0#4hadoop生态圈之NoSQL数据库redis入门
Posted 择码记
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了0#4hadoop生态圈之NoSQL数据库redis入门相关的知识,希望对你有一定的参考价值。
【为什么会有 redis?】
2008 年,意大利一家创业公司 Merzia 推出了一款基于
mysql 的网站实时统计系统 LLOOGG,
然而没过多久,该公司的创始人 Salvatore Sanfilippo
便对 MySQL 的性能感到失望,
于是他决定自己搞一个数据库,2009年就搞出来了,
它就是 Redis!!
不过 Salvatore Sanfilippo 并不满足于只将 Redis 用于
这一款产品,于是开源发布,并开始和 Redis 的另一名
主要贡献者 Pieter Noordhuis 一起继续 Redis 的开发,直到今天。
Redis 后来火了,国内如新浪微博,知乎,国外如 Github,
Stack Overflow 等都是 Redis 的用户。
VMware 公司从 2010 年开始赞助 Redis,Salvatore Sanfilippo
和 Pieter Noordhuis 也分别在 3 月和 5 月加入 VMware,全职开发 Redis。
【Redis 的应用场景】
1、缓存(最多使用):数据查询、短连接、新闻内容、商品内容等;
2、分布式集群架构中的 Session 分离;
3、聊天室的在线好友列表;
4、任务队列(秒杀,抢购等);
5、应用排行榜;
6、网站访问统计;
7、数据过期处理(可以精确到毫秒)。
【什么是NoSQL?】
NoSQL,No only SQL。
NoSQL 是非关系型数据库,为了解决
高并发、高可扩展、高可用以及高写入
而产生的数据库解决方案。
它是关系型数据库的良好补充,而不能替代关系型数据库。
【什么是Redis?】
C 语言开发的,
高性能的,
键值对存储的,
非关系型数据库。
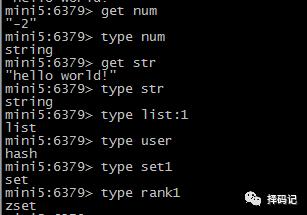
Redis 存储的数据类型有以下几种:
字符、散列、列表、集合、有序集合。
【Redis 的安装启动】
下载:
https://redis.io/download
下载 3.2.11 (新版本 4.0 的特性待以后探讨)
上传到机器上,解压
[hadoop@mini5 ~]$ tar -zxf redis-3.2.11.tar.gz
安装 C 语言环境
[hadoop@mini5 redis-3.2.11]$ sudo yum install -y gcc-c++
进入刚才解压出来的 redis 文件夹,
[hadoop@mini5 ~]$ cd redis-3.2.11
[hadoop@mini5 redis-3.2.11]$ make
[hadoop@mini5 redis-3.2.11]$ make install PREFIX=/home/hadoop/apps/redis-3.2.11
到刚才指定的目录下查看安装情况
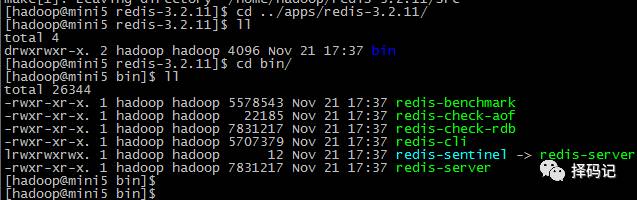
【Redis 服务前端启动】(不推荐使用)
[hadoop@mini5 redis-3.2.11]$ bin/redis-server
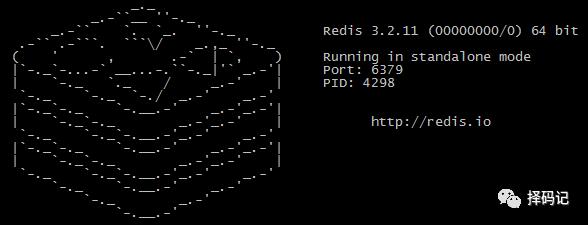
前端启动问题:一旦客户端关闭,则 redis 服务也停掉,不建议使用。
直接 ctrl+c 关掉。
【Redis 服务后端启动】
从刚才解压的 redis 文件夹中拷贝 redis.conf
[hadoop@mini5 redis-3.2.11]$ cp /home/hadoop/redis-3.2.11/redis.conf .
[hadoop@mini5 redis-3.2.11]$ vi redis.conf
注意下面几点:
1、绑定的主机名:bind [hostname]

2、绑定的端口:port [num]

3、是否后台运行:daemonize [yes/no]

保存退出。
启动命令
[hadoop@mini5 redis-3.2.11]$ bin/redis-server redis.conf
查看是否启动成功

关闭后端启动的方式
1、强制关闭:kill -9 4326
2、正常关闭:
[hadoop@mini5 redis-3.2.11]$ bin/redis-cli -p 6379 -h mini5 shutdown
【Redis 自带客户端的启动和关闭】
启动 redis 服务端后,
启动 Redis 客户端:
[hadoop@mini5 redis-3.2.11]$ bin/redis-cli -h mini5 -p 6379

-h 指定主机名
-p 指定端口号
因为其默认端口号是 6379,所以也可以省略,
执行
[hadoop@mini5 redis-3.2.11]$ bin/redis-cli -h mini5
即可。
退出客户端
mini5:6379> quit
【Redis 自带客户端的使用】
【String 类型】
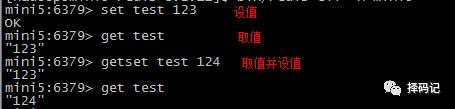
设值:SET key value
取值:GET key
取值并设值:GETSET key value
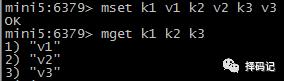
设多个键值:MSET key value [key value …]
取多个值:MGET key [key …]
删除某个key:DEL key

递增:INCR key
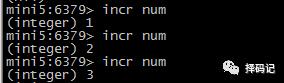
将某个key的值递增指定的整数:INCRBY key increment
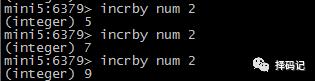
递减:DECR key
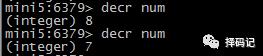
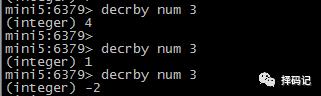
将某个 key 的值递减指定的整数:DECRBY key decrement
追加字符串:APPEND key value
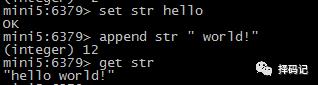
若键不存在,则相当于 SET key value。
返回值是追加后 value 的长度。
返回某个键的值的长度:STRLEN key

若 value 为数字,则同样把 value 当做字符串,然后返回其长度。
【String 类型应用案例】
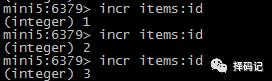
商品编号、订单号可以采用 Redis String 类型的自增数字特性生成。
【Hash 类型】
设置某个对象的一个属性:HSET key field value

获取某个对象的一个属性:HGET key field

设置某个对象的多个属性:HMSET key field value [field value...]

获取某个对象的多个属性:HMGET key field [field...]

字段不存在时设置某个对象的一个属性:HSETNX key field value
(如果字段已存在,则不做任何操作)
字段已存在的情况:

字段不存在的情况:


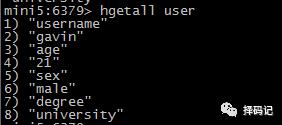
获取某个对象的所有字段值:HGETALL key
删除某个对象的多个字段:HDEL key field [field...]
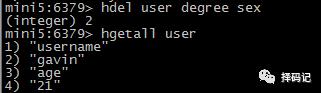
返回值是被删除的字段个数
某 field 的值递增指定整数:HINCRBY key field incrment
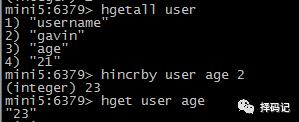
判断某个 field 是否存在:HEXISTS key field
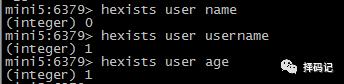
存在返回1,不存在返回0.
返回某个 key 的所有字段:HKEYS key

返回某个 key 的所有 fields 的值:HVALS key
获取字段数量:HLEN key

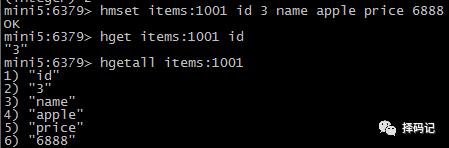
【Hash类型应用案例】
存放某商品对象
【List 类型】
ArrayList 使用数组来存储数据,特点:查询快,增删慢;
LinkedList 使用双向链表存储数据,特点:增删快,查询慢,但是查询链表两端的数据也很快。
Redis 的 List 是采用链表来存储的。
从 List 左边推入数据:LPUSH key value [value ...]
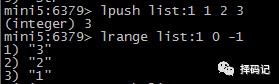
从 List 右边推入数据:RPUSH key value [value ...]
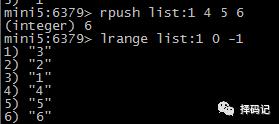
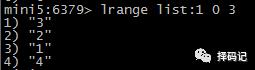
从左边列出 List 的数据:LRANGE key start stop(如果 stop = -1 表示最后一个元素)
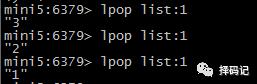
从 List 左边弹出数据:LPOP key
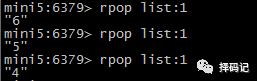
从 List 右边弹出数据:RPOP key

获取列表中元素的个数:LLEN key
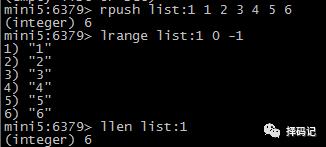
删除 List 中 count 个值为 value 的元素:LREM key count value
如果 count < 0,则从右边开始删除:
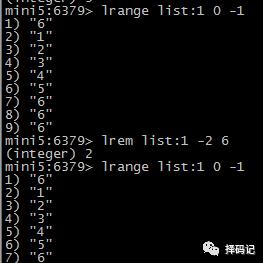
如果 count > 0,则从左边开始删除:
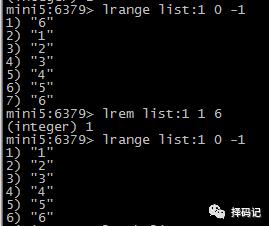
如果 count = 0,则删除所有的值为 value 的元素:
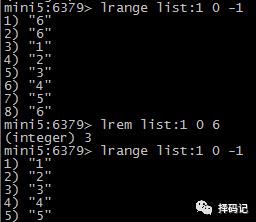
取出 List 中指定索引的值:LINDEX key index
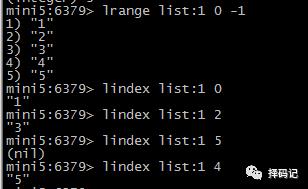
设定 List 中指定索引的值:LSET key index value
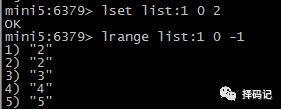
只保留 List 指定片段:LTRIM key start stop
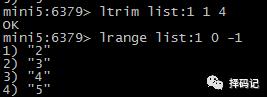
在某指定值的前/后插入值:LINSERT key [BEFORE | AFTER] pivot value
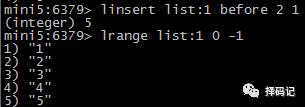
将 List 右边的元素弹出,从左边推入一个新的 List 中:RPOPLPUSH source destination
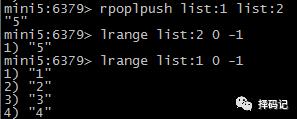
【List 应用案例】
存放商品评价列表:

【Set 类型】
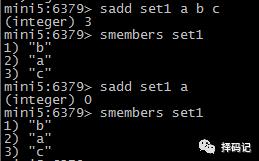
添加元素:SADD key member [member ...]
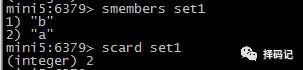
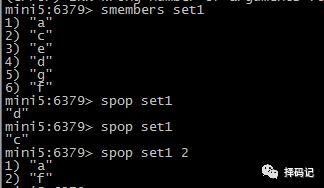
查看 Set 中所有元素:SMEMBERS key
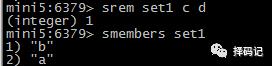
移除元素:SREM key member [member ...]
判断元素是否在 Set 中:SISMEMBER key member

差集:SDIFF key [key ...]
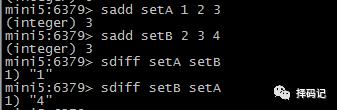
交集:SINTER key [key ...]

并集:SUNION key [key ...]
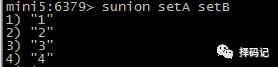
获得 Set 中元素个数:SCARD key
随机弹出 count 个元素:SPOP key [count],count不写,则默认弹出一个元素
【SortedSet 类型】
SortedSet 又叫 ZSet,
SortedSet 是有序集合,可排序,但是唯一;
SortedSet 和 Set 的不同之处,是会给元素增加一个分值,
然后通过这个分值进行排序。
添加元素分值和元素:ZADD key score member [score member ...]

获得某个范围的元素(按分值从低到高,可选项:是否包含分值):ZRANGE key start stop [WITHSCORES]
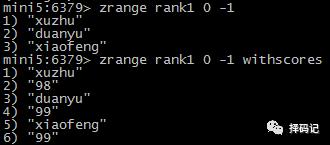
查看某元素分值:ZSCORE key member

移除元素:ZREM key member [member ...]

按照分值从高到低返回某范围的元素:ZREVRANGE key start stop [WITHSCORES]
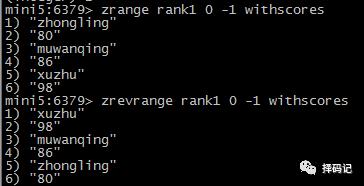
获取元素排名(从小到大):ZRANK key member
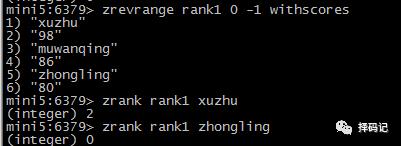
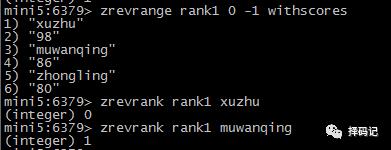
获取元素排名(从大到小):ZREVRANK key member
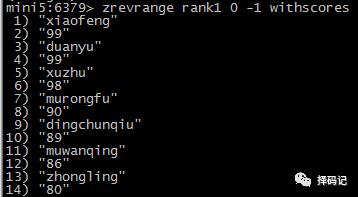
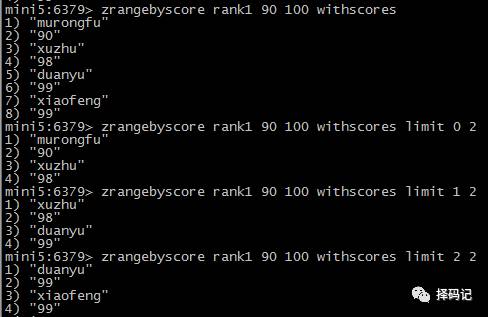
ZRANGEBYSCORE key min max [WITHSCORES] [LIMIT offset count]
offset:返回结果中,脚本为 offset 开始。
增加某个元素的分值:ZINCRBY key increment member

获得元素个数:ZCARD key

获得指定范围内的元素个数:ZCOUNT key min max

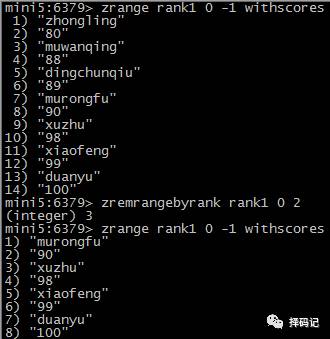
按照排名范围删除元素:ZREMRANGEBYRANK key start stop
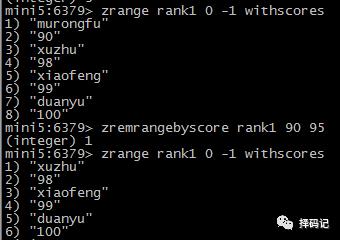
按照分值范围删除元素:ZREMRANGEBYSCORE key min max
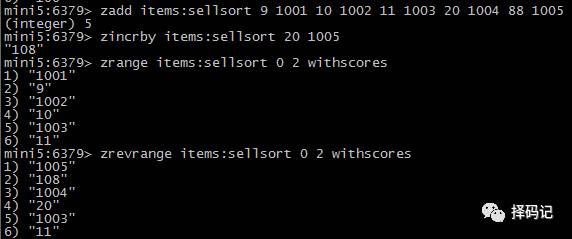
【SortedSort 案例】
商品销售排行榜
key=items:sellsort
编号 1005 的商品增加 20 销量
销量最差的三个商品
销量最好的三个商品
【常用命令】
查看key:key pattern
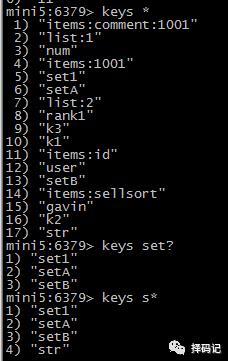
判断 key 是否存在:exists key [key ...]
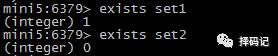
返回值是存在的 key 的个数
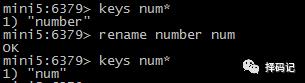
删除 key:del key [key ...]

重命名某个 key:rename key newkey
查看某个 key 的类型: type key
设置 key 的生存时间:expire key seconds
查看 key 的剩余生存时间:ttl key
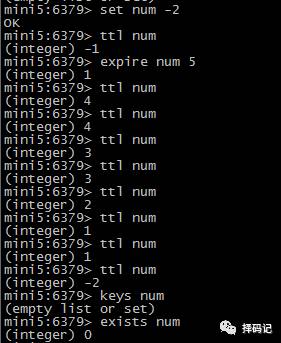
持久化 key:persist key
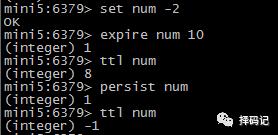
设置 key 的生存时间(单位:毫秒):pexpire key milliseconds
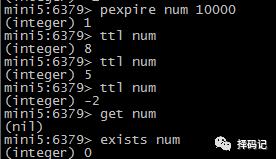
【持久化方案】
【RDB 方式持久化】
默认方式,无需配置。
功能:在指定时间间隔内,将数据集快照写入磁盘。
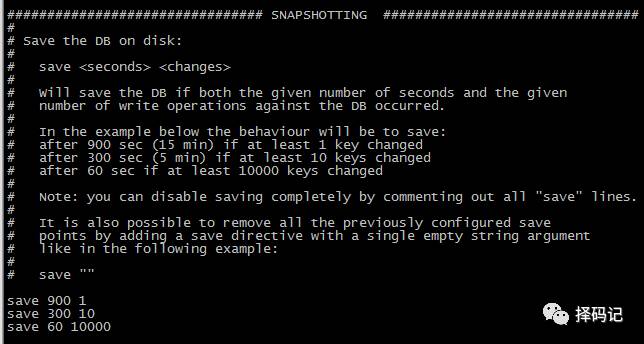
每 900 秒(15 分钟)至少有 1 个 key 发生变化,则 dump 内存快照;
每 300 秒(5 分钟)至少有 10 个 key 发生变化,则 dump 内存快照;
每 60 秒(1 分钟)至少有 10000 个 key 发生变化,则 dump 内存快照。
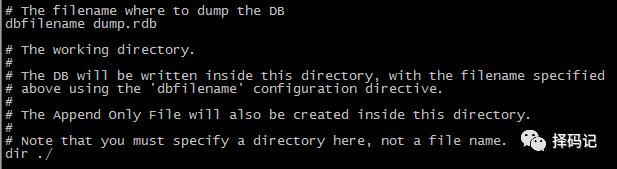
dbfilename:dump 的文件名
dir:dump 的文件夹
【RDB 方式持久化的问题】
一旦 redis 非法关闭,那么会丢失最后一次持久化之后的数据。
如果数据不重要,则不必要关心;
如果数据不能允许丢失,那么要使用 AOF 的方式。
【AOF 方式持久化】
以日志的形式记录服务器所处理的每一个写操作,
在 Redis 服务器启动之初会读取该文件来重新构建数据库,
以保证启动后数据库中的数据是完整的。
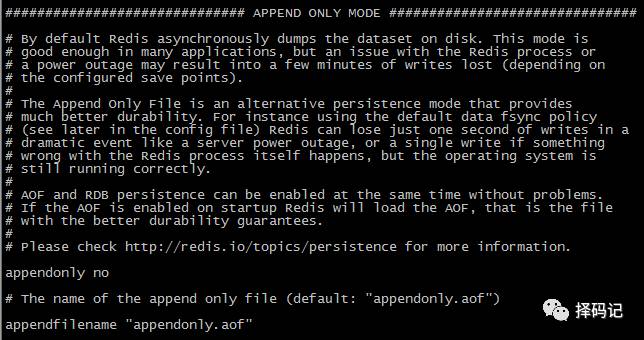
appendonly:设置为 yes,则开启 aof 持久化方式,默认是 no;
appendfilename:aof 持久化到磁盘的文件名。
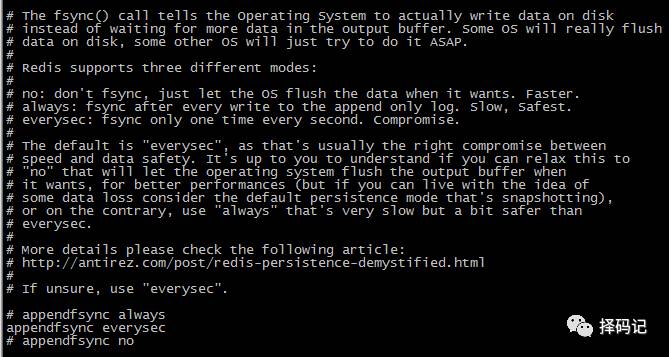
appendfsync:设置 aof 的持久化策略,有三种——
always 表示每次有数据修改发生时都会写入 aof 文件,
everysec 表示每秒钟同步一次,该策略为默认策略,
no 表示不会持久化。
【已有数据的情况下,开启 AOF 持久化的方式】
同时使用 RDB 和 AOF 方式的时候, 如果 redis 服务重启,
则数据从 AOF 文件加载。
此时,如果本来已存在数据,开启 AOF 再重启服务后,
redis 会新建一个后缀为 aof 的文件用于备份数据,并根据此文件恢复数据,而不再载入 RDB 中的数据快照,所以原来的数据会丢失。
为了避免这种情况发生,应该按照以下步骤,在已有数据的情况下,
开启 AOF 的持久化方式。
1、先备份 dump.rdb
[hadoop@mini5 redis-3.2.11]$ cp dump.rdb dump.rdb.bak
2、使用 BGREWRITEAOF 命令,将当前数据写入 aof 文件
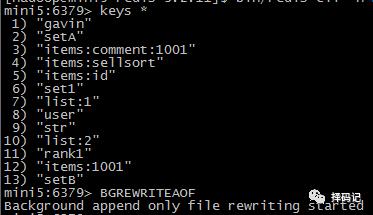
看到生成了 appendonly.aof 文件,并且文件大小大于0

3、修改配置文件
appendonly yes
appendfsync always(此项根据需要,如果对数据安全性要求一般,则设置为 everysec)
4、关闭 redis 服务器,然后重启。
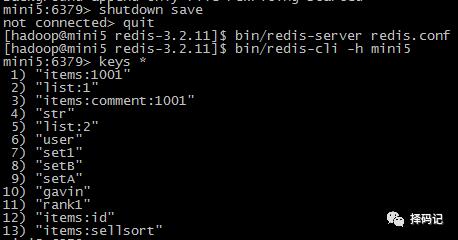
发现数据都存在;
5、写入数据,看看 aof 文件是否有增加大小。


发现从 886 变成 951,说明开启成功。
【数据恢复案例】
把数据库清空,模拟数据丢失,并且用不安全的方式关闭数据库。

[hadoop@mini5 redis-3.2.11]$ vi appendonly.aof
shift + g 跳到文件末尾,删除 flushdb 这个命令,保存退出。
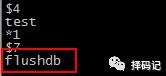
重新开启服务器和客户端
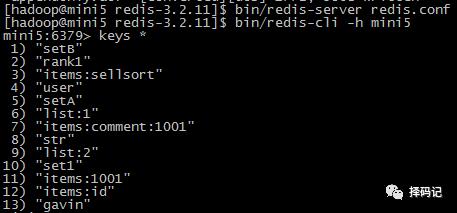
发现数据已经恢复。
【主从复制】
如果提供 redis 服务的机器硬盘损坏,则可能导致数据丢失。
通过 redis 的主从复制,可以避免单点故障导致的数据丢失。
在 mini5 上,把 redis 复制到 mini2
[hadoop@mini5 ~]$ sudo scp -r apps/redis-3.2.11/ hadoop@mini7:/home/hadoop/apps/
在 mini2 上,删除持久化文件
[hadoop@mini2 redis-3.2.11]$ rm -f appendonly.aof dump.rdb dump.rdb.bak
修改配置文件
[hadoop@mini2 redis-3.2.11]$ vi redis.conf
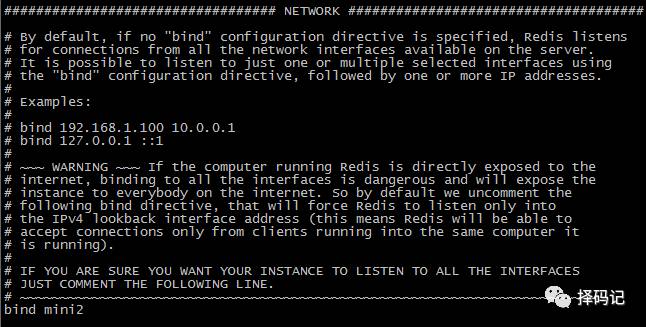
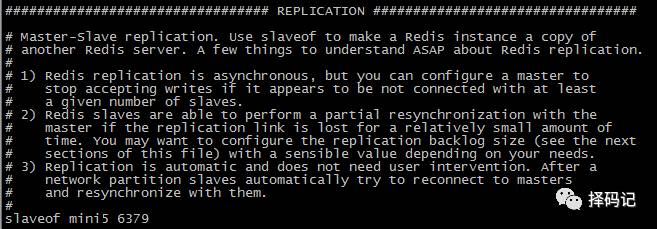
启动 mini2 中的 redis 服务和客户端
[hadoop@mini2 redis-3.2.11]$ bin/redis-server redis.conf
[hadoop@mini2 redis-3.2.11]$ bin/redis-cli -h mini2
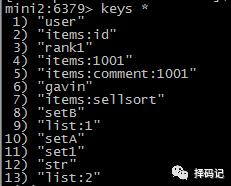
发现 mini5 的数据已经被自动复制过来了。
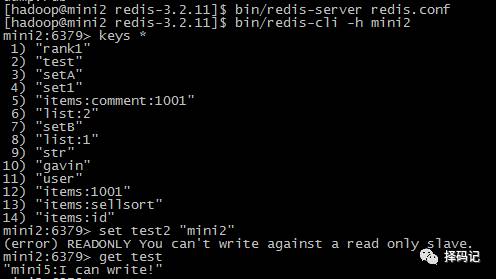
尝试进行写数据:

到 mini5 上写数据,看看 mini2 是否同步

发现 mini2 果然同步成功了!

【模拟磁盘损坏下的服务器恢复】
这样,假如 mini5 磁盘损坏了,也能通过 mini2 的持久化文件修复。
实验如下:
关闭 redis 服务,并把持久化文件全部删除(模拟硬盘损坏)
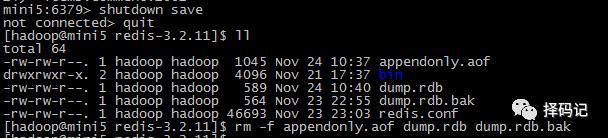
此时,千万不能在 mini5 上直接重启服务!!否则,重启后,
mini5 上没有任何数据,并且会直接备份到从节点 mini2 上,
导致数据再也无法恢复!
应先到 mini2 上,把持久化文件拷贝到 mini5 的文件夹下。
查看 mini2 是否有数据
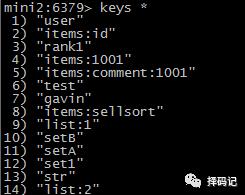
安全退出 mini2 的 redis 服务。

将 mini2 的持久化文件拷贝到 mini5:
[hadoop@mini2 redis-3.2.11]$ sudo scp -r appendonly.aof dump.rdb hadoop@mini5:/home/hadoop/apps/redis-3.2.11/
重启 mini5,发现数据已经恢复:
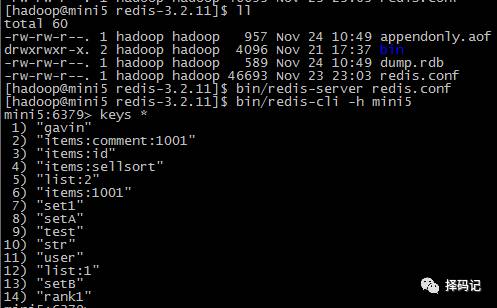
确认数据已经恢复,此时,才能再次启动 mini2:
【安装部署 redis 集群】
1、将 mini5 下 redis 的持久化文件备份,并配置集群可用
[hadoop@mini5 redis-3.2.11]$ mkdir backup
[hadoop@mini5 backup]$ mv appendonly.aof dump.rdb backup
[hadoop@mini5 redis-3.2.11]$ mv backup/ ../redisBackup
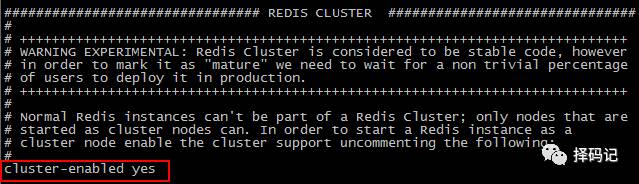
编辑 redis.conf 文件
[hadoop@mini5 redis-3.2.11]$ vi redis.conf
打开cluster-enable:
2、将mini5 下的 redis-3.2.11 文件夹复制到其他节点。
由于至少要 6 个节点,所以安排将其复制到
mini2~mini7。
先到 mini2 下,删除原来的 redis 安装文件夹。
[hadoop@mini2 redis-3.2.11]$ cd ~/apps/
[hadoop@mini2 apps]$ rm -rf redis-3.2.11/
到 mini5 下
cd ~/apps
sudo scp -r redis-3.2.11/ hadoop@mini2:/home/hadoop/apps/
sudo scp -r redis-3.2.11/ hadoop@mini3:/home/hadoop/apps/
sudo scp -r redis-3.2.11/ hadoop@mini4:/home/hadoop/apps/
sudo scp -r redis-3.2.11/ hadoop@mini6:/home/hadoop/apps/
sudo scp -r redis-3.2.11/ hadoop@mini7:/home/hadoop/apps/
3、编辑 redis.conf 文件
到 mini2 下。
[hadoop@mini2 redis-3.2.11]$ vi redis.conf

同理,修改 mini3~mini7。
4、在 mini5 下配置免密登录
编写脚本:
[hadoop@mini5 ~]$ cd ~/bin/
[hadoop@mini5 bin]$ vi copySshId.sh
#!/bin/bash
SERVERS="mini2 mini3 mini4 mini5 mini6 mini7"
PASSWORD=hadoop
BASE_SERVER=mini5
auto_ssh_copy_id() {
expect -c "set timeout -1;
spawn ssh-copy-id $1;
expect {
*(yes/no)* {send -- yes ;exp_continue;}
*assword* {send -- $2 ;exp_continue;}
eof {exit 0;}
}";
}
ssh_copy_id_to_all() {
for SERVER in $SERVERS
do
auto_ssh_copy_id $SERVER $PASSWORD
done
}
ssh_copy_id_to_all
注:如果提示找不到 expect 命令,则需要安装 expect。
[hadoop@mini5 ~]$ sudo yum -y expect
运行脚本:
[hadoop@mini5 bin]$ sh copySshId.sh
5、启动所有 RedisServer
编写脚本:
[hadoop@mini5 ~]$ cd ~/bin/
[hadoop@mini5 bin]$ vi startAllRedisServer.sh
#/bin/sh
echo "start RedisServers..."
for i in 2 3 4 5 6 7
do
ssh mini$i "source /etc/profile;cd /home/hadoop/apps/redis-3.2.11/;bin/redis-server redis.conf"
echo "mini$i redisServer has started..."
done
添加权限:
[hadoop@mini5 bin]$ chmod a+x startAllRedisServer.sh
运行脚本:
[hadoop@mini5 bin]$ cd ~
[hadoop@mini5 ~]$ startAllRedisServer.sh
查看是否成功启动:
ps aux | grep redis | grep -v grep

发现都已成功启动,并且末尾都带着 [cluster] 标记。
6、安装 ruby 环境
[hadoop@mini5 ~]$ sudo yum -y install ruby
[hadoop@mini5 ~]$ sudo yum -y install rubygems
7、复制 redis-trib.rb
到 redis 的源解压缩文件下的 src 目录下复制。

[hadoop@mini5 src]$ cp redis-trib.rb ~/bin/
8、安装 redis-trib.rb 运行依赖的 ruby 包
访问网址:
https://rubygems.org/gems/redis/versions/
由于我们安装的 redis 版本是 redis-3.2.11,故选择此版本:
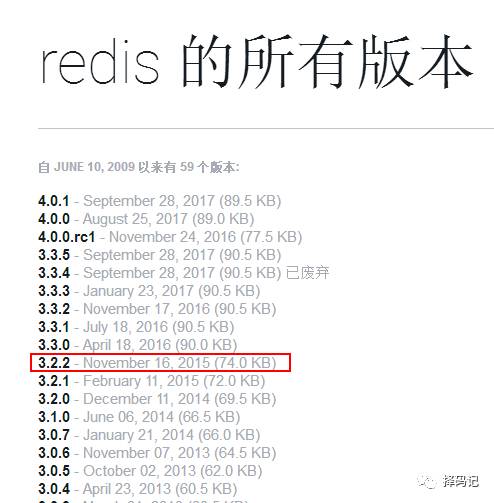
点击进入,右侧相关链接点下载:

将下载下来的文件放到 mini5 下的 ~/bin 目录下。
运行命令:
[hadoop@mini5 bin]$ sudo gem install redis-3.2.2.gem
9、运行 redis-trib.rb 创建集群
[hadoop@mini5 ~]$ cd bin/
[hadoop@mini5 bin]$ ./redis-trib.rb create --replicas 1 192.168.87.152:6379 192.168.87.153:6379 192.168.87.154:6379 192.168.87.155:6379 192.168.87.156:6379 192.168.87.157:6379
注:hostname 及其对应 ip 如下
mini2 192.168.87.152
mini3 192.168.87.153
mini4 192.168.87.154
mini5 192.168.87.155
mini6 192.168.87.156
mini7 192.168.87.157
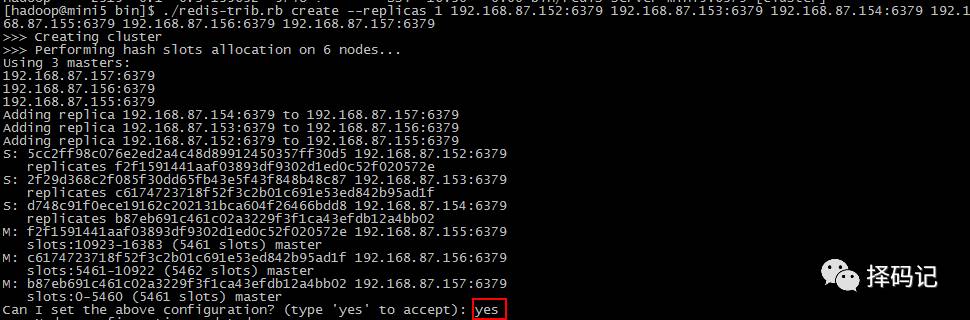
输入 yes 后,
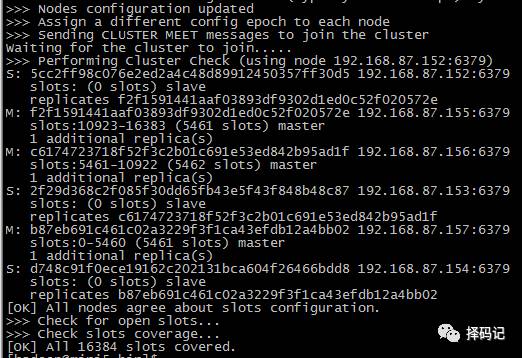
说明集群创建成功!
如果有创建失败,会在根目录下默认生成一个集群配置文件:nodes.conf
(或者是 redis.conf 中配置的 cluster-config-file 所在的文件)

将它们全部删除,重启所有节点的 Redis Server,再重新运行上方的 redis-trib.rb 命令即可。
【连接集群】
在任意节点,运行连接客户端命令,末尾加 -c
[hadoop@mini5 redis-3.2.11]$ bin/redis-cli -h mini5 -p 6379 -c

进行简单的 set 操作,发现它会重定向到其他节点,说明集群运行正常。
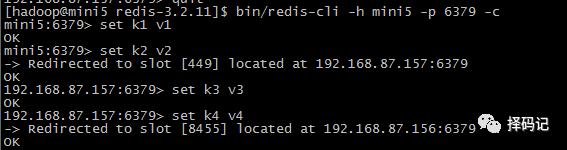
查询刚才设置的值,发现其同样会重定向。
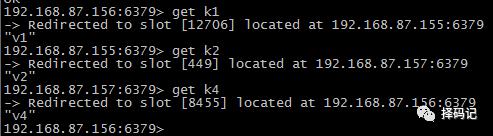
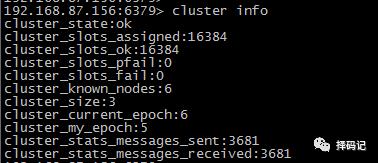
查看集群节点信息

查看集群状态
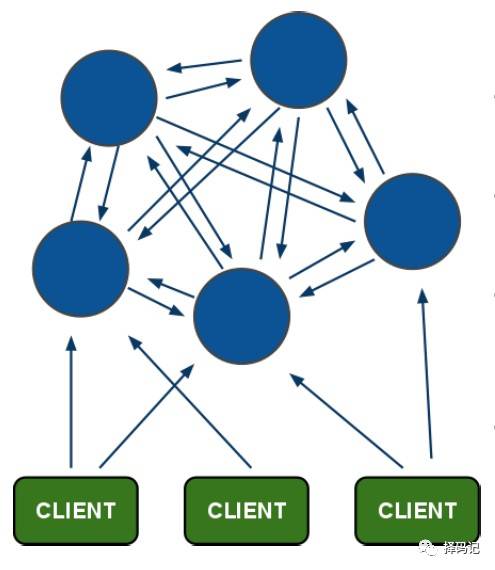
【redis-cluster 架构】
通过上方的集群搭建和测试,大家对集群有了一个初步的了解。
接下来我们来了解下 Redis 集群的架构。
架构图:
 、
、
架构细节:
1、所有的 redis 节点彼此互联(PING-PONG机制),
内部使用二进制传输协议优化传输速度和带宽;
2、节点的 fail 是通过
集群中超过半数的节点检测失败时才生效;
3、客户端与 redis 节点直连,不需要中间的 proxy 层;
客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可;
4、redis-cluster 把所有物理节点映射到 [0-16383] slot 上,
并负责维护;
注:redis 集群内置了16383 个哈希槽(slot),当需要在 redis 集群中
放置一个 key-value 时,redis 先对 key 使用 crc16 算法算出一个 result,
然后把 result 对 16384 求余数,这样每个 key 都会对应一个编号在
0-16383 之间的哈希槽, redis 会根据节点数量大致均等的将
哈希槽映射到不同的节点;
【redis-cluster 投票:容错】
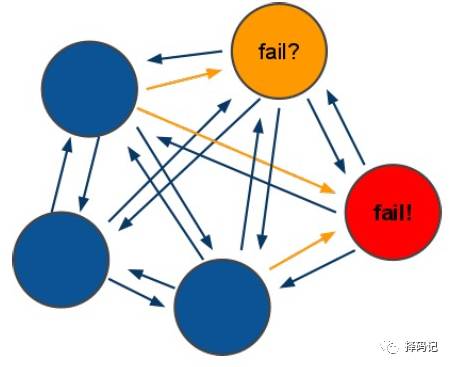
1、集群中所有 master 参与投票,
如果半数以上 master 节点与
其中一个master 节点通信超过
cluster-node-timeout,认为该 master 节点挂掉。
2、什么时候整个集群不可用?
2.1、如果集群任意 master 挂掉,且当前 master 没有 slave,
则集群进入 fail 状态。
也可以理解成集群的 [0-16383] slot 映射不完全时进入 fail 状态。
2.2、如果集群超过半数以上 master 挂掉,无论是否有 slave,
集群进入 fail 状态。
【维护集群】
【添加主节点】
1、从 mini5 复制 redis 文件夹到 mini1
[hadoop@mini5 apps]$ sudo scp -r redis-3.2.11/ hadoop@mini1:/home/hadoop/apps/
2、删除持久化文件和集群配置信息文件
[hadoop@mini1 redis-3.2.11]$ rm -rf appendonly.aof dump.rdb nodes.conf
3、打开 mini1 下的 redis 服务,并再次删除持久化文件和集群配置信息
[hadoop@mini1 redis-3.2.11]$ bin/redis-server redis.conf

测试 mini1 下的 redis 服务

再次删除持久化文件和集群配置信息
4、到 mini5 下执行添加节点命令
hostname ip
mini1 192.168.87.151
mini5 192.168.87.155
执行命令
[hadoop@mini5 bin]$ ./redis-trib.rb add-node 192.168.87.151:6379 192.168.87.155:6379
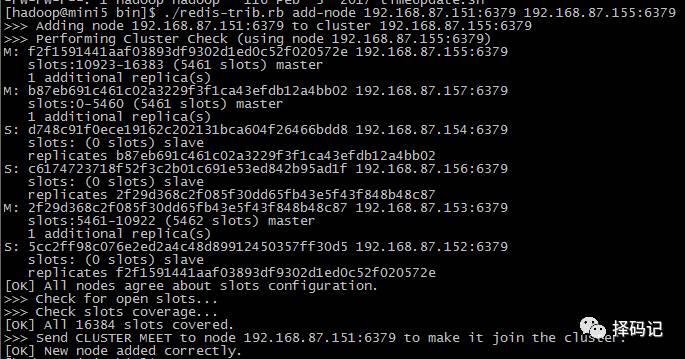
发现 mini1 的 redis 根目录下多了集群配置信息文件

【5、重新分配 Hash 槽】
到任意节点(此处为 mini7)查看集群节点信息

发现 mini1 虽然连接上了,但是并没有分配任何 Hash 槽,故无法存储数据。
记录下 mini1 的 redis id:99c7dc20c884fbf3aa7a39539919078313517d9c
在 mini5(集群中任意一个可用节点都行) 运行命令,为 mini1 分配槽:
./redis-trib.rb reshard 192.168.87.151:6379
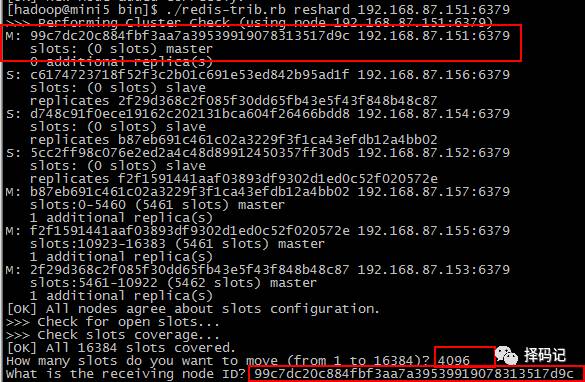
输入 4096(此处为你想分配的槽的个数,这里由于 4 个 master,16384 个槽均分就是 4096),按回车;
输入 mini1 的 redis id,按回车;
输入 all,表示从所有节点中获取槽

显示出准备移动的槽,输入 yes,表示确认移动到 mini1
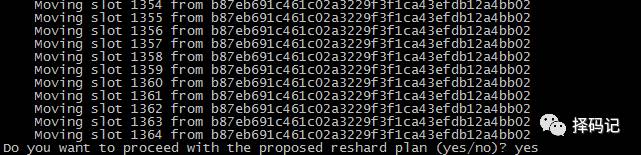
移动完毕

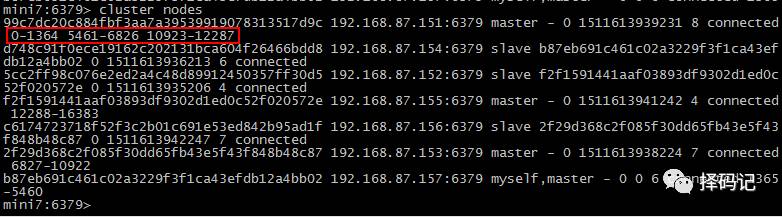
查看移动后的集群信息:
【添加从节点】
在 mini2 上添加一个新节点,作为 mini1 的从节点。
mini2 192.168.87.152:6380
复制 redis
[hadoop@mini2 apps]$ cp -r redis-3.2.11/ redis-mini1Slave
删除持久化文件和集群配置文件
[hadoop@mini2 apps]$ cd redis-mini1Slave/
[hadoop@mini2 redis-mini1Slave]$ rm -rf appendonly.aof dump.rdb nodes.conf
修改端口
[hadoop@mini2 redis-mini1Slave]$ vi redis.conf
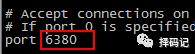
启动 redis 新节点,mini2:6380
[hadoop@mini2 redis-mini1Slave]$ bin/redis-server redis.conf

再次删除持久化文件和集群配置文件
到 mini5 下,执行添加从节点命令:
[hadoop@mini5 bin]$ ./redis-trib.rb add-node --slave --master-id 99c7dc20c884fbf3aa7a39539919078313517d9c 192.168.87.152:6380 192.168.87.155:6379
其中,99c7dc20c884fbf3aa7a39539919078313517d9c 为 mini1 下的 redis id。
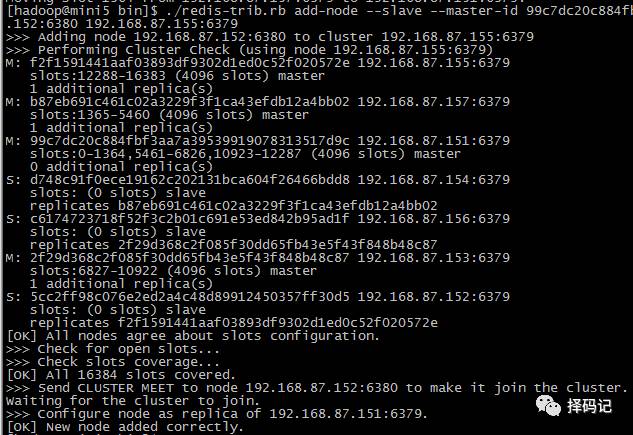
查看集群节点信息
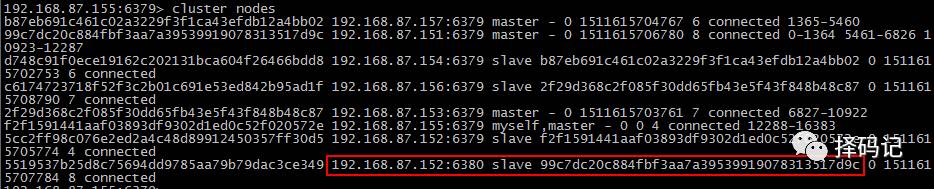
发现,mini1 的从节点添加成功。
【删除从节点】
现在,想把 mini2:6380 这个从节点删除
查看集群信息:
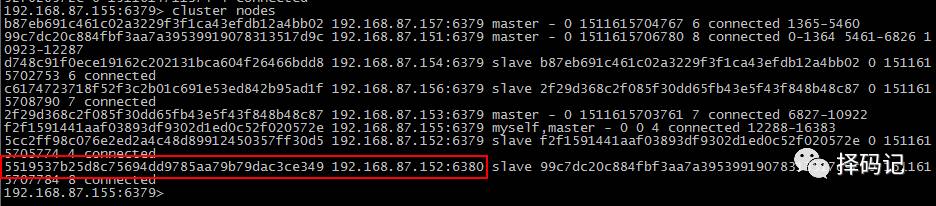
记录下 mini2:6380 节点的 id:
5519537b25d8c75694dd9785aa79b79dac3ce349
到 mini5 下,执行删除节点命令:
[hadoop@mini5 bin]$ ./redis-trib.rb del-node 192.168.87.152:6380 5519537b25d8c75694dd9785aa79b79dac3ce349

查看集群节点信息:

发现,mini2:6380 这个节点已经不在集群节点信息里了。
并且,此节点的 redis 服务也已经关闭。

如果该节点不需要了,再把相关的文件删除即可。
[hadoop@mini2 apps]$ rm -rf redis-mini1Slave/
【删除主节点】
删除已经占有 Hash 槽的主节点会失败,报错如下:
[ERR] Node 192.168.87.151:6379 is not empty! Reshard data away and try again.
需要先重新分配槽,把 mini1 节点下的槽回收。
查看集群信息:
192.168.87.155:6379> cluster nodes
以下是各主节点的信息:
b87eb691c461c02a3229f3f1ca43efdb12a4bb02 192.168.87.157:6379 master - 0 1511616684035 6 connected 1365-5460
99c7dc20c884fbf3aa7a39539919078313517d9c 192.168.87.151:6379 master - 0 1511616681017 8 connected 0-1364 5461-6826 10923-12287
2f29d368c2f085f30dd65fb43e5f43f848b48c87 192.168.87.153:6379 master - 0 1511616683027 7 connected 6827-10922
f2f1591441aaf03893df9302d1ed0c52f020572e 192.168.87.155:6379 myself,master - 0 0 4 connected 12288-16383
根据信息,我们知道,要回收 mini1 的 Hash 槽,可以将 mini1 的 Hash 槽中
0-1364 给 mini7,5461-6826 给 mini3,
10923-12287 给 mini5,
所以,应该
给 mini7 分配 1364 - 0 + 1 = 1365 个槽,
给 mini3 分配 6826 - 5461 + 1 = 1366 个槽,
给 mini5 分配 12287 - 10923 + 1 = 1365 个槽。
到 mini5 下,执行命令重新分配 mini7 的 Hash 槽:
[hadoop@mini5 bin]$ ./redis-trib.rb reshard 192.168.87.157:6379
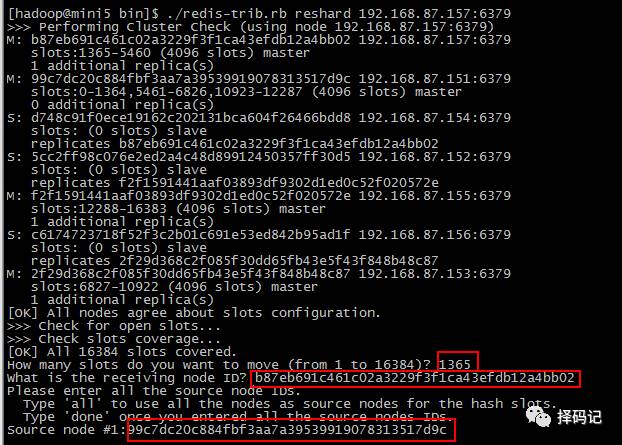
输入要分配的槽数:1365,
输入要接收的 mini7 节点的 id,
输入源节点 mini1 的 id。
输入 done

输入确认移动:

移动完成

同理,移动 mini1 的剩余槽到 mini3 和 mini5。
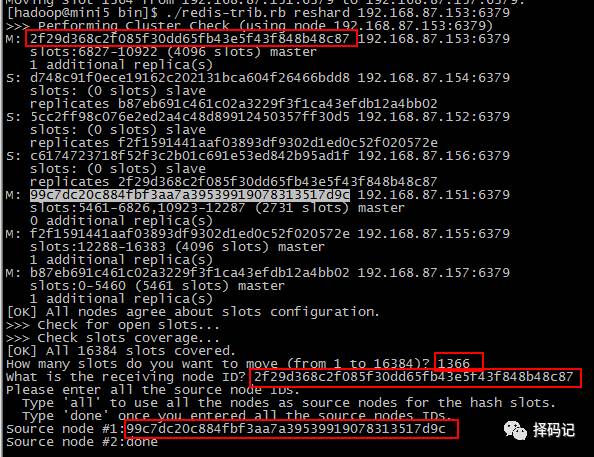
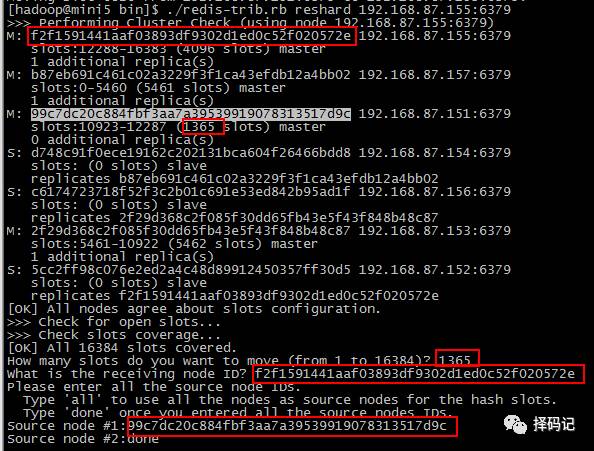
执行完毕后,再次查看集群信息:
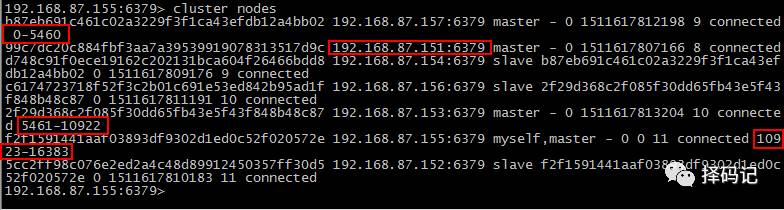
发现 mini1 血槽已空
这时候,就可以删除 mini1 这个主节点了。
[hadoop@mini5 bin]$ ./redis-trib.rb del-node 192.168.87.151:6379 99c7dc20c884fbf3aa7a39539919078313517d9c
再次查看集群节点信息,
发现已经找不到 mini1:6379 这个节点了。
如果该 redis 节点不需要了,删除相关的 redis 文件即可。
好了,关于 redis 的部分,暂时介绍到这里。
下一篇文,我们将重点介绍 redis 的 java 客户端:jedis。
———————————分割线———————————
阅后来撩啊:
未关注的,文章开头右上角,请亲戳"择码记"关注哦~
觉得文章不错,请亲点赞哦~
觉得可能对别人有帮助,请亲分享哦~
觉得为您共享了价值,请壕打赏哦~
版本所有:Gavin Hawk
择码记扣扣群:579522954,欢迎小伙伴们一起学习分享交流哦~
谢谢亲支持哟!
另:
感谢您的阅读~
择码记将持续发布高质量的文章,诚意满满,干货满满,以期对您有所帮助!
若您要查看章节,请直接输入“1”,即可跳转到第一章。以此类推。
有些章节分上下两篇,如第三章有“3_1”和"3_2",
则输入“3_1”即可出来上篇,以此类推。
若您需要查看某方面相关文章,可直接输入试试,比如“Spark部署”、“combineByKey”等。
包含:1, 2, 3_1, 3_2, 4_1, 4_2, 5_1, 5_2, 6, 7, 8 共 11 篇文章;
专题:专题1,专题2,专题3,专题4
官方翻译:3#1
Hadoop 生态圈:0#1, 0#2, 0#3, 0#4
认知:认知1
以上是关于0#4hadoop生态圈之NoSQL数据库redis入门的主要内容,如果未能解决你的问题,请参考以下文章