用Zookeeper来实现SparkSql的高可用
Posted 大数据架构技术
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了用Zookeeper来实现SparkSql的高可用相关的知识,希望对你有一定的参考价值。
用Zookeeper来实现SparkSql的高可用
一,简介
SparkSql是目前Spark体系里面最为重要的一个组件,其原理跟Hive相似,就连sql都有至少80%以上的兼容性,在绝大多数情况下SparkSql查询速度都会比Hive快10倍以上,SparkSql也是tap4fun极为重要的一个组件,tap4fun的数据仓库都是在SparkSql上建设的,使用的版本是Hortonworks基于Spark2.2的发行版
SparkSql是以ThriftServer方式提供服务,Client通过jdbc的方式来连接ThriftServer
二,原理
从上面架构可以看出ThriftServer是存在单点压力的,即如果ThriftServer挂掉,那么整个SparkSql服务将会不可用,完全不能达到tap4fun高可用的要求,而且SparkSql本身是不支持高可用的,所以就需要通过修改源码来实现,其基本思路就是对ThriftServer做负载均衡,即启动多个ThriftServer,同时提供服务,一台ThriftServer挂了还有其它ThriftServer能够提供服务,本文就将详细介绍tap4fun是如何通过修改SparkSql的源码来实现ThriftServer高可用的
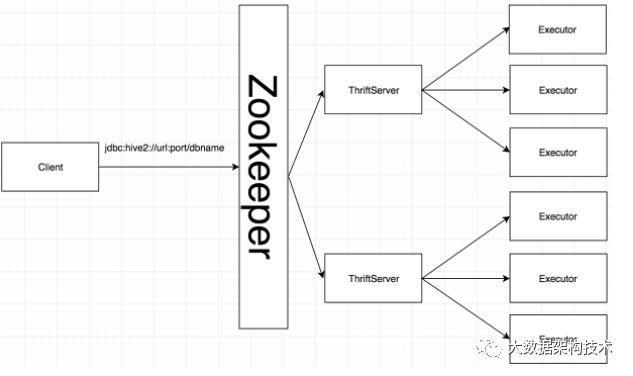


3,当某一台ThriftServer不可用,这里会有两种情况
Client再去连接ThriftServer

三,实现
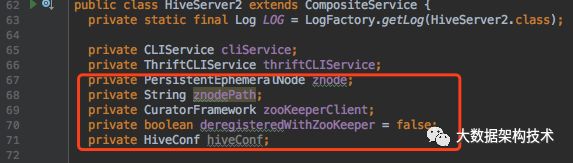
1,HiveServer2.scala(rg.apache.hive.service.server.HiveServer2.scala)
新增全局变量:
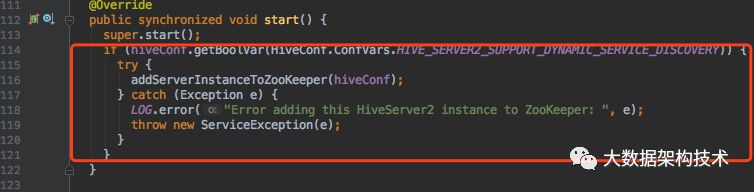
修改方法:
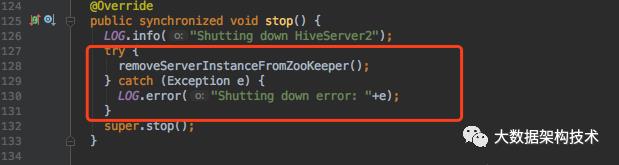
新增方法:
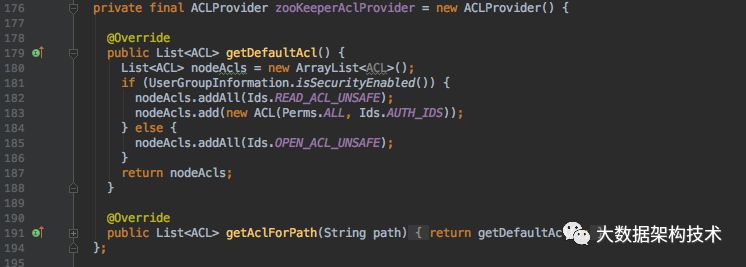
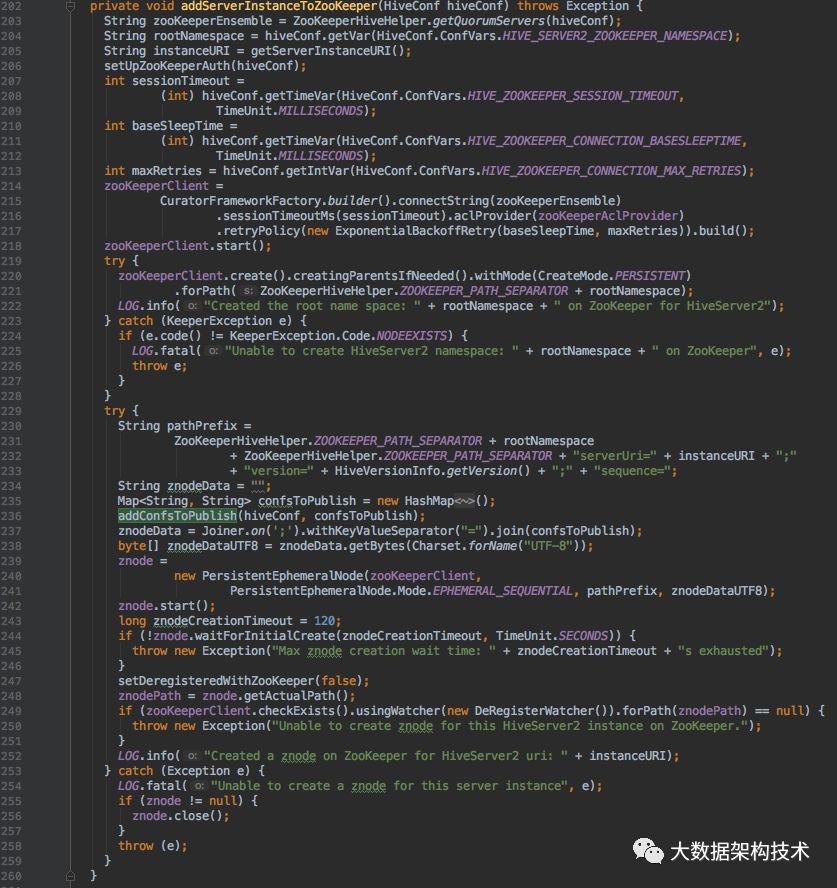
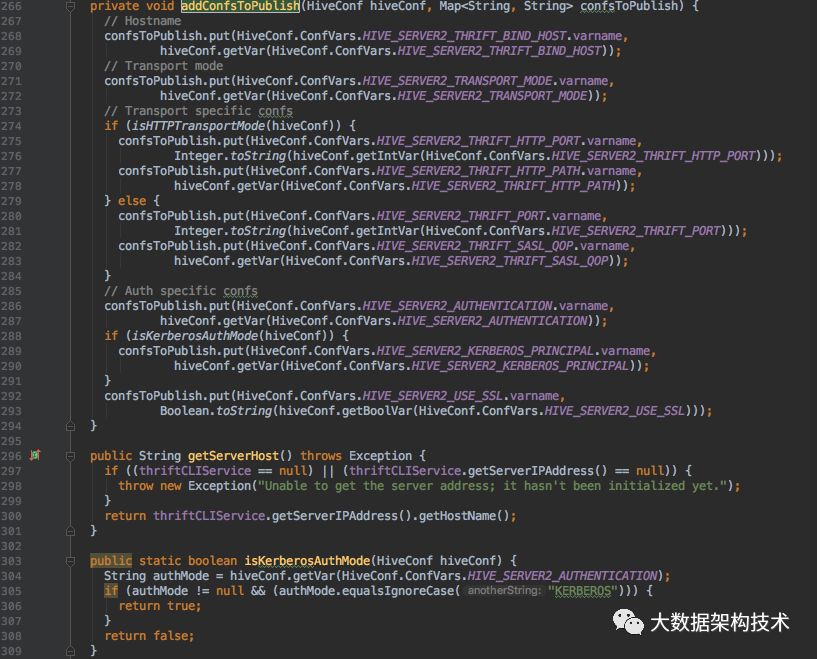
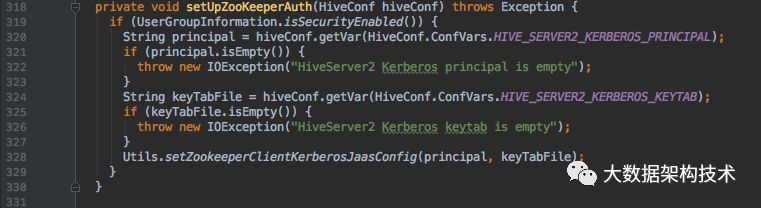
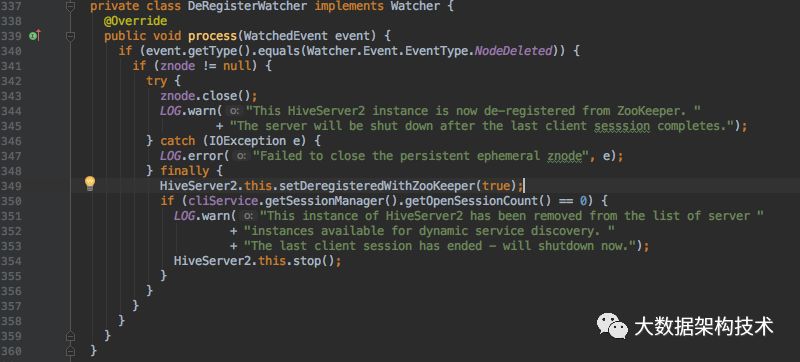
以上是ThriftServer向ZK注册,监听,删除的过程,接下来介绍需要改一下ThriftServer的启动类
2,HiveThriftServer2.scala(org.apache.spark.sql.hive.thriftserver.HiveThriftServer2.scala)
修改的方法:
编译:
mvn -Pyarn -Dscala-2.11.11 -Phive -Phive-thriftserver -DskipTests clean package
注:编译ThriftServer好像只能把Spark全部编译一遍,不能单独编译,可能是我理解不够透彻,希望知道的大神能给我留言,怎么单独编译ThriftServer
配置:
需要在hive-site.xml中加入一下配置
运行:
把编译好的ThriftServer jar包替换掉原来的jar包,然后分别在多台机器上启动ThriftServer
sbin/start-thriftserver.sh --master yarn --name test
连接:
这里要注意,在没有加入ZK之前的链接是:beeline -u "jdbc:hive2://yourthriftserverip:port/dbname",加入ZK之后的链接有一些变化:
beeline -u “jdbc:hive2://yourzkip:zkport/dbname;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=spark2_zk”
红色字体是必须要写的,其中zooKeeperNamespace就是你配置文件中的hive.server2.zookeeper.namespace
以上是关于用Zookeeper来实现SparkSql的高可用的主要内容,如果未能解决你的问题,请参考以下文章