache Spark,目前Spark的生态总体更为完善一些,且在机器学习的集成和应用性暂时领先。但作为下一代大数据引擎的有力竞争者-Flink在流式计算上有明显优势,Flink在流式计算里属于真正意义上的单条处理,每一条数据都触发计算,而不是像Spark一样的Mini Batch作为流式处理的妥协。Flink的容错机制较为轻量,对吞吐量影响较小,而且拥有图和调度上的一些优化,使得Flink可以达到很高的吞吐量。而Strom的容错机制需要对每条数据进行ack,因此其吞吐量瓶颈也是备受诟病。
鉴于如上3个通用的实时计算技术的比较,AbutionGraph选用了具有竞争力的下一代大数据技术Flink作为实时数据接入源,同时也是国内首个使用Flink作为数据源的图数据库,且为此实现了一些常用的消息组件接口:Kafka-2.0、Kafka-0.10、RocketMQ、ActiveMQ、Socket等,使用Flink作为与AbutionGraph的实时数据接入时,您可以不关注数据源有多少种,它支持任意多的不同消息组件同时对已有图形增量更新。
Ps:(AbutionGraph与Flink的结合使用可以很轻量,在单机环境下,您甚至都不需要安装部署它就可以使用这些功能,不必担心新的技术体系使系统变得臃肿)
鉴于Spark在离线批量计算、分布式机器学习的“王者”地位,技术生态也非常的完善。AbutionGraph顺其自然的将Spark作为离线计算(OLAP)平台,可将图形数据轻易的转变为Spark DataFrame/GraphFrame,反之,也可以将Spark DataFrame直接转换到AbutionGraph的图形中,这种数据源有别于Flink-即如上所说这是大批量的数据入库。此外,AbutionGraph还基于Spark构建了一个世界最丰富的分布式图挖掘算法库-AbutionGCS,它目前包含13大类60余种图算法。
实时存储结构
有了实时计算框架Flink作为多源数据的接入口,我们可能更关心数据在AbutionGraph中存储的优势在哪。
主流存储结构分析
市面上的图数据库一般采用B+树、LSM树、链表、哈希表等存储结构。No-SQL数据库一般采用LSM树,即日志结构合并树(Log-Structured Merge-Tree)作为数据结构,HBase也不例外,尽管这么做会使得读取效率在所难免地有一定下降,但换来的是高效得多的写入性能。众所周知,RDBMS一般采用B+树作为索引的数据结构,B+树对于数据读操作能很好地提高性能,但对于数据写,效率不高。这也是No-SQL数据库性能优越于传统mysql类数据库的原因之一。
图形数据存储
我们暂且将企业应用程序中产生的每一条数据成为一个发生的事件,譬如张三与李四之间的一次通话计为一个事件,推荐系统使用到的数据本身也天然是事件关系图,比如在人和人之间做用户推荐,或者在人与物之间做物品推荐等等,都围绕着发生的事件去做业务拓展。在将每一条事件数据描述成某些实体之间的关系时,我们可以使用刚才所说的树形结构或是链表,因为那是传统且经过反复验证了的方案。
基于使用的存储结构,传统图数据库还需要在此之上构建完善的并发控制机制来管理对图中顶点/边的并发访问。这使得他们不得不在每次操作中存储一部分额外的信息(例如乐观并发控制需要的读写集、多版本并发控制产生的多份数据)或是触及一些需要竞争的资源(例如悲观并发控制中的锁),而这些都会或多或少地在访问图数据库中的数据对象时引入一定开销。
做算法的同学相信都知道有一种结构它也可以存储图形,就是邻接矩阵,我们一般在推荐系统中会遇到比较多,它面向的是一整个的大图做大量的机器学习算法迭代,得到满意的结果同时也消耗了大量的计算资源,所以邻接矩阵不适合作为永久的数据存储结构,我们只关注它在内存中的临时性能,以及它灵活可变的阵列值,且可以依据横纵坐标快速定位到行列值(即实体/关系的属性值)。
鉴于树型存储与矩阵存储的优劣势,AbutionGraph的存储设计充分的借鉴了两者的优势,采用一种新颖的架构-“动态分布式维度数据模型”,基于关联数组进行图形数据的存储,提供了的统一存储框架,该框架包含传统数据库(即SQL)和非传统数据库(即NoSQL)。
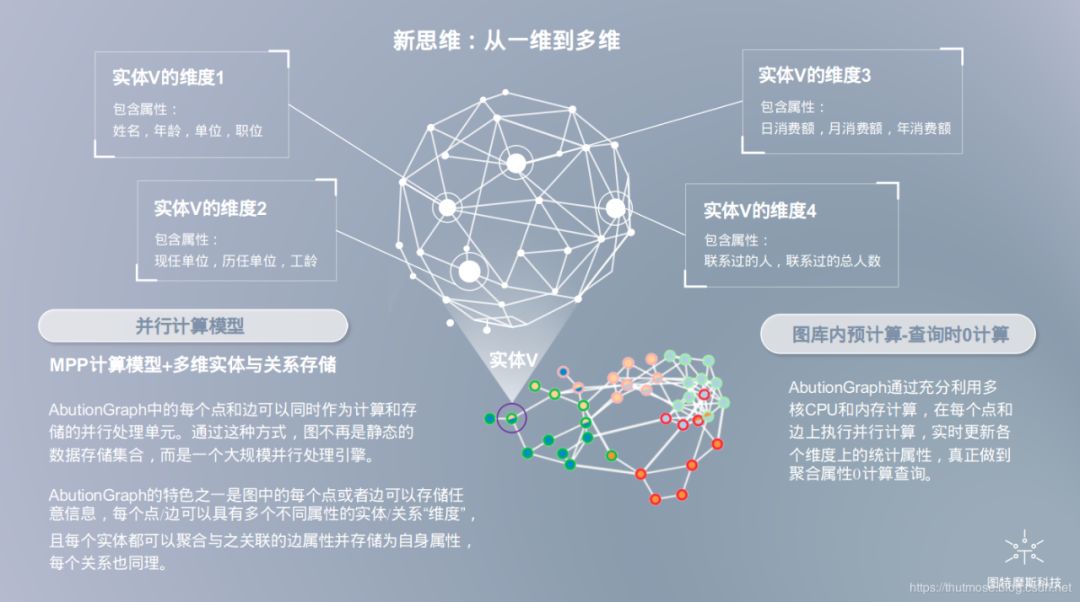
对于传统数据库的特性
存储形式举例:
普通维度的事件数据存储:
张三 -(于2020.1.1 09:00:00, 通话1分钟)-> 李四
张三 -(于2020.1.1 09:09:00, 通话2分钟)-> 李四
张三 -(于2020.1.1 11:00:00, 通话3分钟)-> 李四
张三 -(于2020.1.1 12:00:00, 通话5分钟)-> 李四
以小时为维度的统计事件存储:
张三 -(于2020.1.1 09:00:00到2020.1.1 09:59:59, 通话2次,共3分钟)-> 李四
张三 -(于2020.1.1 11:00:00到2020.1.1 11:59:59, 通话1次,共3分钟)-> 李四
张三 -(于2020.1.1 12:00:00到2020.1.1 12:59:59, 通话2次,共5分钟)-> 李四
以天为维度的统计事件存储:
张三 -(于2020.1.1 00:00:00到2020.1.1 24:59:59, 通话4次,共11分钟)-> 李四
AbutionGraph将存储与计算相结合,AbutionGraph中的每个点和边可以同时作为计算和存储的并行处理单元,就像我们实时汇总张三与李四的通话事件,我们不仅可以在原有维度上拓展出一个以天为汇总单位的维度,亦可以拓展出以小时、年、月为单位的维度,只要张三与李四发生通话,将立刻将汇总值更新到对应时间序列区间的维度值中。通过这种方式,图不再是静态的数据存储集合,而是一个大规模并行处理引擎。把存储后计算所耗费的大资源转变为实时计算所耗费的小资源,把离线型图数据库做成一个实时的业务型平台。即“动态”数据模型。
虽然这是种传统的行存储形式,但是您以图形三元组(实体,边属性,实体)的存储形式思考一下,仔细观察示例事件,有没有发现它们其实并不传统,张三/李四是实体,通话的次数/通话时长不就是边的属性嘛!如果您再用矩阵的思维取思考这些示例事件,张三/李四可不就是矩阵中横纵实体坐标轴中的一员嘛,而边属性就是两个实体交互所产生的具体值了。
对于非传统数据库的特性
AbutionGraph会自然的产生一个通用Schema,该Schema可用于完全索引并快速查询数据集中的每个唯一字符串,而无需像JanusGraph那样再显式的去构建数据属性索引来提高查询效率,AbutionGraph可以很友好的规避这些繁琐且不灵活的开发步骤。
AbutionGraph通过使用NoSQL的架构优势,您还可以直接像使用Hbase(实时读写的大数据OLTP引擎)那样直接将其作为一个Key-Value大数据库使用,且支持所有的Hbase功能,该特性把AbutionGraph定位为一个实时的交互图数据库平台。但Hbase的一个不足之处是无法满足超大规模的事件同时IO,可能单台服务器6w次/s即到瓶颈。
AbutionGraph的多维数据存储模式中,我们采用RoaringBitmap(一种高效的搜索技术)来快速检索基于时间序列的维度事件,加上AbutionGraph的实时属性汇总特性,对于了解Druid(准实时的多维数据仓库技术-OLAP引擎)的用户,您完全可以将AbutionGraph定位为一款相似技术,且支持所有的Druid功能,即数据仓库+知识存储平台。相较于Hbase,Druid加入的计算模型,实时性略有降低,但解决了超大规模的事件同时IO的瓶颈,更适合于大规模实时且永不停止的应用。
AbutionGraph的数据存储结构如下图所示:
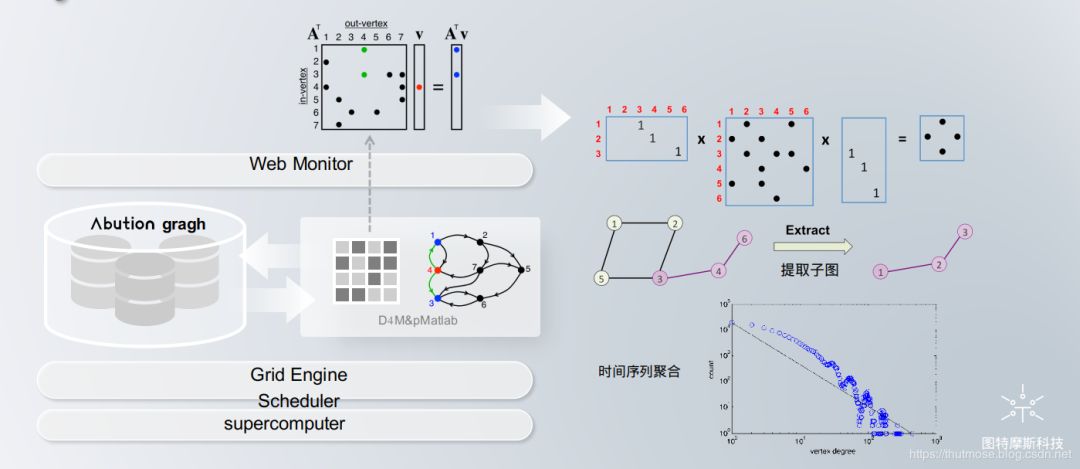
鉴于AbutionGraph动态分布式维度数据存储模型的种种特性,使它可以像Druid一样对大规模的在线数据实时存储与汇总计算,又可以像Hbase一样快速的对事件保存与查询,又同时兼具传统数据库的表模式到多维三元组矩阵的映射,在面向小量事件数据的时候,AbutionGraph可以与Hbase特性相当,在面向大量事件数据的时候,AbutionGraph可以与Druid特性相当。AbutionGraph尝试结合这些独特的处理技术(稀疏线性代数,关联数组,分布式数组和三重存储/ NoSQL数据库)的优势,以提供可解决数据库和计算系统的统一问题,即大数据相关的问题。它可以直接表示复杂的关系(稀疏矩阵或图结构)。因此,使用AbutionGraph来开发复杂数据场景比于其他图数据库具有更大的效率优势。
不管场景如何,AbutionGraph都具备了一款准实时的知识图谱平台的条件,意味着可对任意数据量的事件进行存储与快速查询。这使得AbutionGraph顺理成章的成为国内第一个使用Apache Flink作为超大大规模实时事件流接入的端到端知识图谱平台,AbutionGraph在毫秒-秒之内完成图形生成后就立即可查询。
Apache Flink 在中国的应用
随着 Flink 社区的快速发展,其技术也逐渐走向成熟。Apache Flink 能够以高吞吐低延时的优异实时计算能力帮助企业和开发者实现数据算力升级,支持海量数据的亚秒级快速响应。在 2019 年末,国内已经有大量的本土互联网公司开始采用 Apache Flink 作为主流的实时计算解决方案。同时,在全球范围内,优步、网飞、微软和亚马逊等国际互联网公司也逐渐开始使用 Apache Flink。
AbutionGraph+Flink:物联网时代的应用利器
1)数据据时代的知识图谱
大数据时代的到来,催生了以知识图谱为代表的大规模知识表示,同时也为其发展奠定了必要的基础。今天这个时代谈知识工程跟 20 世纪谈专家系统有什么不同?最大的不同点是我们有前所未有的大数据、前所未有的机器学习能力以及前所未有的计算能力。这三个技术的合力作用使我们可以摆脱对专家的依赖,使实现大规模自动化知识获取成为可能,这也是大数据知识工程的根本。这一种知识获取,本质上可以称为自下而上的获取。
显然,这种数据驱动的知识获取方式与人工构建的知识获取方式完全不同。前者可以实现大规模自动化知识获取,无须高昂的人力成本。相对于人工构建的知识获取方式,数据驱动的知识获取方式是一种典型的自下而上的做法,是相对务实、实用的做法。大数据时代所发展出来的众包技术使得知识的规模化验证成为可能。知识获取的众多环节均可以受益于众包技术。比如,训练知识抽取模型时可以通过众包获取标注样本,从而构建有效的有监督抽取模型。
在知识图谱技术的引领下,各种各样的知识表示将在不损失质量的前提下逐步提升规模,从小规模的知识表示变成大规模的知识表示,最终应对大规模开放性给知识工程带来的巨大挑战。
2)物联网时代的知识图谱
随着5G和垂直行业的成熟商用,网络需要接入更多设备、处理海量数据、满足低时延业务需求。通信技术的升级换代一直是推动社会创新发展的重要力量,5G技术的到来,通信产业开启了全新的时代,也代表着人们真正迈进物联网时代,“万物互联”已是大势所趋,一大批的智能设备正在倍速的加入到互联网中,在云管端均发生了深刻变化,从移动互联到万物智联,从消费互联网到产业互联网,从单一领域创新到跨产业融合创新。然而,物联网要实现智能化,仍面临众多挑战:网络中互联的传感器产生数据量大,数据变化迅速,这对数据库的摄入量、可靠性和实时性要求很高,而且数据之间往往相互关联、查询频繁。
AbutionGraph的出现,就是为了解决传统离线式图形数据库所不能满足的的这些新业务要求。不管是在物联网领域或是金融风控、欺诈检测中,AbutionGraph在结合图处理引擎后还可以提供其所需的关联数据的高效复杂查询与计算能力。

-End-

◆
精彩推荐
◆
点击阅读原文,或扫描文首贴片二维码
所有CSDN 用户都可参与投票和抽奖活动
加入福利群,每周还有精选学习资料、技术图书等福利发送
你点的每个“在看”,我都认真当成了AI
以上是关于结合Flink,国内自研,大规模实时动态认知图谱平台——AbutionGraph |博文精选的主要内容,如果未能解决你的问题,请参考以下文章
如何迁移开源 Flink 任务到实时计算Flink版?实战手册来帮忙!