分布式协调服务中间件ZooKeeper 入门-ZK的介绍与特性
Posted 风间影月
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分布式协调服务中间件ZooKeeper 入门-ZK的介绍与特性相关的知识,希望对你有一定的参考价值。
一、Zookeeper简介
Zookeeper是一个服务,是一个分布式协调技术,他提供高性能,分布式的协调服务。主要用来解决分布式环境当中多个进程之间的同步控制,让他们有序的去访问某种临界资源,防止造成“脏数据”的后果。它也提供了其他简单的功能,这样分布式系统可以基于它来实现更好的服务,比如同步,配置管理,集群等等。他使用文件系统目录树作为数据模型。服务端可以跑在java程序上,他提供java和C的客户端api。
什么是分布式系统?
1.由多台计算机组成一个整体
2.计算机之间可以互相通信(rest/rpc)
3.用户的一次请求可能由多台计算机共同计算得出结果
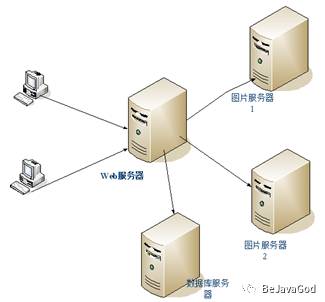
二、分布式系统所存在的瓶颈:
ZK通过协调服务来对各个系统进行有序的管理
三大特性:一致性、可用性、容错性

协调服务:简单来说,多个节点一起完成一系列动作
举个栗子:
集群成员管理,自身zk也是一个分布式系统,部署为集群,对自己进行管理
锁(分布式锁)
分布式锁作为ZK的核心,主要保持了分布式系统中资源的独占性,保证这个资源只会被进程A访问,而不会被进程2和3甚至其他的进程访问,直到释放。这样就保证了多个进程的有序访问,相当于堵车时候交警的作用,他是一个协调者。
*Chubby à谷歌
分布式事务
选主(集群或者分布式系统中某个计算机作为主leader来管理其他节点,比如一主二从,三主三从)
同步,数据一致性的同步,系统版本的同步管理
发布/订阅,可以作为数据同步的一种方式,通知到相关集群进行配置
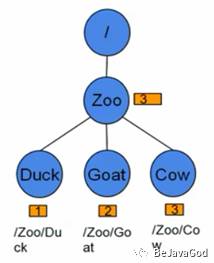
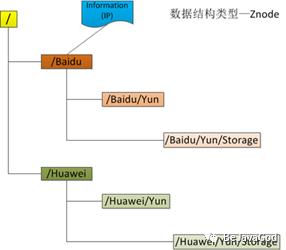
三、Zookeeper数据模型
1.ZooKeeper数据模型Znode,整体是个树形结构,实现过ztree.js/treegrid/treeview这些组件的就会很知道这样的结构,类似于文件系统结构,ftp结构
2.每个节点都称之为znode,每个节点可以有数据,也可以有子节点
3.节点路径: /Baidu/Yun/Storage /Zoo/Duck (不存在相对路径)
4.可以通过stat来保存数据的变化,acl的变化和时间戳
stat:此为状态信息,描述该Znode的版本,权限等信息
data:与该Znode关联的数据
children:该Znode下的子节点
5.数据发生变化,版本号会递增 (右下图的橙色框为版本号,可以当做乐观锁)
6.Znode可以进行数据的读写,主要用于存储配置文件信息、状态信息等等。存数都以KB为单位,不得超过1M
7.节点类型:
临时节点:存在于一个会话中,也就是session,session超时结束,那么本节点就没了,当然也可以手动删除。
需要注意的是,临时节点不能有子节点。
永久节点:永久存在,只有在客户端上才能被删除。
8.节点是有序的,我们可以自己添加递增计数给节点。并且这个计数是唯一存在的
9.主节点选举:会有一个主节点获取最新数据,然后同步到其他的节点上,保证数据一致;同时当有新的节点加入的时候也能去同步主节点的数据
10.监督者watcher
客户端上是可以设置wathc的,当阶段状态发生变化,也就是增删改的时候,zk会向客户端发送一条通知(只会发一次)。
11.每一个节点都拥有自己的ACL(访问控制列表),这个列表规定了用户的权限,即限定了特定用户对目标节点可以执行的操作。
四、Zookeeper中的时间与版本号
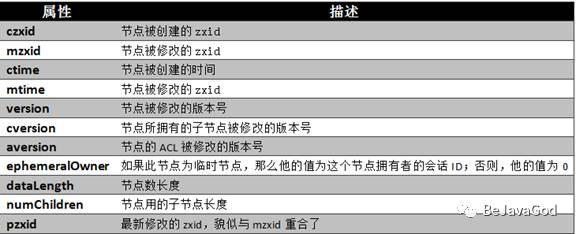
1.Zxid
zk节点发生变化,那都会接受到一个时间戳,称之为zxid,这个时间戳是全局的并且有序的,值越小发生的时间越久远,值越大发生的时间越靠近。其中每个节点的zxid有三种:
czxid:节点创建的时候发生的时间
mzxid:节点修改的时候发生的时间
pzxid:该节点或者子节点发生改变的时间
2.版本号
version:当前节点数据版本号
cversion:当前节点的子节点版本号
aversion:当前节点所拥有的ACL(访问控制)的版本号
五、节点属性图
六、zookeeper中的几个基本操作,如下图:
更新ZooKeeper操作涉及到delete或setData,必须明确要更新的Znode的版本号,使用exists进行判断并且找到改znode。如果版本号不匹配,更新将会失败。
更新ZooKeeper操作是非阻塞式的。也就是说,客户端如果失去了一个更新(由于另一个进程在同时更新这个Znode),他可以在不阻塞其他进程执行的情况下,选择重新尝试或进行其他操作。
*阻塞和非阻塞,要区别于同步和异步
七、watch触发器/监督者
对于所有的读操作:exists()、getChildren()及getData(),zk可以为其设置watch。Watch是一次性触发器,当监控的对象发生变化,那么就会触发对应的事件,然后这个事件被异步发送到客户端,并且zk也为watch提供了一致性保证。
Watch的类型:
数据watch,getData和exists负责设置数据watch
子节点数据watch,getChildren负责设置孩子watch
根据不同的操作返回的数据,来设置不同的watch
getData和exists返回节点的数据信息
getChildren返回子节点数据列表
触发器对应:
setData触发Znode的数据watch
create触发Znode的数据watch以及子节点数据watch
delete触发Znode的数据watch以及子节点数据watch
Watch 注册与触发
1. exists的watch,在被监视的Znode创建、删除或数据更新时被触发。
2. getData的watch,在被监视的Znode删除或数据更新时被触发。在被创建时不能被触发,因为getData的时候,这个znode必须是存在的。
3.getChildren的watch,在被监视的Znode的子节点创建或删除,或是这个Znode自身被删除时被触发。可以通过查看watch事件类型来区分是Znode,还是他的子节点被删除:NodeDelete表示Znode被删除,NodeDeletedChanged表示子节点被删除。
注意:服务器一旦断开连接,watch将不会被接收。不过,当一个新的客户端重新建立连接的时候,之前设置注册过的watch会被重新注册。
八、zookeeper数据发布与订阅
就是所谓的配置中心,发布者将数据发布到zooKeeper的一个或多个节点上,订阅者进行数据订阅,当有数据变化的时候,可以获得数据变化的通知(watch触发器)
和消息队列MQ类似。
九、zk的负载均衡
Zk自身的配置管理功能可以实现负载均衡,主要步骤
1.服务的提供者把自己的IP和端口注册到zk中2.服务消费者通过IP和某个端口来进行获取3.当提供者宕机的时候,对于的IP就会减少映射了4.Dubbo就是基于zookeeper来实现的5.Solr集群6.Kafka集群
(我们不建议使用zk来实现负载均衡,可以使用其他的软/硬负载均衡来做,LVS+nginx/F5)
十、集群角色,不同的计算机在集群环境中有不同的角色
Leader:为客户端提供读写服务
Follower:提供读服务,所有写的服务都需要由leader来做,参与选举
Observer:提供读服务,不参与选举,主要用于提高zk的并发,此角色用的不多
十一、zk会话session
客户端与服务端之间的连接存在会话
通过心跳机制来监测并且保持客户端连接的存活
可以接受触发watch的事件
可以设置session超时时间
十二、ACL(access control lists)访问权限
类似于linux/unix的权限控制
Create:创建子节点的权限
Read:获取节点数据和子节点列表的权限
Write:更新节点数据的权限
Delete:删除子节点的权限
Admin:设置节点ACL的权限
Create 和 delete 都是针对子节点的权限
以上是关于分布式协调服务中间件ZooKeeper 入门-ZK的介绍与特性的主要内容,如果未能解决你的问题,请参考以下文章