图解ZooKeeper的典型应用场景
Posted Java识堂
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了图解ZooKeeper的典型应用场景相关的知识,希望对你有一定的参考价值。
zookeeper在很多框架中都有应用,例如:Dubbo,Hadoop,Kafka等,但典型的用法也就几种,掌握了这几种用法,再看zookeeper在相关框架中的应用就很轻松,下一篇文章将会详细介绍zookeeper在dubbo中的使用,以便有一个更深刻的了解
本文参考了《从Paxos到ZooKeeper》,鉴于本文的定位是一篇科普性质的文章,因此对于一些诸如共享锁和分布式队列的具体实现没有进行更详细的描述,实际工作中需要实现时可以参考这本书
zookeeper的数据模型和文件系统类似,每一个节点称为znode,是zookeeper中的最小数据单元,每一个znode上可以报存数据和挂载子节点,从而构成一个层次化的属性结构
可以创建如下四种节点(znode)
持久节点:节点创建后会一直存在zookeeper服务器上,直到主动删除
持久顺序节点:每个节点都会为它的一级子节点维护一个顺序
临时节点:临时节点的生命周期和客户端的会话保持一致。当客户端会话失效,该节点自动清理
临时顺序节点:在临时节点上多了一个顺序的特性
简单演示一下常用的命令
create [-s] [-e] path data acl-s : 创建顺序节点
-e : 创建临时节点
path : 路径
data : 数据
acl : 权限
create默认创建的是持久节点
create /level-1 123
create /level-1/level-1-2 456
get /level-1(获取节点level-1的值,输出123)
ls /level-1 (获取节点level-1的子节点,输出[level-1-2])
// 创建一个顺序节点
create -s /nodes 123(实际为nodes0000000003)
create -s /nodes 456(实际为nodes0000000004)执行完上述命令后,数据结构如下所示
这里简单说一下顺序节点的特性。每次创建顺序节点时,zk都会在路径后面自动添加上10位的数字(计数器),例如 < path >0000000001,< path >0000000002,……这个计数器可以保证在同一个父节点下是唯一的。在zk内部使用了4个字节的有符号整形来表示这个计数器,也就是说当计数器的大小超过2147483647时,将会发生溢出,每次在父节点下创建一个顺序节点时,大小加1,如上图的3到4
zookeeper提供了分布式数据发布/订阅,允许客户端向服务端注册一个watcher监听,当服务端的一些指定事件触发了这个watcher,那么就会向指定客户端发送一个事件通知来实现分布式的通知功能。
简单举几个watcher的事件类型
EventType
触发条件
NodeCreated(节点创建)
Watcher监听的对应数据节点被创建
NodeDeleted(节点删除)
Watcher监听的对应数据节点被删除
NodeDataChanged(节点数据修改)
Watcher监听的对应数据节点的数据内容发生变更
NodeChildrenChanged(子节点变更)
Watcher监听的对应数据节点的子节点列表发生变更
基础知识讲解完毕,下面正式分享zookeeper的作用
数据发布/订阅(Publish/Subscribe)系统,即所谓的配置中心,顾明思义就是发布者将数据发布到zookeeper的一个或一系列的节点上,供订阅者进行数据订阅,进而达到动态获取数据的目的,实现配置信息的集中式管理和数据的动态更新。
zookeeper采用推拉结合的方式来实现发布订阅系统:客户端向服务端注册自己需要关注的节点,一旦该节点的数据发生变更,那么服务端就会向相应的客户端发送Watcher事件通知,客户端接收到这个消息通知之后,需要主动到服务端获取最新的数据。
程序总是需要配置的,如果程序分散部署在多台机器上,要这个改变配置就变得困难。好吧,现在把这些配置全部放到zookeeper上去,保存在zookeeper的某个目录节点中,然后所有相关应用程序对这个目录节点进行监控,一旦配置信息发生变化,每个应用程序就会收到zookeeper的通知,然后从zookeeper中获取新的配置信息应用到系统中就好
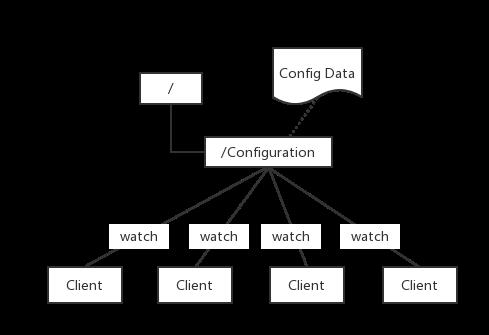
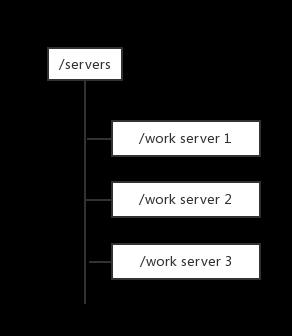
每台服务端在启动时都会去zookeeper的servers节点下注册临时节点(注册临时节点是因为,当服务不可用时,这个临时节点会消失,客户端也就不会请求这个服务端),每台客户端在启动时都会去servers节点下取得所有可用的工作服务器列表,并通过一定的负载均衡算法计算得出应该将请求发到哪个服务器上
在过去的单库单表型系统中,通常可以使用数据库字段自带的auto_increment属性来自动为每条记录生成一个唯一的ID。但是分库分表后,就无法在依靠数据库的auto_increment属性来唯一标识一条记录了。此时我们就可以用zookeeper在分布式环境下生成全局唯一ID。做法如下:每次要生成一个新Id时,创建一个持久顺序节点,创建操作返回的节点序号,即为新Id,然后把比自己节点小的删除即可。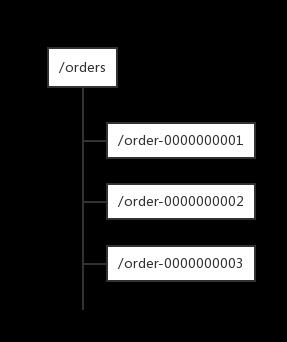
Master选举是一个在分布式系统中非常常见的应用场景。在分布式系统中,Master往往用来协调系统中的其他系统单元,具有对分布式系统状态变更的决定权。例如,在一些读写分离的应用场景用,客户端的写请求往往是由Master来处理的,而在另一些场景中, Master则常常负负责处理一下复杂的逻辑,并将处理结果同步给集群中其他系统单元。Master选举可以说是zookeeper最典型的应用场景了
利用zookeeper的强一致性,能够很好地保证在分布式高并发情况下节点的创建一定能保证全局唯一性,即zookeeper将会保证客户端无法重复创建一个已经存在的数据节点。也就是说,如果同时有多个客户端请求创建同一个节点,那么最终一定只有一个客户端能够创建成功。利用这个特性,就很容易在分布式环境中进行Master选举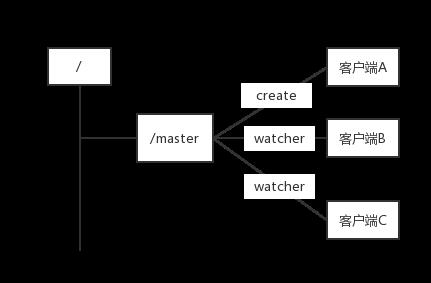
客户端集群往zookeeper上创建一个/master临时节点。在这个过程中,只有一个客户端能够成功创建这个节点,那么这个客户端就成了master。同时其他没有在zookeeper上成功创建节点的客户端,都会在节点/master上注册一个变更的watcher,用于监控当前的master机器是否存活,一旦发现当前的master挂了,那么其余的客户端将会重新进行master选举
在同一个JVM中,为了保证对一个资源的有序访问,如往文件中写数据,可以用synchronized或者ReentrantLock来实现对资源的互斥访问,如果2个程序在不同的JVM中,并且都要往同一个文件中写数据,如何保证互斥访问呢?这时就需要用到分布式锁了
目前分布式锁的主流实现方式有两种
利用redis setnex(key value) key不存在返回0,key存在返回1
zookeeper实现排他锁,共享锁(读锁)
这里只简单介绍一下排他锁的实现方式
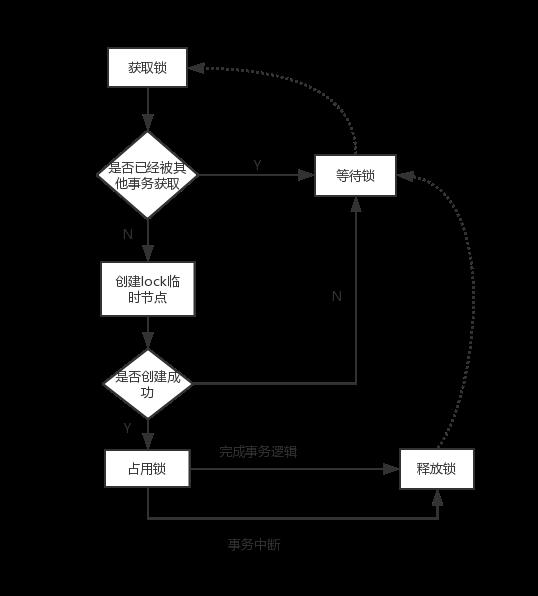
实现原理和master选举类似,所有客户端在/exclusive_lock节点下创建临时子节点/exclusive_lock/lock,zookeeper会保证在所有的客户端中,最终只有一个客户端能够创建成功,那么就认为该客户端获取了锁,其他没有获取到锁的客户端就需要到/exclusive_lock节点看上注册一个子节点变更的watcher监听,以便实时监听到lock节点的变更情况
释放锁的情况有如下两种
当前获取锁的客户端发生宕机,那么zookeeper上的这个临时节点就会被删除
正常执行完业务逻辑后,客户端会主动将自己创建的临时节点删除
整个排他锁的获取和释放流程可以用如下图表示
如下图,创建/queue作为一个队列,然后每创建一个顺序节点,视为一条消息(节点存储的数据即为消息内容),生产者每次创建一个新节点,做为消息发送,消费者监听queue的子节点变化(或定时轮询),每次取最小节点当做消费消息,处理完后,删除该节点。相当于实现了一个FIFO(先进先出)的队列。注:zookeeper强调的是CP(一致性),而非专为高并发、高性能场景设计的,如果在高并发,qps很高的情况下,分布式队列需酌情考虑。
推荐阅读
Java识堂
以上是关于图解ZooKeeper的典型应用场景的主要内容,如果未能解决你的问题,请参考以下文章