Spark vs. Flink -- 核心技术点
Posted 互联网全栈架构
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark vs. Flink -- 核心技术点相关的知识,希望对你有一定的参考价值。
前言
Apache Spark 是一个统一的、快速的分布式计算引擎,能够同时支持批处理与流计算,充分利用内存做并行计算,官方给出Spark内存计算的速度比MapReduce快100倍。因此可以说作为当下最流行的计算框架,Spark已经足够优秀了。
Apache Flink 是一个分布式大数据计算引擎,能够提供基于数据流的有状态计算,被定义为下一代大数据处理引擎,发展十分迅速并且在行业内已有很多最佳实践。
两者都是优秀的框架,究竟有何不同,Spark还没学好现在又来了一个Flink,程序猿攻城狮们能接住招吗!本文主要从部分功能上聊一聊这两款大数据处理引擎。
编程模型
Spark 可以说是一站式的分布式计算引擎,能够支持批处理、流计算、机器学习以及图计算。
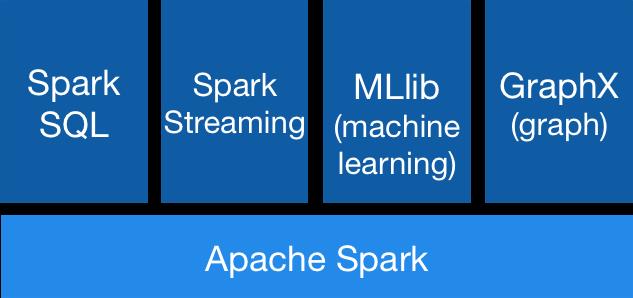
Spark Core:Spark核心模型,底层的高级抽象 RDD 称为弹性分布式数据集,具有高容错性,是并行计算的基石。
Spark SQL:Spark提供了Spark SQL模块用于处理结构化数据,支持交互式SQL、DataFrame API以及多种语言支持。
Spark Streaming:可扩展、容错的流计算框架,基于微批(micro batch)处理的模式,Spark2.0 引入了Structured Streaming进一步定义了流计算诸多方面的语义。
MLlib:原生支持的机器学习库,支持主流的统计与机器学习算法。
GraphX:Spark提供的分布式图计算框架,能够处理复杂的业务场景比如社交关系、金融担保等。
Flink与Spark类似,同样提供了多种编程模型,从流计算到批处理,再到结构化数据处理以及机器学习、图计算等。
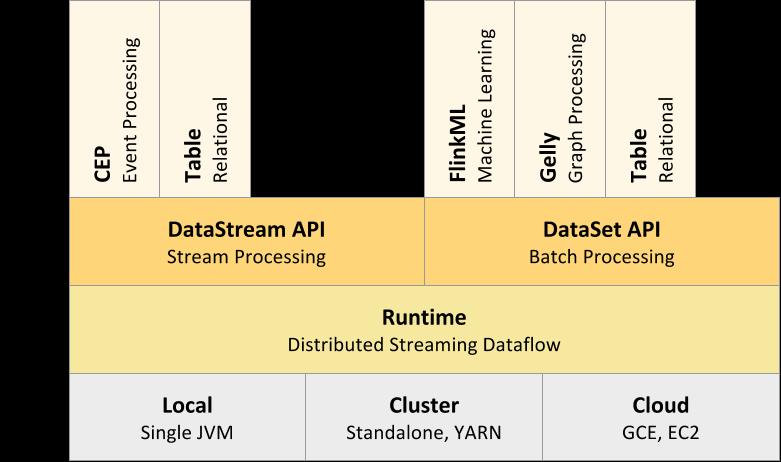
DataStream API / DataSet API:这是Flink核心的编程模型,这两套API分别面向流处理与批处理,是构建在有状态流处理以及Runtime之上的高级抽象,供大部分业务逻辑处理使用。
Table API & SQL :Table API & SQL是以DataStream API 和 DataSet API为基础面向结构化数据处理的高级抽象,提供类似于关系型数据库的Table和SQL查询功能,能够简单方便的操作数据流。
CEP:是DataStream API / DataSet API的另一个高级抽象,是一个面向复杂事件处理的库。
FlinkML:Flink机器学习库,批处理API的高级封装,提供可扩展的ML算法、直观的API和工具。
Gelly:Flink图计算的库,也是在批处理API基础上做的一层封装,提供了创建、转换和修改图的方法以及图算法库。
流处理方面对比
Flink更多的是作为一个流处理引擎,而Spark在流处理方面支持Spark Streaming和Structured Streaming(2.x),下面主要从流处理机制、状态管理、时间语义、Exactly-Once语义等几方面阐述两者的差异。
流处理机制
Spark Streaming流处理的机制是将源源不断的流式数据按照一定时间间隔,分隔成一个一个小的batch批次,然后经过Spark引擎处理后输出到外部系统。实际上是微批操作,因此上述的时间间隔称为Batch Duration,即批处理时间间隔。Spark Streaming这种把流当作一种批的设计思想具有非常高的吞吐量,但避免不了较高的延时,因此Spark Streaming的场景也受到了限制,实时性要求非常高的场景不适合使用Spark Streaming。
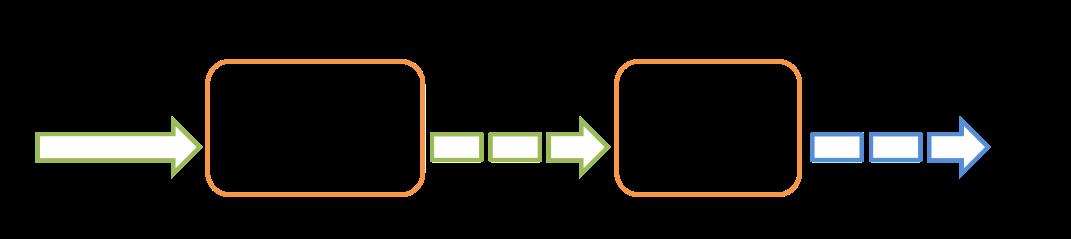
Flink本质上就是一个流处理引擎,基于消息事件驱动,并引入了状态管理,因此能够对数据流进行有状态的(Stateful)计算。Flink的设计思想是把批当作一种有限的流,这样在流处理过程中也能够发挥批处理的特性,实现了批流一批化。
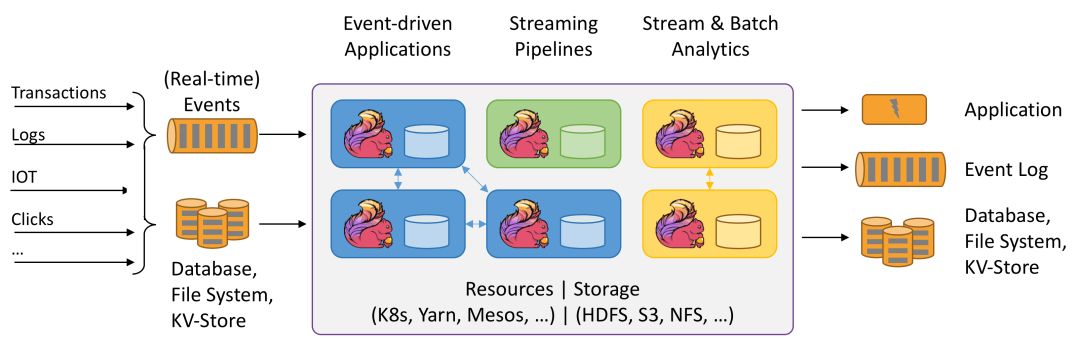
状态管理
Spark Streaming支持两种状态管理操作 updateStateByKey 与 mapWithState,分别用来满足类似全量与增量的操作。而在Structured Streaming中有支持用户自定义的mapGroupsWithState和flatMapGroupsWithState状态操作。
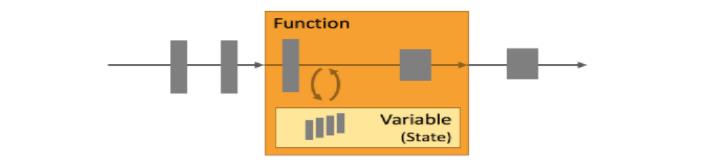
Flink设计之初就引入了状态管理,其最突出的表现也是能够进行有状态处理 (Stateful Processing),示意图如下:
时间语义
Spark Streaming只支持处理时间,到了Structured Streaming 模型中同时支持处理时间和事件时间。
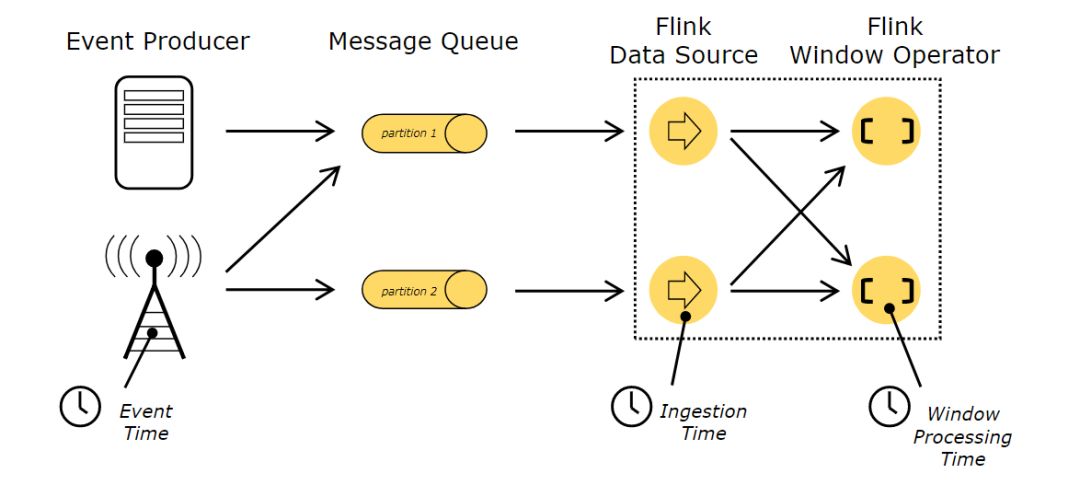
Flink中时间和状态是流应用中的两大元素,Flink支持三种时间语义,含义与示图如下:
事件时间(Event Time):是数据产生或消息创建的时间;
接入时间(Ingestion Time):是数据或消息进入Flink计算引擎的时间;
处理时间(Processing Time):是数据被Flink计算引擎处理的时间。
Exactly-Once语义
在容错性方面,Spark Streaming能够保证 At-most-Once 或 At-least-Once 这种至多或至少一次的处理语义,基本上保证不了 Exactly-Once 这种严格一次的处理语义。通常是只实现 At-least-Once 的处理,保证数据不丢失,但是不能保证数据不会被重复处理,因此要求输出端能够支持幂等操作或者更新操作。
Flink能够保证 Exactly-Once 状态一致性的语义,整体上是通过checkpoint机制和两阶段提交协议(two-phase commit)实现的。
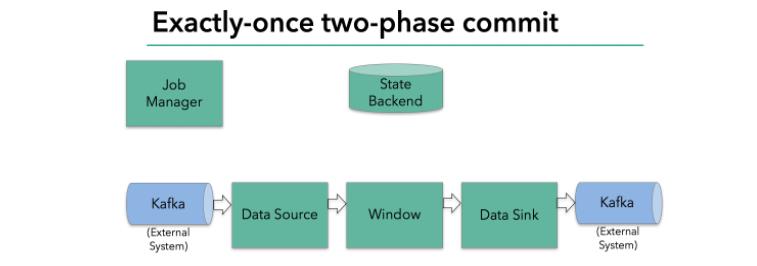
具体实现思路可以参考 https://flink.apache.org/features/2018/03/01/end-to-end-exactly-once-apache-flink.html
总结
总的来说,Spark是一个通用的、快速的大数据处理引擎,集批处理、流处理、机器学习与图计算等于一身,基于内存的迭代计算更加高效,目前也在不断增强包括流处理在内的能力。Flink更多的是一个流计算引擎,但又不仅仅是流计算,其实有着和Spark相似的计算模型,特别是流计算的诸多方面要优于Spark。

2.
3.
4
5
6
7
8
10

扫码二维码关注我
·end·
我们一起愉快的玩耍!
以上是关于Spark vs. Flink -- 核心技术点的主要内容,如果未能解决你的问题,请参考以下文章