hue/ oozie/ sqoop/ kafka/ zookeeper/ flume 简介及cdh安装简介
Posted 清研学堂
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了hue/ oozie/ sqoop/ kafka/ zookeeper/ flume 简介及cdh安装简介相关的知识,希望对你有一定的参考价值。
Hue是一个开源的Apache Hadoop UI系统,最早是由Cloudera Desktop演化而来,由Cloudera贡献给开源社区,它是基于Python Web框架Django实现的。通过使用Hue我们可以在浏览器端的Web控制台上与Hadoop集群进行交互来分析处理数据,例如操作HDFS上的数据,运行MapReduce Job等等。Hue所支持的功能特性集合: 默认基于轻量级sqlite数据库管理会话数据,用户认证和授权,可以自定义为mysql、Postgresql,以及Oracle; 基于文件浏览器(File Browser)访问HDFS;基于Hive编辑器来开发和运行Hive查询;支持基于Solr进行搜索的应用,并提供可视化的数据视图,以及仪表板(Dashboard);支持基于Impala的应用进行交互式查询;支持Spark编辑器和仪表板(Dashboard);支持Pig编辑器,并能够提交脚本任务;支持Oozie编辑器,可以通过仪表板提交和监控Workflow、Coordinator和Bundle;支持HBase浏览器,能够可视化数据、查询数据、修改HBase表;支持Metastore浏览器,可以访问Hive的元数据,以及HCatalog;支持Job浏览器,能够访问MapReduce Job(MR1/MR2-YARN);支持Job设计器,能够创建MapReduce/Streaming/Java Job;支持Sqoop 2编辑器和仪表板(Dashboard);支持ZooKeeper浏览器和编辑器;支持MySql、PostGresql、Sqlite和Oracle数据库查询编辑器。
hue server安装在master 或者 bakmaster节点上
oozie:工作流和定时器
Oozie是一个基于工作流引擎的开源框架,是由Cloudera公司贡献给Apache的,它能够提供对Hadoop MapReduce和Pig Jobs的任务调度与协调。Oozie需要部署到Java Servlet容器中运行。Oozie工作流定义,同JBoss jBPM提供的jPDL一样,也提供了类似的流程定义语言hPDL,通过XML文件格式来实现流程的定义。对于工作流系统,一般都会有很多不同功能的节点,比如分支、并发、汇合等等,Oozie也有类似的一些概念,不做过多解释,更多信息可以参考相关文档。Oozie定义了控制流节点(Control Flow Nodes)和动作节点(Action Nodes),其中控制流节点定义了流程的开始和结束,以及控制流程的执行路径(Execution Path),如decision、fork、join等;而动作节点包括Hadoop map-reduce、Hadoop文件系统、Pig、SSH、HTTP、eMail和Oozie子流程。
oozie server 可以安装在任一集群节点上
sqoop:sql to hadoop 因此涉及到数据传输 所以 最好是在每一个datanode上安装sqoop 1 client way
Sqoop是一个用来将Hadoop和关系型数据库中的数据相互转移的工具,可以将一个关系型数据库(例如 : MySQL ,Oracle ,Postgres等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。通过hadoop的mapreduce把数据从关系型数据库中导入数据到HDFS。Sqoop大约有13种命令,和几种通用的参数(都支持这13种命令)。Sqoop通用参数又分Common arguments,Incremental import arguments,Output line formatting arguments,Input parsing arguments,Hive arguments,HBase arguments,Generic Hadoop command-line arguments。
kafka:
kafka的工作方式和其他MQ基本相同,只是在一些名词命名上有些不同。为了更好的讨论,这里对这些名词做简单解释。通过这些解释应该可以大致了解kafkaMQ的工作方式。Producer (P):就是kafka发消息的客户端 Consumer (C):从kafka取消息的客户端 Topic (T):可以理解为一个队列 Consumer Group (CG):这是kafka用来实现一个topic消息的广播(发给所有的consumer)和单播(发给任意一个consumer)的手段。一个 topic可以有多个CG。topic的消息会复制(不是真的复制,是概念上的)到所有的CG,但每个CG只会把消息发给该CG中的一个 consumer。如果需要实现广播,只要每个consumer有一个独立的CG就可以了。要实现单播只要所有的consumer在同一个CG。用CG还 可以将consumer进行自由的分组而不需要多次发送消息到不同的topic。Broker(B):一台kafka服务器就是一个broker。一个集群由多个broker组成。一个broker可以容纳多个topic。Partition(P):为了实现扩展性,一个非常大的topic可以分布到多个broker(即服务器)上。kafka只保证按一个partition中的将消息顺序发给consumer,不保证一个topic的整体(多个partition间)的顺序。可靠性(一致性) MQ要实现从producer到consumer之间的可靠的消息传送和分发。传统的MQ系统通常都是通过broker和consumer间的确认 (ack)机制实现的,并在broker保存消息分发的状态。即使这样一致性也是很难保证的。kafka的做法是由consumer自己保存 状态,也不要任何确认。这样虽然consumer负担更重,但其实更灵活了。因为不管consumer上任何原因导致需要重新处理消息,都可以再次从broker获得。
kafka的producer有一种异步发送的操作。这是为提高性能提供的。producer先将消息放在内存中,就返回。这样调用者(应用程序) 就不需要等网络传输结束就可以继续了。内存中的消息会在后台批量的发送到broker。由于消息会在内存呆一段时间,这段时间是有消息丢失的风险的。broker间的消息复制机制,去除了broker的单点故障(SPOF)。
扩展性:kafka使用zookeeper来实现动态的集群扩展,不需要更改客户端(producer和consumer)的配置。broker会在 zookeeper注册并保持相关的元数据(topic,partition信息等)更新。而客户端会在zookeeper上注册相关的watcher。 一旦zookeeper发生变化,客户端能及时感知并作出相应调整。这样就保证了添加或去除broker时,各broker间仍能自动实现负载均衡。
负载均衡:负载均衡可以分为两个部分:producer发消息的负载均衡和consumer读消息的负载均衡。producer有一个到当前所有broker的连接池,当一个消息需要发送时,需要决定发到哪个broker(即partition)。这是由 partitioner实现的,partitioner是由应用程序实现的。应用程序可以实现任意的分区机制。要实现均衡的负载均衡同时考虑到消息顺序的 问题(只有一个partition/broker上的消息能保证按顺序投递),partitioner的实现并不容易。consumer读取消息时,除了考虑当前的broker情况外,还要考虑其他consumer的情况,才能决定从哪个partition读取消息。
性能 性能是kafka设计重点考虑的因素。使用多种方法来保证稳定的O(1)性能。
kafka使用磁盘文件保存收到的消息。它使用一种类似于WAL(write ahead log)的机制来实现对磁盘的顺序读写,然后再定时的将消息批量写入磁盘。消息的读取基本也是顺序的。这正符合MQ的顺序读取和追加写特性。
另外,kafka通过批量消息传输来减少网络传输,并使用java中的sendfile和0拷贝机制减少从读取文件到发送消息间内存数据拷贝和内核用户态切换的次数。
由于kafka时消息中间件,因此最好安装在 flume agent 以及 hbase gateway 和 hive gateway
zookeeper:分布式应用程序协调服务 奇数个节点 需要比hbase kafka hive yarn早安装
支持hdfs/yarn/hive/hbase/oozie/kafka/hue
Zookeeper的核心是原子广播,这个机制保证了各个Server之间的同步。实现这个机制的协议叫做Zab协议。Zab协议有两种模式,它们分别是恢复模式(选主)和广播模式(同步)。当服务启动或者在领导者崩溃后,Zab就进入了恢复模式,当领导者被选举出来,且大多数Server完成了和leader的状态同步以后,恢复模式就结束了。状态同步保证了leader和Server具有相同的系统状态。
为了保证事务的顺序一致性,zookeeper采用了递增的事务id号(zxid)来标识事务。所有的提议(proposal)都在被提出的时候加上了zxid。实现中zxid是一个64位的数字,它高32位是epoch用来标识leader关系是否改变,每次一个leader被选出来,它都会有一个新的epoch,标识当前属于那个leader的统治时期。低32位用于递增计数。
flume:经常与kafka结合 用于数据传输和简单的数据转换 因此,安装该组件时 一般与kafka broker在一个节点上
Flume是一个分布式、可靠、和高可用的海量日志聚合的系统,支持在系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。Flume NG:Flume next generation ,即Flume 1.x版本,它由Agent、Client等组件构成。
Flume NG基本架构
Flume NG是一个分布式、可靠、可用的系统,它能够将不同数据源的海量日志数据进行高效收集、聚合、移动,最后存储到一个中心化数据存储系统中。Flume NG更像是一个轻量的小工具,非常简单,容易适应各种方式日志收集,并支持failover和负载均衡。
Flume NG 的架构图如下所示。
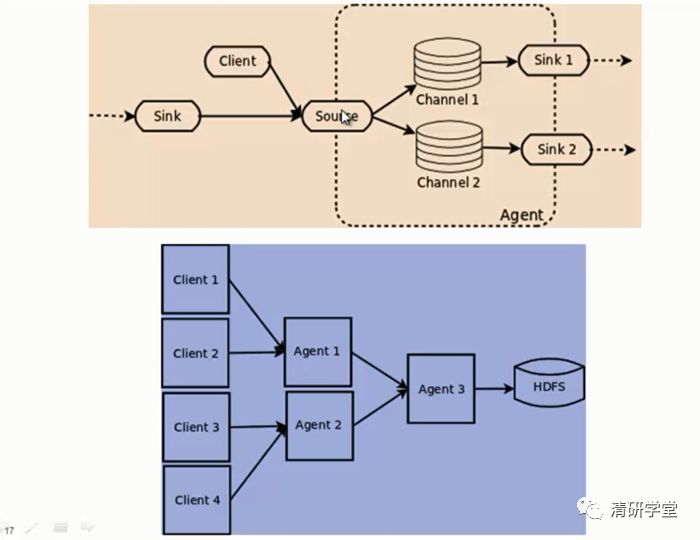
Flume NG核心概念
Flume的架构主要有一下几个核心概念:
1、Event:一个数据单元,带有一个可选的消息头。2、Flow:Event从源点到达目的点的迁移的抽象。3、Client:操作位于源点处的Event,将其发送到Flume Agent。4、Agent:一个独立的Flume进程,包含组件Source、Channel、Sink。1)、Source:用来消费传递到该组件的Event。2)、Channel:中转Event的一个临时存储,保存有Source组件传递过来的Event。3)、Sink:从Channel中读取并移除Event,将Event传递到Flow Pipeline中的下一个Agent(如果有的话)或者数据持久化。
Event
1、Event 是Flume数据传输的基本单元。 2、Flume 以事件的形式将数据从源头传输到最终的目的。 3、Event 由可选的header和载有数据的一个byte array构成。1)载有的数据对Flume是不透明的。 2)Header 是容纳了key-value字符串对的无序集合,key在集合内是唯一的。 3)Header 可以在上下文路由中使用扩展。
Client
1、Client 是一个将原始log包装成events并且发送它们到一个或者多个agent的实体。 2、Client 在Flume的拓扑结构中不是必须的,它的目的是从数据源系统中解耦Flume。
Agent
1、一个Agent包含Source、Channel、Sink和其他组件。 2、它利用这些组件将events从一个节点传输到另一个节点或最终目的地。 3、agent是Flume流的基础部分。 4、Flume 为这些组件提供了配置、生命周期管理、监控支持。
Agent之Source
1、Source负责接收event或通过特殊机制产生event,并将events批量的放到一个或多个Channel。 2、Source包含event驱动和轮询两种类型。 3、Source 有不同的类型。1)与系统集成的Source:Syslog,NetCat。 2)自动生成事件的Source:Exec 3)用于Agent和Agent之间的通信的IPC Source:Avro、Thrift。 4、Source必须至少和一个Channel关联。
Agent之Channel与Sink
Agent之Channel
1、Channel位于Source和Sink之间,用于缓存进来的event。 2、当Sink成功的将event发送到下一跳的Channel或最终目的地,event才Channel中移除。 3、不同的Channel提供的持久化水平也是不一样的:1)Memory Channel:volatile。 2)File Channel:基于WAL实现。 3)JDBC Channel:基于嵌入Database实现。 4、Channel支持事物,提供较弱的顺序保证。 5、Channel可以和任何数量的Source和Sink工作。
Agent之Sink
1、Sink负责将event传输到下一跳或最终目的,成功完成后将event从Channel移除。 2、有不同类型的Sink:1)存储event到最终目的的终端Sink。比如HDFS,HBase。 2)自动消耗的Sink。比如:Null Sink。 3)用于Agent间通信的IPC sink:Avro。 3、Sink必须作用于一个确切的Channel。
以上是关于hue/ oozie/ sqoop/ kafka/ zookeeper/ flume 简介及cdh安装简介的主要内容,如果未能解决你的问题,请参考以下文章
大数据协作框架Sqoop+Flume+Oozie+Hue(59讲)
在hue 使用oozie sqoop 从mysql 导入hive 失败
修真大数据协作框架Sqoop+Flume+Oozie+Hue(59讲)
数据采集+调度:cdh5.8.0+mysql5.7.17+hadoop+sqoop+hbase+oozie+hue
Oozie-sqoop 工作流在 cloudera 中因心跳问题而挂起
Hadoop,Zookeeper,Hbase,Hive,Spark,Kafka,CDH,impala,azkaban,oozie,hue中webui常用端口