取代ZooKeeper!高并发下的分布式一致性开源组件StateSynchronizer
Posted AI前线
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了取代ZooKeeper!高并发下的分布式一致性开源组件StateSynchronizer相关的知识,希望对你有一定的参考价值。
StateSynchronizer 设计者之一 Flavio 是著名开源组件 ZooKeeper 的最早作者,他同时也是 《ZooKeeper:分布式过程协同技术详解》 这本书的作者。
更多优质内容请关注微信公众号“AI 前线”(ID:ai-front)
StateSynchronizer 不仅是 Pravega 公共 API 的一部分,许多 Pravega 内部组件也大量依赖 StateSynchronizer 共享状态,如 ReaderGroup 的元信息管理。并且我们可以基于 StateSynchronizer 实现更高级的一致性原语,例如跨 stream 的事务。
Pravega [1] 既可以被想象成是一组流存储相关的原语,因为它是实现数据持久化的一种方式,Pravega 也可以被想象成是一个消息订阅 - 发布系统,因为通过使用 reader,writer 和 ReaderGroup 它可以自适应地进行消息传递。本文假设读者已经熟悉 Pravega 的有关概念,否则可以参考相应的官方文档 [2] 和已发布的 4 篇专栏文章(见文末链接)。
Pravega 实现了各种不同的构建模块用以实现 stream 相关原语,StateSynchronizer [2] 就是其中之一,目的在于协调分布式的环境中的各个进程 ^2。从功能上看,StateSynchronizer 为一组进程提供可靠的共享的状态存储服务:允许多个客户端同时读取和更新同一共享状态并保证一致性语义,同时提供数据的冗余和容错。从实现上看,StateSynchronizer 使用一个 stream 为集群中运行的多个进程提供了共享状态的同步机制,这使得构建分布式应用变得更加简单。使用 StateSynchronizer,多个进程可以同时对同一个共享状态进行读取和修改,而不必担心一致性问题 [3]。
StateSynchronizer 的最大贡献在于它提供了一种 stream 原生的一致性存储方案。由于 stream 具有只允许追加(Append-Only)的特性,这使得大部分现有的存储服务都无法很好地应用于 stream 存储的场景。相比于传统的状态存储方案,stream 原生的存储使得 StateSynchronizer 具有以下优点:
与常见的键值存储(Key/Value Store)不同,StateSynchronizer 支持任意抽象的共享状态,而不仅仅局限于维护键值集合。
与常见的数据存储不同,StateSynchronizer 以增量的方式维护了共享状态的整个变更历史,而不仅仅是维护共享状态的最新快照。这一特性不仅大大减少了网络传输开销,还使得客户端可以随时将共享状态回滚到任意历史时刻。
与常见的状态存储不同,StateSynchronizer 的服务端既不存储共享状态本身也不负责对共享状态进行修改,所有共享状态的存储和计算都只发生在客户端本地。这一特性不仅节约了服务端的计算资源,还增加了状态计算的灵活性,例如:除了基本的 CAS(Compare-And-Swap)语义,还支持高隔离级别的复杂事务 [^3]。
与现有的基于乐观并发控制(Optimistic Concurrent Control, OCC) [4] [5] 的存储系统不同,StateSynchronizer 可以不依赖多版本控制机制(Multi Version Concurrent Control, MVCC) [6] [7]。这意味着即使在极端高并发的场景下,状态更新的提交也永远不会因版本冲突而需要反复重试。
StateSynchronizer 无意于也不可能在所有场景中替代传统的分布式键值存储组件,因为它的运行机制大量依赖 stream 的特性。但是,在具有 stream 原生存储和较强一致性需求的场景下,StateSynchronizer 可能是一种比其它传统键值存储服务更为高效的选择。
在不同的上下文环境中,“一致性”一词往往有着不同的语义 [8] [9]。在分布式存储和数据高可用(High Availability)相关的语境下,一致性通常指数据副本(Replica)的一致性 [8]:如何保证分布在不同机器上的数据副本内容不存在冲突,以及如何让客户端看起来就像在以原子的方式操作唯一的数据副本,即线性化(Linearizability) [10]。常见的分布式存储组件往往依赖单一的 Leader(主节点)确定出特定操作的全局顺序,例如:ZooKeeper [11] 和 etcd [12] 都要求所有的写操作必须由 Leader 转发给其它数据副本。数据副本的一致性是分布式系统的难点,但却并不是一致性问题的全部。
脱离数据副本,在应用层的语境下,一致性通常指数据满足某种约束条件的不变性(Invariant)[13],即:指的是从应用程序特定的视角出发,保证多个进程无论以怎样的顺序对共享状态进行修改,共享状态始终处于一种“正确的状态”,而这种正确性是由应用程序或业务自身定义的。例如,对于一个交易系统而言,无论同时有多少个交易在进行,所有账户的收入与支出总和始终都应该是平衡的;又如,多进程操作(读 / 写)一个共享的计数器时,无论各进程以怎样的顺序读写计数器,计数器的终值应该始终与所有进程顺序依次读写计数器所得到的值相同。参考文献 [8] 将这种一致性归类为“事务性的一致性(Transactional Consistency)”,而参考文献 [9] 则将此类一致性简单称为“涉及多对象和多操作的一致性”。应用层的数据一致性语义与数据副本的一致性语义完全不同,即使是一个满足线性化的分布式系统,也需要考虑应用层的数据一致性问题 ^4。
目前常用的分布式键值存储服务,例如 ZooKeeper 和 etcd,都可以看作是一种对共享状态进行存储和维护的组件,即所有键值所组成的集合构成了当前的共享状态。在数据副本层面,ZooKeeper 和 etcd 都依赖共识(Consensus)算法提供一致性保证。ZooKeeper 使用 ZAB(ZooKeeper’s Atomic Broadcast)协议 [14] 在各节点间对写操作的提交顺序达成共识。在广播阶段,ZAB 协议的行为非常类似传统的两阶段提交协议。etcd 则使用 Raft 协议 [15] 在所有节点上确定出唯一的写操作序列。与 ZAB 协议不同,Raft 协议每次可以确认出一段一致的提交序列,并且所有的提交动作都是隐式的。
在应用层数据层面,ZooKeeper 和 etcd 都使用基于多版本控制机制的乐观并发控制提供最基础的一致性保证。一方面,虽然多版本控制机制提供了基本的 CAS 语义,但是在极端的高并发场景下仍因竞争而存在性能问题。另一方面,仅仅依靠多版本控制机制无法提供更加复杂的一致性语义,例如事务。尽管在数据副本层面,ZooKeeper 和 etcd 都提供很强的一致性语义,但对于应用层面的数据一致性却还有很大的提升空间:ZooKeeper 无法以原子的方式执行一组相关操作,而 etcd 的事务仅支持有限的简单操作(简单逻辑判断,简单状态获取,但不允许对同一个键进行多次写操作)。
在应用层数据层面,ZooKeeper 和 etcd 都使用多版本控制机制提供最基础的一致性保证。例如,ZooKeeper 的所有写操作都支持乐观并发控制:只有当目标节点的当前版本与期望版本相同时,写操作才允许成功;而 etcd 则更进一步,还支持非常有限的简单事务操作。一方面,虽然多版本控制机制提供了基本的 CAS 语义,但是在极端的高并发场景下仍因竞争而存在性能问题。另一方面,仅仅依靠多版本控制机制无法提供更加复杂的一致性语义,例如事务。
尽管在数据副本层面,ZooKeeper 和 etcd 都提供很强的一致性语义,但对于应用层面的数据一致性却还有很大的提升空间:ZooKeeper 无法以原子的方式执行一组相关操作,尤其是同时操纵多个键;而 etcd 的事务仅支持非常有限的简单操作(简单逻辑判断,简单状态获取,但不允许对同一个键进行多次写操作)。
为应用层数据提供比现有的分布式存储组件更强的一致性语义(复杂事务)和更高的并发度是 StateSynchronizer 的主要目标,尤其是在 stream 原生场景下,因为传统的以随机访问为主的存储组件很难适配 stream 存储的顺序特性。得益于 stream 的自身特性,StateSynchronizer 可以不依赖乐观并发控制和 CAS 语义,这意味着不会出现版本冲突也无需重试,从而更加适用于高并发的场景(2.2.4 小节)。在“无条件写”模式下,StateSynchronizer 的理论更新提交速度等价于 stream 的写入速度。
与现有的绝大多数存储服务不同,StateSynchronizer 反转了传统的数据存储模型(2.2.3 小节):它并不存储共享状态本身,转而存储所有作用在共享状态上的更新操作。一方面,这一反转的数据模型直接抽象出了共享状态,使得共享状态不再局限于简单的键值存储,而可以推广到任意需要一致性语义的状态。另一方面,反转数据存储的同时还不可避免地反转了数据相关的操作,使得原本大量的服务端状态计算可以直接在客户端本地完成(2.2.1 小节)。这一特性不仅大大降低了服务端的资源消耗,同时也使得 StateSynchronizer 可以提供更灵活的更新操作和更强一致性语义:复杂事务。
在 StateSynchronizer 的框架中,客户端提交的所有更新操作都是以原子的方式顺序执行的,并且所有更新操作的执行都发生在本地。从逻辑上看,每一个更新操作都等价于一个本地事务操作。这也意味着客户端可以在更新操作中使用复杂的业务逻辑(几乎是不受限的操作,只要操作本身的作用是确定性的)而无需担心一致性问题。
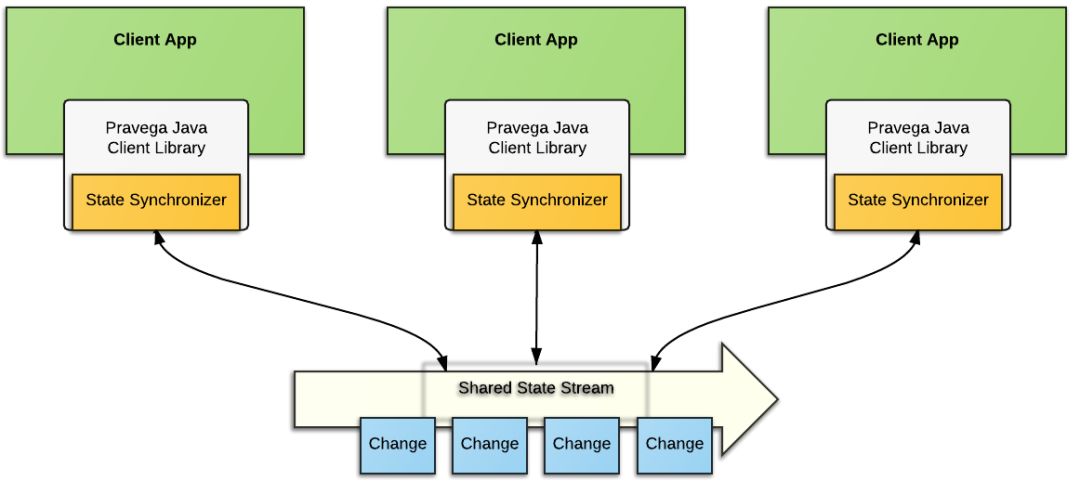
图 1 StateSynchronizer 的整体架构 [3] StateSynchronizer 包括一个嵌入在应用里的客户端和一个用于“存储”共享状态的 stream。
从整体架构上看,StateSynchronizer 是一个很典型的客户端 / 服务器结构(如图 1 所示):它包括一个以库的形式(当前版本仅支持 Java)嵌入在应用中的客户端,以及服务器端的一个对应 stream。从概念上看,StateSynchronizer 服务端负责以 stream 的形式“存储”共享状态。严格说来,stream 存储的是更新操作而不是共享状态本身。2.2.3 小节将对此进行更加深入的讨论。
StateSynchronizer 客户端是一个轻量级的组件,它与所有其它的 stream 客户端(例如 reader 和 writer)并没有本质上的不同:StateSynchronizer 客户端使用标准的 stream API 与服务器端的 stream 交互,并且服务器端也并不存在任何特定于 StateSynchronizer 的特性或实现。也就是说,StateSynchronizer 客户端具有其它 stream 客户端共同的优点,高效。所有 StateSynchronizer 特定的行为都是在客户端实现的,服务器端仅仅用于提供 stream 形式的存储媒介。StateSynchronizer 的客户端还非常精巧,核心部分的实现不过数百行代码 [16]。
从概念上说,每一个 StateSynchronizer 都对应一个共享状态:所有的客户端都可以并发地对这个共享状态进行读写操作,并且保持一致性。这个共享状态既可以很简单(例如,它可以是一个基本的数值变量),也可以很复杂(例如,它也可以是一个任意复杂的数据结构)。但是,如果从物理实现角度上看,根本不存在这样一个可以被共享访问的状态:每一个 StateSynchronizer 的客户端都只在各自的本地维护着一个“共享”状态的副本(Copy),除此以外没有任何地方存储这个状态。所有的读和写(更新)操作都是直接作用在这个本地共享状态副本上:读操作直接返回本地共享状态副本,而更新操作作用于本地共享状态并生成新的共享状态。
为了达到顺序一致性 [8],所有共享状态必须满足全序(Total Order)关系 [17]。如果用符号“≺”表示二元 happens-before 语义 [18],则任意 N 个状态必须能够确定出唯一全局顺序,如下:
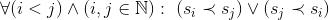 (1)
(1)
注意,happens-before 关系必须满足传递性,反自反性和反对称性 [19]。
如果读者阅读过StateSynchronizer接口 [20] 的实现类StateSynchronizerImpl,就会发现它有一个名为currentState的StateT类型的成员,并且StateT类型实现了Revisioned接口。这就是 StateSynchronizer 所维护的本地共享状态副本。Revisioned接口仅有两个成员方法:getScopedStreamName()用于获取该状态对应的 stream 的名字,getRevison()方法用于获取该状态对应的 Revision(一个抽象的版本概念,也可以近似等价为 Kafka 的 offset)。而Revision接口最终继承了Comparable接口,允许任意两个 Revision 进行比较,用于保证共享状态的全序关系。感兴趣的读者可以继续阅读Revision接口的标准实现类RevisionImpl的compareTo()方法,就会发现 Revision 的比较实际上是基于 Segment 偏移量进行的。由于 StateSynchronizer 的底层 stream 仅包含一个 segment,基于该 segment 的偏移量天然就是一个全序关系的良定义(well-defined)。
StateSynchronizer 上的更新操作的实现是递归式的,也可以说是生成式的。StateSynchronizer 的客户端接受一个更新操作 un ,将其成功持久化后(细节将在下文讨论)应用于当前的本地共享状态副本 sn,从而生成新状态 sn+1 ,如下:
sn+1 = un(sn) (2)
从纯数学的角度看,这是一个很典型的一阶马尔科夫模型 / 链(Markov Model) [21]:如果把 n 看作是离散的时间,那么 sn就构成了系统状态随时间迁移(Transition)的一个有序序列,并且该系统在任意时间点的状态 sn+1只依赖前一时刻的状态 sn ,并由当前更新 un 确定,而与任何其它状态无关。也可以这么理解,我们假设了状态 sn 已经包含了所有之前时刻的状态信息。这就是所谓的马尔科夫假设。为了启动状态迁移,我们规定系统必须具有一个起始状态 s0 ,而更新操作引起了随后的状态迁移。
如果从集群的视角看,有多个 StateSynchronizer 客户端独立同时运行并接受更新操作,而每个客户端本地的共享状态则分别经历着基于马尔科夫模型的状态迁移。为保证每个 StateSynchronizer 客户端的本地共享状态都能够收敛于相同的最终状态,首先要求状态迁移是确定性的(deterministic),也就是说,更新操作 un 本身必须是确定性的(我们将在 2.3.1 小节深入讨论更新操作与确定性问题)。从这个角度看,上述马尔可夫链其实已经退化成一个普通状态机。
其次,所有的 StateSynchronizer 客户端必须具有相同的起始状态 s0,并且以相同的顺序应用更新 un。整个集群的这种行为模式非常类似经典的复制状态机(Replicated State Machine)模型 [22]。复制状态机模型是一个应用广泛的分布式模型,许多常见的全序广播 / 原子广播协议都是基于该模型进行的,如 ZAB 协议和 Raft 协议等。我们有意忽略了著名的 Paxos 协议 [23] [24],因为原生的 Paxos 协议并非用于解决全序广播问题,尽管共识算法与全序广播之间确实被证明存在等价关系 [25]。复制状态机模型可以简单描述如下:
在各自独立的服务器节点上放置同一状态机的实例;
接受客户端请求,并转译成状态机的输入;
确定输入的顺序;
按已确定的顺序在各个状态机实例上执行输入;
用状态机的输出回复客户端;
监测各个状态副本或者状态机输出可能出现的差异。
复制状态机最核心也是最困难的部分是如何确定出一个输入顺序,以便让每个状态机实例都严格按照该顺序执行状态迁移,从而保证一致性。从整体架构上来说,ZAB 协议和 Raft 协议都依赖单一的主节点确定输入顺序:所有的更新操作只能通过主节点进行,因此顺序由主节点唯一确定。所不同的是,ZAB 协议通过显式的类两阶段提交方法保持广播更新操作的原子性,而 Raft 协议甚至没有显式的提交过程,直接依赖计数的方法实现隐式提交。
在 StateSynchronizer 的场景下,状态机实例即 StateSynchronizer 客户端,输入顺序即更新操作的应用顺序,执行状态迁移即应用更新操作至本地共享状态。StateSynchronizer 使用完全不同的方式解决输入顺序的确定问题,使得 StateSynchronizer 不需要依赖任何主节点。从严格意义上说,StateSynchronizer 并不负责维护数据副本,但是其本地共享状态的维护和更新模型都与数据副本有着相似之处。我们将在下文详细讨论 StateSynchronizer 如何确定输入顺序以及和传统模型的差别。
如果读者仔细阅读过 StateSynchronizer 的源代码,就会发现 StateSynchronizer 接口内定义有一个名为UpdateGenerator的函数式接口。UpdateGenerator接口本质上是一个二元消费者:它接受两个参数,其中一个是StateT类型的当前共享状态,另一个是以List形式存在在更新操作(Update类型)列表,而列表内 的更新操作最终都将被持久化到相应的 stream 上。从概念上看,UpdateGenerator接口其实就是公式 2 的等价实现。
在传统的数据库模型中,数据库的服务器端负责维护一个全局的持久化的共享状态,即数据库中所有数据所组成的一个集合。多个独立的客户端同时向服务器端提交更新操作(事务),更新操作作用于共享状态上引起状态改变,而客户端本地不存储任何状态。在这个模型中,服务器端的共享状态无论从逻辑上看还是从物理上看,它都是共享的(这与 StateSynchronizer 的共享状态有很大的不同):因为几乎所有的数据库系统都允许多个事务并发执行。从形式化的角度看,所谓“事务 ui和 uj是并发的”指的是它们既不满足 ui ≺ uj 关系,也不满足 uj ≺ ui 关系,即 ui 的作用对 uj不完全可见,并且 uj的作用对 ui也不完全可见 [13]。可以不是很精确地将并发理解为:ui和 uj之间无法确定顺序。也可以从直觉上这样理解:ui和 uj的执行,在时间上存在重叠部分。并发直接导致了数据一致性问题。传统数据库模型解决并发问题的手段是设置事务的隔离级别 [26]:并发事务在不同的隔离级别下有着不同的可见性。
StateSynchronizer 摈弃了传统的数据库模型,从一个完全不同的角度解决并发问题和状态机输入顺序问题。其核心思想是,StateSynchronizer 的服务器端只存储(持久化)了更新操作本身而不是共享状态,共享状态由每个客户端独立维护,如 2.2.1 小节所述。由于 StateSynchronizer 架构中并不存在物理上的共享状态,因此不会因为状态共享而导致竞争,也不会因此产生并发问题。对于每一个 StateSynchronizer 的客户端而言,所有的更新操作都是顺序地作用于本地的共享状态副本(物理上顺序执行),这也不存在并发问题。
但是,单凭这一点还不足以保证共享状态的一致性,除非能够保证唯一的更新操作应用顺序。StateSynchronizer 的服务器端用单 segment 的 stream 存储了所有的更新操作:每一个更新操作作为一个 event 被持久化 [^5]。Stream 的最大特性就是只允许追加:所有的 event 写入操作只允许在尾部进行(原子操作),并且一个 event 一旦写入就不允许修改。这一特性不仅使得多个 writer 可以同时进行写入并且保持一致性,还使得所有 event 的顺序得以唯一确定,即每个 event 最终在 Segment 内的相对顺序。所以,对于每一个 StateSynchronizer 客户端来说,都能够看见一个一致的有序的更新操作视图。
细心的读者可能还希望进一步了解服务器端的 stream 是如保持只允许追加的特性和一致性的。与 Kafka 的消息代理节点(Broker)直接用本地文件系统存储 stream 数据的方法不同,Pravega 的消息代理节点将数据的存储完全交由一个抽象的存储层代理,包括数据副本的维护。目前已经支持的具体存储层实现包括:BookKeeper [27],HDFS [28],Extended S3 [29],NFS [30] 等等。也就是说,数据副本的实现对消息代理节点来说是完全透明的。具体的 segment 分层存储设计细节已经超出本文的讨论范围,感兴趣的读者可以自行阅读 Pravega 的相关文档 [31]。
StateSynchronizer 的这种数据模型其实非常类似 Change Data Capture(CDC) [32] 和 Event Sourcing [33] 的设计模式:不存储系统状态,而是通过推导计算得出 [13]。以 stream 形式存在的更新操作其实可以看作是系统状态的另一种视图。从这一视图出发,不仅能够推导出系统的最终状态,还可以得出系统在历史任意时刻的状态。
为了让所有的更新操作本身都能被持久化到 stream 中,StateSynchronizer 要求所有的更新操作都以类的形式实现,封装好所有所需的状态并且支持序列化 / 反序列化。这一点从StateSynchronizer的接口定义上也可以反映出来:创建一个StateSynchronizer实例必须提供两个Serializer接口实例,分别用于对更新操作和起始状态作序列化 / 反序列化,并且UpdateGenerator接口的定义要求所有更新操作必须实现Update接口。
将更新操作本身持久化到相应的 stream 中是 StateSynchronizer 实现更新操作接口的重要步骤之一,因为只有这样才能使所有的 StateSynchronizer 客户端都看见一个全局唯一的更新操作序列。目前,StateSynchronizer 支持以两种不同的模式将更新操作持久化到 stream 端:条件写模式(Conditionally Write)与无条件写模式(Unconditionally Write)。这两种更新模式分别有各自的适用场景。
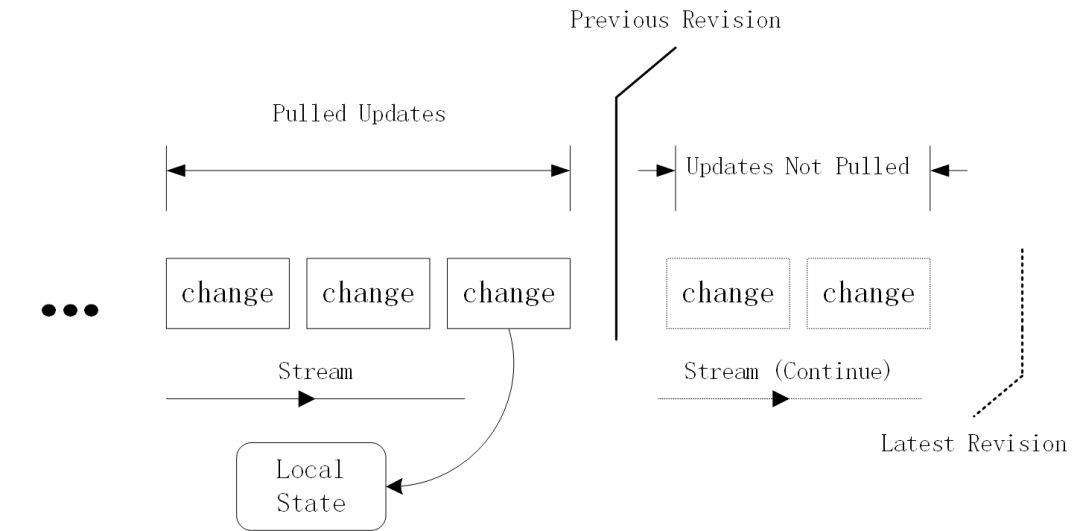
图 2 条件写示意图 每个矩形框代表已经持久化到 stream(右侧为尾端)中的一个更新操作。实线框为已经累积到当前某个 StateSynchronizer 客户端本地状态的更新操作,而虚线框为尚未作用到本地状态的更新操作,即:其它 StateSynchronizer 客户端提交但尚未被当前 StateSynchronizer 客户端拉取的更新操作。两条竖线分隔符分别对应当前 StateSynchronizer 客户端所见的 Revision 以及此时真正的最新 Revision。只要存在虚线框所示的更新操作,或者说只要当前 StateSynchronizer 客户端所见的 Revision 不是最新,那么条件写操作就无法成功完成。
在条件写模式下(参考StateSynchronizer接口上updateState()方法的实现),当 StateSynchronizer 客户端尝试把一个更新操作写入 stream 内时需要首先检查当前本地的共享状态是否是对应 stream 上的最新状态。如果是,则写入成功,可以继续将该更新操作作用于本地的共享状态并更新为新状态;如果不是,说明已经有其它的客户端抢先往 stream 中写入了其它更新操作,此时本地的共享状态已经“过期”,本次写入失败,如图 2 所示。对于写入失败的情况,StateSynchronizer 会自动尝试从 stream 拉取所有缺失的更新,并将所有拉取到的更新顺序作用于当前本地共享状态以便将其更新到最新状态,然后重试条件写。这一“失败 - 重试”的过程可能重复多次,直至写入成功。从概念上看,条件写表现出的行为与多线程编程中的 CAS 操作有着诸多相似之处。
如果读者仔细思考条件写的实现细节,不难得出如下的结论:检查状态是否过期与实际的 stream 写入动作必须是一个整体的原子操作,否则将出现竞争条件。事实上,检查状态是否过期这一动作并不是在客户端进行的,而是由 stream 的相关接口直接代理的,否则很难与发生在服务器端的写入动作合并为一个原子操作。在阅读过 StateSynchronizer 实现类StateSynchronizerImpl的源代码之后,读者会发现一个名为client的RevisionedStreamClient类型成员。RevisionedStreamClient是 StateSynchronizer 客户端用来与后端 stream 交互的唯一入口,所有 stream 的读写操作都通过该接口进行,包括条件写。RevisionedStreamClient接口上有一个名为writeConditionally()的方法(即条件写的真正实现),允许在写入一个 event 的同时指定一个 Revision。
正如其名字所暗示的那样,Revision接口可以近似理解为 stream 的“版本”:每次成功的写入操作都会导致对应 stream 的 Revision 发生变化,writeConditionally()方法甚至还直接返回该 Revision 以方便客户端用作多版本并发控制。现在继续讨论writeConditionally()方法的行为,只有当 stream 的当前的实际 Revision 与指定的 Revision 相同时(即:从上次成功条件写入到目前为止都没有其它的成功写入发生),真正的写入动作才发生,否则写入失败。很明显,这是一个典型的乐观并发控制模式。
聪明的读者甚至还可以从物理实现角度理解 Revision。从 2.2.1 小节的讨论中我们知道,Revision 是基于 segment 内的偏移量实现的,而 segment 本质上就是一个无边界的字节流。所谓 stream 的“版本”其实就是 stream 当前尾端的偏移量。由于 stream 只允许追加的特性,往指定偏移位置执行写入操作时,只有当该偏移确实处于尾端时才能成功。图 2 中所标记的 Revision 既可以看作是当前本地共享状态所对应的 stream 版本,也可以看作是当前 StateSynchronizer 客户端所看见的 stream 尾部位置。从这个角度看,stream 的特性和操作得到了统一。
由于条件写的失败 - 重试机制,在某些极端场景下(例如更新操作极度频繁引起的激烈竞争),可能导致较多次数的重试。并且由于条件写操作目前并未实现公平机制,理论上可能出现某个客户端“饥饿”的情况。为应对这种场景,StateSynchronizer 还提供了另一种持久化模式:无条件写模式。在无条件写模式下(参考StateSynchronizer接口上updateStateUnconditionally()方法的实现),StateSynchronizer 客户端往 stream 写入更新操作时并不会要求比较 Revision,而是无条件地将该更新操作写入当前 stream 的实际尾端,并且在写入成功后也不会更新本地的共享状态。
从实现上看,无条件写模式下的更新动作其实就是一个简单的 stream 追加动作。在服务和资源正常的情况下,stream 的追加写入总是能够成功的。如果调用者希望得到更新操作作用后的共享状态,则还需要手动拉取一次更新(参考StateSynchronizer接口上的fetchUpdates()方法)。由于更新操作的件写入动作与拉取动作之间存在时间窗口,在这段时间内可能已经有其它的客户端继续写入新的更新操作。因此,在拉取得到的更新操作序列上,并不能保证之前提交的更新操作是该序列上的最后一个元素。
也就是说,在应用该更新操作之前和之后,可能有其它的更新操作已经作用或继续作用在当前本地共享状态上。相反,条件写模式却总是能保证所提交的更新一定是最后一个作用在当前本地共享状态上的操作。根据具体应用场景的不同,这可能是个问题,也可能不是。例如,在无条件写模式下,所有的更新操作现在都变得不可观测了:假设你执行了一个无条件的更新操作,往一个共享的集合里面添加了一个元素。现在,哪怕你立刻进行集合遍历,也不能保证你一定能够找到刚刚添加的元素,因为可能存在其它客户端提交的后续更新操作已经将刚刚添加的元素删除了。这恐怕是一种与直觉相违背的行为表现。
总之,与条件写相比,无条件写有着优异的并发性能,但是这一切都是有代价的,例如:牺牲了开发者的可理解性。
StateSynchronizer 的更新操作模型(2.2.2 小节)要求所有更新操作的实现必需是确定性的,因为所有的更新操作都会在每一个 StateSynchronizer 客户端被重放。对于相同的输入,如果更新操作本身不能够产生确定性的结果,即使以完全相同的顺序在每一个客户端被执行,也会破坏共享状态的最终一致性。根据实际业务场景的不同,这一要求可能是一个问题,也可能不是,例如:
不可以使用随机函数。这一看似简单的要求实际上限制了不少可能性,很多科学计算依赖随机函数。
不可以使用绝大多数的本地状态,例如:本地时间,本机硬件信息等。
引用任何外部系统的状态都需要格外小心可能引入的不一致。例如,如果一个外部系统的状态会随时间变化,各个客户端可能看到各不相同的外部状态,因为同一个更新操作在每个客户端被执行的时间点是不确定的。
除了保证更新操作的确定性之外,还需要特别注意更新操作的执行是否具有“副作用”,例如:引发全局状态或外部系统状态的改变。如果回答是肯定的,那么还需要特别注意这些引发状态改变的动作接口是否具有幂等性 [34],因为同一个更新操作不仅会在每个客户端被执行,即使在同一客户端也可能被执行多次(2.2.4 小节)。
有人担心 StateSynchronizer 是否存在丢失更新问题 [6]。丢失更新问题一般在如下场景发生:两个进程并发地对同一共享变量进行“读取 - 修改 - 写入”组合操作。如果这一组合操作不能够被作为一个原子操作完成,那么后写入的状态有可能覆盖另一个写入操作的结果,导致其中一个修改结果(更新)“丢失”。如 2.2.3 小节所述,所有的更新操作都是在 StateSynchronizer 的客户端本地顺序执行的,因此不存在并发修改共享状态的场景,也不会产生更新丢失问题。
虽然 StateSynchronizer 客户端保证了以并发安全的方式执行所有更新操作,但是,一个不正确实现的更新操作仍有可能导致更新丢失问题。如果一个应用需要实现“读取 - 修改 - 写入”组合操作,唯一正确的做法是将所有的读取,修改和写入动作都封装在同一个更新操作中,即按如下伪代码所示实现更新操作 un :
un:
> 读取状态 sn;
> 执行修改;
> 生成并返回新状态 sn+1;
源代码 1 用伪代码表示的更新操作一般实现
一种常见的错误是在更新操作 un外部进行“读取状态 sn”和“执行修改”动作,并将新状态 sn+1直接封装进更新操作 un。另一种不那么直观的错误是,尽管将“读取”,“修改”和“写入”动作都封装进了同一个更新操作,但是在进行“读取状态 sn”动作时有意或无意地使用了某种缓存机制,即并非每次都从 StateSynchronizer 获取当前共享状态 sn。这两种错误的实现都将导致很严重的丢失更新问题。2.2.4 小节的相关讨论解释了其中的原因:由于条件写操作可能失败并重试多次,并且每次重试都意味着 StateSynchronizer 客户端本地的共享状态已经改变,任何缓存或者等价的行为都将导致实际的“执行修改”动作作用在一个已经过期的旧状态上,从而导致丢失更新问题。
在每一个 StateSynchronizer 客户端上,所有的更新操作都是顺序执行并作用在本地共享状态上的,正所谓“解决并发问题最简单的办法就是完全消除并发” [13]。有人担心更新操作的顺序执行是否会显著降低系统性能。从目前已有的研究看,用单线程的方式执行所有事务是完全可行的 [35],并且在很多现有的数据库实现中已经被采用,例如:VoltDB/H-Store [36],Redis [37],Datomic [38] [39] 等。当然,这对事务本身以及数据集都有所要求 [13],例如:
每个事务必须足够小,并且足够快。
数据集的活跃部分必须足够小,以便能够全部载入物理内存。否则,页面的频繁换入和换出会引起大量的磁盘 IO 操作,导致事务频繁阻塞。
写操作的吞吐量必须足够小,以便单 CPU 核心可以有足够的能力处理。否则,CPU 运算能力将成为瓶颈。
对于一个 StateSynchronizer 应用来说,无论是共享状态还是更新操作的设计实现,都必须遵循上述要求。
每一个 StateSynchronizer 客户端在进行启动后的首次更新操作时,都需要从对应的 stream 拉取所有的历史更新操作,并重放这些操作以便得到当前最新的共享状态。如果这是一个长时运行的共享状态,那么 stream 内此时可能已经累积了相当数量的更新操作。拉取并重放所有这些更新操作可能需要消耗大量的时间与资源,造成首次更新性能低下。为了应对这种场景,StateSynchronizer 还提供了所谓的状态压缩机制。状态压缩(compact)是一个特殊的StateSynchronizer接口方法,它允许将 StateSynchronizer 客户端的本地共享状作为一个新的起始状态,用条件写模式重新写入 stream[^6],并且使用 stream 的 mark 机制标记该起始状态的最新位置 [^7]。StateSynchronizer 客户端每次拉取更新操作时,都会首先尝试使用 mark 机制定位到最新的起始状态并忽略所有之前的更新操作,从而避免了长时间的历史重放。
如果首次更新操作的性能对于应用程序来说非常重要,那么开发者可以选择周期性地进行状态压缩。那么首次更新操作所要拉取和应用的更新操作数量则不会多于一个周期内所累积的更新操作数量,这将大大提升首次更新操作的性能。
本文主要从状态共享和一致性的角度出发,详细描述了 Pravega 的状态同步组件 StateSynchronizer 的工作机制和实现细节。StateSynchronizer 支持分布式环境下的多进程同时读写共享状态,并提供一致性保证。StateSynchronizer 具有典型的客户端 / 服务器架构,但是却非常轻量和高效,因为服务器端仅仅用于提供存储媒介。StateSynchronizer 的核心工作机制可以归纳为两个关键点:维护本地共享状态和只存储更新操作本身。StateSynchronizer 利用 stream 的天然特性实现了更新操作的全局有序。StateSynchronizer 还提供了条件写和无条件写两种更新写入模式,可以适用于并发度极高的场景。StateSynchronizer 未来的工作可能集中在如何向开发者提供更加便捷易用的编程接口,以减轻开发者的负担。
Pravega 根据 Apache 2.0 许可证开源,0.4 版本 已于近日发布。我们欢迎对流式存储感兴趣的大咖们加入 Pravega 社区,与 Pravega 共同成长。本篇文章为 Pravega 系列第五篇,系列文章如下:
高并发下新的分布式一致性解决方案 (StateSynchronizer)
Pravega 的仅一次语义及事务支持
与 Apache Flink 集成使用
蔡超前:华东理工大学计算机应用专业博士研究生,现就职于 Dell EMC,6 年搜索和分布式系统开发以及架构设计经验,现从事流相关的设计与研发工作。
滕昱:现就职于 Dell EMC 非结构化数据存储部门 (Unstructured Data Storage)团队并担任软件开发总监。2007 年加入 Dell EMC 以后一直专注于分布式存储领域。参加并领导了中国研发团队参与两代 Dell EMC 对象存储产品的研发工作并取得商业上成功。从 2017 年开始,兼任 Streaming 存储和实时计算系统的设计开发与领导工作。
[1] "Pravega," Dell EMC, [Online]. Available: https://github.com/pravega/pravega.
[2] "Working with Pravega: State Synchronizer," Dell EMC, [Online]. Available: https://github.com/pravega/pravega/blob/master/documentation/src/docs/state-synchronizer.md.
[3] "Pravega Concepts," Dell EMC, [Online]. Available: https://github.com/pravega/pravega/blob/master/documentation/src/docs/pravega-concepts.md.
[4] H. T. Kung and J. T. Robinson, "On optimistic methods for concurrency control," ACM Transactions on Database Systems, vol. 6, no. 2, pp. 213-226, 1981.
[5] P. A. Bernstein and N. Goodman, "Concurrency Control in Distributed Database Systems," ACM Computing Surveys, vol. 13, no. 2, pp. 185-221, 1981.
[6] "Concurrency Control," Wikipedia, [Online]. Available: https://en.wikipedia.org/wiki/Concurrency_control.
[7] "Multiversion Concurrency Control," Wikipedia, [Online]. Available: https://en.wikipedia.org/wiki/Multiversion_concurrency_control.
[8] P. Viotti and M. Vukolić, "Consistency in Non-Transactional Distributed Storage Systems," ACM Computing Surveys (CSUR), vol. 49, no. 1, 2016.
[9] P. Bailis, A. Davidson, A. Fekete, A. Ghodsi, J. M. Hellerstein and I. Stoica, "Highly available transactions: virtues and limitations," in Proceedings of the VLDB Endowment, 2013.
[10] M. P. Herlihy and J. M. Wing, "Linearizability: a correctness condition for concurrent objects," ACM Transactions on Programming Languages and Systems (TOPLAS) , vol. 12, no. 3, pp. 463-492, 1990 .
[11] "Apache ZooKeeper," [Online]. Available: https://zookeeper.apache.org/.
[12] "etcd (GitHub Repository)," [Online]. Available: https://github.com/etcd-io/etcd.
[13] M. Kleppmann, Designing Data-Intensive Applications, O’Reilly Media, 2017.
[14] F. P. Junqueira, B. C. Reed and M. Serafini, "Zab: High-performance broadcast for primary-backup systems," In DSN, pp. 245-256, 2011.
[15] D. Ongaro and J. Ousterhout, "In search of an understandable consensus algorithm," in Proceedings of the 2014 USENIX conference on USENIX Annual Technical Conference, Philadelphia, 2014.
[16] "StateSynchronizer Related Source Code in Pravega GitHub Repository," Dell EMC, [Online]. Available: https://github.com/pravega/pravega/tree/master/client/src/main/java/io/pravega/client/state.
[17] M. Hazewinkel, Ed., Encyclopaedia of Mathematics (set), 1 ed., Springer Netherlands, 1994.
[18] L. Lamport, "Time, clocks, and the ordering of events in a distributed system," Communications of the ACM, vol. 21, no. 7, pp. 558-565, 1978.
[19] "Happened-before," Wikipedia, [Online]. Available: https://en.wikipedia.org/wiki/Happened-before.
[20] "StateSynchronizer Interface Definition (v0.4)," Dell EMC, [Online]. Available: https://github.com/pravega/pravega/blob/r0.4/client/src/main/java/io/pravega/client/state/StateSynchronizer.java.
[21] P. A. Gagniuc, Markov Chains: From Theory to Implementation and Experimentation, New Jersey: John Wiley & Sons, 2017.
[22] F. B. Schneider, "Implementing fault-tolerant services using the state machine approach: a tutorial," ACM Computing Surveys, vol. 22, no. 4, pp. 299-319, 1990.
[23] L. Lamport, "The part-time parliament," ACM Transactions on Computer Systems, vol. 16, no. 2, pp. 133-169, 1998.
[24] L. Lamport, "Paxos Made Simple," SIGACT News, vol. 32, no. 4, pp. 51-58, 2001.
[25] X. Défago, A. Schiper and P. Urbán, "Total order broadcast and multicast algorithms: Taxonomy and survey," ACM Computing Surveys, vol. 36, no. 4, pp. 372-421, 2004.
[26] H. Berenson, P. Bernstein, J. Gray, J. Melton, E. O'Neil and P. O'Neil, "A critique of ANSI SQL isolation levels," in Proceedings of the 1995 ACM SIGMOD international conference on Management of data, San Jose, California, USA, 1995.
[27] "Apache BookKeeper," [Online]. Available: https://bookkeeper.apache.org/.
[28] "Apache Hadoop," [Online]. Available: https://hadoop.apache.org/.
[29] "Amazon S3," Amazon, [Online]. Available: https://aws.amazon.com/s3/.
[30] "NFS version 4.2 (RFC 7862)," [Online]. Available: https://tools.ietf.org/html/rfc7862.
[31] "Pravega Segment Store Service (v0.4)," Dell EMC, [Online]. Available: https://github.com/pravega/pravega/blob/r0.4/documentation/src/docs/segment-store-service.md.
[32] "Change Data Capture," Wikipedia, [Online]. Available: https://en.wikipedia.org/wiki/Change_data_capture.
[33] M. Fowler, "Event Sourcing," 12 12 2005. [Online]. Available: https://martinfowler.com/eaaDev/EventSourcing.html.
[34] "Idempotence," Wikipedia, [Online]. Available: https://en.wikipedia.org/wiki/Idempotence.
[35] M. Stonebraker, S. Madden and D. J. Abadi, "The End of an Architectural Era (It’s Time for a Complete Rewrite)," in Proceedings of the 33rd international conference on Very large data bases, Vienna, 2007.
[36] R. Kallman, H. Kimura and J. Natkins, "H-Store: A High-Performance, Distributed Main Memory Transaction Processing System," Proceedings of the VLDB Endowment, vol. 1, no. 2, pp. 1496-1499, 2008.
[37] "Redis," [Online]. Available: https://redis.io/.
[38] R. Hickey, "The Architecture of Datomic," 2 11 2012. [Online]. Available: https://www.infoq.com/articles/Architecture-Datomic.
[39] "Datomic Cloud," Cognitect, Inc., [Online]. Available: https://www.datomic.com/.
[^2]: 在有关分布式系统的文献中,习惯上用“进程(Process)”指代一组可以在集群内不同机器上运行的进程,而不一定局限于本地机器。工程上则常常使用“节点”表达类似的含义。在不会引起歧义的上下文环境中,本文将不再试图对这两个术语做出区分。
[^3]: 事实上,StateSynchronizer 的现有实现已经可以支持串行化(Serializable)的事务。
[^4]: 一个典型的例子就是,即使是单机版本的关系型数据库,也需要提供事务支持以便满足不同的隔离级别(一致性需求)。
[^5]: 仔细阅读过源代码的读者会发现,StateSynchronizer 事实上还支持将同一个客户端本地的一组有序更新操作作为一个 event 提交,但这并不影响我们讨论的正确性,因为我们可以把这一组更新操作视作一个逻辑上的更新操作。
[^6]: 事实上,所有的起始状态都是作为一个特殊的更新操作(InitialUpdate)写入 stream 的。StateSynchronizer 客户端在拉取更新操作时能够区分 InitialUpdate 与普通更新操作,并做相应处理。
[^7]: 有关 mark 机制的实现已经超出本文范围,感兴趣的读者可以参考相应的说明文档。
今日荐文
30年前他发明了万维网,现在他要颠覆互联网
喜欢这篇文章吗?点一下「好看」再走 以上是关于取代ZooKeeper!高并发下的分布式一致性开源组件StateSynchronizer的主要内容,如果未能解决你的问题,请参考以下文章