Flink 在快手实时多维分析场景的应用
Posted Flink 中文社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flink 在快手实时多维分析场景的应用相关的知识,希望对你有一定的参考价值。
摘要:作为短视频分享跟直播的平台,快手有诸多业务场景应用了 Flink,包括短视频、直播的质量监控、用户增长分析、实时数据处理、直播 CDN 调度等。此次主要介绍在快手使用 Flink 在实时多维分析场景的应用与优化。主要内容包括:
-
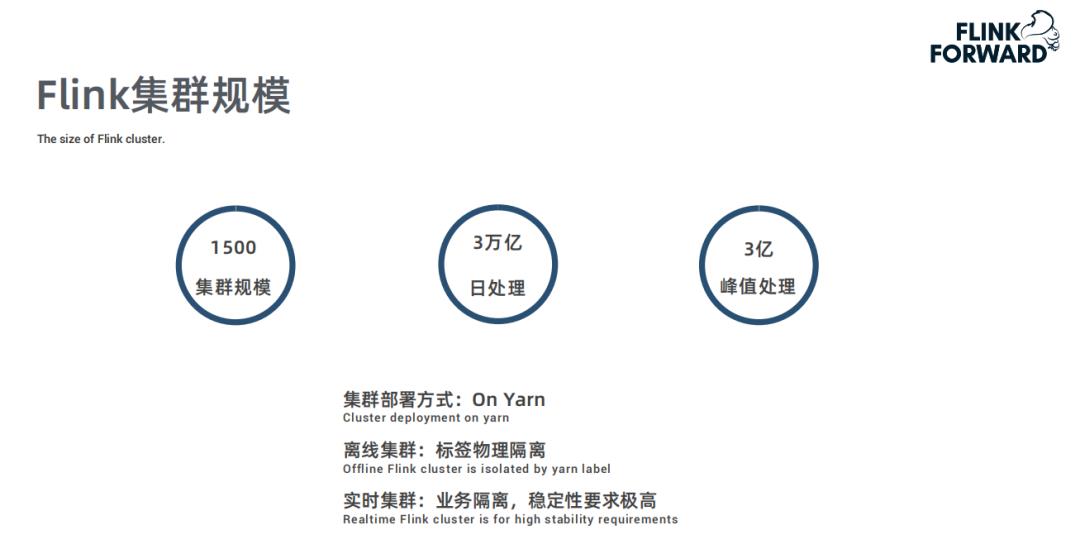
Flink 在快手应用场景及规模 -
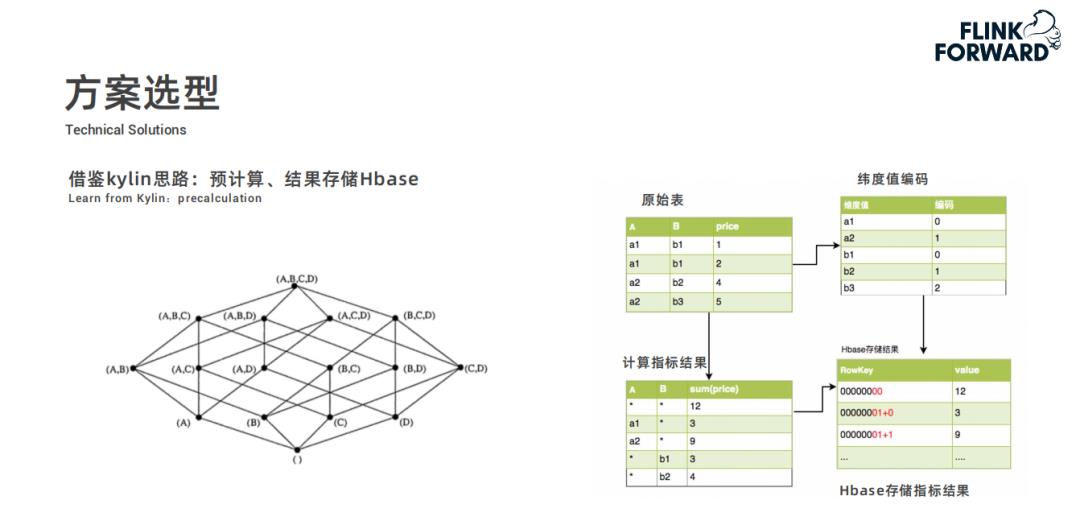
快手实时多维分析平台 -
SlimBase-更省 IO、嵌入式共享 state 存储
Flink 在快手应用场景及规模

-
80% 统计监控 :实时统计,包括各项数据的指标,监控项报警,用于辅助业务进行实时分析和监控; -
15% 数据处理 :对数据的清洗、拆分、Join 等逻辑处理,例如大 Topic 的数据拆分、清洗; -
5% 数据处理 :实时业务处理,针对特定业务逻辑的实时处理,例如实时调度。

-
快手是分享短视频跟直播的平台,快手短视频、直播的质量监控是通过 Flink 进行实时统计,比如直播观众端、主播端的播放量、卡顿率、开播失败率等跟直播质量相关的多种监控指标; -
用户增长分析 ,实时统计各投放渠道拉新情况,根据效果实时调整各渠道的投放量; -
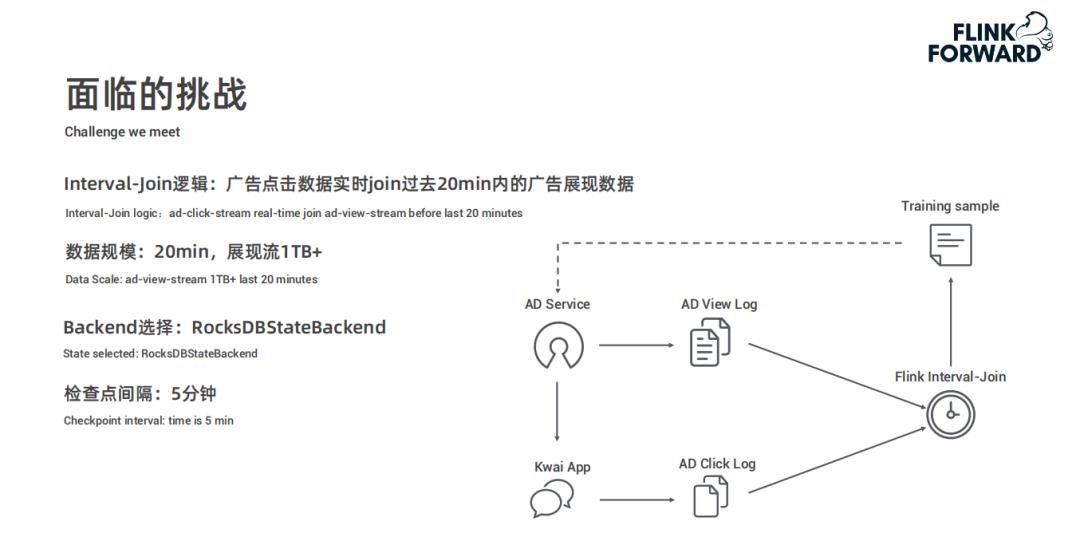
实时数据处理 ,广告展现流、点击流实时 Join,客户端日志的拆分等; -
直播 CDN 调度 ,实时监控各 CDN 厂商质量,通过 Flink 实时训练调整各个 CDN 厂商流量配比。
快手实时多维分析平台

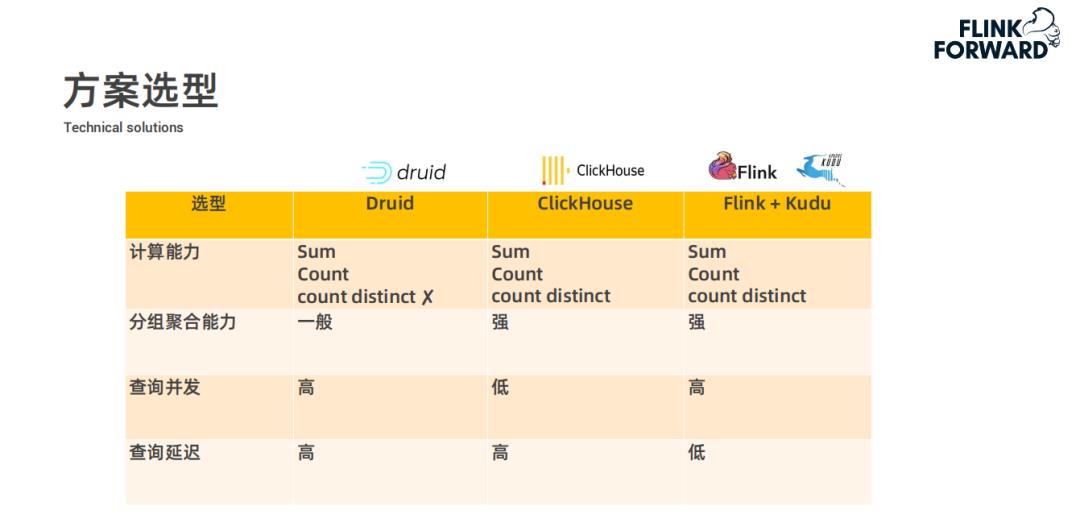
-
计算能力方面 :多维查询这种业务场景需要支持 Sum、Count 和 count distinct 等能力,而 Druid 社区版本不支持 count distinct,快手内部版本支持数值类型、但不支持字符类型的 count distinct;ClickHouse 本身全都支持这些计算能力;Flink 是一个实时计算引擎,这些能力也都具备。 -
分组聚合能力方面 :Druid 的分组聚合能力一般,ClickHouse 和 Flink 都支持较强的分组聚合能力。 -
查询并发方面 :ClickHouse 的索引比较弱,不能支持较高的查询并发,Druid 和 Flink 都支持较高的并发度,存储系统 Kudu,它也支持强索引以及很高的并发。 -
查询延迟方面 :Druid 和 ClickHouse 都是在查询时进行现计算,而 Flink+Kudu 方案,通过 Flink 实时计算后将指标结果直接存储到 Kudu 中,查询直接从 Kudu 中查询结果而不需要进行计算,所以查询延迟比较低。
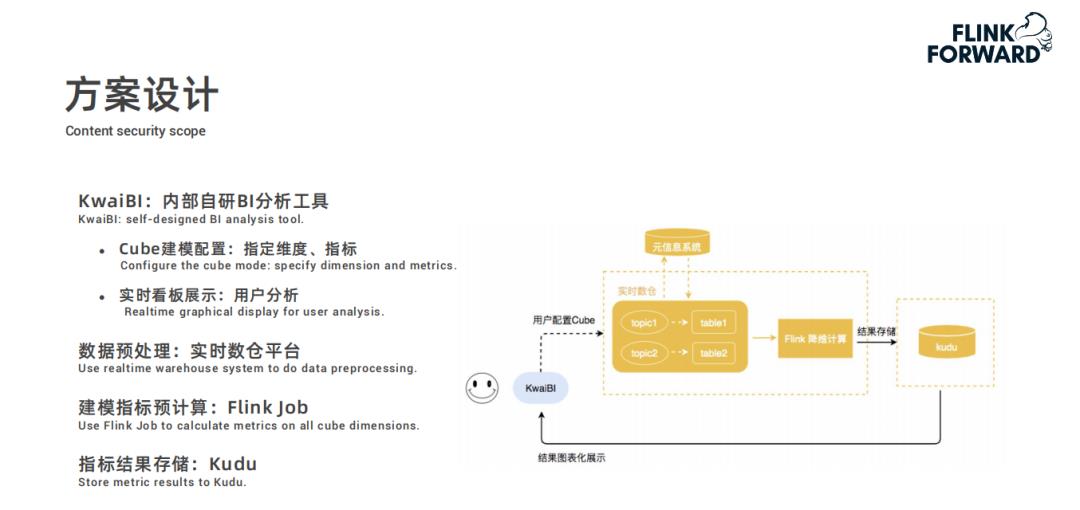
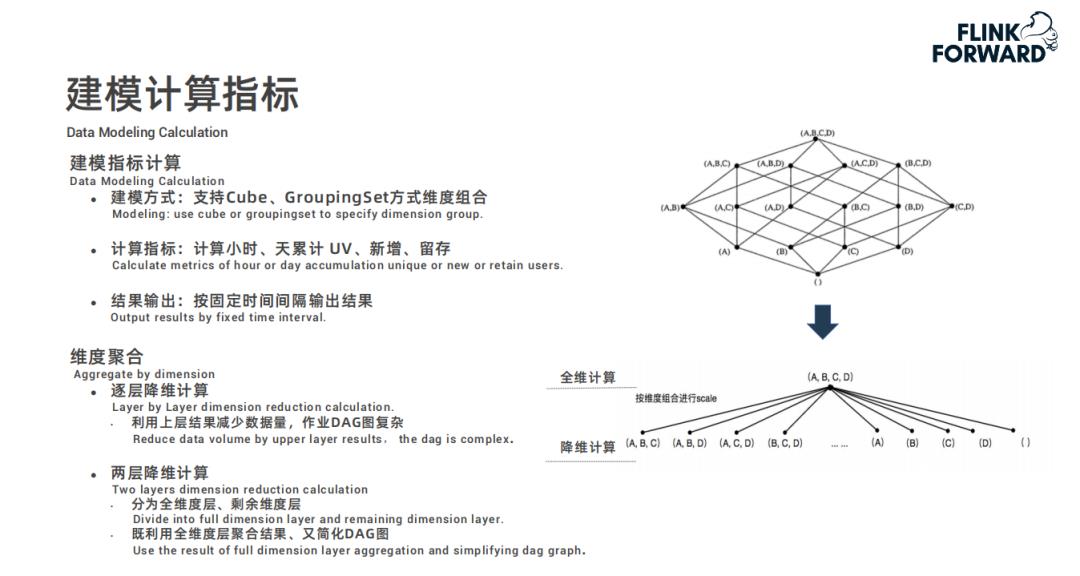
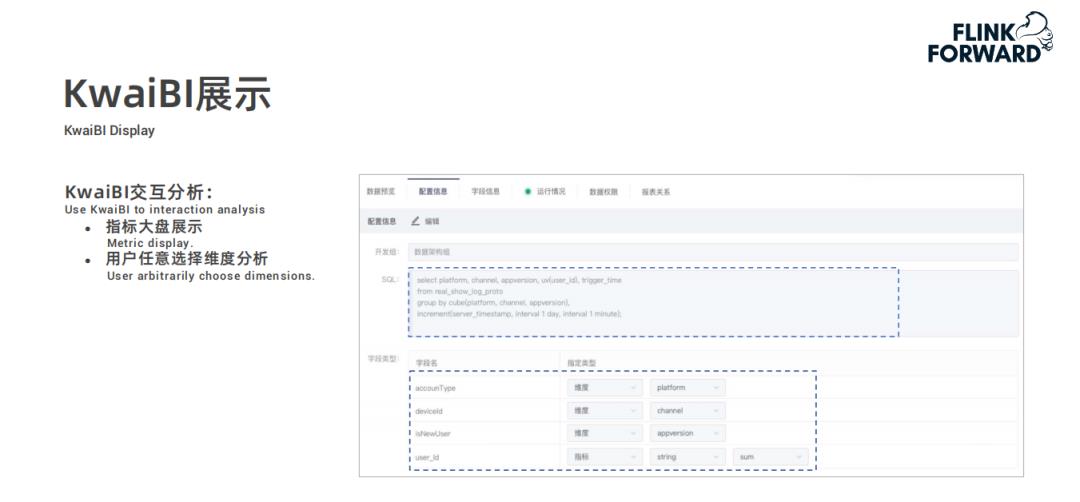
用户在快手自研的 BI 分析工具 KwaiBI 上配置 Cube 数据立方体模型,指定维度列和指标列以及基于指标做什么样的计算;
配置过程中选择的数据表是经过处理过后存储在实时数仓平台中的数据表;
然后根据配置的计算规则通过 Flink 任务进行建模指标的预计算,结果存储到 Kudu 中;
最后 KwaiBI 从 Kudu 中查询数据进行实时看板展示。
-
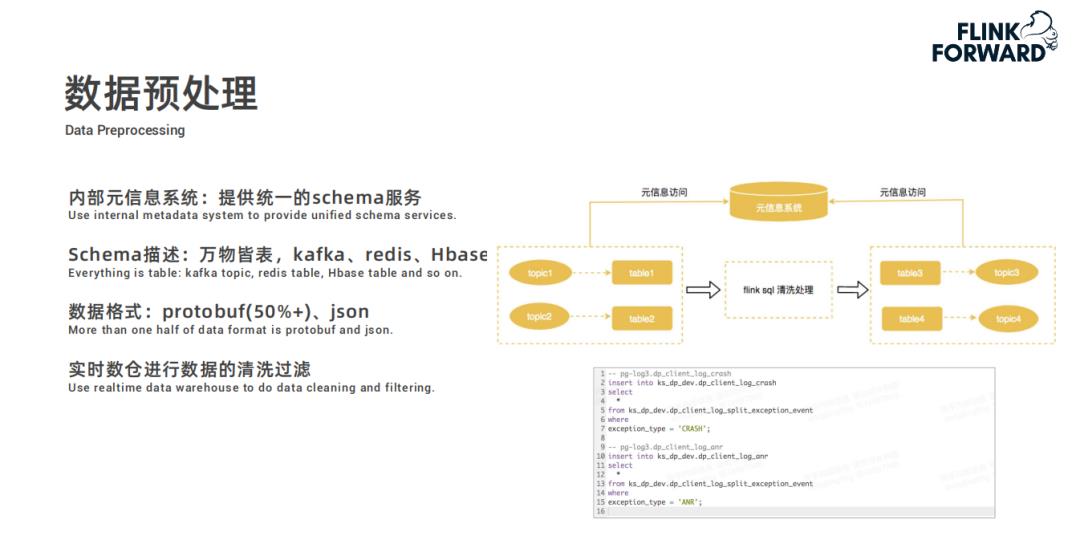
首先内部有一个元信息系统,在元信息系统中提供统一的 schema 服务,所有的信息都被抽象为逻辑表; -
例如 Kafka 的 topic、Redis、Hbase 表等元数据信息都抽取成 schema 存储起来; -
快手 Kafka 的物理数据格式大部分是 Protobuf 和 Json 格式,schema 服务平台也支持将其映射为逻辑表; -
用户只需要将逻辑表建好之后,就可以在实时数仓对数据进行清洗和过滤。
-
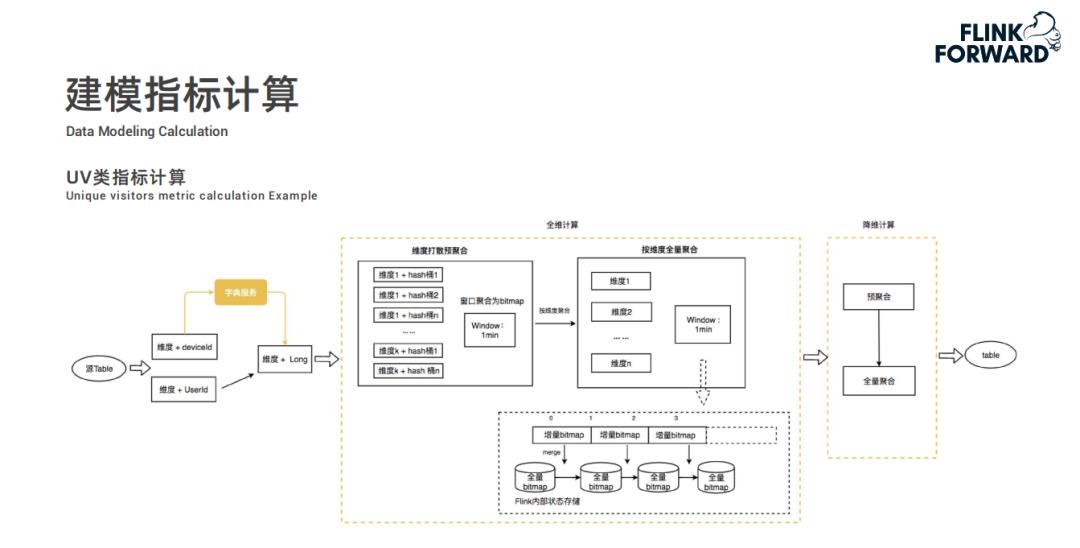
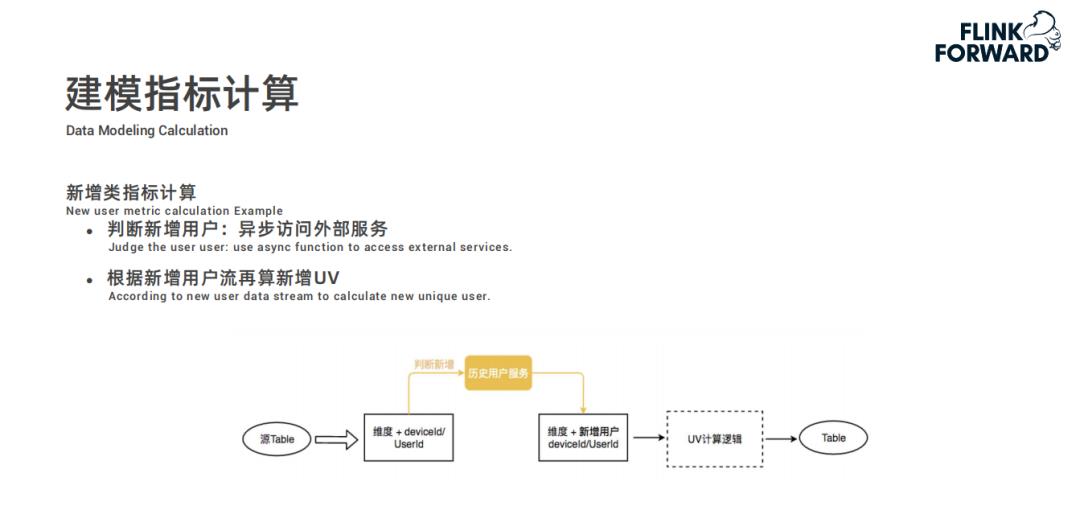
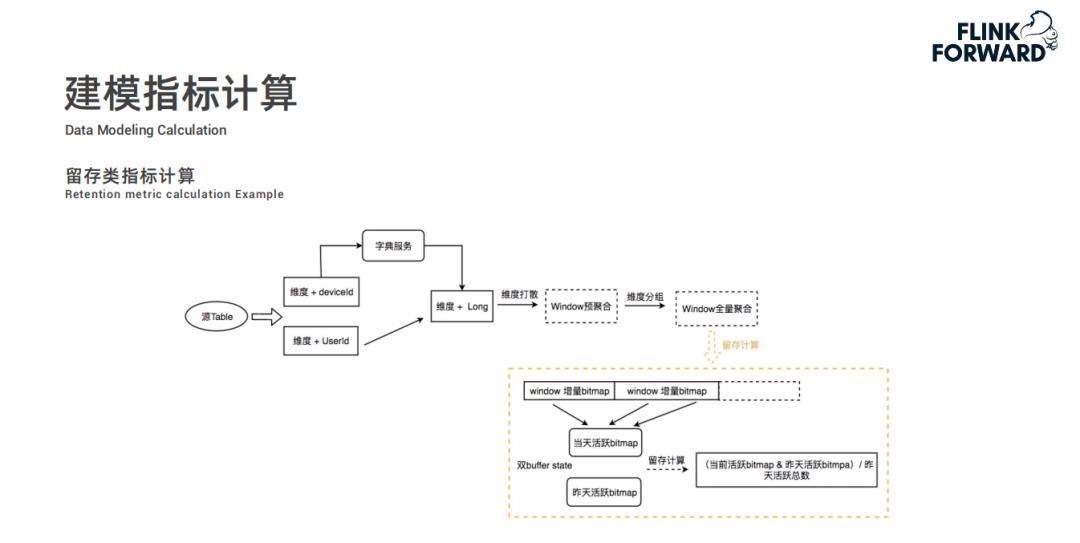
全维计算分为两个步骤,为避免数据倾斜问题,首先是维度打散预聚合,将相同的维度值先哈希打散一下。因为 UV 指标需要做到精确去重,所以采用 Bitmap 进行去重操作,每分钟一个窗口计算出增量窗口内数据的 Bitmap 发送给第二步按维度全量聚合;在全量聚合中,将增量的 Bitmap 合并到全量 Bitmap 中最终得出准确的 UV 值。然而有人会有问题,针对用户 id 这种的数值类型的可以采用此种方案,但是对于 deviceid 这种字符类型的数据应该如何处理?实际上在源头,数据进行维度聚合之前,会通过字典服务将字符类型的变量转换为唯一的 Long 类型值,进而通过 Bitmap 进行去重计算 UV。 -
降维计算中,通过全维计算得出的结果进行预聚合然后进行全量聚合,最终将结果进行输出。


SlimBase-更省 IO、嵌入式共享 state 存储

-
首先,在 Checkpoint 期间会产生四倍的大规模数据拷贝,即:从 RocksDB 中全量读取出来然后以三副本形式写入到 HDFS 中; -
其次,对于大规模数据写入,RocksDB 的默认 Level Compaction 会有严重的 IO 放大开销。

-
共享存储方面,HBase 支持, RocksDB 不支持 -
SizeTieredCompation 方面,RocksDB 默认不支持,HBase 默认支持 -
基于事件时间下推的 FIFOCompaction 方面,RocksDB 不支持,但 HBase 开发起来比较简单 -
技术栈方面,RocksDB 使用 C++,HBase 使用 java,HBase 改造起来更方便
-
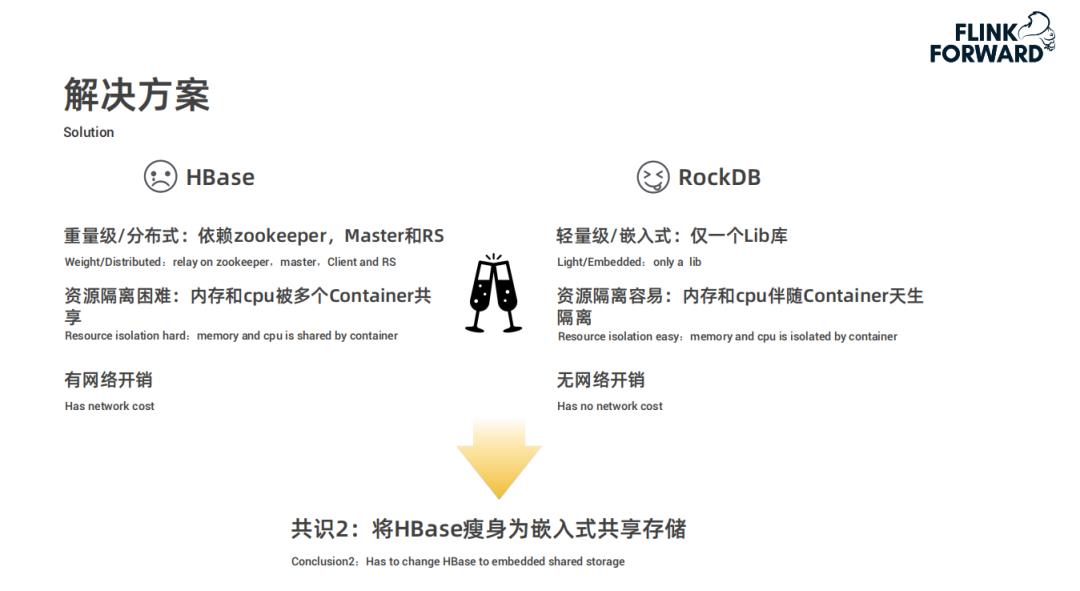
HBase 是一个依赖 zookeeper、包含 Master 和 RegionServer 的重量级分布式系统;而 RocksDB 仅是一个嵌入式的 Lib 库,很轻量级。 -
在资源隔离方面,HBase 比较困难,内存和 cpu 被多个 Container 共享;而 RocksDB 比较容易,内存和 cpu 伴随 Container 天生隔离。 -
网络开销方面,因为 HBase 是分布式的,所有比嵌入式的 RocksDB 开销要大很多。

-
一层是 SlimBase 本身,包含三层结构:Slim HBase、适配器以及接口层; -
另一层是 SlimBaseStateBackend,主要包含 ListState、MapState、ValueState 和 ReduceState。

-
先对 HBase 进行减裁,去除 client、zookeeper 和 master,仅保留 RegionServer -
再对 RegionServer 进行剪裁,去除 ZK Listener、Master Tracker、Rpc、WAL 和 MetaTable -
仅保留 RegionServer 中的 Cache、Memstore、Compaction、Fluster 和 Fs
-
将原来 Master 上用于清理 Hfile 的 HFileCleaner 迁移到 RegionServer 上 -
RocksDB 支持读放大写的 merge 接口,但是 SlimBase 是不支持的,所以要实现 merge 的接口
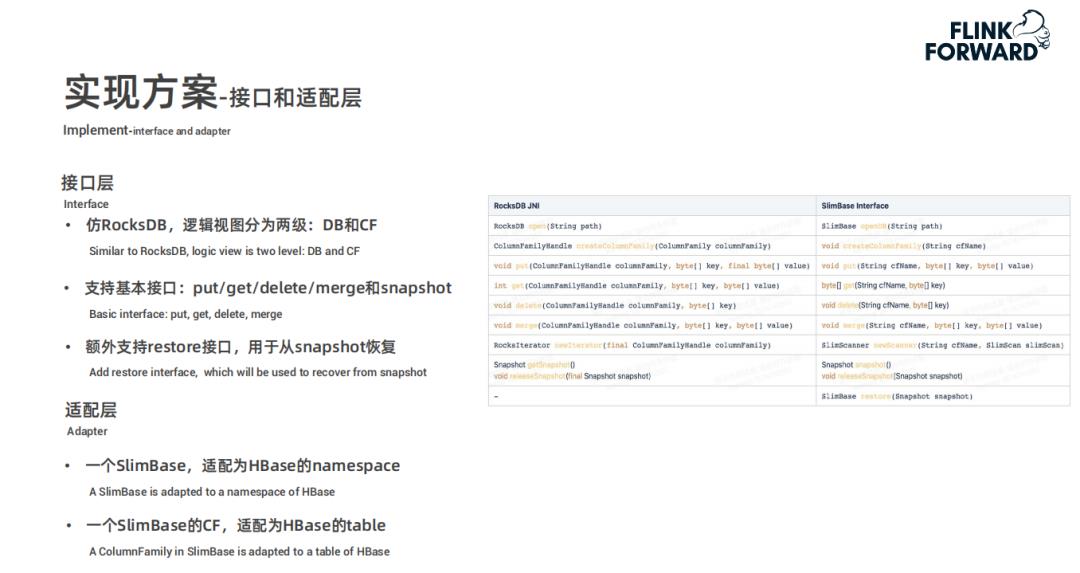
-
仿照 RocksDB,逻辑视图分为两级:DB 和 ColumnFamily -
支持一些基本的接口:put/get/delete/merge 和 snapshot -
额外支持了 restore 接口,用于从 snapshot 中恢复
-
一个 SlimBase 适配为 Hbase 的 namespace -
一个 SlimBase 的 ColumnFamily 适配为 HBase 的 table

-
一是多种 States 实现,支持多种数据结构,ListState、MapState、ValueState 和 ReduceState -
二是改造 Snapshot 和 Restore 的流程,从下面的两幅图可以看出,SlimBase 在磁盘 IO 上节省了大量的资源,避免了多次的 IO 的问题。
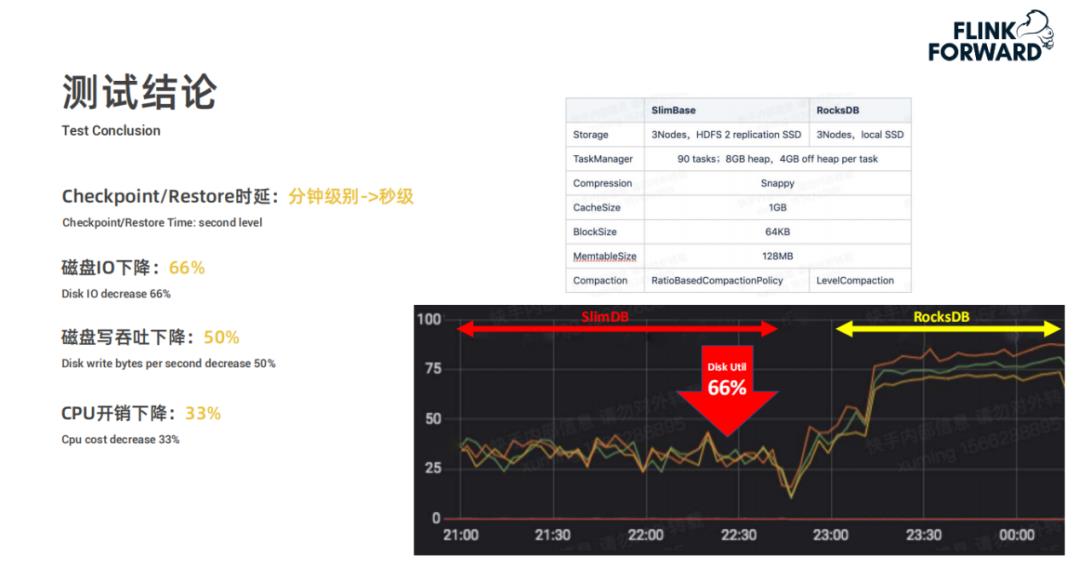
-
Checkpoint 和 Restore 的时延从分钟级别降到秒级。 -
磁盘 IO 下降了66% -
磁盘写吞吐下降50% -
CPU 开销下降了33%


-
SlimBase 使用 InMemoryCompaction,降低内存 Flush 和 Compaction 开销 -
SlimBase 支持 prefixBloomFilter,提高 Scan 性能 -
SlimBase 支持短路读 -
HDFS 副本落盘改造:非本地副本使用 DirectIO 直接落盘,提高本地读 pagecache 命中率;此条主要是在测试使用时发现单副本比多副本读写效率高这一问题
 春晚活动下快手实时链路保障实践
春晚活动下快手实时链路保障实践
▼ 活动亮点 ▼
> 超豪华嘉宾阵容!多位资深技术专家在线分享对行业趋势的洞察!
> 极丰富干货分享!集结大数据热门议题,一次看完:数据处理、数仓、数据湖、AI 等技术实践与生产应用落地。
> 多种奖品拿到手软!直播间已准备超多精美礼品,现场送送送!预约直播并参与互动即有机会领走哦。
以上是关于Flink 在快手实时多维分析场景的应用的主要内容,如果未能解决你的问题,请参考以下文章