使用Zookeeper实现分布式锁--Zookeeper介绍
Posted 差无知
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了使用Zookeeper实现分布式锁--Zookeeper介绍相关的知识,希望对你有一定的参考价值。
什么是分布式系统?
与分布式系统相对应的就是集中式系统,什么是集中式系统呢?将一个软件安装部署到一台计算机上对外提供服务,这台计算机响应所有客户端的请求,就是一个集中式系统.
而很多台计算机组成了一个整体,一个整体一致对外处理同一个请求就是分布式系统.
分布式系统内部的每一个台计算机可以相互通信(RPC/REST/WebService/消息队列)
分布式系统的典型应用就是客户端到服务端的一次请求到响应结束会历经多个计算机.
图例一: 分布式文件系统
图例二: 购物流程:
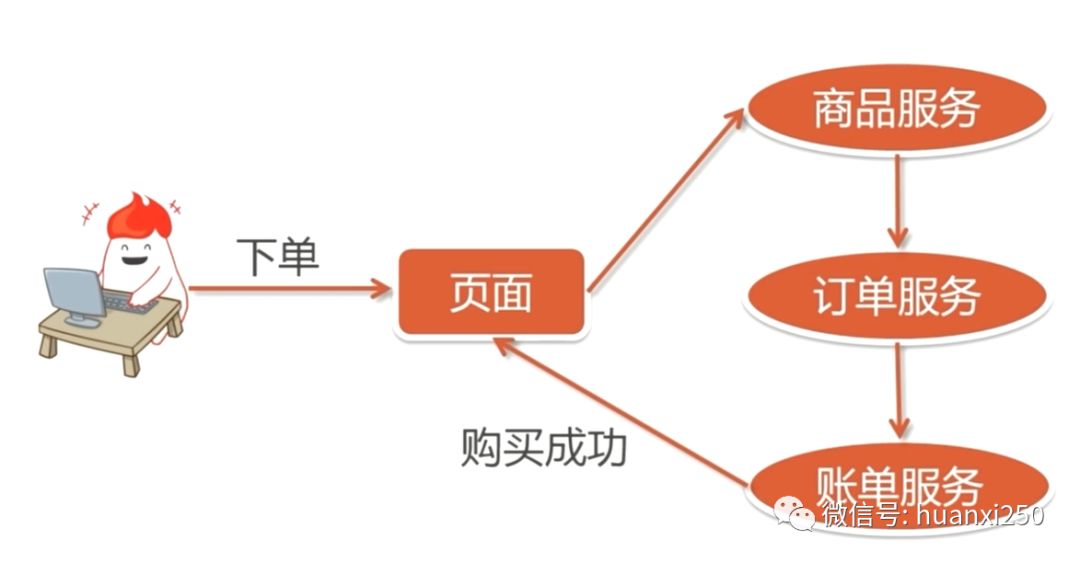
为什么要使用分布式系统?
更好的服务用户:
当用户量增加的时候,用户请求会分流,整体的负载和性能会有一个很大的提高
面向服务的架构
将整个系统划分为不同的服务模块,这样降低了耦合性,提高系统功能的扩展性
分布式系统的协调服务Zookeeper
地铁上的人流负载
分布式系统如果操作相同的共享数据,由于存在多个进程进行资源的竞争,所以可能会出现数据的一致性问题,造成数据不安全.

2. Zookeeper负责分布式系统的协调服务
Zookeeper就像是拥挤的地铁站中的指挥人员,负责协调分布式系统各个服务之前相互协作以及数据的安全共享.
一致性,数据的一致性,数据按照顺序分批次入库
原子性:事务要么成功,要么失败,不会局部化
单一视图:客户端连接集群中任意一个zk节点,数据都是一致性的
可靠性,每一次的ZK的操作状态都会保存到服务端
实时性: 客户端可以读取到zk服务端的最新数据
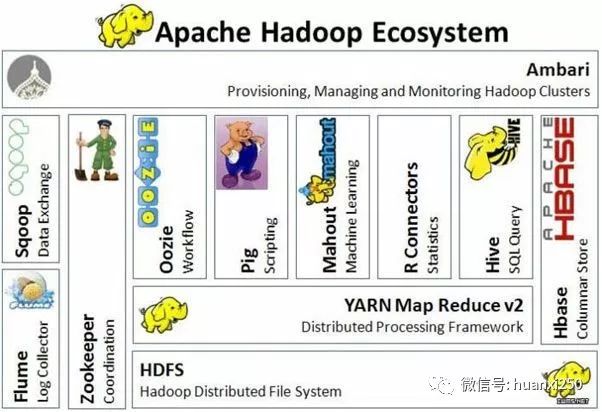
Zookeeper作为分布式系统协调服务,在Hadoop生态中扮演重要作用,被称为(Zookeeper)动物管理员.
3. Zookeeper的特性:
4. Hadoop生态
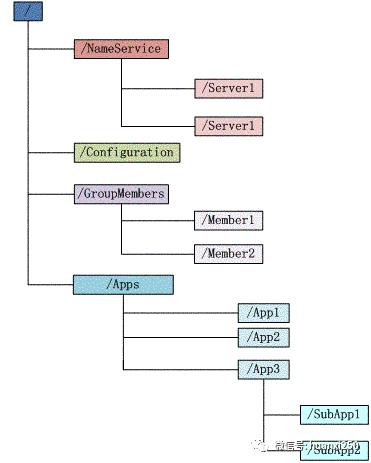
Zookeeper的数据结构模型和特点
zk的数据结构模型
2. zk数据结构特点(这些特点后续都会用到):
zk存储数据的结构如上图,是树状结构
每个子目录项如NameService都被称作znode,这个znode是被它所在的路径唯一标识,如Server1这个znode的标识为/NameService/Server1
znode可以有子节点目录,每一个znode必须存储数据
znode是有版本version,也就是一个访问路径可以存储多份不同版本数据
znode可以是临时节点,退出zk客户端与服务端失去联系就删除,也可以是永久节点
znode可以设置权限访问
znode可以被监控,通过设置一个监听事件来判断这个znode的增删改情况
Zookeeper的安装
分为集群模式和单机模式,安装在linux机器上,可以自行百度查询.
Zookeeper的会话原理
客户端与服务端的连接存在一个会话
每一个会话都可以设置一个超时时间
心跳机制原理:zk客户端向服务端的ping包请求
会话过期后:则临时节点znode会被抛弃
心跳结束后:会话过期
Zookeeper常用查询命令
./zKcli.sh 打开zk的命令行客户端
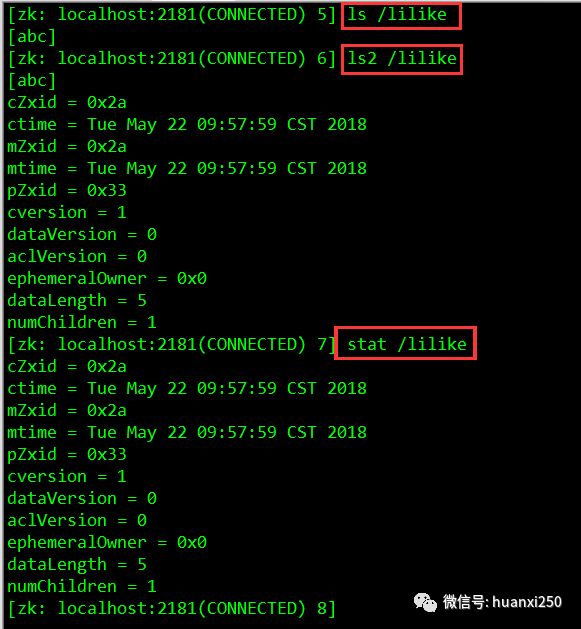
ls 命令和 ls2命令
ls : 查看一个目录下面有哪些内容
ls2 : 查看一个目录下面的内容和内容状态信息
ls2 = ls + stat
get 和 stat 命令
stat : 就是 status
get : 把某个节点所有的数据取出来
stat状态
cZxid : 创建后分配的id
ctime : 创建事件
mZxid : 修改后分配的id
mtime : 修改时间
pZxid : 子节点的id
cversion : 子节点的version
dataVersion : 当前节点数据的版本号
aclVersion : 版本号
dataLength : 数据长度
mChildren : 子节点数量
ephemeralOwner : 如果不是0x0就表示是临时节点
Zookeeper的增删改命令
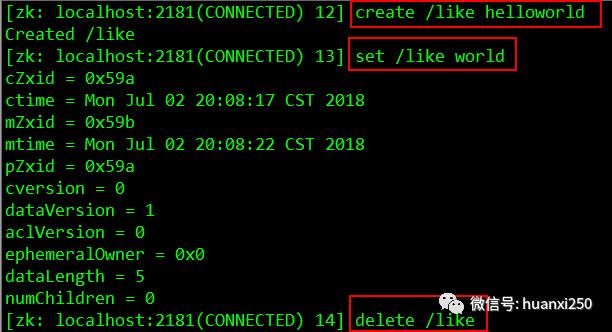
create 命令 :创建znode节点
临时节点 :
create -e /lyric/tmp hello永久节点 :
create /lyric lilike创建顺序节点 :
create -s /lyric/sec seqcreate [-s] [-e] path data acl
delete path [version] : 删除znode
delete /lyric 1set path data [version]
set /lyric like 1
Zookeeper的Watcher机制及其命令
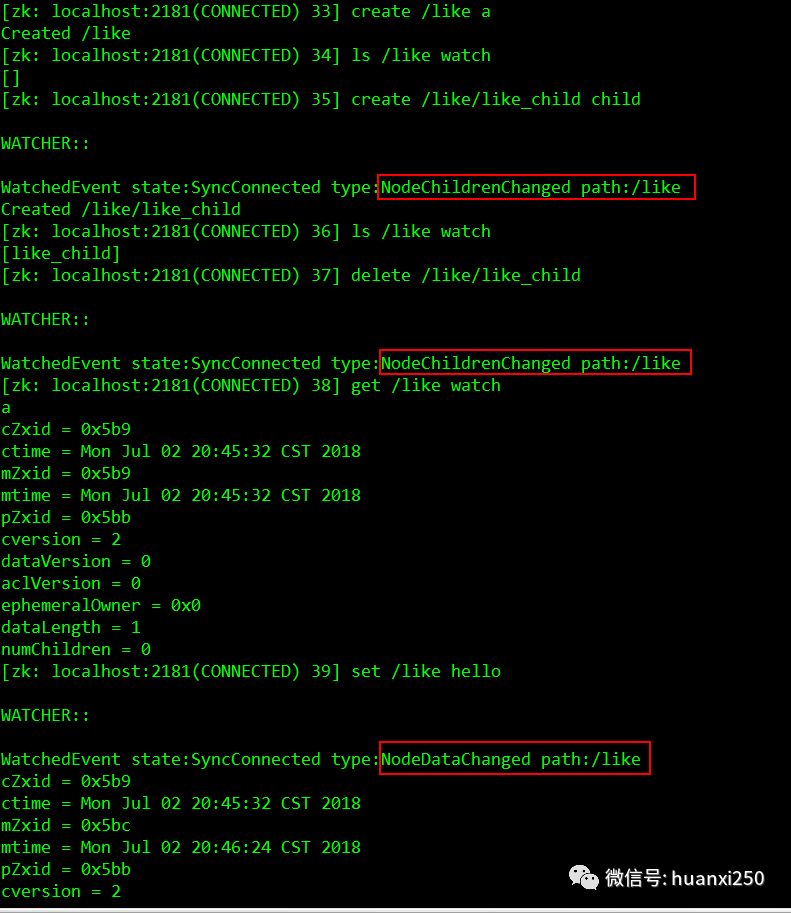
针对每一个节点操作(增删改),都有一个监督者 —- Wather
当监控的某个对象(znode)发生了变化,就会触发wather事件
zk的wather是一次性的,触发后就会立即销毁
针对不同类型的操作,触发的Wather事件也会不同:
创建事件: NodeCreated
修改事件: NodeDataChanged
删除事件: NodeDeleted
监听了某个znode之后无论是父节点,子节点,本znode发生变化,都会监听到
使用步骤:
设置监听事件
进行相应操作触发事件
设置事件:
ls path watchstat path watchls2 path wathch创建节点触发: NodeCreated
create /big onels /big watchcreate /big/yun one修改节点触发: NodeDataChanged
create /big oneget /big watchset /big two删除节点触发: NodeDelete
create /big onels /big watchdelete /big
Watch使用场景
分布式系统的统一资源配置
2. 分布式锁
ACL(access control lists)权限控制
针对znode节点可以设置读写权限,目的是保障数据的安全性
权限permissions可以指定不同权限范围及角色
getAcl : 获取某一个节点acl权限信息
getAcl pathsetAcl : 设置某个节点的acl权限信息
setAcl path acladdauth: 输入认证授权信息,注册时输入明文密码(登录),但是在zk的系统里面,密码以加密方式存在
zk 的 acl通过 [scheme:id:permissions]来构成权限列表
scheme : 代表采用的某种权限机制
id : 代表允许访问的用户
permissions : 权限组合字符串
world : world 下只有一个id,就是只有一个用户,也就是anyone,组合写法就是world:anyone:[permissions]
auth : 需要认证登录,需要注册用户有权限就可以,形式是auth:user:password:[permissions]
digest:需要对密码进行加密才能访问,组合形式:
digest:username:BASE64(SHA1(password)):[permissions]
简而言之:auth和digest的区别就是前者是明文,后者是密文:
setAcl/path auth:lee:lee:cdrwa
与
setAcl/path digest:lee:BASE64(SHA1(password))cdrwa
是等价的,在通过
addauth digest lee:lee后都能操作指定节点的权限
比如 ip:192.168.1.1:[permissions]
super : 代表超级管理员,拥有所有的权限
权限字符串 crdwa:
CREATE : 创建子节点
READ : 获取节点/子节点
WRITE : 设置子节点权限
DELETE : 删除子节点
ADMIN : 设置权限
ACL命令行练习
world: anyone :cdrwa
getAcl /lilike/abcsetAcl /lilike/abc world:anyone:cwrdauth:user:pwd:cdrwa
digest:user:BASE64(SHA1(pwd)):cdrwa
addauth digest user:pwd
代码:
addauth digest like:like— 添加用户setAcl /names/imooc auth:like:like:cdrwa— 设置权限使用digest:
退出当前用户 ctrl + c
setAcl /names/test digest:imooc:XwEDaL3J0JQGkRQzM0DpO6zMzZs=:cdraaddauth digest imooc:imooc— 登录还是要用明文去登录使用ip:
create /names/ip ipgetAcl /names/ipsetAcl /names/ip ip:192.168.1.1:cwrd使用supser进行超级用户登陆:
修改zkServer.sh增加super管理员
重启zkServer.sh
进入zkCli.sh 客户端之后,需要登录超级管理员之后才有权限
ACL使用场景
开发和测试环境分离,开发者无权操作测试库的节点,只能看
生产环境上控制指定ip的服务可以访问相关的节点,防止混乱
常用的ZK java客户端
ZK原生API
超时重连,不支持自动,需要手动操作
Watch注册一次之后会失效
不支持递归创建节点
ZKclient:
第三方开源项目
Apache curator
Apache的开源项目
解决了watcher的注册一次就失效
提供了常用的Zookeeper的工具类
编程风格更爽
Apache curator的使用
导入包:
<!-- curator start -->
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-framework</artifactId>
<version>4.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-recipes</artifactId>
<version>4.0.0</version>
</dependency>
<!-- curator end -->具体可参考文档: http://curator.apache.org/getting-started.html
Quick-Start:
// 重试机制:重试超时和重试次数
RetryPolicy retryPolicy =
new ExponentialBackoffRetry(1000, 3)
CuratorFramework client = CuratorFrameworkFactory.
newClient(zookeeperConnectionString,
retryPolicy);
client.start(); // 创建一个客户端
client.create().forPath("/my/path", myData) //创建一个Zookeeper的znode节点Zookeeper用来解决分布式系统中的数据一致性问题
在集中式系统中高并发的情况下,多条线程之间对共享资源进行抢夺使用权并进行数据修改,可能会导致数据的不一致问题.我们可以采用同步锁的方式来解决.
在分布式系统中,实际上是多个进程对共享数据的修改,此时线程的同步锁已经无法解决这个问题,例如分布式系统:
订单服务和商品服务可能同时操作订单表,对订单表进行增删改操作
而这两个服务是部署到不同的机器上的,所以他们是不同的进程
我们可以采用分布式锁的方式对这两个进程同时修改订单表进行限制
下一篇我将使用Zookeeper实现分布式锁,来保证分布式系统中数据的一致性.
以上是关于使用Zookeeper实现分布式锁--Zookeeper介绍的主要内容,如果未能解决你的问题,请参考以下文章