通俗易懂:一篇文章理解Python异步编程的基本原理
Posted 恋习Python
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了通俗易懂:一篇文章理解Python异步编程的基本原理相关的知识,希望对你有一定的参考价值。
本文要点:深入介绍一下 asyncio 是如何通过单线程单进程实现并发效果的,以及异步代码是不是能在所有方面都代替同步代码。
一些例子
第一个例子
实际上,在现实中你只需要消耗50分钟就可以了——
-
先给朋友打电话,让他现在出门 -
把衣服放进洗衣机并打开电源 -
把米淘洗干净,放进电饭煲并打开电源
然后,你要做的就是等待。
第二个例子
现在,你需要完成语文试卷,数学试卷和英语试卷。每张试卷需要做1小时。于是你需要1 + 1 + 1 = 3小时来完成所有的试卷。没人帮你,所以你没有办法在少于3小时的情况下完成这三张试卷。
第三个例子
现在,你需要用电饭煲煮饭、用洗衣机洗衣服,并完成一张数学试卷。其中,电饭煲需要30分钟才能把饭煮好,洗衣机需要40分钟才能把衣服洗好,试卷需要1小时才能完成。
但你并不需要30 + 40 + 60 = 130分钟。你只需要70分钟左右——
-
把衣服放进洗衣机并打开电源 -
把米淘洗干净,放进电饭煲并打开电源 -
开始完成试卷
能异步与不能异步
再看第二个例子,每一张试卷都会占用整个你,没有等待的时间,所以必须一张一张试卷完成。
这两个例子实际上对应了两种程序类型:I/O 密集型程序和计算密集型程序。
我们在使用 requests 请求 URL、查询远程数据库或者读写本地文件的时候,就是 I/O操作。这些操作的共同特点就是要等待。
以 request 请求URL 为例,requests 发起请求,也许只需要0.01秒的时间。然后程序就卡住,等待网站返回。请求数据通过网络传到网站服务器,网站服务器发起数据库查询请求,网站服务器返回数据,数据经过网线传回你的电脑。requests 收到数据以后继续后面的操作。
大量的时间浪费在等待网站返回数据。如果我们可以充分利用这个等待时间,就能发起更多的请求。而这就是异步请求为什么有用的原因。
但对于需要大量计算任务的代码来说,CPU 始终处于高速运转的状态,没有等待,所以就不存在利用等待时间做其它事情的说法。
所以:异步只适用于 I/O 操作相关的代码,不适用于非 I/O操作。
Python 的异步代码
上面我们使用生活中的例子来说明异步请求,这可能会给大家一种误解——我可以控制代码,让代码在我想让他异步的地方异步,不想异步的地方同步。例如,可能有人会希望能用下面这段伪代码所描述方式来写代码:
请求 https://baidu.com,在网站返回期间:
a = 1 + 1
b = 2 + 2
c = 3 + 3
拿到返回的数据,做其他事情
这段伪代码写得很符合直觉,但在使用 Python里面不能这样写。
下面我们用一段真正的代码,来说明这样写有什么问题。
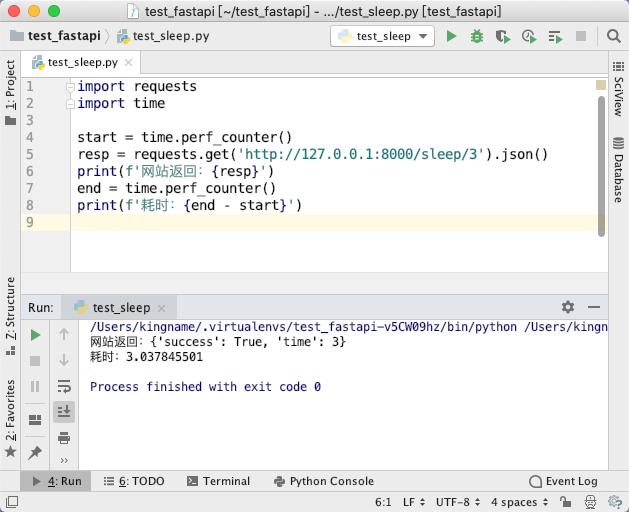
首先,我们做一个网站,当我们请求http://127.0.0.1:8000/sleep/<num>时,网站会等待num秒才会返回。例如:http://127.0.0.1:8000/sleep/3表示,当你发起请求后,网站会等待3秒钟再返回。运行效果如下图所示。
现在,我们使用 aiohttp 发送3次请求,分别等待1秒、2秒、3秒返回:
import aiohttp
import asyncio
import time
async def request(sleep_time):
async with aiohttp.ClientSession() as client:
resp = await client.get(f'http://127.0.0.1:8000/sleep/{sleep_time}')
resp_json = await resp.json()
print(resp_json)
async def main():
start = time.perf_counter()
await request(1)
a = 1 + 1
b = 2 + 2
print('能不能在第一个请求等待的过程中运行到这里?')
await request(2)
print('能不能在第二个请求等待的过程中运行到这里?')
await request(3)
end = time.perf_counter()
print(f'总计耗时:{end - start}')
asyncio.run(main())
运行效果如下图所示:
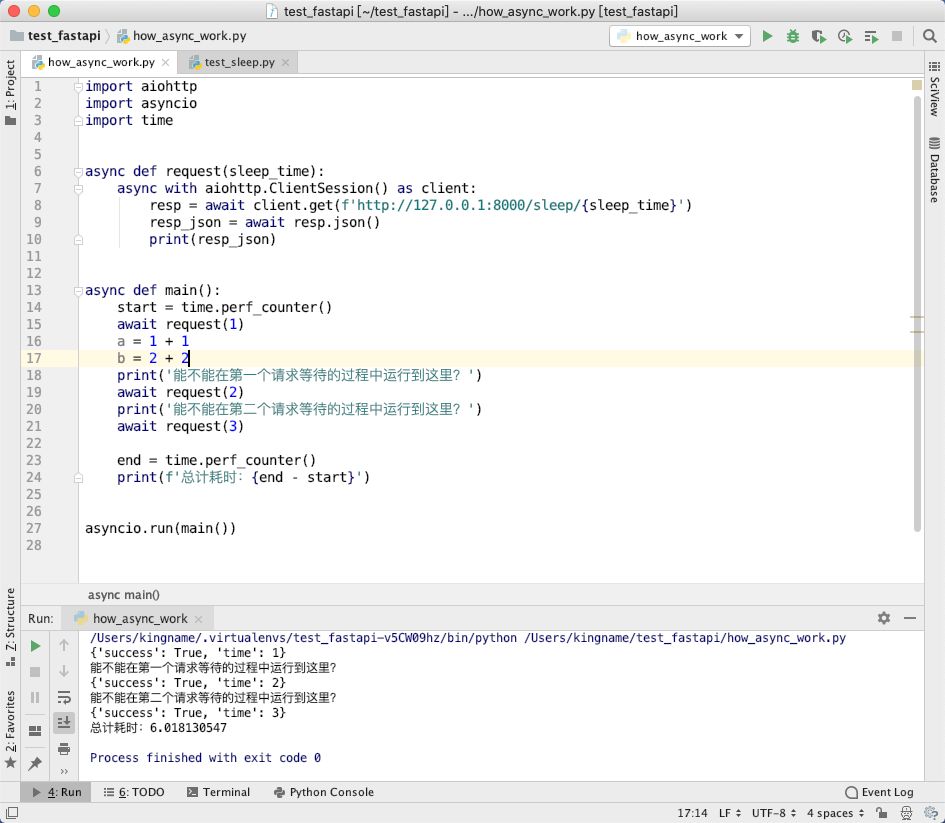
在图中第15行代码,发起了1秒的请求,那么第15行应该会等待1秒钟才会返回数据。而第16、17、18行都是简单的赋值和 print 函数,运行时间加在一起都显然小于1秒钟,所以理论上我们看到的返回应该是:
能不能在第一个请求等待的过程中运行到这里?
能不能在第二个请求等待的过程中运行到这里?
{'success': True, 'time': 1}
{'success': True, 'time': 2}
{'success': True, 'time': 3}
总计耗时:3.018130547
但实际上,我们看到的效果,却是:程序先运行到第15行,等待请求完成网站返回以后,再运行16,17,18行,然后运行19行,等2秒请求完成了,再运行第20行,最后运行第21行。3次请求串行发出,最终耗时6秒。
程序的运行逻辑与我们期望的不一样。程序并没有利用 I/O 等待的时间发起新的请求,而是等上一个请求结束了再发送下一个请求。
问题出在哪里?
问题出现在,Python 的异步代码,请求之间的切换不能由开发者来直接管理。
开发者通过await语句告诉 asyncio,它后面这个函数,可以被异步等待。注意是可以被等待,但要不要等待,这是 Python 底层自己来决定的。
因为一个 I/O 操作,无论你是发网络请求,还是读写硬盘,Python 都知道,所以当 Python 发现你现在的这个操作确实是一个 I/O操作时,它才会利用I/O 等待时间。
所以,在 Python 的异步编程中,开发者能做的事情,就是把所有能够异步的操作,一批一批告诉 Python。然后由 Python 自己来协调、调度这批任务,并充分利用等待时间。开发者没有权力直接决定这些 I/O操作的调度方式。
所以,上面的代码我们需要做一些修改:
import aiohttp
import asyncio
import time
async def request(sleep_time):
async with aiohttp.ClientSession() as client:
resp = await client.get(f'http://127.0.0.1:8000/sleep/{sleep_time}')
resp_json = await resp.json()
print(resp_json)
async def main():
start = time.perf_counter()
tasks_list = [
asyncio.create_task(request(1)),
asyncio.create_task(request(2)),
asyncio.create_task(request(3)),
]
await asyncio.gather(*tasks_list)
end = time.perf_counter()
print(f'总计耗时:{end - start}')
asyncio.run(main())
运行效果如下图所示:
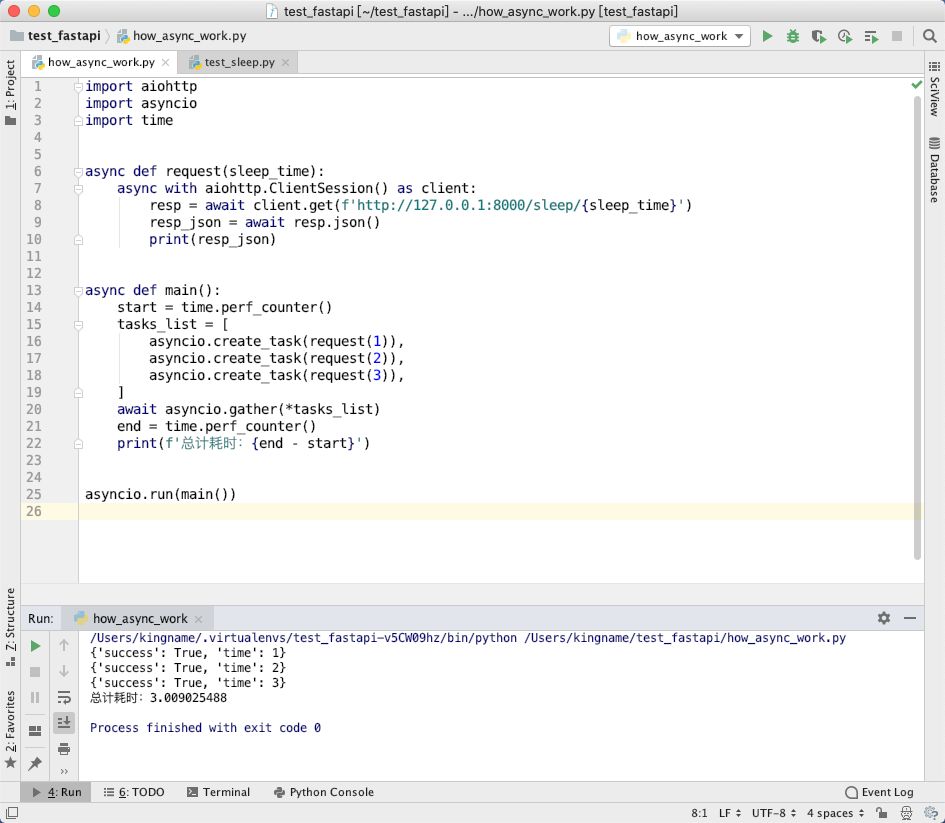
可以看到,现在耗时3秒钟,说明这3次请求,确实利用了请求的等待时间。
我们通过asyncio.create_task()把不同的协程定义成异步任务,并把这些异步任务放入一个列表中,凑够一批任务以后,一次性提交给asyncio.gather()。于是,Python 就会自动调度这一批异步任务,充分利用他们的请求等待时间发起新的请求。
我们平时在写 Scrapy 爬虫时,会有类似下面这样的代码:
...
yield scrapy.Request(url, callback=self.parse)
next_url = url + '&page=2'
yield scrapy.Request(next_url, callback=self.parse)
看起来像是先“请求”url,然后利用这个请求的等待时间执行next_url = url + '&page=2'接下来再发起另一个请求。
但实际上,在 Scrapy 内部,当我们执行yield scrapy.Request后, 仅仅是把一个请求对象放入 Scrapy 的请求队列里面,然后就继续执行next_url = url + '&page=2'了。
请求对象放进请求队列后,还没有真正发起 HTTP请求。只有凑够了一定数量的请求对象或者等待一段时间以后,Scrapy 的下载器才会统一调度这一批请求对象,统一发送 HTTP请求。当某个请求返回以后,Scrapy 把返回的 html 组装成 Response 对象,并把这个对象传入 callback 函数执行后续操作。
综上所述,在 Python 里面的异步编程,你需要先凑够一批异步任务,然后统一提交给 asyncio,让它来帮你调度这批任务。你不能像 JavaScrapt 中那样手动直接控制在异步请求等待时执行什么代码。
在异步代码中调用同步函数
在异步函数里面是可以调用同步函数的。但是如果被调用的同步函数很耗时,那么就会卡住其他异步函数。例如print函数就是一个同步函数,但是由于它耗时极短,所以不会卡住异步任务。
我们现在写一个基于递归的斐波那契数列第 n 项计算函数,并在另一个异步函数中调用它:
def sync_calc_fib(n):
if n in [1, 2]:
return 1
return sync_calc_fib(n - 1) + sync_calc_fib(n - 2)
async def calc_fib(n):
result = sync_calc_fib(n)
print(f'第 {n} 项计算完成,结果是:{result}')
return result
众所周知,基于递归的方式计算斐波那契数列第 n 项,速度非常慢,我们计算一下第36项,可以看到耗时在5秒钟左右:
如果我们把计算斐波那契数列(CPU 密集型)与请求网站(I/O密集型)任务放在一起会怎么样呢?
我们来看看效果:
可以看出,总共耗时8秒左右,其中计算斐波那契数列第36项耗时5秒,剩下3次网络请求耗时3秒,所以总共耗时8秒。
这段代码说明,当一个异步函数(calc_fib)中调用了一个耗时非常长的同步函数(sync_calc_fib)时,这一批所有的异步任务都会被卡住,只有这个同步函数运行完成以后,其他的异步函数才能被正常调度。这就是为什么在异步编程里面,不建议使用 time.sleep的原因。
以上是关于通俗易懂:一篇文章理解Python异步编程的基本原理的主要内容,如果未能解决你的问题,请参考以下文章