视频干货Hadoop扫盲系列|04-大数据处理模式
Posted 碧茂大数据
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了视频干货Hadoop扫盲系列|04-大数据处理模式相关的知识,希望对你有一定的参考价值。
机构介绍:
数云大数据(Big Data Family)是国内领先致力于大数据技术传播、普及的领航者,同时也是湖南首家大数据教育培训基地的奠基者,专注于大数据培训及咨询服务。企业立足于长沙,辐射全中国!
课程介绍:
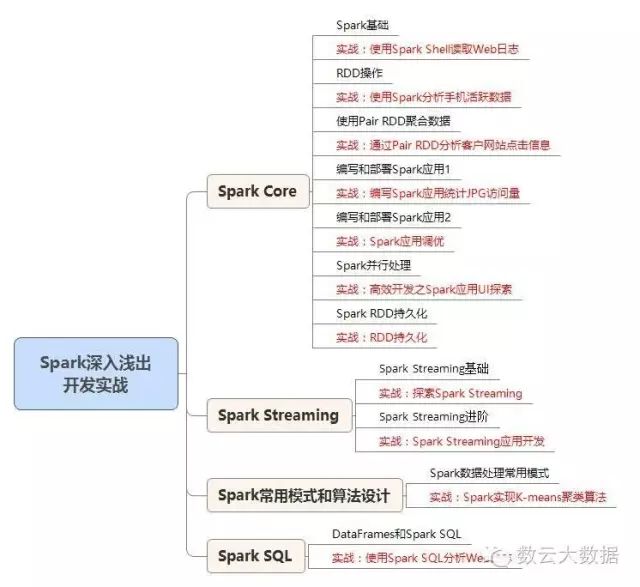
本次课程以Cloudera Hadoop(CDH)平台为基础,通过大量项目实战案例的形式,全面系统地讲解Spark,全方位无死角地打造Spark高级开发员。内容涉及到Spark core、Spark streaming、Spark SQL、Spark算法开发等精彩内容。
学习目标:
1、理解Spark重要概念
2、掌握Spark shell的使用和Spark Application的开发
3、掌握Spark streaming的开发
4、掌握Spark SQL的开发
5、理解Spark的常用模式和重要算法实现
课程大纲:
【大数据之家-湖南大数据培训中心 版权所有】
点击下方“阅读原文”,获取更多干货

关注“数云大数据”,更多干货,客官自取勿谢!
数据驱动 云领未来 www.bigdatafamily.com
以上是关于视频干货Hadoop扫盲系列|04-大数据处理模式的主要内容,如果未能解决你的问题,请参考以下文章