如此火爆的ZooKeeper,到底如何选主?
Posted 架构之美
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如此火爆的ZooKeeper,到底如何选主?相关的知识,希望对你有一定的参考价值。
前言
Leader选举流程概述
我们本篇文章的目的就是详细的剖析Leader选举的过程,但是Leader选举的过程较为复杂,我们直接上来就讲其详细的过程,大家容易蒙圈,所以我们这一小段就简单描述一下Leader选举的大概流程。
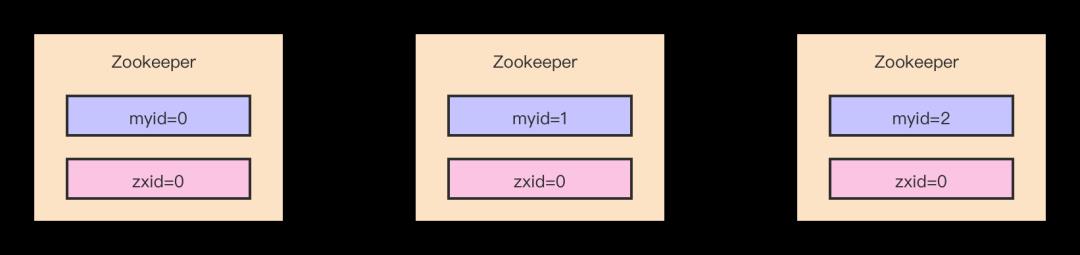
如上图所以,假设我们目前有一个3个节点构成的ZooKeeper集群,myid的编号分别是0,1,2,又因为集群当前是一个空的集群,所以每个节点的ZXID初始都为0,该集群启动的时候Leader的选举流程如下:
(1)我们首先启动myid为0的服务,但是目前只有一台ZooKeeper服务,所以是无法完成Leader选举的,ZooKeeper集群要求Leader进行投票选举条件是至少有2台服务才行,不然都没法进行通信投票。
(2)启动myid为1的服务,第二台启动了以后,这两台ZooKeeper就可以相互通信了,接下来就可以进行投票选举了。
(3)2台ZooKeeper进行投票选举的时候,第一次都是推荐自己为Leader,投票包含的信息是:服务器本身的myid和ZXID。比如第一台投自己的话,它会发送给第二台机器的投票是(0,0),第一个0代表的是机器的myid,第二个0代表是的ZXID。故两台机器收到的投票情况如下:
第一台:(1,0)
第二台:(0,0)
(4)两台服务器在接收到投票后,将别人的票和自己的投票进行PK。PK的是规则是:
(a)优先对比ZXID,ZXID大的优先作为Leader(ZXID大的表示数据多)
(b)如果ZXID一样的话,那么就比较myid,让myid大的作为Leader服务器。
那根据这个规则的话,第一台服务器,接受到的投票是(1,0),跟自己的投票(0,0)比,ZXID是一样的,但是myid比接收到的投票的小,所以第一台原先是推荐自己投票为(0,0),现在进行了PK以后,投票修改为(1,0)。第二台服务器,接受到的投票是(0,0),跟自己的投票(1,0)比,ZXID是一样的,但是myid是比接受到的投票的大,所以坚持自己的投票(1,0)。两台服务器再次进行投票。
(5)每次投票以后,服务器都会统计所有的投票,只要过半的机器投了相同的机器,那么Leader就选举成功了,上面的两台服务器进行第二次投票之后,两台服务器都会收到相同的投票(1,0)。那么此时myid为1的服务器就是Leader了。
Leader选举的详细流程
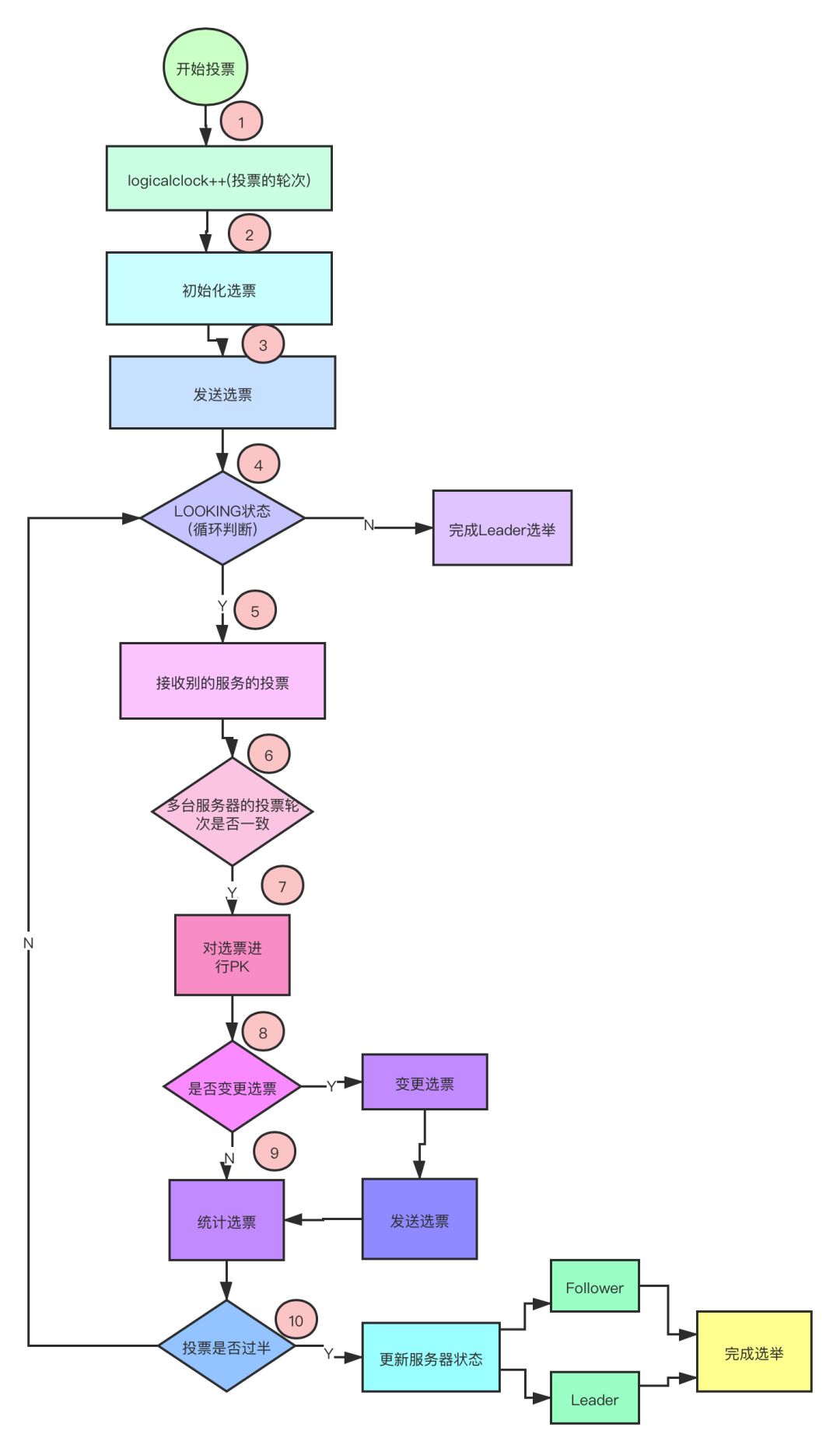
如上图是ZooKeeper选举的核心算法逻辑图,接下来我们详细的看一下其选举流程。
0x01 投票轮次递增
用于标识当前投票的轮次,ZooKeeper规定了同一轮次的投票才是有效的。所以如果要进行新一轮的投票,需要对投票轮次进行递增。
0x02 初始化选票
在投票之前每台服务器都会初始化自己的选票,选票里面最重要的两个值一个是本机的myid的值,一个是本机的ZXID的值。
0x03 发送初始化选票
完成选票的初始化以后,服务器就会发起第一次投票,第一次投票都是推荐自己为Leader,也就是都投自己。
0x04 判断服务状态
ZooKeeper的服务有四个状态:LOOKING, FOLLOWING, LEADING, OBSERVING
LOOKING:寻找Leader的状态。
FOLLOWING:跟随者状态。
LEADING:领导者状态。
OBSERVING:观察者状态。
如果当前服务的状态是LOOKING,那么说明还没选举出来Leader,继续下面的步骤,正常情况下一开始都是LOOKING的状态。
0x05 接受外部选票
每台服务器会不断的从某个队列里面获取外部的选票。如果发现服务器无法获取外部的任何选票,那么就会立即确认自己是否和集群中的其他服务器保持着有效连接。如果发现没有建立连接,那么立马建立连接。如果已经建立连接了,那么再次发送自己的投票。
0x06 判断选举轮次
发送完初始化选票以后,接下来就要处理外部的选票了,处理选票的时候会根据不同轮次的选票进行不同的处理。
6.1 外部投票的选举轮次大于自己的轮次
如果发现自己的投票轮次小于外部的轮次,那么立即更新自己的轮次,然后清空已经接收到的选票。然后使用初始化的选票来PK刚刚的外部投票以确定是否变更自己的投票(PK的规则跟概述里描述一致)。
6.2 外部投票的选举轮次小于自己的轮次
如果接收到的选票的选举轮次落后与服务器本身的轮次,那么直接忽略该外部选票,不做任何处理。
6.3 外部投票的选举轮次等于自己的轮次
大多数属于这个情况,如果外部的选票的轮次跟自己的选票轮次一致的话,就进行选票PK。
0x07 选票PK
(a)优先对比ZXID,ZXID大的优先作为Leader。
(b)如果ZXID一样的话,那么就比较选票里的myid,myid大的选为Leader。
0x08 变更选票
通过选票PK以后,如果确定了别的服务的选票优于自己的选票,那么就进行选票变更,把自己的选票信息变更为更适合作为Leader的服务器的选票信息。然后再把这些选票发送出去。不过无论是否发生了选票变更,当前的服务都会将刚刚接收到的选票进行归档并按照服务器的myid来区分,如:{(0,vote1),(1,vote2),....}
0x09 统计投票
完成了选票归档之后,就可以统计选票了,说白了就是看是否有过半的服务器认为某台服务器适合做Leader,如果确定了则终止投票。否者返回步骤(4)。
0x0A 更新服务状态
统计投票后,如果已经确定出来Leader就终止投票,接下来就变更服务的状态,首先看一下自己是不是Leader,如果自己是Leader那么就更新自己的状态为Leader,如果不是Leader,那么就根据配置文件,要么切换为Follower,要么切换为Observer。
以上10个步骤就是ZooKeeper选举的核心算法,其中4-9会经过几轮循环直到Leader产生。
最后
ZooKeeper是我们学习架构的过程中必不可少的一个技术,今天主要跟大家讲解了ZooKeeper的Leader选举算法,后面会陆续剖析ZooKeeper的ZAB协议算法,数据快照机制,数据清理机制,会话机制,长连接机制等。欢迎大家持续关注。
大家加油!!!
以上是关于如此火爆的ZooKeeper,到底如何选主?的主要内容,如果未能解决你的问题,请参考以下文章
zookeeper使用curator进行选主(Leader)
简述 zookeeper 基于 Zab 协议实现选主及事务提交