实战项目——Hadoop生态圈之动物管理员Zookeeper安装与实现
Posted ItStar
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了实战项目——Hadoop生态圈之动物管理员Zookeeper安装与实现相关的知识,希望对你有一定的参考价值。
本文分别从:单机版zookeeper-3.4.10、连接到单机zookeeper和集群版zookeeper-3.4.10三方面加以阐述。
1、 进入”conf”目录,复制“zoo_sample.cfg”,创建另一个文件”zoo.cfg”:[root@master conf]# cp zoo_sample.cfg zoo.cfg 如图所示:
2、 修改配置文件”zoo.cfg”:[root@master conf]# vi zoo.cfg 如图所示: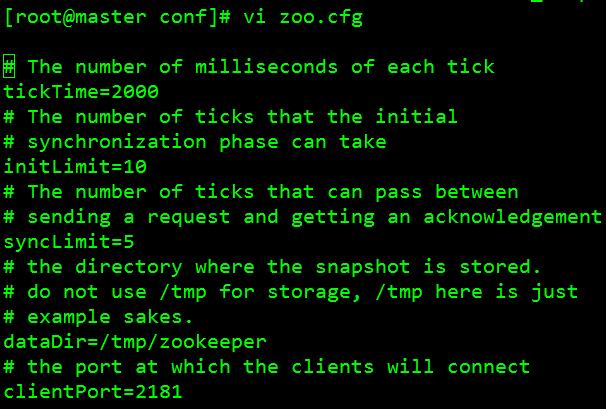 3、 修改内容如下:
3、 修改内容如下:
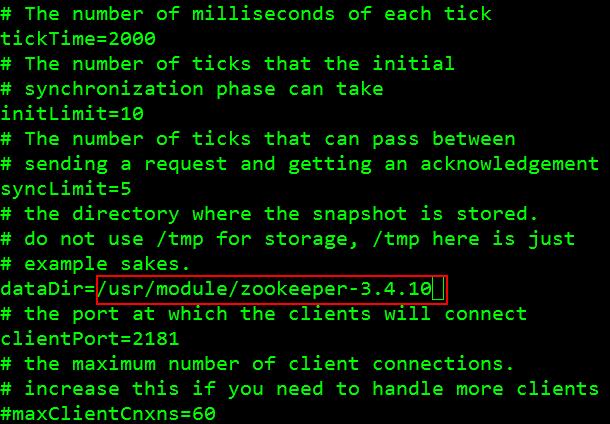 “dataDir=/usr/module/zookeeper-3.4.10”:存储快照的目录4、保存退出5、启动zookeeper单节点:[root@master zookeeper-3.4.10]# bin/zkServer.sh start 如图:
“dataDir=/usr/module/zookeeper-3.4.10”:存储快照的目录4、保存退出5、启动zookeeper单节点:[root@master zookeeper-3.4.10]# bin/zkServer.sh start 如图:
 6、 检查进程:[root@master zookeeper-3.4.10]# jps 如图:
6、 检查进程:[root@master zookeeper-3.4.10]# jps 如图:
 7、 检查模式:[root@master zookeeper-3.4.10]# bin/zkServer.sh status 如图:
7、 检查模式:[root@master zookeeper-3.4.10]# bin/zkServer.sh status 如图:
 说明:单机模式,节点启动成功!
说明:单机模式,节点启动成功!
8、 关闭zookeeper进程:[root@master zookeeper-3.4.10]# bin/zkServer.sh stop 如图:
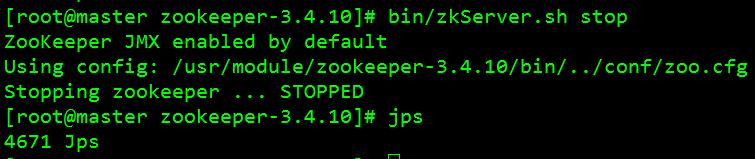 关闭成功!
关闭成功!
首先,要启动zookeeper进程:[root@master zookeeper-3.4.10]# bin/zkServer.sh start[root@master zookeeper-3.4.10]# bin/zkCli.sh -server 127.0.0.1:2181通过上述命令,可以看到如下结果:
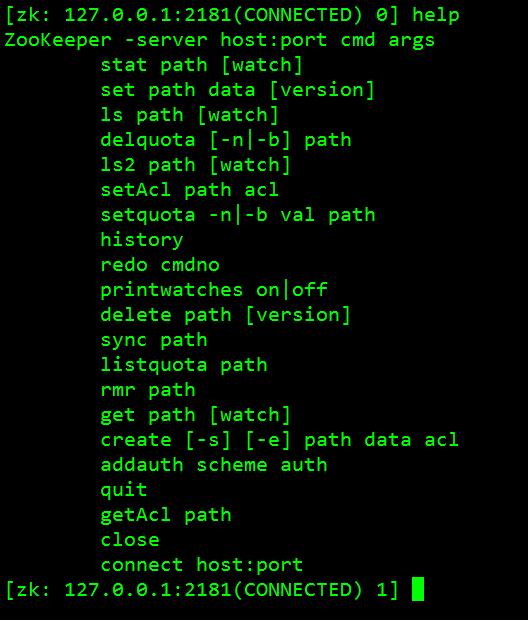
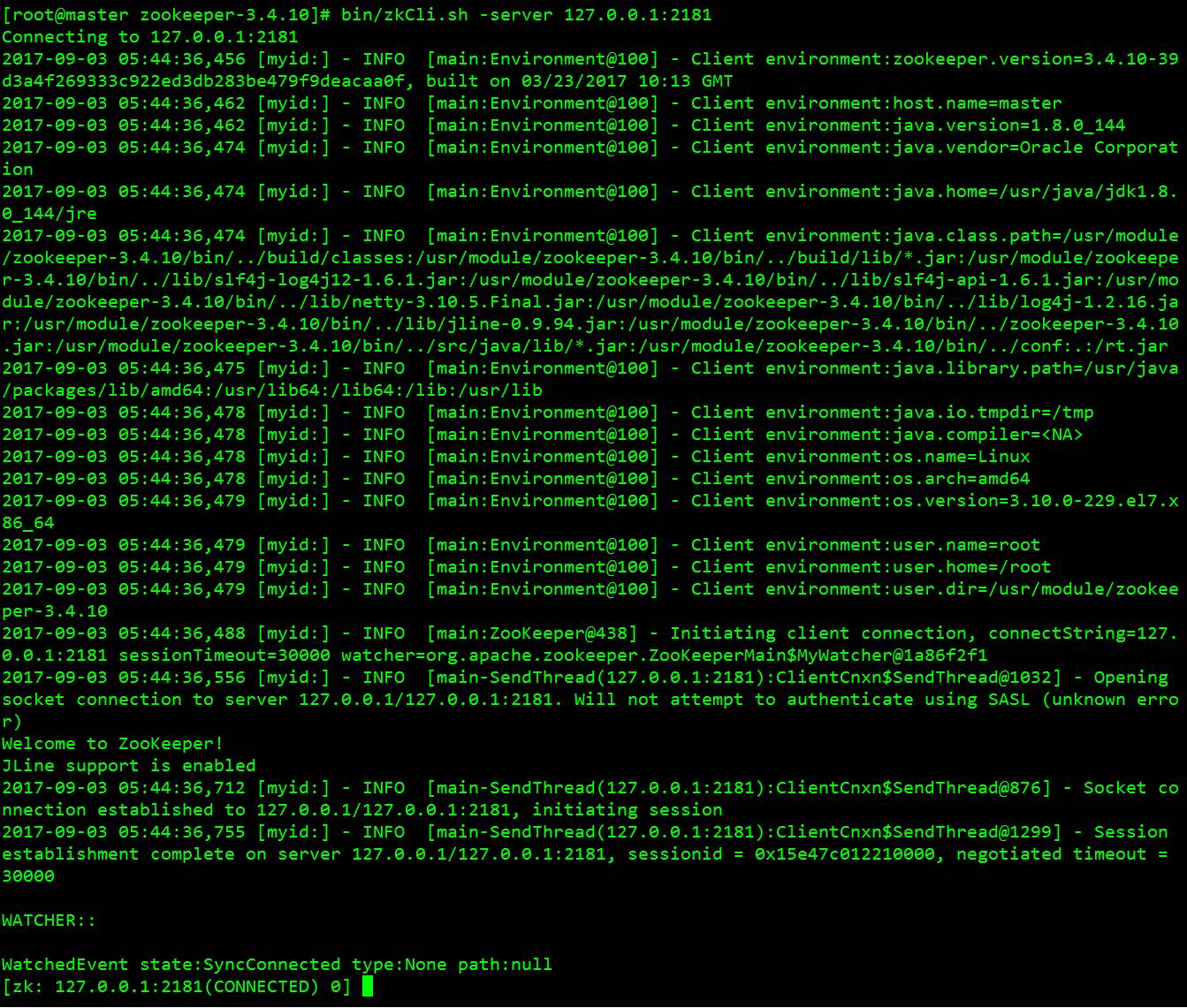 这样你就可以进行简单的文件类操作了!感受一下新的命令行界面吧!1、 zookeeper的列表命令:[zk: 127.0.0.1:2181(CONNECTED) 0] help 如图:
这样你就可以进行简单的文件类操作了!感受一下新的命令行界面吧!1、 zookeeper的列表命令:[zk: 127.0.0.1:2181(CONNECTED) 0] help 如图:
 2、 查看一下已存在的Znode:[zk: 127.0.0.1:2181(CONNECTED) 1] ls / 如图:
2、 查看一下已存在的Znode:[zk: 127.0.0.1:2181(CONNECTED) 1] ls / 如图:
 3、 创建一个新的Znode:”zk_test”,并且把数据”my_data”关联进去:[zk: 127.0.0.1:2181(CONNECTED) 2] create /zk_test my_data 如图:
3、 创建一个新的Znode:”zk_test”,并且把数据”my_data”关联进去:[zk: 127.0.0.1:2181(CONNECTED) 2] create /zk_test my_data 如图:
 4、 查看新建Znode:[zk: 127.0.0.1:2181(CONNECTED) 3] ls / 如图:
4、 查看新建Znode:[zk: 127.0.0.1:2181(CONNECTED) 3] ls / 如图:
 创建成功!
创建成功!
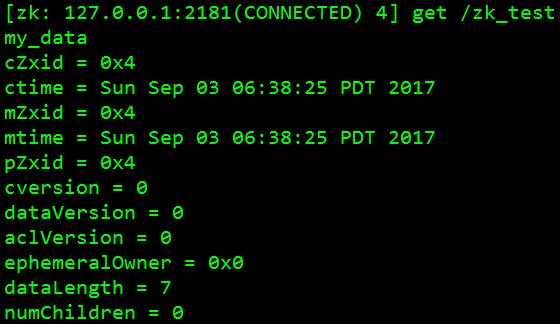
5、 验证数据“my_data”已关联新Znode:[zk: 127.0.0.1:2181(CONNECTED) 4] get /zk_test 如图:
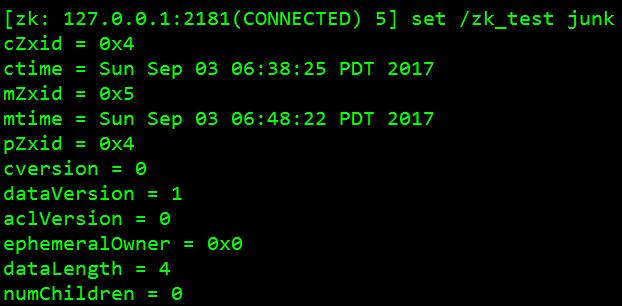
 6、 改变数据与Znode的关联:[zk: 127.0.0.1:2181(CONNECTED) 5] set /zk_test junk 如图:
6、 改变数据与Znode的关联:[zk: 127.0.0.1:2181(CONNECTED) 5] set /zk_test junk 如图:
 7、 测试是否更改:[zk: 127.0.0.1:2181(CONNECTED) 6] get /zk_test 如图:
7、 测试是否更改:[zk: 127.0.0.1:2181(CONNECTED) 6] get /zk_test 如图:
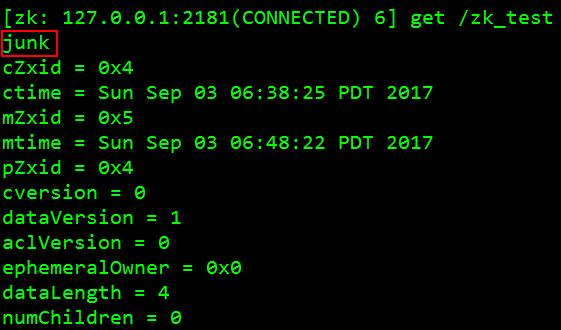 已更改!
已更改!
8、 删除新建Znode:[zk: 127.0.0.1:2181(CONNECTED) 7] delete /zk_test 如图:
 删除成功!
删除成功!
9、 退出zookeeper客户端:[zk: 127.0.0.1:2181(CONNECTED) 9] quit 如图:

1、 配置环境变量:[root@master ~]# vi /etc/profile 如图:
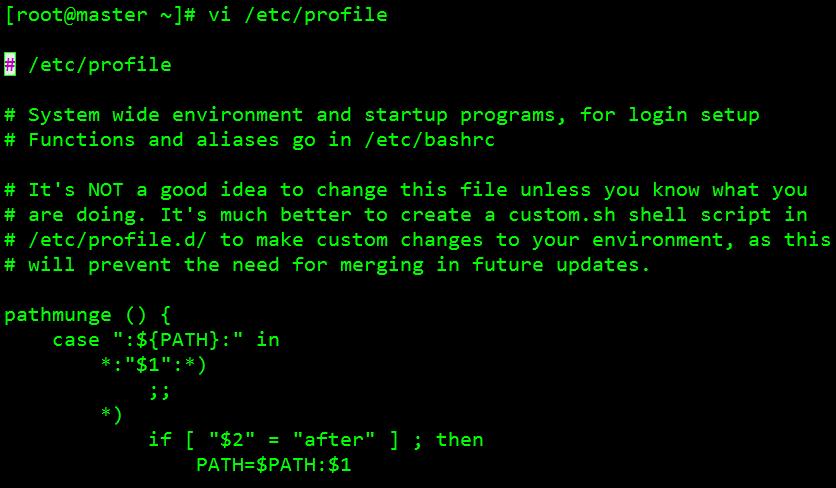 2、 文件底部加入如下内容:#SET ZK_HOMEexport ZK_HOME=/usr/module/zookeeper-3.4.10 export PATH=$PATH:$ZK_HOME/bin:$ZK_HOME/conf 3、 保存退出,刷新配置:[root@master ~]# source /etc/profile 4、 修改“conf”目录下的“zoo.cfg”文件:[root@master zookeeper-3.4.10]# vi conf/zoo.cfg 修改内容如图:
2、 文件底部加入如下内容:#SET ZK_HOMEexport ZK_HOME=/usr/module/zookeeper-3.4.10 export PATH=$PATH:$ZK_HOME/bin:$ZK_HOME/conf 3、 保存退出,刷新配置:[root@master ~]# source /etc/profile 4、 修改“conf”目录下的“zoo.cfg”文件:[root@master zookeeper-3.4.10]# vi conf/zoo.cfg 修改内容如图:
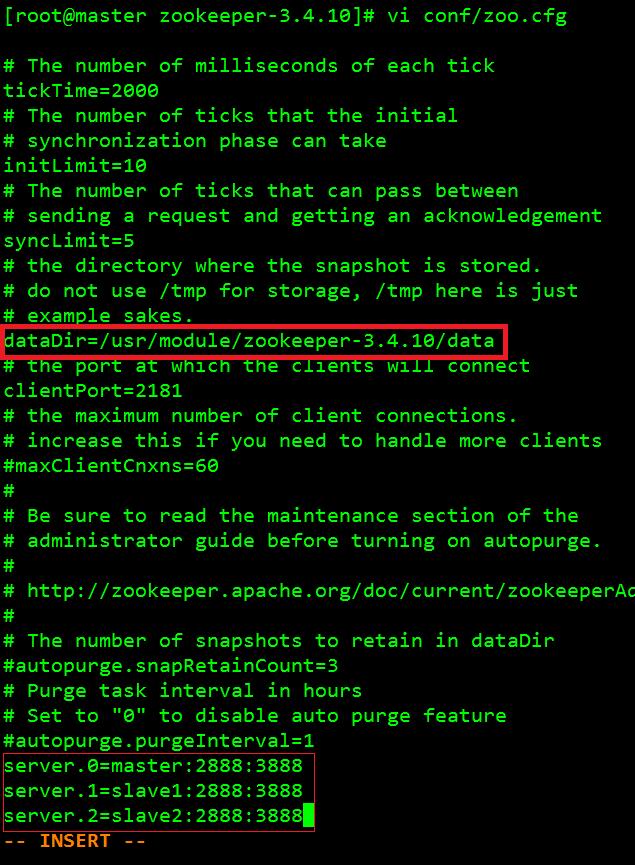
在“dataDir”的位置多了一个“data”路径,下面红框中的0、1、2分别代表服务器ID,master、slave1、slave2分别代表各自IP,2888、3888代表端口,用来系统之间通讯 5、 保存退出 6、 进入“zookeeper-3.4.10”目录,创建一个“data”文件夹:[root@master zookeeper-3.4.10]# mkdir data 如图: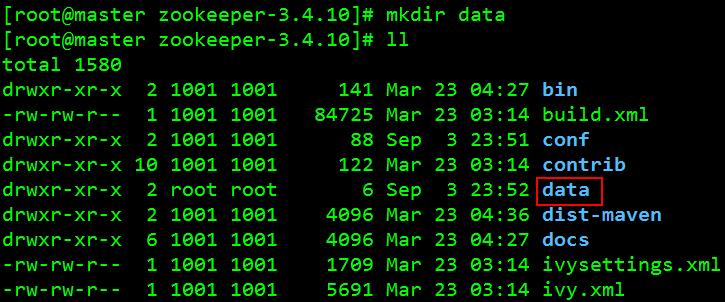 7、 进入“data”目录,创建一个文件“myid”,把“0”作为服务器ID写入文件:[root@master zookeeper-3.4.10]# cd data/ [root@master data]# vi myid 如图:
7、 进入“data”目录,创建一个文件“myid”,把“0”作为服务器ID写入文件:[root@master zookeeper-3.4.10]# cd data/ [root@master data]# vi myid 如图: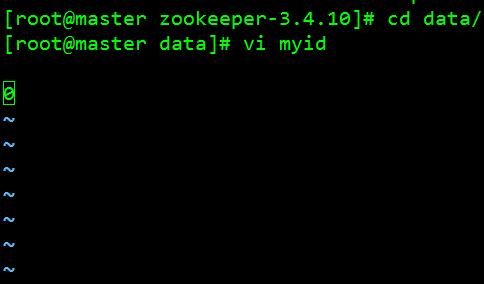 8、 保存退出
8、 保存退出
9、 把“zookeeper-3.4.10”拷贝到另外两台机器上:
[root@master module]# scp -r zookeeper-3.4.10 slave1:/usr/module/
[root@master module]# scp -r zookeeper-3.4.10 slave2:/usr/module/ 10、 slave1、slave2和master的环境变量保持一致并要记得刷新环境变量! 11、修改“zookeeper-3.4.10/data”下的“myid”文件,slave1的“myid”改成1,slave2的“myid”改成2,[root@slave1 data]# vi myid [root@slave2 data]# vi myid 如图:
slave1、slave2保存退出12、master、slave1、slave2分别启动进程:
[root@master zookeeper-3.4.10]# bin/zkServer.sh start
[root@slave1 zookeeper-3.4.10]# bin/zkServer.sh start
[root@slave2 zookeeper-3.4.10]# bin/zkServer.sh start 如图:



13、检查是否真正启动:[root@master zookeeper-3.4.10]# bin/zkServer.sh status [root@slave1 zookeeper-3.4.10]# bin/zkServer.sh status [root@slave2 zookeeper-3.4.10]# bin/zkServer.sh status 如图:

 三体zookeeper启动成功!
三体zookeeper启动成功!
14、关闭进程
以上是关于实战项目——Hadoop生态圈之动物管理员Zookeeper安装与实现的主要内容,如果未能解决你的问题,请参考以下文章