日均20万亿次计算量!腾讯基于Flink的实时流计算平台演进之路丨附PPT下载
Posted InfoQ
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了日均20万亿次计算量!腾讯基于Flink的实时流计算平台演进之路丨附PPT下载相关的知识,希望对你有一定的参考价值。
大家好,我是来自腾讯大数据团队的杨华(vinoyang),很高兴能够参加这次北京的 QCon,有机会跟大家分享一下腾讯实时流计算平台的演进与这个过程中我们的一些实践经验。

这次分享主要包含四个议题,我会首先阐述一下腾讯在实时计算中使用 Flink 的历程,然后会简单介绍一下腾讯围绕 Flink 的产品化实践:我们打造了一个 Oceanus 平台,同时腾讯云也早已提供基于 Flink 的实时流计算服务,接着我们会重点跟大家聊一聊我们对社区版 Flink 的一些扩展与改进、优化。
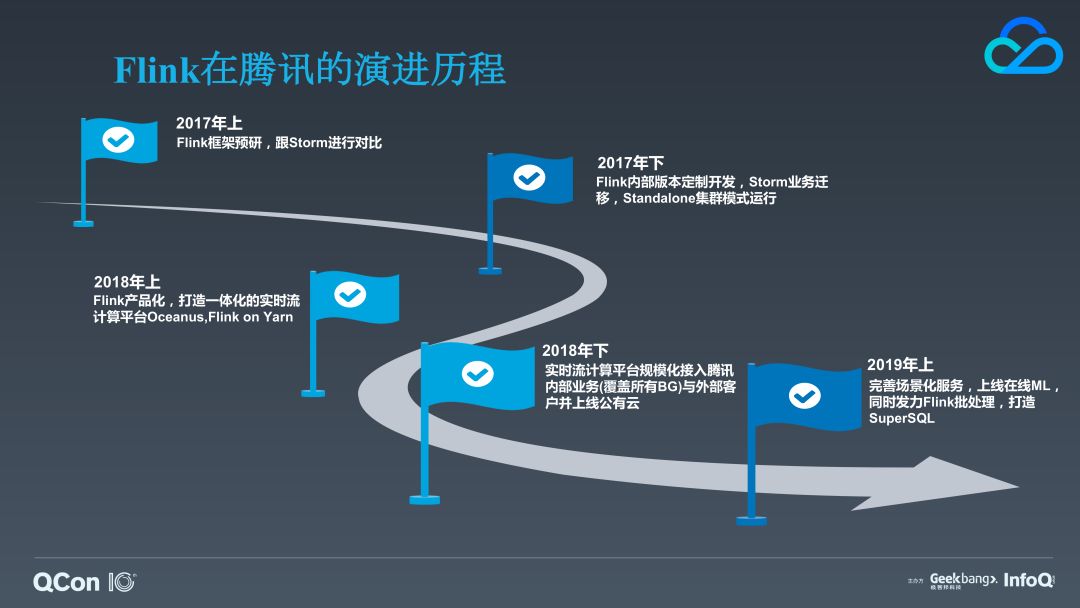
首先,我们进入第一个议题。Flink 在腾讯正式被考虑替代 Storm 是在 2017 年。
17 年上半年,我们主要在调研 Flink 替换 Storm 的可行性、特性、性能是否能够满足我们的上线要求。在此之前,我们内部以 Storm 作为实时计算的基础框架也已经有几年的时间了,在使用的过程中也发现了 Storm 的一些痛点,比如,没有内置状态的支持,没有提供完备的容错能力,没有内置的窗口 API,core API 无法提供 Exactly-once 的语义保证等等。
17 年下半年,我们从社区拉出当时最新的发布分支(1.3.2)作为我们内部的定制开发分支进行开发。作为一个试点,我们选择了内部一个流量较大的业务来进行替换,这个业务在我们内部是以 standalone 的模式部署的,所以我们最初也使用的是 Flink 的 standalone 部署模式。
18 年上半年,我们开始围绕 Flink 进行产品化,打造了一个全流程、一体化的实时流计算平台——Oceanus,来简化业务方构建实时应用的复杂度并降低运维成本,这也基本明确了后续我们主要的运行模式是 Flink on YARN。
18 年下半年,我们的 Oceanus 平台已经有足够的能力来构建常见的流计算应用,我们部门内部的一些实时流计算业务也已经在平台上稳定运行,于是我们开始为腾讯云、腾讯其他事业群以及业务线提供流计算服务。同时,我们也将平台整合进我们的大数据套件,为外部私有云客户提供流计算服务。
19 年上半年,我们的主要目标是在 Oceanus 上沉淀并完善上层的场景化服务建设,比如提供在线机器学习、风控等场景化服务。另外,我们也在 Flink 批处理方向发力,利用 Flink 的计算能力来满足跨数据中心,跨数据源的联合分析需求。它可以做到:数据源 SQL 下推,避免集群带宽资源浪费;单 DC 内 CBO(基于代价优化),生成最优的执行计划;跨 DC CBO,根据 DC 负载和资源选择最佳 DC 执行计算,从而获得更好的资源利用和更快的查询性能。以上就是腾讯使用 Flink 的整个历程。


接下来我们来了解一下,目前 Flink 在腾讯使用的现状。目前我们 Oceanus 平台 YARN 集群的 vcore 总数目达到了 34 万,累计的峰值计算能力接近 2.1 亿 / 秒,日均处理消息规模近 20 万亿。到目前为止,腾讯内部除了广告的在线训练业务外,原先运行在 Storm 上的实时流计算业务都已逐步迁移到 Flink 引擎上,而广告这块的业务预计也会在今年下半年迁移完成。
接下来,我们进入第二个议题:简要介绍一下我们的 Oceanus 平台。
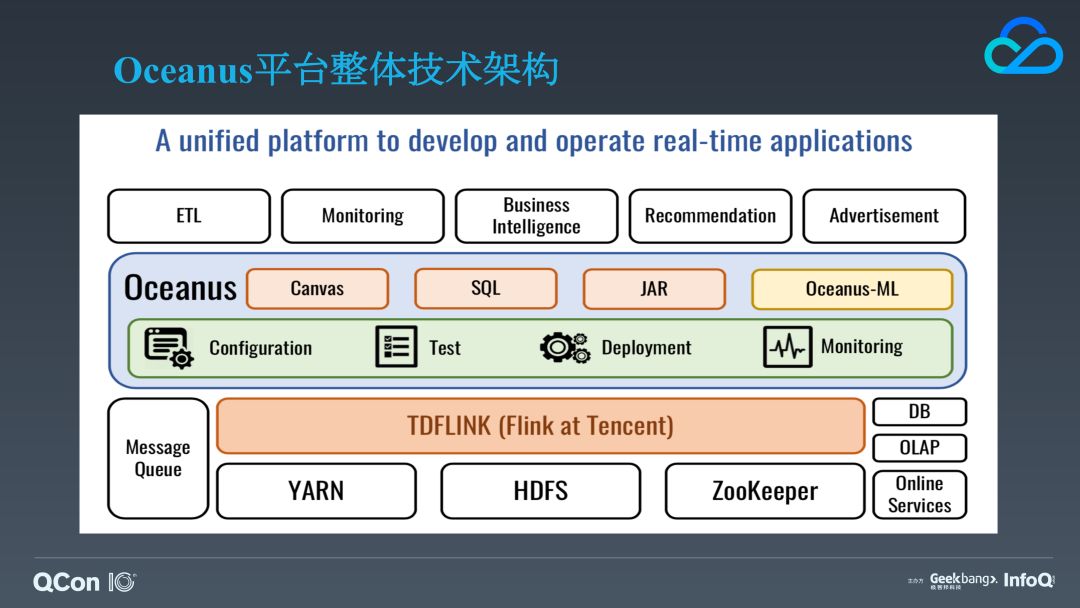
首先,我们来看一下 Oceanus 平台的整体技术架构。我们内部定制版的 Flink 引擎,称之为 TDFLINK,它跟其他的一些大数据基础设施框架交互并协同支撑了我们上层的 Oceanus 平台,Oceanus 支持画布、SQL 以及 Jar 三种形式构建应用,为了方便业务方降低整体成本,我们还提供了配置、测试、部署等完整配套的功能,在平台之上我们提供了一些领域特定的场景化服务比如 ETL、监控、推荐广告等。
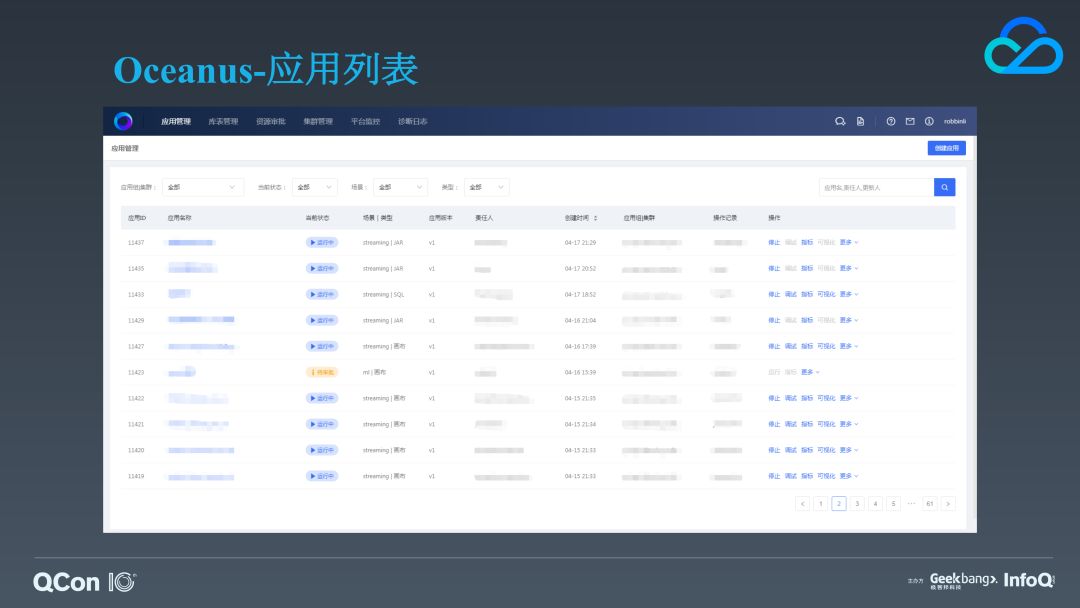
下面我们来介绍 Oceanus 的几个典型功能。首先这是某个用户的应用列表页。从列表中,我们可以看到应用的当前状态、类型、迭代的版本,它归属于哪个场景等信息。在操作栏,我们可以一键对应用进行启停、调试,查看它的指标信息等,除此之外我们还提供了很多便捷的操作,比如快速复制一个应用,他们都收纳在“更多”菜单按钮中。
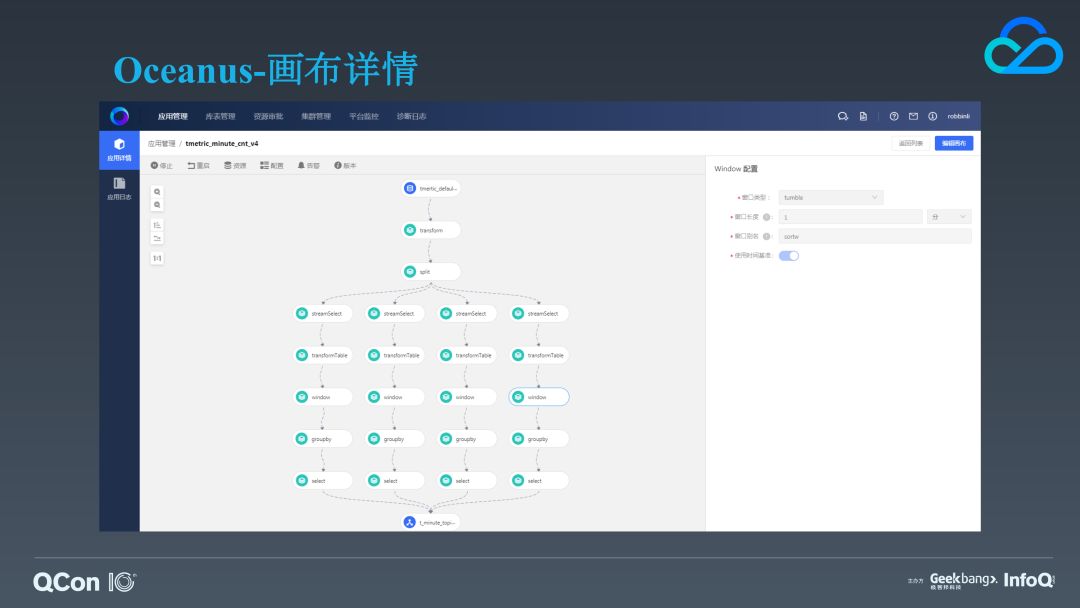
这是我们的一个指标分钟级统计的画布应用详情页,我们为 ETL 类型的应用提供了一个通用的 transform 算子。它提供了很多功能细分的可插拔的便捷函数来简化常见的事件解析与提取的复杂度。在图中,多种不同类型的指标经过 split 算子分流后将相同的指标进行归类,然后再对它们应用各自的统计逻辑,就像这里的窗口一样,基本上每个算子都是配置化的。像这种类型的应用我们通过拖拽、配置就可以轻松完成它的构建。

这幅图展示了我们的指标详情页检查点的指标明细,为了让业务人员更直观地了解它们最关心的指标信息,我们将一些必要的指标进行了重新梳理并展示到我们的平台上,这里有些指标直接使用了 Flink 提供的 REST API 接口,而有些指标则是我们内部扩展定制的。
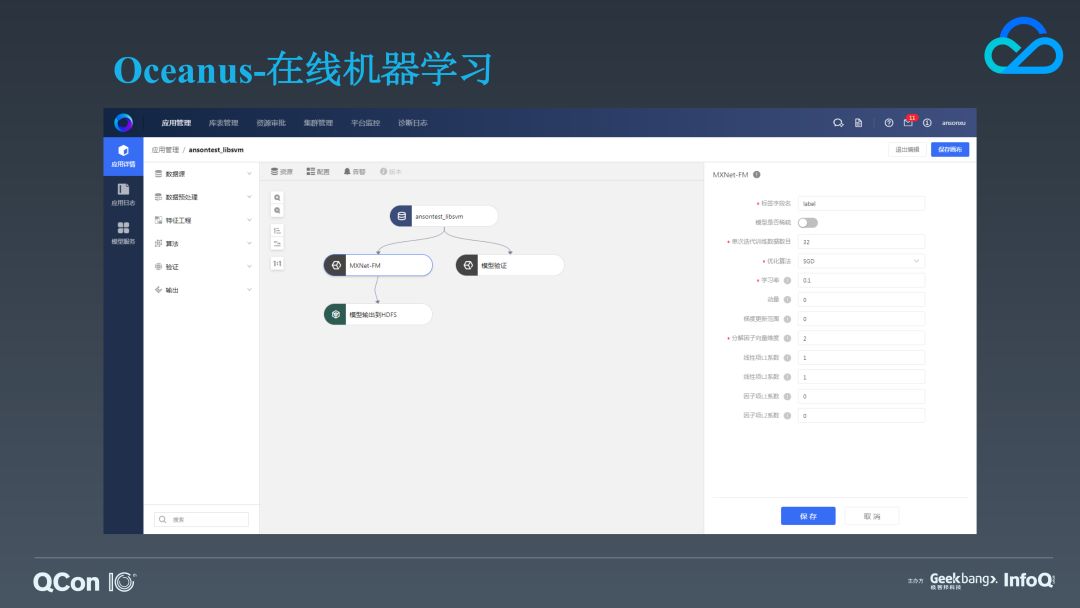
最后,我们来介绍一下最近上线的在线机器学习模块。这是我们一个模型训练应用的详情页,同样它也是画布类型的,我们对常规的机器学习类型的应用进行了步骤拆分,包括了数据预处理、算法等相关步骤,每个步骤都可以进行拖拽,再加上配置的方式就可以完成一个 ML 类型的应用创建。
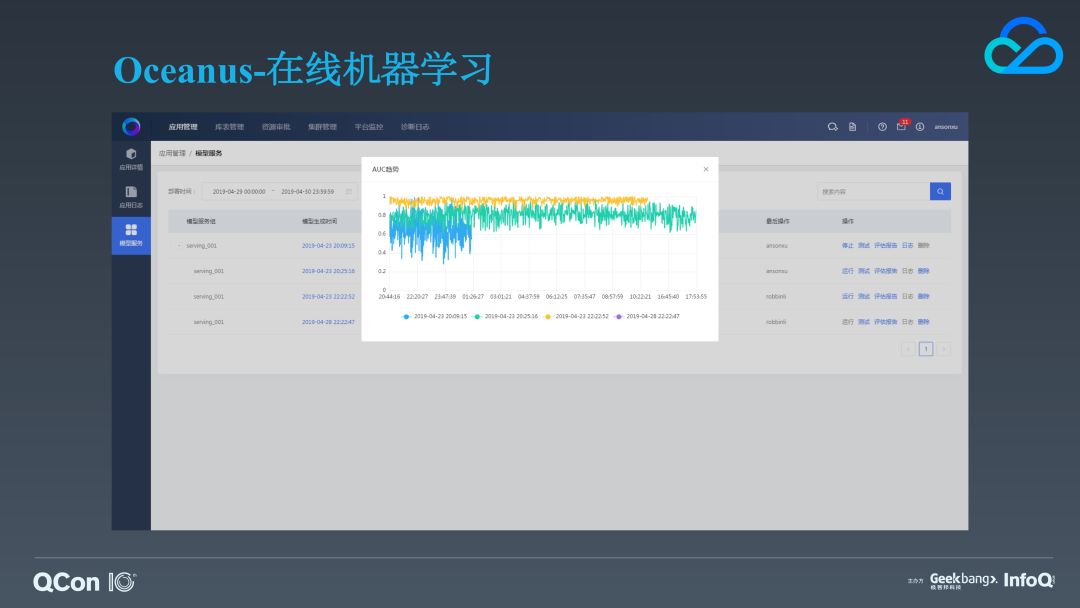
对于训练得到的模型,我们也提供了模型服务功能,我们用模型服务组来管理每个模型的不同时间的版本,点击右侧的“评估报告”可以查看这个模型的 AUC 趋势。
以上是对 Oceanus 平台的介绍,如果大家有兴趣可以扫描 PPT 最后的二维码来进一步了解我们的平台以及腾讯云上的流计算服务。
接下来,我们进入下一个议题,介绍我们内部 Flink 版本在通过腾讯云对外提供服务时基于内部以及业务的相关需求对社区版的扩展与优化。
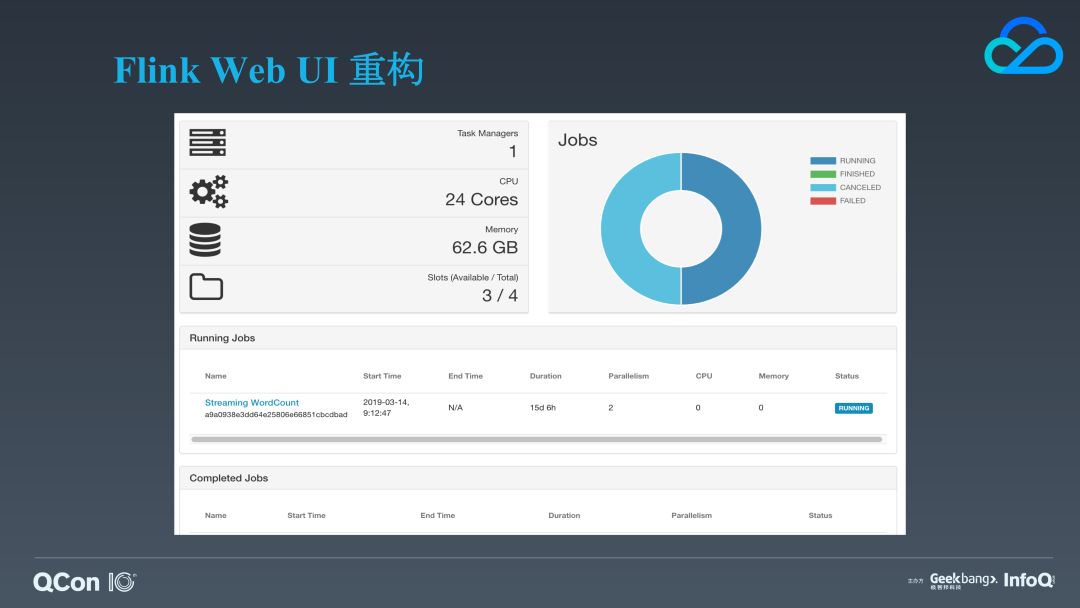
第一个改进是我们重构了 Flink Web UI,我们重构的原因是因为社区版的 Flink Web UI 在定位问题的时候不能提供足够的信息,导致问题定位的效率不够高。尤其是 Job 并行度非常大,YARN 的 container 数目非常多的时候,当 Job 发生失败,很难快速去找到 container 和节点以查看进程的堆栈或者机器指标。所以,为了更高效地定位问题,我们对 Flink web UI 进行了重构并暴露了一些关键指标。

这是我们一个 TaskManager 的详情页,我们为它新增了一个“Threads” Tab,我们可以通过它看到 Task 相关的线程信息:线程名称、CPU 消耗、状态以及堆栈等。这样一旦哪个算子的线程可能成为瓶颈时,我们可以快速定位到它阻塞在什么方法调用上。
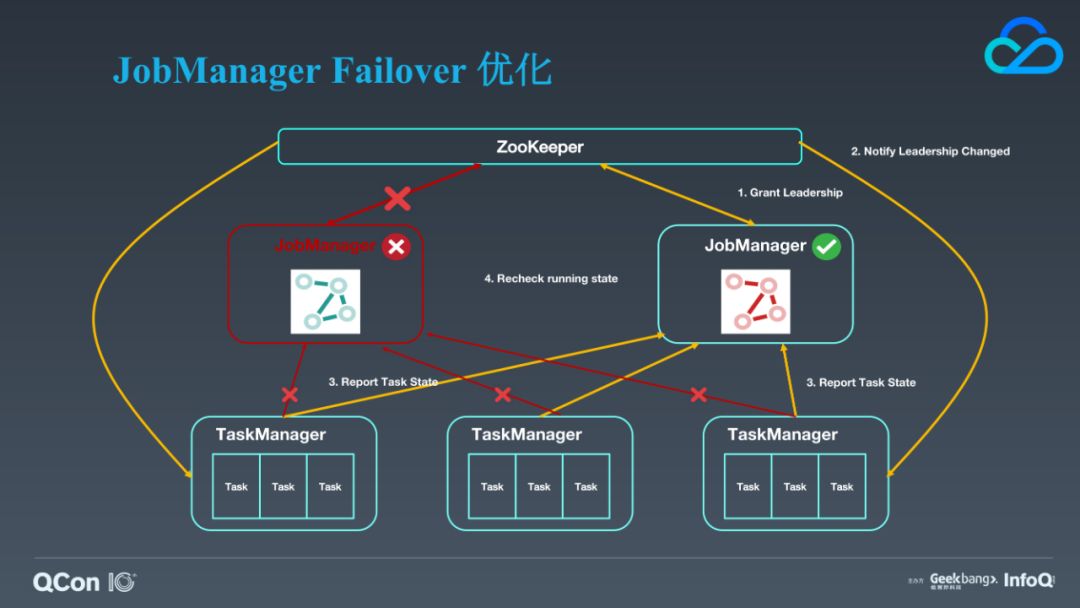
接下来的这个改进是对 JobManager failover 的优化。大家应该都知道社区版的 Flink JobManager HA 在 Standalone 模式下有个很大的问题是:它的 standby 节点是冷备的,JobManager 的切换会导致它管理的所有 Job 都会被重启恢复,这一行为在我们现网环境中是不可接受的。所以,我们首先定制的第一个大特性就是 JobManager 的 failover 优化,让 standby 节点变成热备,这使得 JobManager 的切换对 TaskManager 上已经正在运行的 Job 不产生影响。我们已经对 Standalone 以及 Flink on YARN 这两种部署模式支持了这个特性,Flink on YARN 的支持还处于内部验证阶段。我们以对 Standalone 模式的优化为例来进行分析,它主要包含这么几个步骤:
取消 JobManager 跟 TaskManager 因为心跳超时或 Leadership 变动就 cancel task 的行为;
对 ExecutionGraph 核心数据的快照;
通过 ExecutionGraphBuilder 重构空的 ExecutionGraph 加上快照重置来恢复出一个跟原先等价的 ExecutionGraph 对象;
TaskManager 跟新的 JobManager leader 建立连接后以心跳上报自己的状态和必要的信息;
新的 JobManager 确认在 reconcile 阶段 Job 的所有 task 是否正常运行。
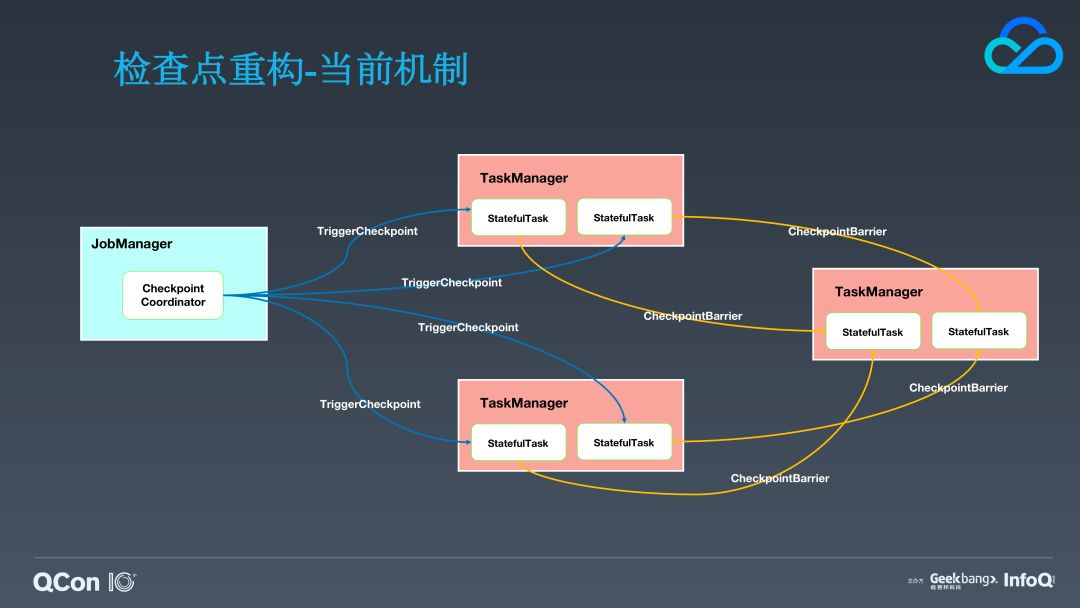
接下来的这个改进已经在反馈社区的过程中,它就是对检查点失败处理的改进。在探讨改进之前,我们先来了解一下社区版当前的处理机制。JobMaster 中,每个 Job 会对应一个 Checkpoint Coordinator,它用来管理并协调 Job 检查点的执行。当到达一个检查点的触发周期,Coordinator 会对所有的 Source Task 下发 TriggerCheckpoint 消息,source task 会在自身完成快照后向下游广播 CheckpointBarrier,作为下游 task 触发的通知。其中,如果一个 task 在执行检查点时失败了,这取决于用户是否容忍这个失败(通过一个配置项),如果选择不容忍那么这个失败将变成一个异常导致 task 的失败,与此同时 task 的失败将会通知到 JobMaster,JobMaster 将会通知这个 Job 的其他 task 取消它们的执行。现有的机制存在一些问题:
Coordinator 并不能控制 Job 是否容忍检查点失败,因为控制权在 task 端;
Coordinator 当前的失败处理代码逻辑混乱,区分出了触发阶段,却忽略了执行阶段;
无法实现容忍多少个连续的检查点失败则让 Job 失败的逻辑。
了解了现有的实现机制,我们再来看接下来的改进方案。首先,我们对源码中 checkpoint package 下的相关类进行了重构,使得它不再区分触发阶段,引进了更多的检查点失败原因的枚举并重构了相关的代码。然后我们引入了 CheckpointFailureManager 组件,用来统一失败管理,同时为了适配更灵活的容忍失败的能力,我们引入了检查点失败计数器机制。现在,当我们遇到检查点失败后,这个失败信息会直接上报到 Coordinator,而是否要让 Job 失败具体的决策则由 CheckpointFailureManager 作出,这就使得 Coordinator 具有了完整的检查点控制权,而决策权转让给 CheckpointFailureManager,则充分实现了逻辑解耦。
下面我们要看的这个特性是对 Flink 原生窗口的增强,所以我们称之为 Enhanced window。大家都知道 Flink 的 EventTime 语义的窗口无法保证任意延迟到达的数据都能参与窗口计算,它只允许你设置一个容忍延迟的时间。但我们的应用场景里,数据的延迟可能非常高,甚至有时跨天的也会发生,但我们无法为常规的窗口设置这么长的延迟时间,并且我们的业务无法容忍延迟数据被丢弃的行为。因此针对这种场景,Flink 自带的窗口无法满足我们的需求。所以,我们对它做了一些改进,它能够容忍任意延迟到来的事件,所有的事件都不会被丢弃,而是会加入一个新的窗口重新计算,新窗口跟老窗口毫无关系,所以最终可能针对一个窗口在用户的目标表中会存在多条记录,用户只需自行聚合即可。

为了方便在上层使用这种窗口,我们为它定制了 SQL 关键字,这幅图展示了我们在指标统计场景中使用它的一个示例。

这是我们根据业务需求所定制的另一个窗口——增量窗口。在业务中经常遇到这样的需求:希望看到一个窗口周期内的增量变化,这个窗口周期可能会很长,比如一个天级别的窗口。比如我们希望看到一天内每个小时的 PV 增长趋势,或者游戏中的一些虚拟物品的消耗趋势。Flink 默认的翻滚窗口以及触发器是没有内置这种窗口内小批次触发的功能。当然我们也可以通过一个个的小窗口来计算阶段性的结果,然后再对数据进行二次处理,但这样会比较麻烦。所以我们实现了大窗口内多次增量触发的功能,扩展实现了一个窗口内多次触发的 Trigger,并定制了相应的 SQL 语法来供业务使用。这里我们可以看到虽然是大窗口,但由于数据都在不断地进行增量聚合,所以并不会 hold 住非常大的状态集。

这幅图展示了增量窗口的使用方式,通过新的关键字,底层会映射到我们自实现的触发器。

接下来我们要看的这个特性是我们对 Flink keyBy 的优化,我们称之为:LocalKeyBy。我们在使用 KeyBy 的时候都遇到过数据热点的问题,也就是数据倾斜。数据倾斜主要是业务数据的 key 取值不够离散,而 keyBy 背后是 hash 的 partition 方式,它根据一个 key 的 hash 值来决定数据要落到哪个节点分区。如果发生数据倾斜很容易造成计算资源利用不均以及反压(back pressure)等问题产生。针对这一点,我们在保证计算语义的情况下对 keyBy 进行了优化,开发了 LocalKeyBy 功能。它的原理是通过本地预聚合来减少发送的数据量,但这里需要注意的一点是:使用这个算子的时候,需要对原有的实现代码进行调整,因为它将原来的 keyBy 拆分为了两步:预聚合以及合并。
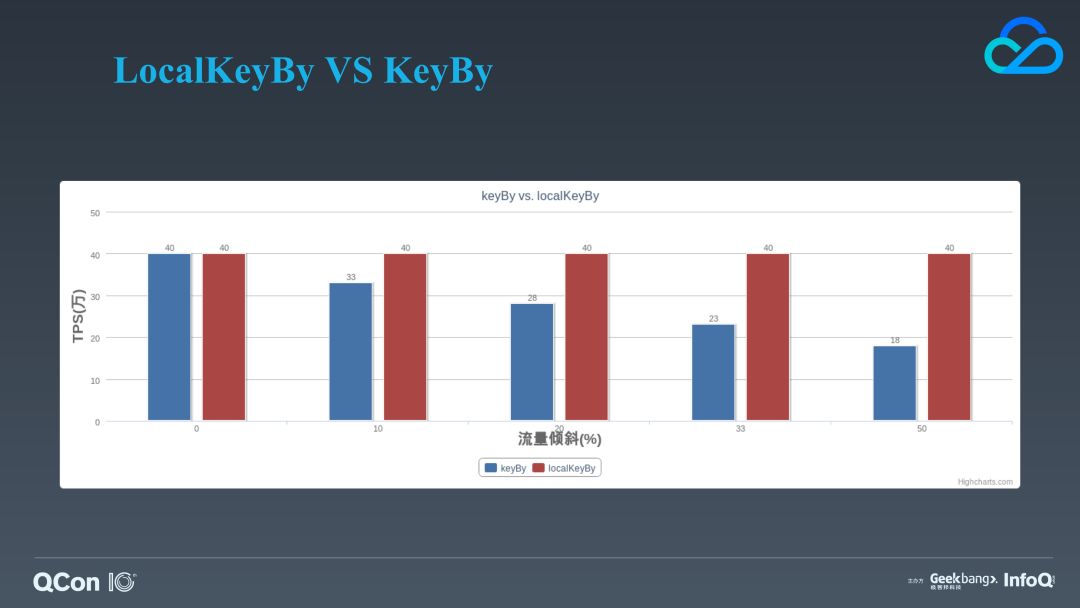
我们在本地对 keyBy 与 LocalKeyBy 做了一个简单的性能对比测试,发现在流量倾斜严重的情况下,使用 LocalKeyBy 整体性能并没有受到太大的影响,但 Flink 原生的 keyBy 则随着流量的倾斜而产生显著的性能下降。
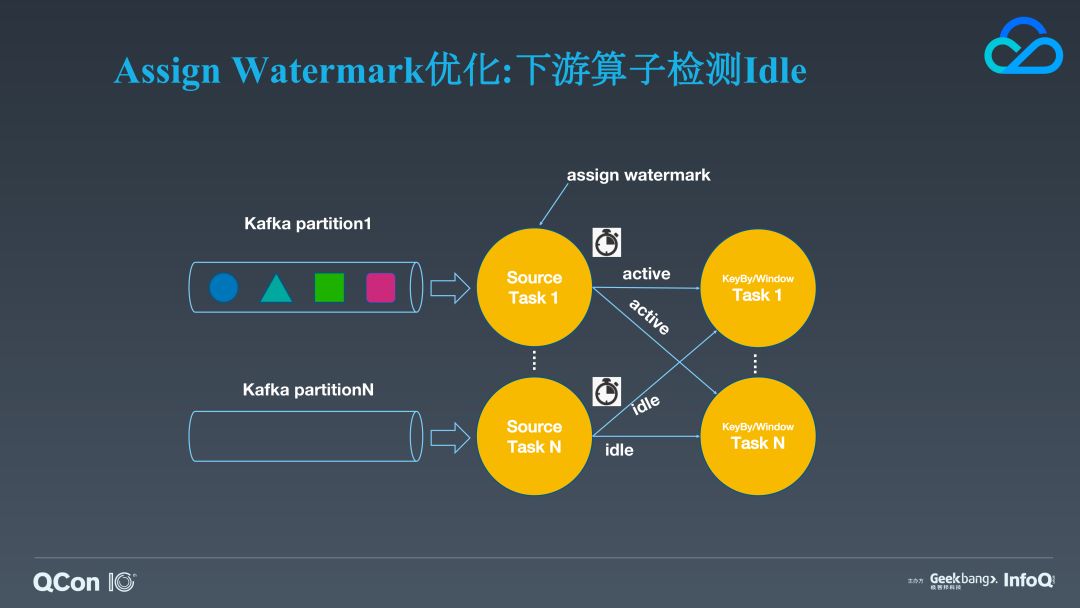
我们继续来看一个特性:水位线算子定时检测流分区空闲的功能。Flink 社区目前针对 Source 实现了定时的流 idle 检测功能(虽然没有开放),它主要针对的场景是 Kafka 某个分区空闲无数据从而造成对应的 subtask 无法正常提取 watermark,导致对下游的计算产生影响。
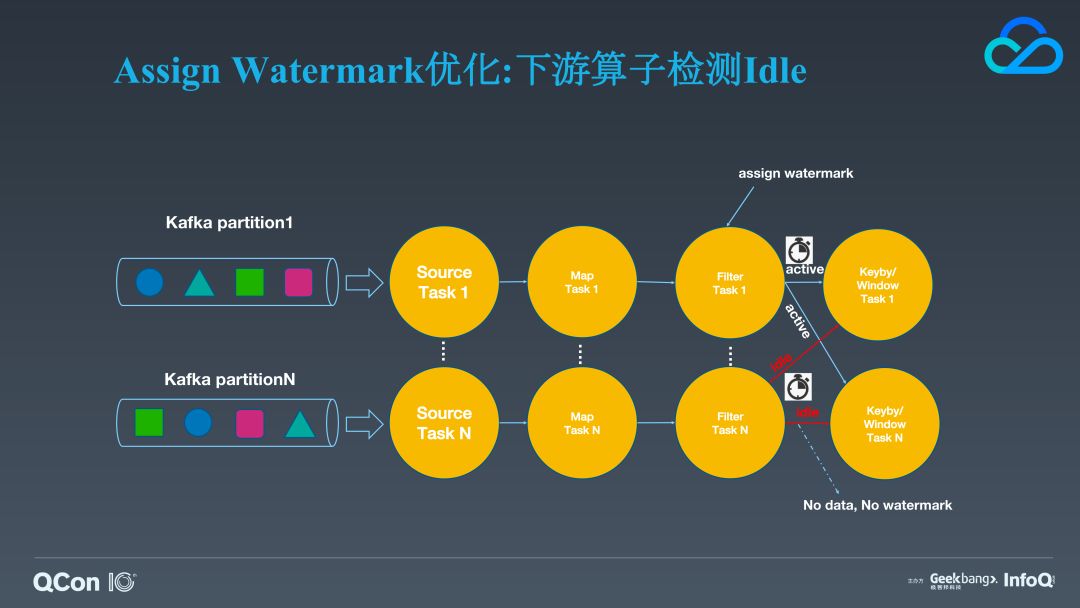
但我们的场景和社区略有差别,我们没有将所有的逻辑都压到 source 里,为了进行逻辑拆分我们引入了一个 transform 算子,它专门针对 ETL 的场景,所以我们的 watermark 很多情况下不在 source 算子上提取,而是在下游的某个算子上,在某些情况下,如果 watermark 的分配算子在 filter 之类的算子后面,则可能造成某个 pipeline 在中间断流,也造成了无法正常提取 watermark 的情形。针对这种场景,我们在提取 watermark 的算子上也实现了定时检测流 idle 的功能。这样就算因为某个分区的数据都被过滤掉造成空闲,也不至于对下游的计算产生影响。
我们介绍的下一个特性是 Framework 与用户业务日志的分离。这个特性其实最受益的是 Standalone 部署模式,因为这种模式下多 job 的 task 是混合部署在同一个 TaskManager 中的,而 TaskManager 本身只使用一个日志文件来记录日志。所以,这导致排查业务问题非常麻烦。另外,我们对 Flink web UI 展示日志文件也做了一些改进,我们会列出 JobManager 以及 TaskManager 的日志文件夹中所有的文件列表。这是因为,随着流应用长时间运行,累积的日志量会越来越大,我们通常都会对应用的日志配置滚动策略,除此之外我们还会输出 GC 日志等,而 Flink 的 web UI 默认只能展示最新的那个日志文件,这对于我们定位问题很不方便。所以,我们引入了一个新的 tab,它能够列出日志文件夹下的文件列表,点击后再请求特定的日志文件。
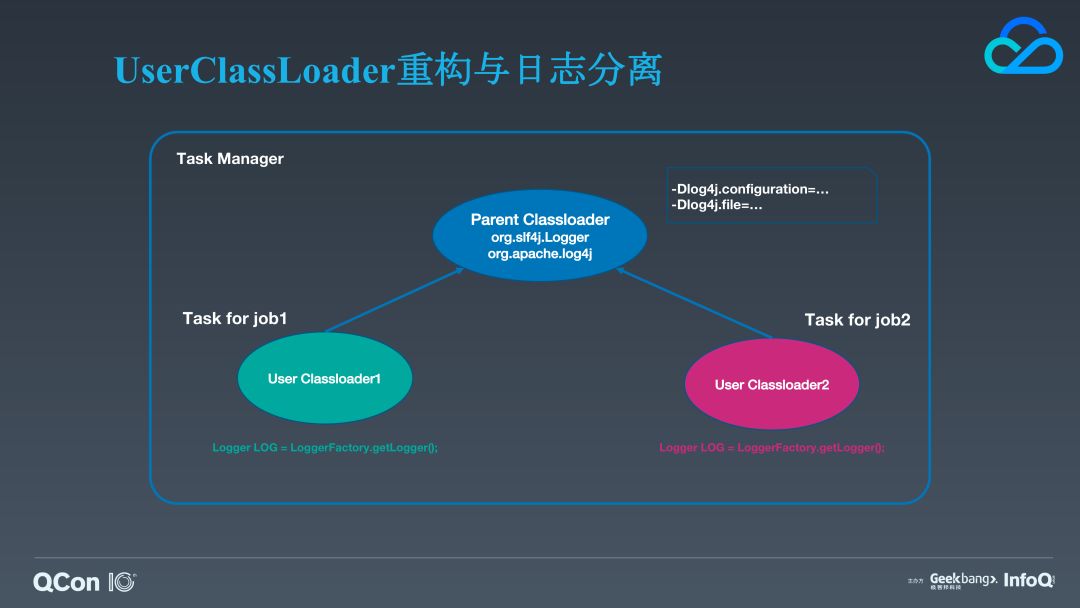
在分析这个特性的实现之前,我们需要先了解 Flink 目前加载日志框架类的方式,它为了避免跟业务 Job 中可能包含的日志框架的依赖、配置文件产生冲突,日志相关类的加载都代理给平台的类加载器,也就是 TaskManager 的类加载器,而 TaskManager 本身加载的这些类都是从 Flink 安装包的 lib 底下加载的。而关于日志配置文件,Flink 通过 JVM 启动参数来指定配置文件路径以及日志文件路径。这些机制共同保证了 Flink 不会受到用户 job jar 的干扰。
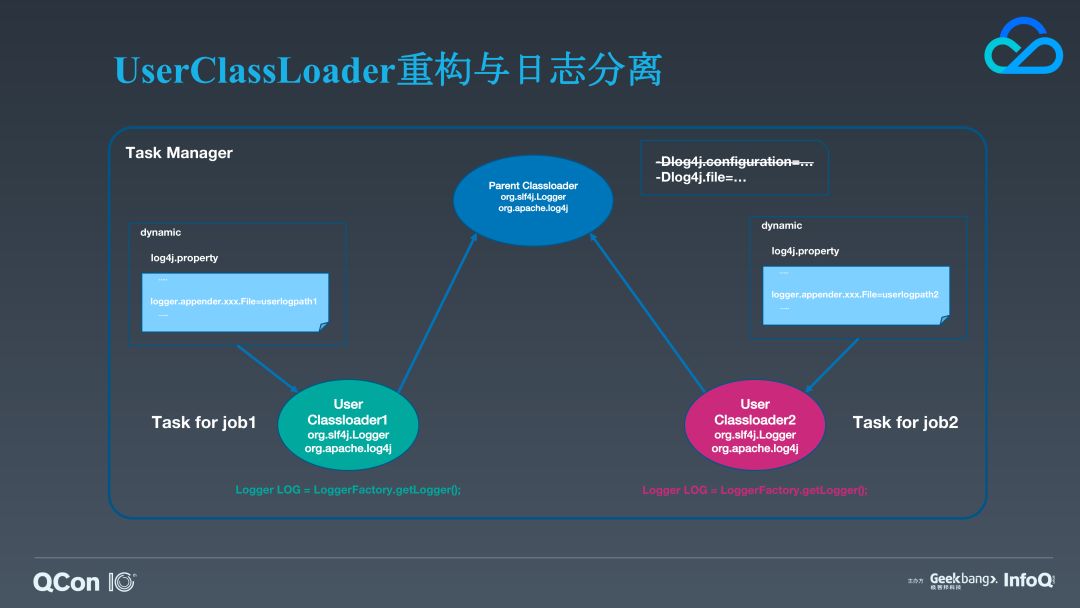
所以,如果我们要实现日志分离,我们就需要打破 Flink 原先的实现机制,关键点在于:为不同 Job 的 Task 加载不同的日志类;为不同 Job 的 Task 指定不同的配置文件以及用户日志文件的路径。这意味着我们需要定制 Flink 自带的 user classloader。针对第一点,我们不再将这些日志类的加载代理给平台的加载器,而是将平台类加载器中日志相关的 jar 的 classpath 加入到各个 task 自己的 classloader 中。
关于配置文件,我们显然也不能用 Flink 平台的配置文件。我们会拿平台使用的配置文件作为模板,对其内部的日志路径进行动态修改,然后将内存中的这个配置文件传递给特定的日志框架。那么这里就有一个问题,内存中的配置文件二进制数据怎么被日志框架读取。log4j 以及 logback 都可以接收配置文件的 URL 表示,而 URL 也可以接收一个 URLStreamHandler 的实现(它是所有流协议的处理器用于连接二进制的数据流与 URL),通过效仿 bytebuddy(一个动态修改 Java 二进制字节码的类库),我们实现了 ByteArrayUrlStreamHandler 来进行二进制的配置文件跟 URL 之间的衔接,这两点完成后不同 Job 的 Task 的类加载器就保证了日志类加载和配置的完全独立性。
QCon 全球软件开发大会广州站刚刚结束,我们为 InfoQ 的读者汇总了大会 PPT,回复关键词:PPT,即可下载!
若您只需要本篇演讲 PPT,可回复关键词:Flink,即可下载。
点个在看少个 bug 以上是关于日均20万亿次计算量!腾讯基于Flink的实时流计算平台演进之路丨附PPT下载的主要内容,如果未能解决你的问题,请参考以下文章 腾讯看点基于 Flink 构建万亿数据量下的实时数仓及实时查询系统 日均请求量1.6万亿次背后,DNSPod的秘密-国密DoH篇 日均请求量1.6万亿次背后,DNSPod的秘密-国密DoH篇