Hadoop-本地模式搭建
Posted 全栈工程师成长记
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop-本地模式搭建相关的知识,希望对你有一定的参考价值。
小编先跳过Hadoop的体系结构这段,后续会补上,先将环境搭建写出来,便于大家能够先对Hadoop有个初步认识做准备,今天主要是写本地模式搭建.本地模式不涉及HDFS(存储),只是对数据的分析,小编会在本地模式搭建完成后,通过Hadoop中自带的WordCount来对文件的单词进行统计.
在搭建环境前,需要先关闭防火墙
1.环境所需的软件
jdk-8u144-linux-x64.tar.gz
hadoop-2.7.3.tar.gz
2.上传到Linux环境
小编是通过SSH Secure连接Linux系统,进行上传,约定好上传的目录为/root/tools
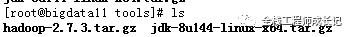
3.解压压缩包
解压的路径也约定为 /root/training
[root@bigdata11 tools]# tar -zxvf jdk-8u144-linux-x64.tar.gz -C /root/training/
[root@bigdata11 tools]# tar -zxvf hadoop-2.7.3.tar.gz -C /root/training/

4.JDK环境变量配置
[root@bigdata11 jdk1.8.0_144]# vi ~/.bash_profile
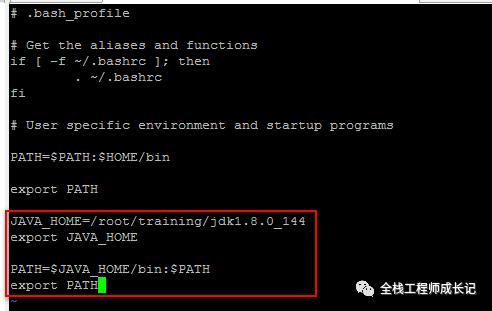
5.Hadoop环境变量配置
[root@bigdata11 hadoop-2.7.3]# vi ~/.bash_profile
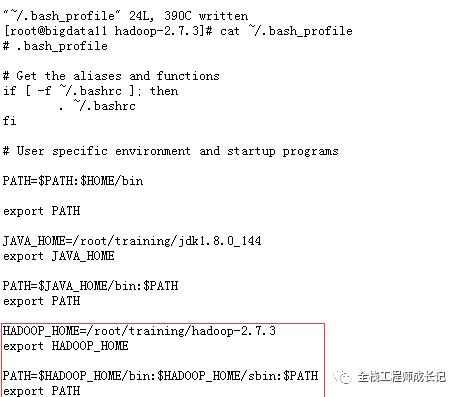
6.生效环境变量
[root@bigdata11 hadoop-2.7.3]. ~/.bash_profile或者source ~/.bash_profile
注意:若使用前面的语句 .和~中间有个空格。
7.修改hadoop下的hadoop-env.sh文件

[root@bigdata11 hadoop]# vi hadoop-env.sh

8.演示MapReduce程序
[root@bigdata11 mapreduce]# hadoop jar hadoop-mapreduce-examples-2.7.3.jar wordcount /root/temp/data.txt /root/temp/dataout
执行后,进入/root/temp/dataout目录中查看结果:
---------------华丽分割线---------------
演示程序中的data.txt需要自己创建,其中的内容为:
I love Beijing
I love China
Beijing is the capital of China
此篇文章主要是环境的搭建,不涉及到结构体系的讲解,大家可以先搭建环境,后续会补充这些相关的理论知识,如果大家学习的大数据知识超过文章的进度,可以与小编留言一起学习讨论.
以上是关于Hadoop-本地模式搭建的主要内容,如果未能解决你的问题,请参考以下文章