Flink 可以做啥?它为什么这么火?
Posted 程序猿DD
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flink 可以做啥?它为什么这么火?相关的知识,希望对你有一定的参考价值。
点击蓝色“程序猿DD”关注我
回复“资源”获取独家整理的学习资料!
作者 | zhisheng
170元买400元书的机会又来啦!
认识zhisheng也已经很长一段时间了,非常有幸他的实习一血被我们拿了。不过也非常可惜,后面没有能够留下来一起共事。但是 ,“上帝为你关掉一扇门,就会为你开启一扇窗”。在离开永辉之后,zhisheng去了阿里云,也接触了更多前沿技术与实际的应用场景,这也给他了非常好的学习机会。努力的人运气一定不会太差,从他开始在博客连载Flink开始,就觉得这小子将来有戏! 什么?你还不知道啥是Flink?那么通过下面这篇他的经历,一起了解一下Flink吧! 下文转载自zhisheng的文章,文中的“我”是zhisheng,不是小编我。
我是 2018 年 6 月加入公司,一直负责监控平台的告警系统。之后,我们的整个监控平台架构中途换过两次,其中一次架构发生了巨大的变化。我们监控告警平台最早的架构如下图所示:
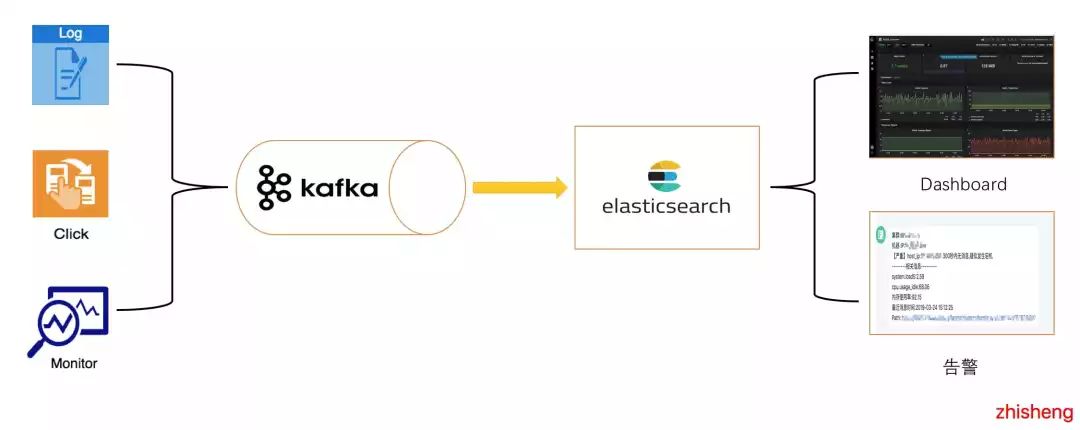
这个架构的挑战难点在于:
海量的监控数据(Metric & Log & Trace 数据)实时写入 ElasticSearch;
多维度的监控指标页面展示(Dashboard) 查 ElasticSearch 的数据比较频繁;
不断递增的告警规则需要通过查询 ElasticSearch 数据来进行判断是否要告警。
从上面的几个问题我们就可以很明显的发现这种架构的瓶颈就在于 ElasticSearch 集群的写入和查询能力,在海量的监控数据(Metric & Log & Trace 数据)下实时的写入对 ElasticSearch 有极大的影响。
我依然清楚记得,当时经常因为写入的问题导致 ElasticSearch 集群挂掉,从而让我的告警和监控页面(Dashboard)歇菜(那会老被喷:为啥配置的告警规则没有触发告警?为啥查看应用的 Dashboard 监控页面没数据)。我也很无奈啊,只想祈祷我们的 ElasticSearch 集群稳一点。
01
初次接触 Flink
在如此糟糕的架构情况下,我们挺过了几个月,后面由于一些特殊的原因,我们监控平台组的整体做了一个很大的架构调整,如下图:
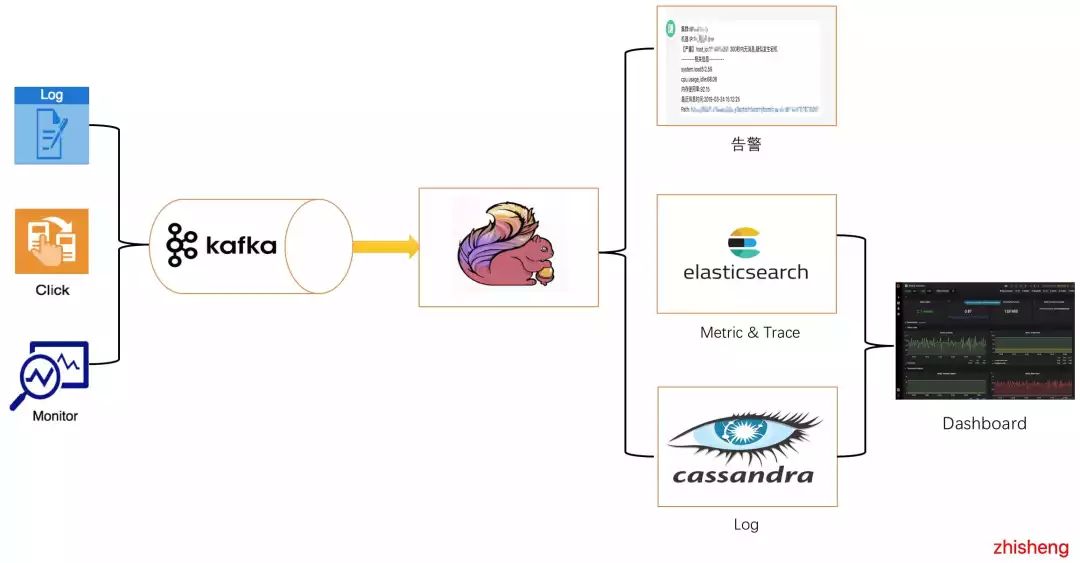
主要做了四点改变:
接入 Flink 集群去消费 Kafka 数据,告警的 Flink Job 消费 Kafka 数据去判断异常点,然后做告警
Metric & Trace 数据存储到 ElasticSearch,之前还存储在 ElasticSearch 中的有 Log 数据
Log 数据存储到 Cassandra
Dashboard 查询数据增加 API 查询 Cassandra 的日志数据
02
遇到 Flink 相关的挑战
那时候我们跑在 Flink 上面的 Job 也遇到各种各样的问题:
消费 Kafka 数据延迟
checkpoint 失败
窗口概念模糊、使用操作有误
Event Time 和 Processing Time 选择有误
不知道怎么利用 Watermark 机制来处理乱序和延迟的数据
Flink 自带的 Connector 的优化
Flink 中的 JobManager 和 TaskManager 经常挂导致 Flink Job 重启
Flink 集群模式的选型
...
03
为什么要学习 Flink?
随着大数据的不断发展,对数据的及时性要求越来越高,实时场景需求也变得越来越多,主要分下面几大类:
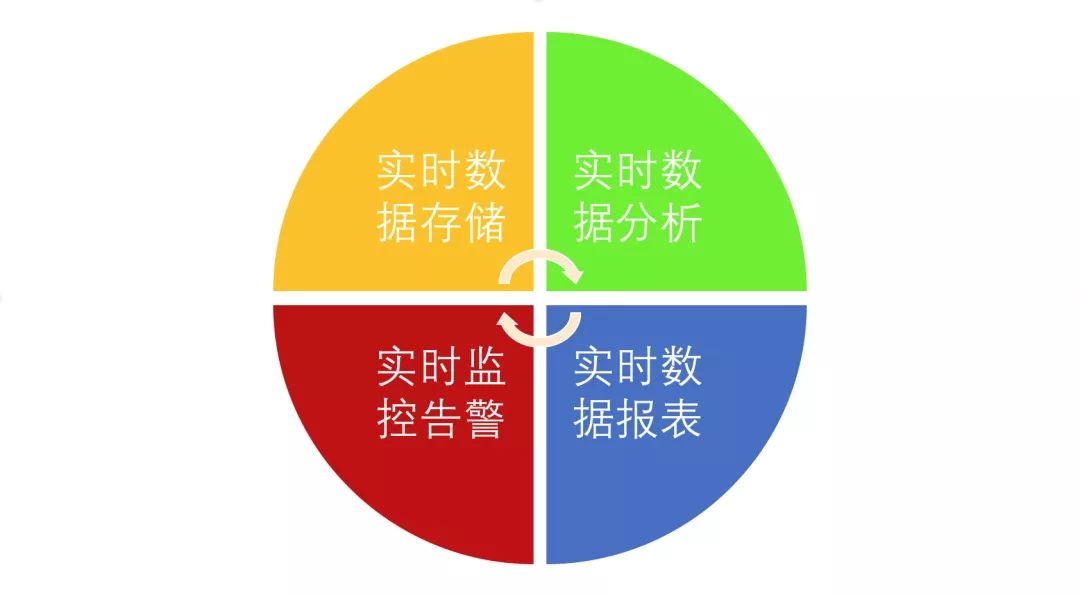
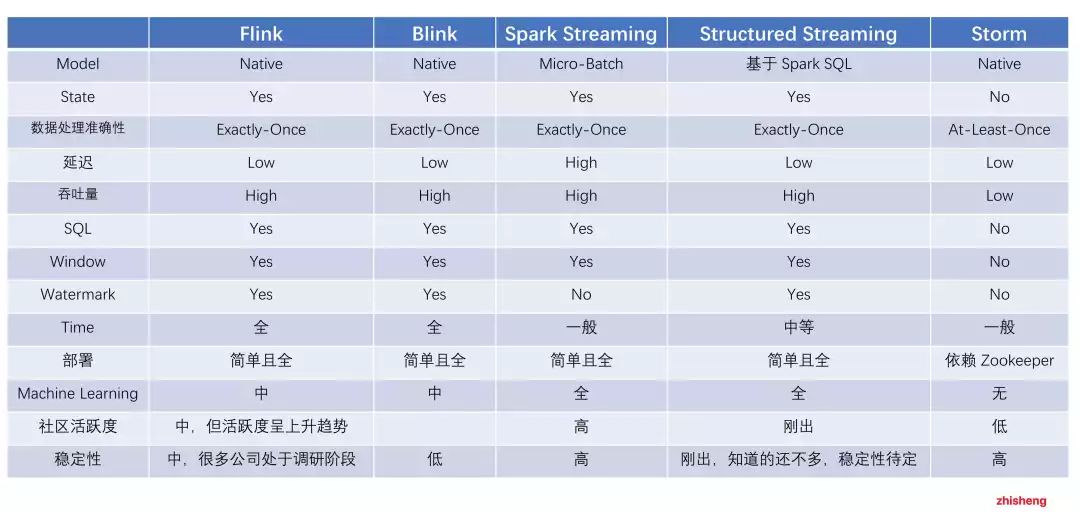
那么为了满足这些实时场景的需求,衍生出不少计算引擎框架,现有市面上的大数据计算引擎的对比如下:
04
我为什么要写 Flink 专栏?
扫码了解 Flink 专栏详情
▼

专栏亮点
全网首个使用最新版本 Flink 1.9 进行内容讲解(该版本更新很大,架构功能都有更新),领跑于目前市面上常见的 Flink 1.7 版本的教学课程。
包含大量的实战案例和代码去讲解原理,有助于读者一边学习一边敲代码,达到更快,更深刻的学习境界。目前市面上的书籍没有任何实战的内容,还只是讲解纯概念和翻译官网。
在专栏高级篇中,根据 Flink 常见的项目问题提供了排查和解决的思维方法,并通过这些问题探究了为什么会出现这类问题。
-
在实战和案例篇,围绕大厂公司的经典需求进行分析,包括架构设计、每个环节的操作、代码实现都有一一讲解。
专栏内容
预备篇
基础篇
进阶篇
高级篇
实战篇
系统案例篇
讲解大型流量下的真实案例:如何去实时处理海量日志(错误日志实时告警/日志实时 ETL/日志实时展示/日志实时搜索)、基于 Flink 的百亿数据实时去重实践(从去重的通用解决方案 --> 使用 BloomFilter 来实现去重 --> 使用 Flink 的 KeyedState 实现去重)。
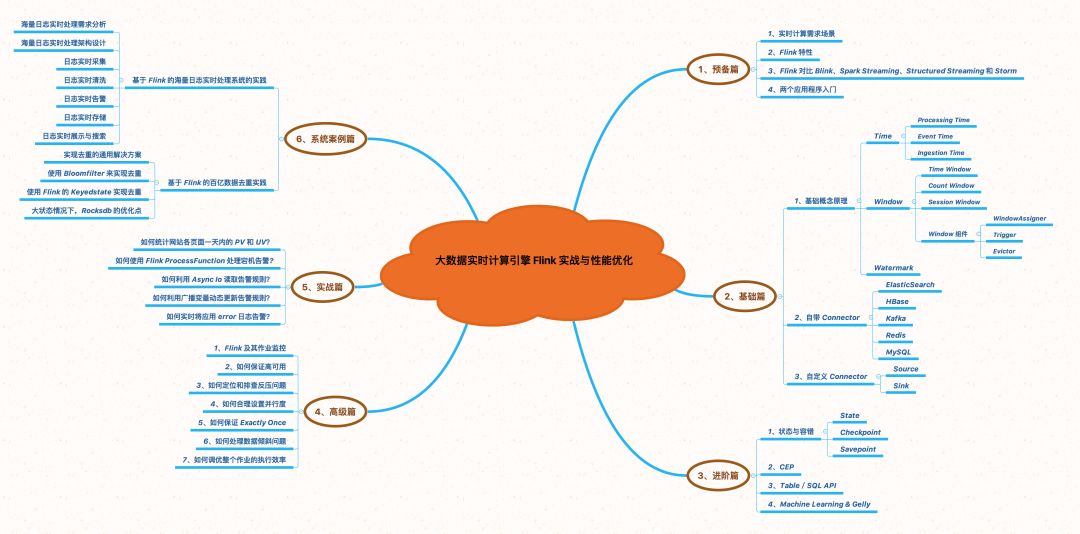
▲Flink 专栏思维导图
多图讲解 Flink 知识点
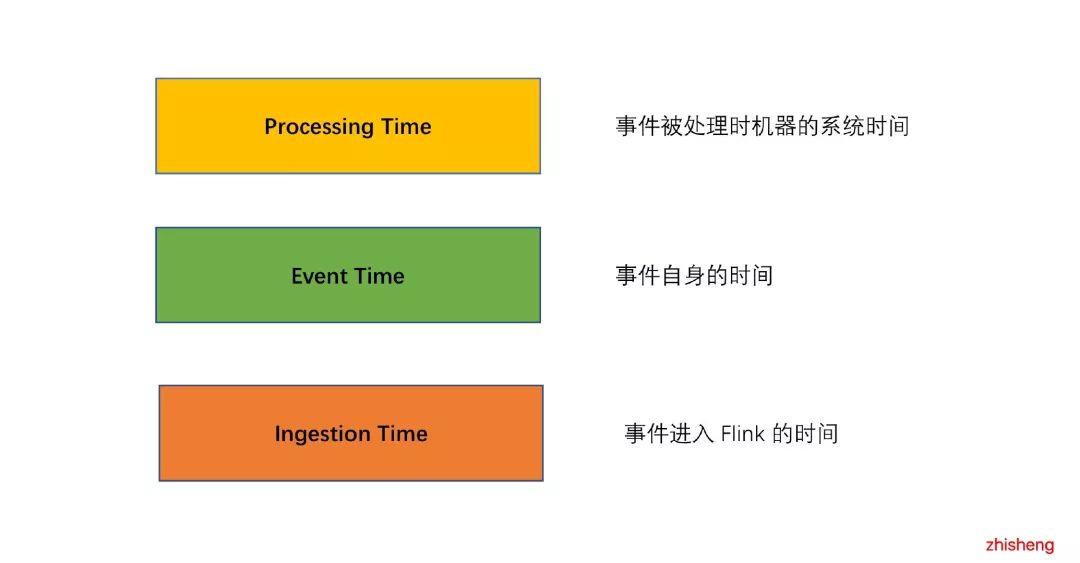
▲Flink 支持多种时间语义
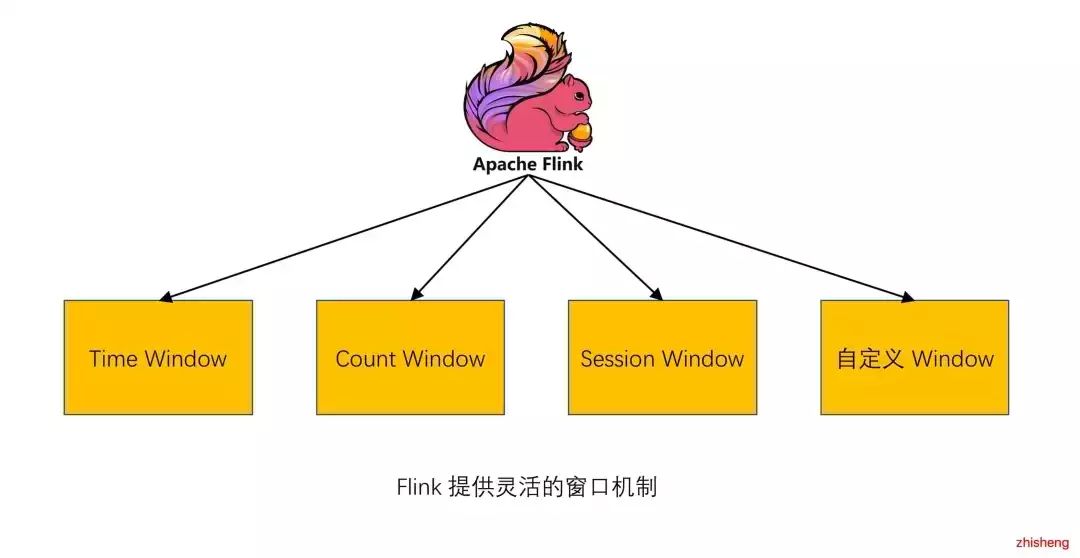
▲Flink 提供灵活的窗口
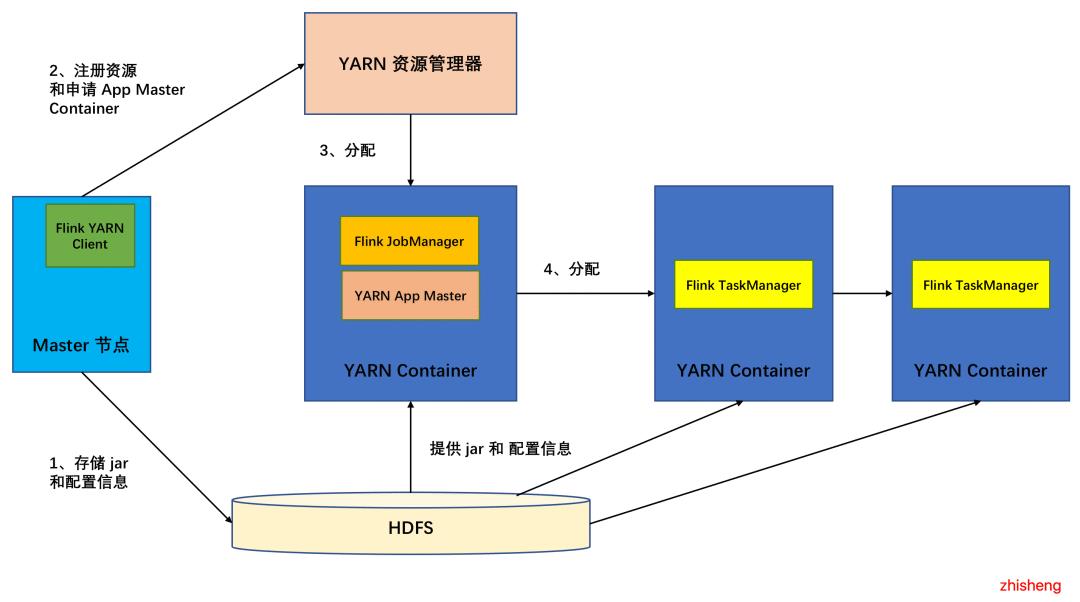
▲Flink On YARN
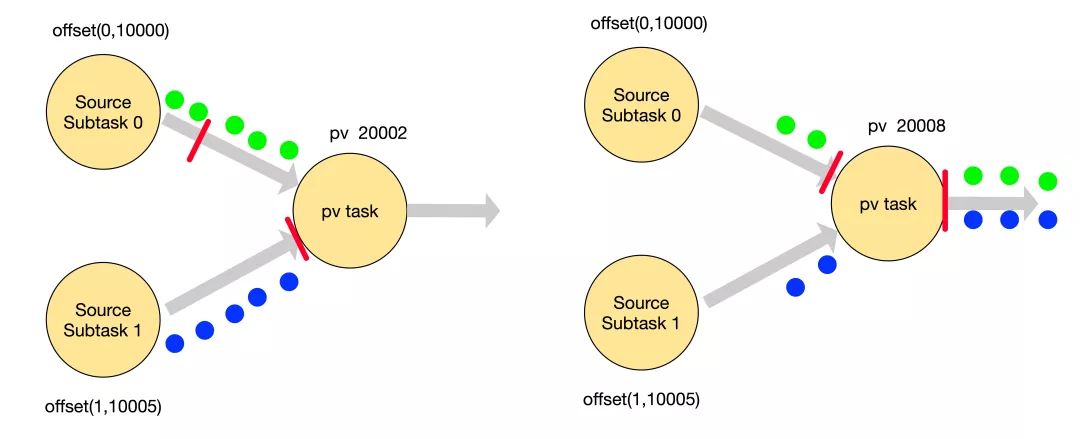
▲Flink Checkpoint
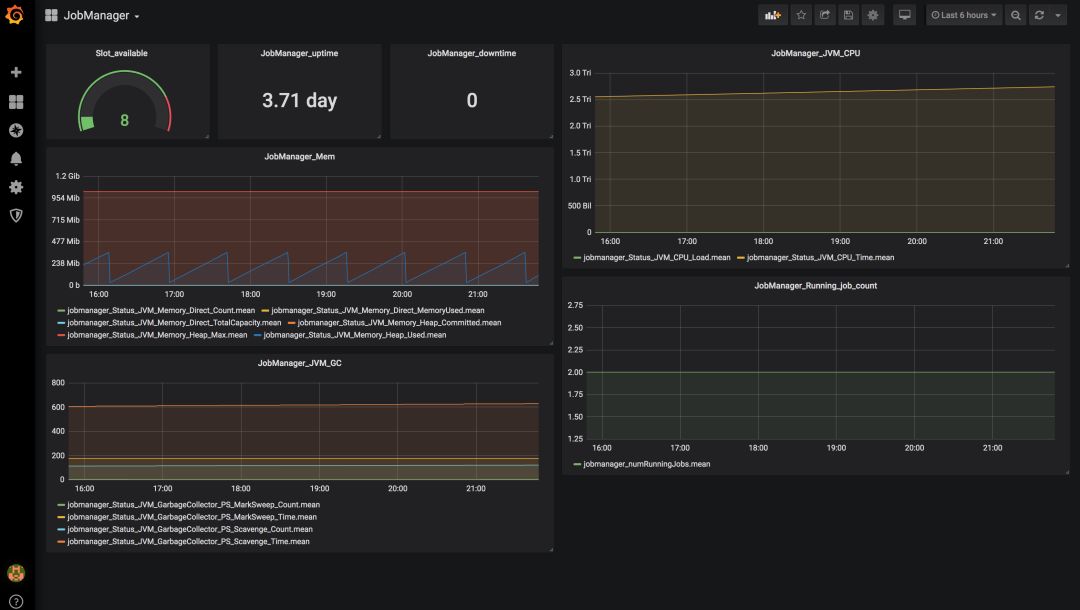
▲Flink 监控
专栏作者-zhisheng
在某大型公司担任监控平台研发工程师,负责实时计算引擎开发和流式告警,现专注于实时计算开发工作。
擅长 Flink、kafka、ElasticSearch 等大数据组件的项目开发和管理等。
专栏作者-范瑞
你将获得什么
掌握 Flink 与其他计算框架的区别
掌握 Flink Time/Window/Watermark/Connectors 概念和实现原理
掌握 Flink State/Checkpoint/Savepoint 状态与容错
熟练使用 DataStream/DataSet/Table/SQL API 开发 Flink 作业
掌握 Flink 作业部署/运维/监控/性能调优
学会如何分析并完成实时计算需求
获得大型高并发流量系统案例实战项目经验
适宜人群
Flink 爱好者
实时计算开发工程师
大数据开发工程师
计算机专业研究生
-
有实时计算场景场景的 Java 开发工程师
Flink 在流式上面带来的优势,底延迟、高吞吐、容错机制等。
-END-
留言交流不过瘾
关注我,回复“加群”加入各种主题讨论群
朕已阅
以上是关于Flink 可以做啥?它为什么这么火?的主要内容,如果未能解决你的问题,请参考以下文章