分布式之Zookeeper核心原理详解
Posted 斯猿
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分布式之Zookeeper核心原理详解相关的知识,希望对你有一定的参考价值。
前言
上一篇:我们对于一致性算法有一定的了解,今天我们来一起学习一下Zookeeper的基础概念与核心原理,以及根据其核心原理去解决一些常见的分布式问题。
❝比如分布式锁、数据发布与订阅、命名服务、配置中心、注册中心等。
❞
本文主要对以下问题进行介绍:
-
zookeeper的基础信息概述。 -
zookeeper的核心原理是什么? -
Zab一致性协议 -
原子广播 -
Zab算法与Paxos算法的区别与联系 -
zookeeper的应用场景。
zookeeper的基础信息概述
集群角色概念、数据节点、Watcher、回话、版本、ACR权限控制
集群角色
-
Leader:Leader服务器是整个Zookeeper集群工作机制中的核心 -
Follower:Follower服务器是Zookeeper集群状态的跟随者 -
Observer:Observer服务器充当一个观察者的角色Leader,Follower 设计模式;Observer 观察者设计模式
会话
会话是指客户端和ZooKeeper服务器的连接,ZooKeeper中的会话叫Session,客户端靠与服务器建立一个TCP的长连接;来维持一个Session,客户端在启动的时候首先会与服务器建立一个TCP连接,通过这个连接,客户端能够通过心跳检测与服务器保持有效的会话,也能向ZK服务器发送请求并获得响应。
数据节点
Zookeeper中的节点有两类:
1、集群中的一台机器称为一个节点
2、数据模型中的数据单元Znode,分为持久节点和临时节点
Zookeeper的数据模型是一棵树,树的节点就是Znode,Znode中可以保存信息。
如下图所示:
ZK大致数据结构跟上图是一致的,如上图所示这个图就像一棵树,这个树有个根节点,然后其下有些子节点,然后每个子节点其下又可以有子节点,大多数的开发就是跟zk的这些数据节点打交道,来读写这些数据节点,来完成任务。
版本
ZK中的版本,是用来记录节点数据或者是节点的子节点列表或者是权限信息的修改次数,注意是这里是修改次数。如果一个节点的version是1,那就代表说这个节点从创建以来被修改了一次,那么这个版本怎么用呢,典型的我们可以利用版本来实现分布式的锁服务。我们知道在数据库中,一般有两种锁,一种是悲观锁一种是乐观锁。
悲观锁
悲观锁又叫悲观并发锁,是数据库中一种非常严格的锁策略,具有强烈的排他性,能够避免不同事务对同一数据并发更新造成的数据不一致性,在上一个事务没有完成之前,下一个事务不能访问相同的资源,适合数据更新竞争非常激烈的场景;
乐观锁
相比悲观锁,乐观锁使用的场景会更多,悲观锁认为事务访问相同数据的时候一定会出现相互的干扰,所以简单粗暴的使用排他访问的方式,而乐观锁认为不同事务访问相同资源是很少出现相互干扰的情况,因此在事务处理期间不需要进行并发控制,当然乐观锁也是锁,它还是会有并发的控制!对于数据库我们通常的做法是在每个表中增加一个version版本字段,事务修改数据之前先读出数据,当然版号也顺势读取出来,然后把这个读取出来的版本号加入到更新语句的条件中,比如,读取出来的版本号是1,我们修改数据的语句可以这样写,update 某某表 set 字段一=某某值 where id=1 and version=1,那如果更新失败了说明以后其他事务已经修改过数据了,那系统需要抛出异常给客户端,让客户端自行处理,客户端可以选择重试。锁,ZK中版本有类式的作用。
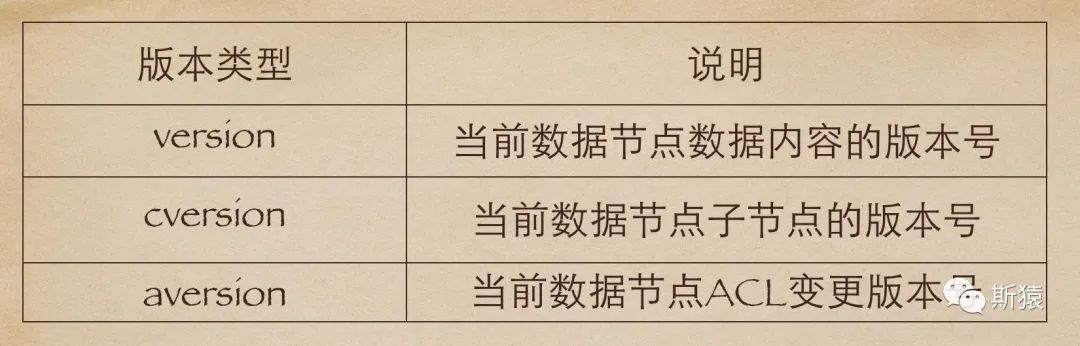
ZK的版本类型有三种:version cversion aversion
Watcher
Watcher我们可以理解为他是一个事件监听器
ZooKeeper允许用户在指定节点上注册一些Watcher,当数据节点发生变化的时候,ZooKeeper服务器会把这个变化的通知发送给感兴趣的客户端。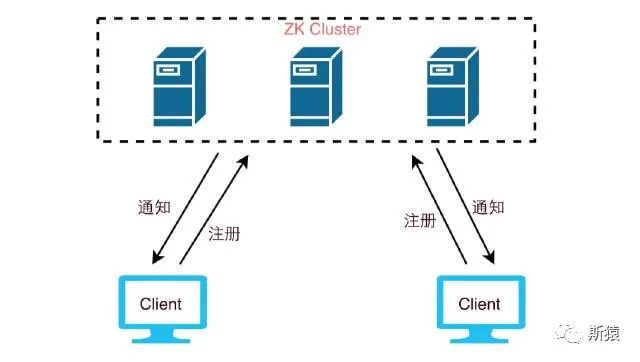 两个客户端都在zookeeper集群中注册了watcher(事件监听器),那么当zk中的节点数据发生变化的时候,zk会把这一变化的通知发送给客户端,当客户端收到这个变化通知的时候,它可以再回到zk中,去取得这个数据的详细信息。
两个客户端都在zookeeper集群中注册了watcher(事件监听器),那么当zk中的节点数据发生变化的时候,zk会把这一变化的通知发送给客户端,当客户端收到这个变化通知的时候,它可以再回到zk中,去取得这个数据的详细信息。
ACL权限控制
ACL是Access Control Lists 的简写, ZooKeeper采用ACL策略来进行权限控制,有以下权限:
-
CREATE: 创建子节点的权限
-
READ: 获取节点数据和子节点列表的权限
-
WRITE: 更新节点数据的权限
-
DELETE: 删除子节点的权限
-
ADMIN: 设置节点ACL的权限
上面的权限有点类似我们信息系统的权限管理,我们在开发系统的时候一般也会对数据做这些权限管理,一个zk集群可能会服务很多的业务,尤其是一些大公司,zk集群的节点中会保存重要的信息,那么这些信息通常只能对一部分的访问者开放,通过acl我们可以对某些节点的访问进行授权,从而来保证数据的安全。
Zab一致性协议
ZooKeeper是通过Zab协议来保证分布式事务的最终一致性。
Zab(ZooKeeperAtomicBroadcast,ZooKeeper原子广播协议)支持崩溃恢复,基于该协议,ZooKeeper 实现了一种主备模式的系统架构来保持集群中各个副本之间数据一致性。
系统架构可以参考下面这张图:
 在ZooKeeper集群中,所有客户端的请求都是写入到Leader进程中的,然后,由Leader同步到其他节点,称为Follower。在集群数据同步的过程中如果出现 Follower 节点崩溃或者 Leader 进程崩溃时,都会通过 Zab 协议来保证数据一致性。
在ZooKeeper集群中,所有客户端的请求都是写入到Leader进程中的,然后,由Leader同步到其他节点,称为Follower。在集群数据同步的过程中如果出现 Follower 节点崩溃或者 Leader 进程崩溃时,都会通过 Zab 协议来保证数据一致性。
❝那么Zab如何保证数据的一致性呢?
❞
Zab 协议中的 Zxid
Zxid是Zab协议的一个事务编号,Zxid是一个64位的数字,其中低32位是一个简单的单调递增计数器,针对客户端每一个事务请求,计数器加1;而高32位则代表Leader周期年代的编号。
这里Leader周期的英文是epoch,可以理解为当前集群所处的年代或者周期,对比另外一个一致性算法 Raft 中的 Term 概念。在 Raft 中,每一个任期的开始都是一次选举,Raft 算法保证在给定的一个任期最多只有一个领导人。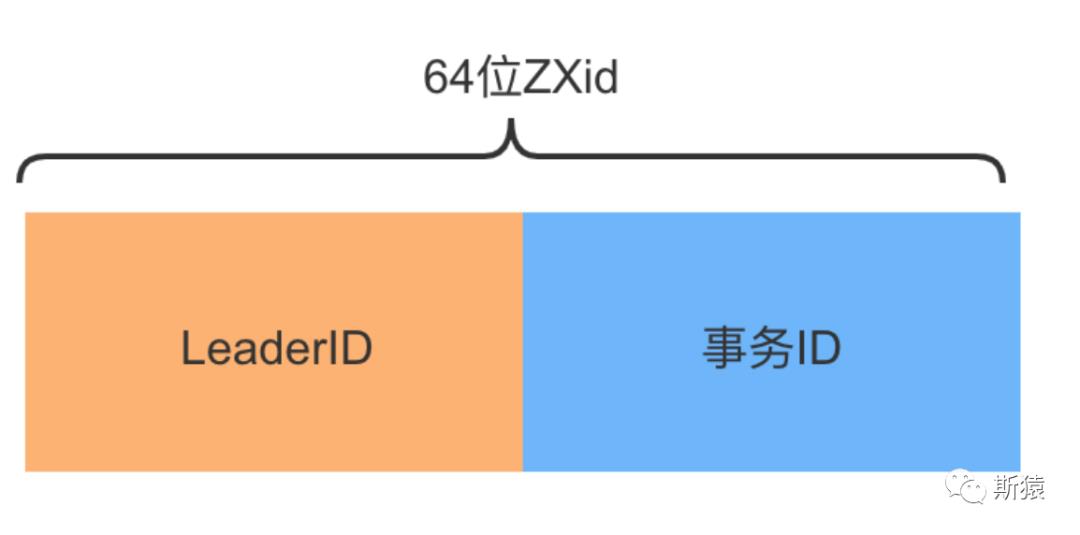
Zab协议的实现也类似,每当有一个新的Leader选举出现时,就会从这个Leader服务器上取出其本地日志中最大事务的Zxid,并从中读取epoch值,然后加1,以此作为新的周期 ID。
总结: 高 32 位代表了每代 Leader 的唯一性,低 32 位则代表了每代 Leader 中事务的唯一性。zab通过Zxid事务编号来保证其唯一性,从而保证数据一致性。
原子广播
原子广播就是保证各个server之间的同步,他的核心实现机制是ZAB协议。原子广播可以拆分为:
-
消息广播 -
崩溃恢复 -
数据同步

消息广播
在ZooKeeper中所有的事务请求都由Leader节点来处理,其他服务器为Follower,Leader将客户端的事务请求转换为事务Proposal,并且将 Proposal 分发给集群中其他所有的 Follower。
完成广播之后,Leader等待Follwer反馈,当有过半数的Follower反馈信息后,Leader将再次向集群内Follower广播Commit信息,Commit 信息就是确认将之前的 Proposal 提交。
这里的Commit可以对比SQL中的COMMIT操作来理解,mysql默认操作模式是autocommit自动提交模式,如果你显式地开始一个事务,在每次变更之后都要通过 COMMIT 语句来确认,将更改提交到数据库中。
Leader 节点的写入也是一个两步操作,第一步是广播事务操作,第二步是广播提交操作,其中过半数指的是反馈的节点数 >=N/2+1,N 是全部的 Follower 节点数量。
消息广播的过程描述可以参考下图:
-
客户端的写请求进来之后,Leader 会将写请求包装成 Proposal 事务,并添加一个递增事务 ID,也就是 Zxid,Zxid 是单调递增的,以保证每个消息的先后顺序;
-
广播这个Proposal事务,Leader节点和Follower节点是解耦的,通信都会经过一个先进先出的消息队列,Leader 会为每一个 Follower 服务器分配一个单独的 FIFO 队列,然后把 Proposal 放到队列中;
-
Follower 节点收到对应的 Proposal 之后会把它持久到磁盘上,当完全写入之后,发一个 ACK 给 Leader;
-
当 Leader 收到超过半数 Follower 机器的 ack 之后,会提交本地机器上的事务,同时开始广播 commit, Follower 收到 commit 之后,完成各自的事务提交。
总结:消息广播通过 Quroum 机制,解决了 Follower 节点宕机的情况,但是如果在广播过程中 Leader 节点崩溃呢?下面将会讲到崩溃回复。
崩溃恢复
崩溃恢复是可以保证在 Leader 进程崩溃的时候可以重新选出 Leader,并且保证数据的完整性。
❝什么情况下会出现崩溃恢复?
❞
-
集群启动的时候回出现 -
Leader 崩溃,因为故障宕机 -
Leader 失去了半数的机器支持,与集群中超过一半的节点断连
崩溃恢复模式将会开启新的一轮选举,选举产生的 Leader 会与过半的 Follower 进行同步,使数据一致,当与过半的机器同步完成后,就退出恢复模式, 然后进入消息广播模式。
❝崩溃恢复期间各个节点状态会发生什么变化?
❞
-
各个节点变更状态,变更为 Looking -
各个 Server 节点都会发出一个投票,参与选举 (第一次投票都是投自己) -
集群接收来自各个服务器的投票,开始处理投票和选举
选举过程其实就是对比Zid的过程,选取最大的Zid,也就是最新的数据。并且服从「过半原则」如果有节点票数过半,则成为新Leader,反之进入下一轮选举。具体交互流程如下图:
数据同步
崩溃恢复完成选举以后,接下来的工作就是数据同步,在选举过程中,通过投票已经确认Leader服务器是最大Zxid的节点,同步阶段就是利用 Leader 前一阶段获得的最新Proposal历史,同步集群中所有的副本。
zookeeper的应用场景
(2)NameService:作为分布式命名服务,通过调用zk的create node api,能够很容易创建一个全局唯一的path,这个path就可以作为一个名称。
(3)分布通知/协调:ZooKeeper 中特有watcher注册与异步通知机制,能够很好的实现分布式环境下不同系统之间的通知与协调,实现对数据变更的实时处理。使用方法通常是不同系统都对 ZK上同一个znode进行注册,监听znode的变化(包括znode本身内容及子节点的),其中一个系统update了znode,那么另一个系统能 够收到通知,并作出相应处理。使用zookeeper来进行分布式通知和协调能够大大降低系统之间的耦合。
(4)分布式锁:主要得益于ZooKeeper为我们保证了数据的强一致性,即用户只要完全相信每时每刻,zk集群中任意节点(一个zk server)上的相同znode的数据是一定是相同的。锁服务可以分为两类,一个是保持独占,另一个是控制时序。控制时序中Zk的父节点(/distribute_lock)维持一份sequence,保证子节点创建的时序性,从而也形成了每个客户端的全局时序。
(5)集群管理:①集群监控:a. 客户端在节点 x 上注册一个Watcher,那么如果x的子节点变化了,会通知该客户端。b. 创建EPHEMERAL类型的节点,一旦客户端和服务器的会话结束或过期,那么该节点就会消失。②Master选举:
利用ZooKeeper的强一致性,能够保证在分布式高并发情况下节点创建的全局唯一性,即:同时有多个客户端请求创建 /currentMaster 节点,最终一定只有一个客户端请求能够创建成功。
(6)分布式队列:一种常规先进先出,另一种待队列成员集齐后执行。
以上是关于分布式之Zookeeper核心原理详解的主要内容,如果未能解决你的问题,请参考以下文章