mac+vmware搭建hadoop
Posted JOPP的私房喵
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了mac+vmware搭建hadoop相关的知识,希望对你有一定的参考价值。
什么是hadoop
hadoop 是一个分布式系统基础架构。这里分布式和集群好像有点差别。集群是个物理状态,多个服务器实现同一业务;分布式是工作方式,不同业务部署在不同服务器上。形象的说,集群就是饭店厨师忙不过来找了两个厨师做饭;分布式就是一个厨师还找了个帮厨减轻自己的工作压力。
hadoop的核心模块是HDFS和MapReduce,此外还有yran和common。hadoop是开源的,所以你可以自己个性化修改增加模块啥的。
hdfs分布式文件系统
hdfs是hadoop中很重要的一个模块,它解决了大数据背景下数据怎么存的问题。比如你有个1TB硬盘的电脑,但是有个数据大小1PB你要怎么存储?最好想的当然是多找几台电脑每个存一块。那么问题来了,分开存储数据,那我要用的时候,先后顺序等要怎么保证?这就引入了hdfs。hdfs使用一个NameNode(NN)来管理存在不同电脑的数据块,存放数据块的节点叫做DataNode(DN)。NN基于内存存储,只存放数据的元数据,真正的数据会被分块存入DN。
形象的说,NN像老师,DN是每个学生。老师知道每个学生携带了什么书。外面有个人(客户端)进来问老师要借一套三年高考五年模拟。老师就知道小明有数学的五三,小红有语文的五三等等;老师告诉那个人这些信息(谁有什么书),那人就去找小明小红这些学生去拿书,就可以拼接成一套了。注意客户端拿数据块是直接和DN取,也就是借书的人拿书并没经过老师的手,只是问了老师书在哪里,自己去取。
当然,班上同学不可能每本书只有一本,那样的话小明请假了(DN宕机)借书的人就借不到了。班上每本书肯定不止一本,小明有数学五三,小花也有一本一模一样的。这就是hdfs的副本。副本可以保证数据的可靠性。
DN要和NN保持心跳检测,就是学生要隔一段时间告诉老师自己还能工作,书还在(汇报block信息)。不然老师不知道小明书丢了或者逃课了,借书的人来了还把那人指向小明,结果就是不能借一套完整的书。
关于副本放置策略,官网给出的文档说的是第一块副本会在本地或者随机一个服务器上,第二个副本在同一机架不同服务器上,第三副本在不同机架上,但是具体实现第二副本是在于第一副本不同的机架放置,第三副本和第二副本在同一机架不同服务器上。下图是具体实现的副本放置策略。
下面这两个图是hdfs的读写过程
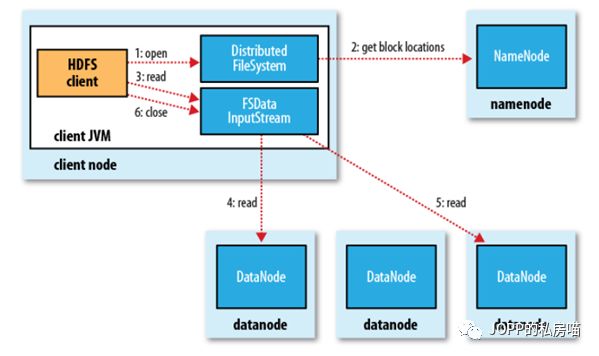
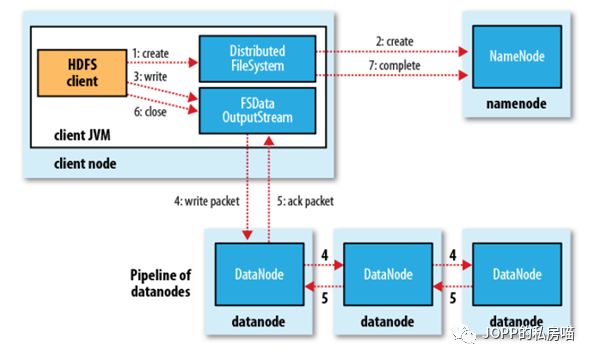
以上是hdfs的最初版本,问题很多。比较重要的就是NameNode 的单点故障。如果NameNode故障,那么hdfs就不能对外提供服务。那么怎么解决呢?
HDFS-HA
既然一个老师病倒了,那肯定找个代课老师啊。ha高可用模型应用而生。使用两个namenode。一主一备。前面说了,NN基于内存存储,主机挂了,那么信息也不存在了,即使备机启动也不能对外提供服务。
这就像是老师把每个人都有什么书记在大脑里,但是老师突然病倒,还没来得及和代课老师说。那么代课老师来了就不能知道谁有什么书,也不能给借书的人提供借书服务了。所以老师想了想,决定每隔一会儿把自己大脑的数据写在小本本上,一旦自己病了,代课老师就可以继续提供借书服务。老师记笔记就是NameNode的持久化。NN的持久化基于editlog和fsimage。editlog就是有人来借书或者还书,老师就在editlog写记录。然后记到大脑里(内存)fsimage是editlog太大的时候,停用这个笔记本,新开一个一样的,然后把这个写满的笔记本和fsimage合并永久存储在硬盘。(editlog只提供追加)。合并这个工作由secondarynamenode来做。
主机可以持久化输出了,但是备机要启动如何还原主机的状态呢?两个方案,第一个是使用nfs,将文件共享,备机就可以读取到了。第二种是交个一个第三方机器,主备机对其进行读写,为保证可靠,使用集群;这就是Journalndoe。
还有一个问题,那就是老师病了,代课老师怎么知道他病了?我们使用一个程序,时刻检测老师,如果老师病了,立刻通知代课老师来上课。这个第三方管理员为了可靠也使用集群。ha模型使用zookeeper来管理namenode。在namenode运行的主机上还有个进程叫做zkfc,它来通知管理员(zookeeper)老师是否健康。hdfs启动时候两个zkfc会再zookeeper集群种创建一个目录,谁创建成果谁管理的namenode就是真正去上课的老师。如果老师挂了,zkfc就会通知zookeeper去让另一个zkfc叫它管理的老师去上课。当然,其实zkfc也是个进程,偶尔也会抛锚。zkfc和zookeeper是保持常连接的,一旦zkfc挂了,那么zookeeper就会让另一个zkfc去叫老师不要上课了,让它管理的代课老师上。因为老师的监管已经不在了,有着潜在的风险。
下图就是ha模型
MapReduce
hdfs解决了数据如何存储,那么MapReduce就是解决数据如何计算。
MapReduce分map阶段和reduce阶段。网上的一幅图很好的解释了这两个过程
map就是分数据,reduce就是组合计算数据。这个具体过程在下一篇文章会以hadoop的示例wordcount来说明。
形象的说,你要数一个图书馆(假设他们没有归类)每种书的数量。那么你可以每个书架雇佣一个人来数,几千个人一起数,每个人把自己书架的书以书名和数量统计出来。然后再来几十个人,每个人对应某一规则的书名(比如第一个人对前面统计的人说书名A开头的书名和数量都报给我)把前面几千个人的相同书名的数量相加。以此类推,最后就得出所有书籍的数量了。上述过程每个人统计书架的数据就是map ,每个人把相同书名报个对应的一个人叫做shuffle,然后拿到相同书名做加法的过程就是reduce。这就是MapReduce的工作过程。
今天写到这里,你真的不关注一下吗?
以上是关于mac+vmware搭建hadoop的主要内容,如果未能解决你的问题,请参考以下文章