一次记录,如何部署Hadoop生态圈工具
Posted 开源智能Pentaho
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一次记录,如何部署Hadoop生态圈工具相关的知识,希望对你有一定的参考价值。

学习无止境,踏上新征程。部署大数据平台的记录,与君分享。

一、准备环境
1 安装简介
Ubuntu 14.04 LTS
jdk-8u152-linux-x64.tar.gz
hadoop-3.0.0.tar.gz (jdk9.0会报错)
apache-hive-2.3.2-bin.tar.gz
spark-2.2.1-bin-without-hadoop.tgz
二、修改主机名
1查看主机名
hostname
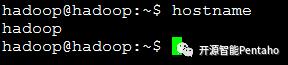
2 修改/etc/hostname文件
修改后

3 立即生效
假如只是完成了步骤2.2,实际上只是修改了静态配置,重启的时候才会生效,要想立即生效,可以输入

4 修改/etc/hosts
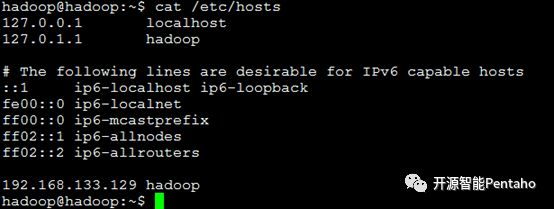
三、安装Java
主要是配置一下JAVA_HOME。
Java的解压路径

配置环境变量,vi /etc/profile

四、Hadoop伪分布式集群安装部署
Hadoop部署模式有:本地模式、伪分布模式、完全分布式模式、HA完全分布式模式。
区分的依据是NameNode、DataNode、ResourceManager、NodeManager等模块运行在几个JVM进程、几个机器。
模式名称 |
各个模块占用的JVM进程数 |
各个模块运行在几个机器数上 |
本地模式 |
1个 |
1个 |
伪分布式模式 |
N个 |
1个 |
完全分布式模式 |
N个 |
N个 |
HA完全分布式 |
N个 |
N个 |
1 配置hadoop-env.sh,yarn-env.sh,mepre-env.sh
在这三个文件的开头加上JAVA_HOME,不配置的话他们会自动从环境变量里面获取。配置为了显示指定JAVA版本环境。
export JAVA_HOME=/hadoop/jdk1.8.0_152

2配置core-site.xml
<property>
<name>hadoop.tmp.dir</name>
<value>/hadoop/data/tmp</value>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop:8020</value>
</property>
这里之所以要配置hostname而不是ip,是虚拟机的ip会变动,所以为了避免频繁更改配置文件,就采用hostname。
hadoop.tmp.dir 是hadoop文件系统依赖的基础配置,很多路径都依赖它。如果hdfs-site.xml中不配置namenode和datanode的存放位置,默认就放在这个路径中。先创建该目录:mkdir -p /hadoop/data/tmp
3配置hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
简单的学习,伪分布式只需要将副本数配置为1(只有一个datanode实例)。
4配置mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
Mapreduce的运行模式,常用的就是yarn(生产),local(测试)两种模式。
5配置yarn-site.xml
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
yarn.nodemanager.aux-services 这个属性,常用的还有spark_shuffle。
6配置hadoop环境变量
vi /home/hadoop/.profile

export HADOOP_HOME=/hadoop/hadoop-3.0.0
export HADOOP_PREFIX=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
此部分为网上内容,未全部配置。
生效:
重启,或者再root模式下执行source /home/hadoop/.profile
7启动Hadoop服务
启动HDFS:
格式化hdfs,然后启动hdfs相关的服务。
hadoop@hadoop:~$ hdfs namenode -format
格式化是对HDFS分布式文件系统中的DataNode进行分块,统计所有分块后的初始元数据存储在NameNode中。
格式化后,查看core-site.xml里hadoop.tmp.dir(本例是/hadoop/data/tmp/目录)指定的目录下是否有了dfs目录,如果有,说明格式化成功。
hadoop@hadoop:~$ start-dfs.sh
hadoop@hadoop:~$ start-dfs.sh
Starting namenodes on [hadoop]
Starting datanodes
Starting secondary namenodes [hadoop]
jps查看进程
hadoop@hadoop:~$ jps
5504 Jps
4981 NameNode
5334 SecondaryNameNode
5126 DataNode
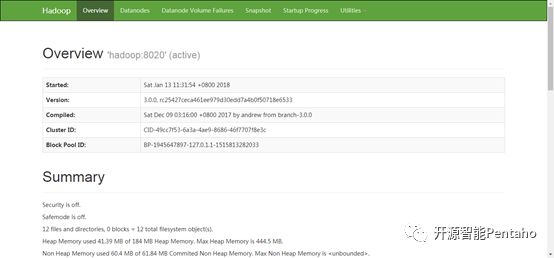
这个时候可以访问HDFS的50070端口,前提是windows和linux网络是通畅的,使用主机名的话需要配置主机和ip映射C:WindowsSystem32driversetcHOSTS文件
在浏览器输入hadoop:50070
启动YARN:
hadoop@hadoop:~$ start-yarn.sh
hadoop@hadoop:~$ start-yarn.sh
Starting resourcemanager
Starting nodemanagers
jps查看进程
hadoop@hadoop:~$ jps
5776 NodeManager
5648 ResourceManager
4981 NameNode
5334 SecondaryNameNode
5126 DataNode
6124 Jps
YARN的Web客户端端口号是8088,在浏览器输入http://hadoop:8088
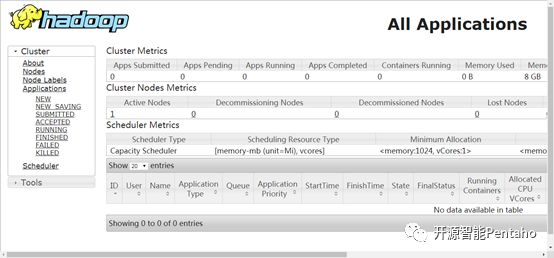
8总结
hadoop伪分布式适合我们平时验证性学习,也可以帮助我们快速学习入门其它的框架比如hive,hbase,spark等。
五、安装Hive
Apache Hive 是Hadoop 生态系统中的第一个SQL 框架。Facebook 的工程师在2007年介绍了Hive,并在2008年将代码捐献给Apache 软件基金会。2010年9月,Hive 毕业成为Apache 顶级项目。Hadoop 生态系统中的每个主要参与者都发布和支持Hive,包括Cloudera、MapR、Hortonworks 和IBM。Amazon Web Services 在Elastic MapReduce(EMR)中提供了Hive 的修改版作为云服务。
1 配置环境变量
配置环境变量HIVE_HOME。
export HIVE_HOME=/hadoop/hive-2.3.2
export PATH=$HIVE_HOME/bin:$PATH

2 配置hive-site.xml
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://192.168.133.1/hive?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>root</value>
<description>password to use against metastore database</description>
</property>
<property>
<name>hive.metastore.uris</name>
<value>thrift://hadoop:9083</value>
</property>
</configuration>
3 添加数据库驱动
mysql-connector-java-5.1.45-bin.jar添加到$HIVE_HOME/lib目录下
4 创建数据存储位置
此步骤,要先启动hadoop。我们在部署Hadoop伪分布式章节已启动相关服务。
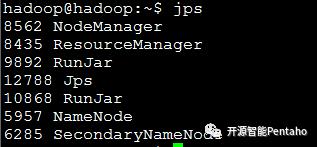
创建数据仓库的存储位置,并赋予权限
hadoop@hadoop:~$ hdfs dfs -mkdir /Hadoop/data/hive/warehouse
hadoop@hadoop:~$ hdfs dfs -chmod g+w /Hadoop/data/hive/warehouse
5 显示查询的表头
为能看到表的数据库和表头信息需要在配置文件(hive-site.xml)里面,加入
<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
6 启动metastore服务
hadoop@hadoop:~$ nohup hive --service metastore >/dev/null 2>&1 &
hadoop@hadoop:~$ nohup hive --service metastore >/dev/null 2>&1 &
[1] 6220
hadoop@hadoop:~$ jps
5776 NodeManager
5648 ResourceManager
6372 Jps
4981 NameNode
5334 SecondaryNameNode
5126 DataNode
6220 RunJar
7 测试Hive
创建表
create table student(id int,name string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ' ';
hive (superstore)> show tables;
OK
tab_name
student
Time taken: 2.003 seconds, Fetched: 1 row(s)
导入数据
load data local inpath '/opt/modules/hive-1.2.1/stu.txt' into table student;
hive (superstore)> load data local inpath '/home/hadoop/student.txt' into table superstore.student;
Loading data to table superstore.student
OK
Time taken: 4.879 seconds
查看导入数据
hive (superstore)> select * from student;
OK
student.id student.name
1001 zhangsan
1002 lisi
1003 wangwu
1004 zhaoli
Time taken: 0.591 seconds, Fetched: 4 row(s)
六、安装Spark
Spark是一个基于内存计算的开源的集群计算系统。在 Scala 语言中实现。
1 配置环境变量
配置环境变量SPARK_HOME。
export SPARK_HOME="/hadoop/spark-2.2.1"
export PATH=$SPARK_HOME/bin:$PATH
2 配置spark-env.sh
在spark-env.sh文件尾部添加下述变量。
export JAVA_HOME="/hadoop/jdk1.8.0_152"
export HADOOP_HOME="/hadoop/hadoop-3.0.0"
export HADOOP_PREFIX=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
export SPARK_HOME="/hadoop/spark-2.2.1"
export SPARK_DIST_CLASSPATH=$($HADOOP_HOME/bin/hadoop classpath)
export SPARK_MASTER_HOSTA=192.168.133.129
export SPARK_MASTER_PORT=7077
export SPARK_MASTER_WEBUI_PROT=8099
export SPARK_WORKER_CORES=2
export SPARK_WORKER_INSTANCES=1
export SPARK_WORKER_MEMORY=500m
export SPARK_WORKER_PORT=8081
export LD_LIBRARY_PATH=${LD_LIBRARY_PATH}:$HADOOP_HOME/lib/native
3 配置Slave
在Slave文件末尾总添加Hostname。
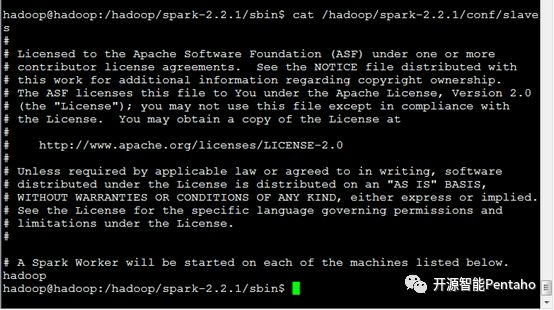
4 配置免密码SSH登陆
Master和Slave处于一台机器,因此配置本机到本机的免密码SSH登陆,如有其他Slave,都需要配置Master到Slave的免密码SSH登陆。
在用户主目录执行下述命令:
ssh-keygen (一路回车)
cd .ssh/
cat id_rsa.pub >> authorized_keys
chmod 600 authorized_keys
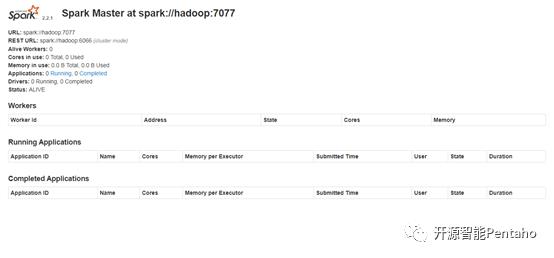
5 启动Spark Master
hadoop@hadoop:/hadoop/spark-2.2.1/sbin$ ./start-master.sh
WARNING: HADOOP_PREFIX has been replaced by HADOOP_HOME. Using value of HADOOP_PREFIX.
starting org.apache.spark.deploy.master.Master, logging to /hadoop/spark-2.2.1/logs/spark-hadoop-org.apache.spark.deploy.master.Master-1-hadoop.out
Spark的WebUI界面端口号是8099,在浏览器输入http://hadoop:8099
6 启动Spark Slave
hadoop@hadoop:/hadoop/spark-2.2.1/sbin$ ./start-slaves.sh
WARNING: HADOOP_PREFIX has been replaced by HADOOP_HOME. Using value of HADOOP_PREFIX.
hadoop: WARNING: HADOOP_PREFIX has been replaced by HADOOP_HOME. Using value of HADOOP_PREFIX.
hadoop: starting org.apache.spark.deploy.worker.Worker, logging to /hadoop/spark-2.2.1/logs/spark-hadoop-org.apache.spark.deploy.worker.Worker-1-hadoop.out
Spark Slave启动成功后,在WebUI界面上可以看到已经有Worker注册。如图:
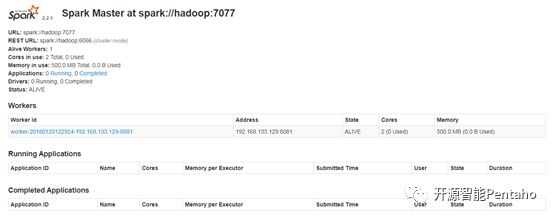
7 启动Spark Shell
hadoop@hadoop:~$ spark-shell --master spark://hadoop:7077
Spark Shell启动成功,在WebUI界面上可以看到一个正在运行的Spark Application,即Spark-Shell,如图:
以上是关于一次记录,如何部署Hadoop生态圈工具的主要内容,如果未能解决你的问题,请参考以下文章