如何在VMware上部署Hadoop
Posted Hadoop实操
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何在VMware上部署Hadoop相关的知识,希望对你有一定的参考价值。
温馨提示:要看高清无码套图,请使用手机打开并单击图片放大查看。
Fayson的github:https://github.com/fayson/cdhproject
提示:代码块部分可以左右滑动查看噢
本文约2万字,阅读时间约为20-30分钟。
1.文档编写目的
本文主要讲述如何在虚拟机(VM)上部署Hadoop,因为虚拟化技术很多家都有,但本文讨论的是VMware。建议阅读人群为:系统管理员,架构师或者开发人员。
无论你是在vSphere上新建Hadoop集群还是重构现有基于裸机的环境,都可以参考这篇文章。根据业务场景的特定需求和可用资源,你还可以参考文中的几种部署方式。
本文主要包含以下内容:
Hadoop架构概述
在vSphere上部署Hadoop的注意事项
vSphere上的Hadoop架构和配置,包含三种参考部署方式
本文的目录如下图所示:
2.Hadoop架构概述
本章主要向读者介绍一些Hadoop入门知识,有些读者可能不太熟悉Hadoop的一些基础知识,却很熟悉vSphere,然后想在vSphere上部署Hadoop。
文末的"参考文献"章节给出了很多进阶的技术资料供参考,适合那些比较熟悉Hadoop的读者。当然本篇文章也参考了这些技术资料。本章讨论的Hadoop内容主要是为后面的部署架构做铺垫,如果您很熟悉Hadoop,可以跳过。
Hadoop分布式系统起源于Google,然后再到Yahoo,主要是为了解决分布式存储和处理大规模的数据。起初主要用于网站索引,特别是搜索。后来成为Apache社区的顶级开源项目。
Apache Hadoop是一个编程框架,运行环境,文件系统和数据存储,同时也是一个可靠和可扩展的分布式计算框架。Hadoop有Apache社区版,同时还有几家商业公司,包括Cloudera,Hortonworks,IBM,MapR和Pivotal,他们基于Apache社区版提供自己的发行版。这些发行版往往还集成了大量其他的组件,有些是开源的,有些是闭源或专有的。这些组件一般都是管理工具或查询Hadoop数据的SQL引擎,每家都会有一些不一样。在接下来的文中,我们把所有这些相关版本,包含Spark,统称为"Hadoop发行版",或者简称为"Hadoop"。但主要还是以核心组件为主。
所有上面提到的这些Hadoop发行版都可以运行在vSphere上。文末的参考文档[1], [2],[3],[4]主要是Hadoop发行版在vSphere上的性能测试报告。VMware与Hadoop发行版公司进行合作,在vSphere上为各个Hadoop发行版提供验证和支持。
Hadoop通常用于跨多台机器的集群的大数据集处理。它可以扩展到数千台机器,每台机器可以同时都参与数据存储和计算。很多企业选择Hadoop,并将其用于大量的定制和封装的应用程序,通过分析更大以及更多样化的数据来帮助企业进行更好的决策。Hadoop已经成为大数据的代名词,它主要包括以下几个功能:
ETL工具
MapReduce
Spark
事件流
机器学习
其他用于分析应用的功能如SQL
围绕着Hadoop的核心,整个生态系统有非常丰富的工具。
Hadoop包含两个主要组件(也称为Hadoop核心):Hadoop Distributed File System(HDFS),用于存储数据;计算资源框架YARN,用于运行作业处理数据。在Hadoop早期,计算框架被称为Hadoop MapReduce,是当时主要的编程框架。近几年来,这一块得到了补充和改进,甚至很多场景我们还替换掉了MapReduce,它就是新的编码API以及执行引擎,Spark。Spark和MapReduce是现在在Hadoop之上主要的两个分布式执行框架。
整个生态系统还有很多其他的技术基于Hadoop核心:Hive,Pig,Sqoop,Flume,Oozie,Impala等。这些组件都不在本篇文档的讨论范围之内,有关这些工具的更多信息,请访问相应Hadoop发行厂商的网站。
Hadoop平台采用“分而治之”(divide and conquer)的方法来处理大量数据,并产生结果。在Hadoop平台执行的任务都是并行的,所以它们很适合分布式环境。Hadoop最新的作业调度和资源管理被称为YARN(Yet Another Resource Negotiator)。它是随着Hadoop2.x一起推出的新的资源管理框架。最开始的资源调度框架是以MapReduce为核心的,其不灵活已经被证明了。重新设计开发的作业资源调度框架YARN更通用,并可以满足不同的工作负载。
在Hadoop YARN架构中,主要的Hadoop角色或进程包括ResourceManager,NameNode,NodeManager和DataNode。在一个Hadoop系统中,这些角色以Java程序的方式在各个节点长时间运行。架构中还包含一些其他的角色,比如ZooKeeper和JournalNode,它们主要提供管理和协调的功能。为了简单起见,本篇文档基于VMware的方案不会包括这些角色。有关更多其他服务相关的信息可以访问Apache Hadoop相关文档或者Hadoop发行厂商的网站。
ResourceManager进程根据请求分配CPU和内存资源给计算进程。同时ResourceManager还会负责Hadoop集群中的所有作业调度,同时包括单个任务(task),这些task组成了作业(job)。一个作业会被分成多个任务,然后在工作节点的容器中(container)执行。通常工作节点都会非常多,几十个,几百个甚至上千个,但是管理节点一般都不到10个。
工作节点上的NodeManager进程负责启动容器(containers),这些容器都是一个一个的JVM进程,容器中会运行task并将进度汇报给中央调度程序ResourceManager。许多容器会在多个节点上同时运行。它们受控于本地的NodeManager,包括容器的启动和停止。
HDFS是类似Linux的文件系统,包括多级目录和大量文件,一般分布在多个节点上。它由一个或者多个NameNode进程进行管理,NameNode中保存一些元数据信息如block或者目录信息。同时还会有Secondary NameNode或者Standby NameNode,对于超大规模的集群,可能还需要多个NameNode,即联邦。
NameNode是HDFS的管理进程。它需要将元数据(如块对文件的映射)保存到内存中,所以它往往需要大量的Java堆空间。NameNode与一组DataNode进程一起协同工作,每个DataNode负责不同机器上的一组HDFS数据。当有请求过来时DataNode的工作主要是负责写入和查询这些数据块。HDFS通过数据副本来保证数据的高可用,以免DataNode故障影响整个集群。默认情况下,HDFS的副本数为3,当然你也可以修改这个复制因子。
NameNode通过维护所有文件名及其关联的数据块的映射关系来管理文件系统命名空间。NameNode保存所有DataNode的列表,包括文件系统中的任何数据块,包括复制的块。
一个完整的Hadoop系统,主要包括以下三类机器:
运行ResourceManager和NameNode进程的节点,一般被称为集群的管理节点。
包含DataNode和NodeManager进程的工作节点。
还有一些节点,主要负责与最终用户交互从而提交作业到集群,一般可以比称为"client","gateway"或者"edge node"。这些节点上一般包括比如Pig或者Hive的客户端配置,当然还有一些其他的集成从而保证可以提交作业。
在Hadoop系统中,还有一个Secondary Namenode,用来备份NameNode的元数据。如果NameNode挂了,Secondary NameNode上的元数据可以用来恢复整个系统。必须保证NameNode状态的运行健康,因为HDFS上所有数据的操作都依赖于它。
如图1所示,一个小型的Hadoop集群中的一个节点一般包含ResourceManager和NameNode服务,以及多个工作节点。如果是非常大规模的集群,ResourceManager和NameNode会分开部署。
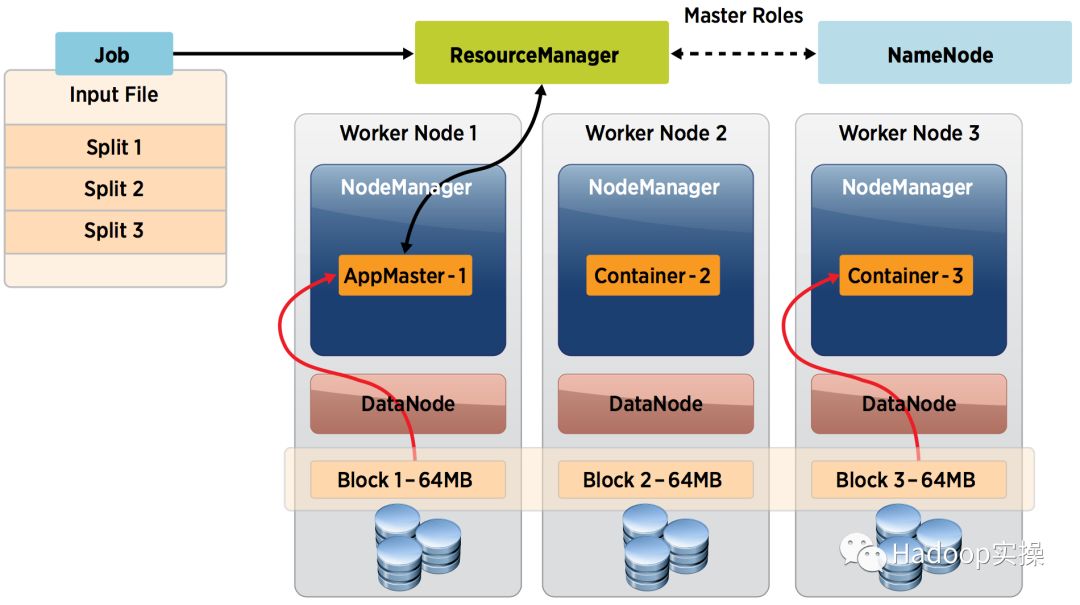
图1:Hadoop架构的各个组件
在图1中,管理节点包含ResourceManager和NameNode服务。每个工作节点包含DataNode和NodeManager服务。还有一些其他的搭配方式,比如只保存数据的工作节点,或者只用于计算的工作节点。
2.1.The Hadoop Architecture on vSphere
当Hadoop被虚拟化后,Hadoop的所有组件的进程包括NameNode,ResourceManager,DataNode和NodeManager,都是在一组VM的OS中运行,而不是基于裸机的OS。这些进程有时被称为Hadoop服务或者守护进程。VM中包含与物理机器完全相同的进程,可以如图1进行布局。
本篇文档,我们使用术语虚机(virtual machine)代表我们以前常在物理机上说的节点(node),然后一个VM可以包含一个或多个Hadoop进程。
我们可以使用Hadoop厂商的工具在VM上来安装这些Hadoop进程,比如Cloudera Manager,Ambari或其他。这种安装无论是在物理机还是虚机,基本相似,只是说以前你是在物理机上实现整个安装过程,现在则是换到虚机上。Hadoop虚拟化后,2个或多个“工作VM”可能会同时运行在一个物理机上。这样如果有多的物理资源(存储或计算资源),我们可以直接在Hadoop集群中扩容新的虚拟机工作节点,而不用去采购新的硬件。这可以让你在扩容集群时节省大量时间。
有些VM可能会在同一个vSphere的物理机上运行,这会导致Hadoop虚拟化后拓扑结构有一些不一样。一个可能发生的情况是同一个HDFS的数据块虽然在不同的VM上,但是可能在同一个物理机。如果这样,当整个物理机故障时,三副本数据的高可用将没有意义。这时我们需要启用Hadoop Virtualization Extension(HVE),这个是VMware贡献给Apache Hadoop的代码。Fayson会在以后的文章对这个功能进行详细说明。
在物理机的Hadoop集群中,管理HDFS的NameNode,我们一般会部署在一台专门的物理服务器上。NameNode管理HDFS文件系统元数据,包括HDFS数据块与文件的映射关系等。当Hadoop虚拟化后,NameNode进程可以部署在一个虚拟机上隔离运行。如果同一台物理主机资源充足,其他的一些Hadoop服务可以部署在另一些VM上,但都基于同一个物理机。
对于ResourceManager进程,如果是物理机的部署,一般也会在单独的服务器上运行,用于管理作业调度和资源分配。在vSphere环境中,常见的是把NameNode和ResourceManager部署在不同的VM上,而且是基于不同的物理机。在较小规模或者实验集群中,你也可以把他们放置在同一台物理机的不同VM中。出于安全角度考虑,如果是NameNode或ResourceManager的Secondary,Standby节点,建议还是单独放置到不同的物理机的VM中,以保证集群真正的高可用。
在有些Hadoop的集群部署中,HDFS组件如NameNode,Secondary NameNode和DataNode进程,会被某些厂商的其他的组件解决方案替代,该组件以兼容的方式提供相同的HDFS APIs。比如由Dell-EMC推出的Isilon,它以NAS(network-attached storage)的形式为Hadoop提供服务,跟MapR的解决方案有点类似。
在Isilon的部署中,NameNode和DataNode的服务,通过Isilon OS上称为OneFS的软件功能来实现。NodeManagers和需要访问文件和数据的容器(containers),当它们需要消费HDFS APIs或RPCs时,OneFS可以提供与NameNode和DataNode相同的服务,功能上没有任何区别。这种存储和计算分离模式在数据采集和减少整体数据存储资源都有相应的优势。业务数据可以通过NFS,CIFS,SMB,HTTP,FTP以及其他的协议进行加载,然后在HDFS中读取,不需要额外的数据采集步骤。
当你将Isilon NAS系统配置为HDFS后,vSphere系统上的VM就是“仅计算”(compute-only)的节点,主要包含NodeManager和执行作业的容器,以及在单独的机器上的ResourceManager。但是这些VM上将不再包含HDFS存储。这样可以让更多的“仅计算”的VM运行在物理服务器上,假设你的物理服务器存储不够但计算资源充足的话。
2.2.Hadoop虚拟化的好处
以下我们看看在vSphere上虚拟化Hadoop后的好处:
1.更好的资源利用率:将大量硬件服务器给一个Hadoop集群专用一般都比较浪费资源。尤其是当这个Hadoop集群有时候没法完全用满所有硬件资源的时候。所以我们经常会碰到是否需要将一些硬件资源或者存储资源共享给多个Hadoop集群的情况。
通常来说,一个企业一般会有三个集群比如开发,测试以及生产,对于一些大的企业可能会更多。传统的做法一般是每个集群都是专门的硬件服务器。但是通过虚拟化,我们可以共享这些硬件资源。
还有一种可能,你的开发集群比其他集群所使用的Hadoop版本都要新,因为开发人员一般都愿意使用最新的版本,或者体验最新的一些Hadoop功能。这就是你为什么需要将Hadoop虚拟化的第二个原因。将一套硬件只用于一个版本的Hadoop,或者只用于一个厂商的发行版,往往并没有充分利用资源。
把Hadoop的虚机节点搭建在主机的多个VM上以支持不同的工作负载也是可以的,尤其是在性能不那么重要的时候。这样可以平衡整个系统的资源使用。通过整合不同的硬件资源,或者不同时间段的硬件资源比如白天或晚上,可以更好的提升应用程序的整体资源利用率。
2.备用的存储选择:本来,Hadoop推荐的是DAS(direct attached storage)。在vSphere上基于DAS的存储方案,我们在很多生产系统的虚拟化Hadoop集群中都可以看到。但是在某些工作负载的情况下,在vSphere上的共享存储的方案依旧有一定的使用场景。
对于一个小规模的Hadoop集群,比如10个或者更少的节点,应用程序的数据可以完全放在共享存储上。对于中型或者大型的Hadoop集群,使用多种存储的混搭模式可以实现更好的性能。对于混合存储的选择,比如Hadoop底层使用DAS,其他部分可以选择SAN(storage area network)或者VMware的vSAN。NameNode和ResourceManager往往使用较少的存储资源,从可用性角度考虑,可以把他们放置在SAN或者vSAN上。为了实现更高的资源利用率和更快的性能,可以将HDFS的数据或者临时数据放在DAS上,当然还可以选择把HDFS数据放在NAS型共享存储上比如Isilon。
3.隔离:包括在同一批硬件的集群之上运行多个不同版本的Hadoop,或者Hadoop与其他应用系统共存,形成一个可以被各种Hadoop租户使用的弹性环境。
4.可用和容错:vSphere的一些功能,比如VMware vSphere High Availability(vSphere HA),和VMware vSphere Fault Tolerance(vSphere FT)可以让Hadoop组件免受服务器故障带来的影响,从而提高可用性。资源管理工具比如VMware vSphere vMotion可以用在服务器有计划的停机或者维护期间,从而提高集群的整体可用性。
5.效率:VMware可以在现有的虚拟化基础设施上轻松高效的部署Hadoop,并将Hadoop集群专用的硬件整合到数据中心和云环境中。
6.快速配置(Rapid provisioning):vSphere可以在虚拟化和云环境中实现Hadoop的快速部署,管理和扩展。从简单的克隆镜像到最终用户需要的复杂配置,VMware的工具比如VMware vRealize Automation可以加快Hadoop的部署,因为在大多数情况下,Hadoop需要很多个节点,而且节点的配置又是不一样的。在新建的VM过程中,集群配置步骤都是并行执行的,从而缩短部署时间。
通过添加一些适当的自动化工具,基于虚拟化的基础架构,可以让用户实现Hadoop集群实例的按需创建。
2.3.部署前置条件
开始在虚拟化环境上部署Hadoop集群之前,请确认以下要求已满足:
1.精确计算需要数据存储的空间
存储在HDFS中的数据
HDFS之外的数据(Hadoop在作业处理过程中的临时文件,buffer-spill,或者shuffle数据)
HDFS会将应用程序的输入和输出数据保存到一个或多个文件中。计算输入和输出文件的大小时,需要考虑默认的复制因子3,同时还有需要的临时空间。对于不同的应用程序,数据副本的数量可能不同。临时数据的大小可能会大于输入或者输出数据大小。临时数据通常不是保存在HDFS中,所以大小和存放位置要单独考虑。
3.确保有足够的物理内存。在VMware ESXi和guest OS级别都没有进程的内存交换(process swapping)。为了避免在ESXi级别有内存交换,请确保有ESXi主机上的所有虚拟机以及虚拟机管理程序有足够的物理内存。具体请参考附件[6]
4.确保虚拟机有足够的内存。为了避免在guest OS级别有内存交换,请确保为虚拟机的所有常驻进程以及OS所需配置了足够的内存。尤其还需要注意Java的堆栈大小,缓冲区缓存大小以及将要运行的进程的内存需求。请咨询Hadoop厂商,以了解各个组件或进程所需的内存大小建议。
5.最后,还需要决定使用多少台物理机,以及每台物理机上有多少个虚拟机。在Hadoop测试的早期阶段,使用少于10台物理机是比较常见的。这也是Hadoop厂商一般推荐的。开始的时候在每台物理机创建两个虚拟机,后期根据实际情况还可以增加。对于一些比较重要的生产系统,本文后面也会介绍的,一台物理机上创建两个虚拟机是一个标准,所以对于一个测试系统也是很好的开始。
当创建完一个Hadoop集群后,最好在集群上运行一些示例的代码或者例子保证集群的健康和可用。通过Cloudera Manager或者Ambari来管理和监控集群的性能。Hadoop厂商一般都提供了一些这种示例代码或者例子来方便进行基准测试。比如测试MapReduce的应用程序,可以使用Terasort。Spark或者其他的应用程序,也可以选择相应的例子代码或工具。
3.参考架构
本章重点讨论Hadoop虚拟化的注意事项,同时提供几种搭建Hadoop集群方式的选择。因为不同企业的基础设施都有一些不同的限制,所以我们不止提供了一种方式。
另外,在Hadoop平台上运行的多种多样的应用程序,可能是基于不同的组件,它们的计算资源消耗其实有很大的差异。比如,MapReduce的应用和Spark程序的资源消耗就会有很大的不同。再比如,与机器学习相比,ETL和数据抽取对于基础设施的资源压力也会不同。同时,这两种应用程序处理的数据量也会不一样。
由vSphere管理的Hadoop平台的基础设施,同时也需要适应不同的应用作业类型,同时提供相应的服务。
本章由三部分组成。第一部分主要是概述做架构设计时需要考虑前置条件。
第二部分主要是之前讨论的Hadoop服务比如NameNode,DataNode,ResourceManager等在VM上的对应。同时我们讨论两种存储方式DAS和NAS,用于HDFS存储数据,或者存储其他应用所需的数据。到底选择哪种有一些权衡。
第三部分主要是讨论系统配置包括集群规划,可用性,硬件选择,和网络,这些都是构成特定架构的基础。介绍了几种选择,但是没有一种是能满足所有需求的,选择哪种都会有一些折衷考虑。
3.1理解应用需求
估计一个Hadoop集群的资源消耗(CPU,内存,存储)在项目开始前期是非常重要的。这些可以让你好好规划你的集群,是架构规划中很重要的环节。细节会在后面的内容中讨论。
企业内部负责Hadoop平台的人在需要将已有的基于裸机的Hadoop集群迁移到vSphere或者在已有VMware的数据中心环境中搭建Hadoop时,需要考虑诸如已经存在的一些存储和网络等约束条件。
在搭建一个虚拟化的Hadoop集群之前,首先要估算数据量的大小,了解应用程序,查询作业以及网络流量的类型。这些信息一般来自于用户,应用程序设计,开发team,和Hadoop厂商。以下是你需要考虑的一些数据:
需要抽取到Hadoop集群的数据量,以及抽取频率。
随着时间推移,预期的数据增长量。
在应用程序处理各个阶段需要的临时数据存储空间,比如shuffle和spill到disk的空间。
写入到HDFS的数据量。
读写数据所需要的吞吐和带宽,如:读写需要多少MB/S
数据的复制因子:数据块需要被复制和存储的次数。
block size的大小,通常是128MB/256MB,是否要更大。
业务应用程度是属于什么类型的工作负载,通常是CPU密集型,I/O密集型,或者网络密集型,与一些基准测试的应用程序可以进行对应,比如TeraGen, TeraSort, TeraValidate, 或BigBench。
列出需要部署到Hadoop集群的所有应用程序。
各个应用程序在一个或多个Hadoop集群的优先级。
多租户考虑和设计,比如给每个租户要分配多少资源。
以上所有的信息都搜集完整以后,就奠定了Hadoop集群设计的坚实基础。
3.2.Hadoop集群的部署方式
本章主要介绍几种Hadoop主要组件部署的方式。同时也会说明选择部署方式的基本原则。这些部署方式都已经成功在多个vSphere系统中验证了的。
图2是两种基本的拓扑选择。你可能需要考虑其他更多的复杂因素,但这里我们先探讨基础知识。图中的计算(compute)是指NodeManager进程,以及它管理的所有container或executor,数据(data)是指DataNode进程。
我们先假定NameNode和ResourceManager管理节点服务会放置在其他单独的虚拟机中。有时候管理节点你还可以部署一些其他轻量级的Hadoop服务,比如History Server等。这里我们把讨论重点放在VM的工作节点上,因为它是最多的。
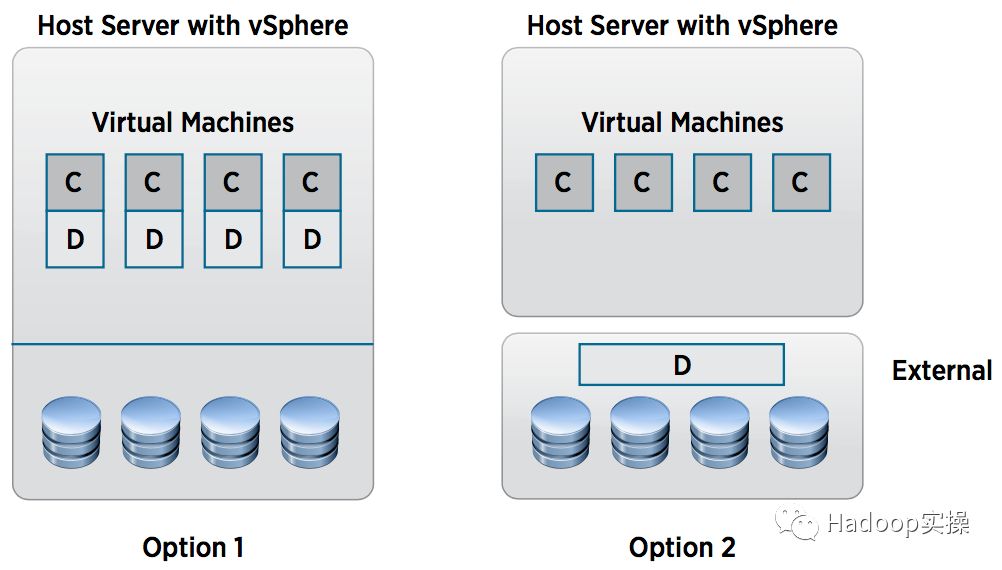
图2:Hadoop工作节点在虚拟机上部署的两种选择
C =Compute/Processing logic (e.g., NodeManager)
D =Data/Storage handling logic (e.g., DataNode)
图2的选项1中,compute (C)和data (D)角色合并到了一个VM中。选项2中,data/storage functions (D) 放置在了其他的地方,比如支持HDFS的NAS,或者其他的外部(“external”)存储。这两种模式有不同的好处,接下来的章节我们会讨论它们的架构。当然还有其他的部署模式,可以查看参考文章中的[7]和[8],不过现如今很少用到。所以我们接下来的讨论重点会放在比较流行的部署模式上。
3.3.架构1:合并计算和数据节点
在这个架构中,NodeManager和DataNode进程会在同一个VM中,就和物理机部署一样。这也是我们部署Hadoop的标准方式。在任何一台vSphere的主机中可能运行多个这样的虚拟机。每台物理机的VM数量受限于这台物理机的可用资源以及每台VM所有进程所需的最低资源要求。
在参考文章[1], [2], [3]和[4]中,每台物理机部署几个VM都有不同的性能测试说明。目前,这种模式在企业内的Hadoop虚拟化集群中是比较常见的。各个Hadoop厂商的架构师也非常熟悉这种架构。这种模式同样也是比较节约成本的,因为DAS磁盘的成本比其他方案要低。但是,它不是唯一的选择。
为了说明这种架构示例,图3代表的是一个vSphere主机有12个本地的DAS磁盘,然后配置了2个VM,每个VM有6块磁盘。这种数目的磁盘只是一个例子,现在的服务器可能有更多的磁盘。你同样可以选择SSD或者闪存来部署该模型。
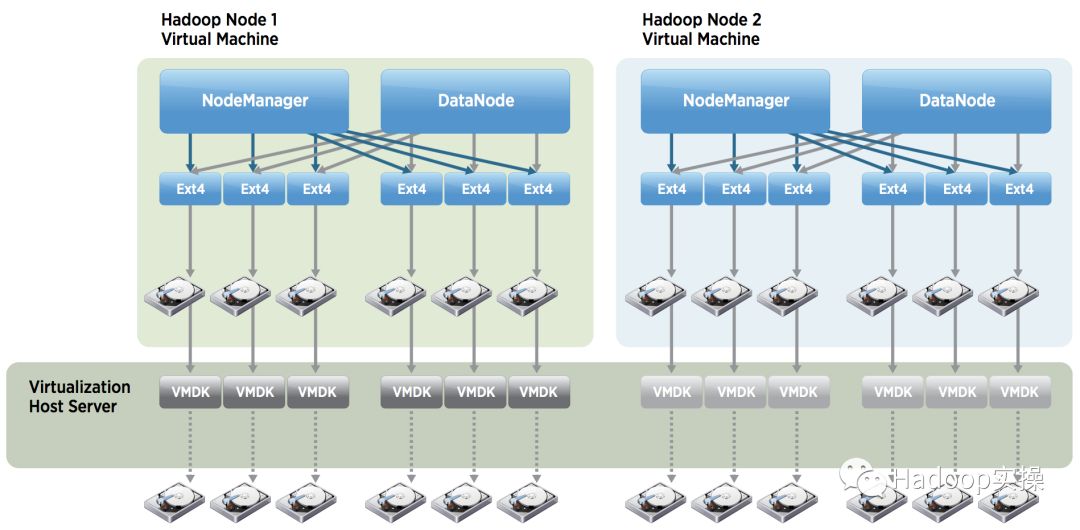
每个VM有6个本地的DAS磁盘
图3:一个ESXi包含多个运行Hadoop工作进程的VM
在这个示例中,有12块DAS磁盘的主轴(spindle)直接连接到vSphere的主机服务器。每个磁盘的主轴(spindle)都是作为vSphere的一个datastore。vSphere的每个datastore都包含一个虚拟磁盘文件(VMDK),而且该VMDK文件与一个VM相关联。也就是说每个VM会独占属于它的datastore和磁盘主轴(spindle),这样避免了访问的争用问题。如果争用不是问题,可以将不同VM中的这些VMDK文件放到同一个datastore中。但我们的最佳实践是任何一个磁盘设备或者datastore都应该只属于一个VM。
NodeManager和DataNode进程可以访问各自单独的OS目录以实现读取和写入数据。这些目录通过vSphere的VMDK和datastore映射到物理磁盘。VM上用于存储OS以及磁盘交换空间可以放置在物理服务器另外的DAS磁盘中,这些磁盘不会存放HDFS数据。为了简单起见,上图3其实是省略了这一点的。VM上用于存储OS以及磁盘交换空间还可以放置在单独的共享存储上。如果没有可用的共享存储,你可以将OS以及磁盘交换空间放到vSphere的datastore上,这些datastore是在配置了raid的几块本地磁盘上的,从而可以避免磁盘故障导致数据丢失。
每台vSphere主机同时部署多个VM可以更好的利用硬件的资源。在文末的参考文献[1], [2], [3]和[4]中描述了一台物理机部署多个VM作为Hadoop工作节点的性能测试报告,每台物理机上有多个VM,每个VM都是一个Hadoop的工作节点,这种方式对于整体系统性能带来了显著的提升。一台物理机的DAS磁盘会平均分配到各个VM,它们只能由专门的VM单独访问。
如果是Hadoop的开发或者测试环境,有时候其实不在乎性能,所以也就没必要给每个VM单独配置专门的硬盘,几块硬盘被多个VM公用也是可以的。但是如果是比较正式的测试或者开发系统,还是建议你采用图3推荐的方式。
图3显示的磁盘访问分离的方式解决了一台物理主机上2个VM公用同一块硬盘的争用问题。以这种方式你可以给一台VM分配多块专用磁盘。建议以这种方式配置6个或更多的专用磁盘给任何一个VM。
3.3.1.使用DAS部署管理节点
Hadoop的管理节点比如NameNode和ResourceManager,一般也会放置在单独的VM中。其他的几个管理角色比如Zookeeper和JournalNode也会部署在这些VM中。这种方式与物理机的部署是一样的。参考文档[1]对这一块有更详细的描述。
如果你有共享存储比如SAN,vSAN,或者NAS,那你可以将这些管理节点的数据存放在共享存储中,从而可以利用vSphere的HA和FT的好处。如果没有共享存储,则不适用。具体可以查看参考文档[13]。
另一个替代方法是使用一部分本地DAS磁盘用作管理节点VM的OS存储。可以依旧使用两块硬盘配置为RAID1或者更多磁盘配置为RAID10.然后将vSphere的datastore放在这些磁盘上。NameNode和ResourceManager的VM的VMDK的文件就放到这些datastore上。具体可以查看参考文档[1]和[4]。
除了可以将DataNode和NodeManager放置在同一个VM,你也可以分离这两个角色放置在不同的VM上。这样你在扩容NodeManager时,避免了数据重平衡。不过使用DAS的场景下,这种方式极为不常见。查看参考文档[7]和[8]。
3.3.2.存储应用程序的临时数据
对于Hadoop的工作节点,还需要考虑临时和shuffle数据空间。这些临时空间对于特定的应用作业是不一样的。它不会用来存储HDFS数据,但它对于一个作业的完成也是很重要的,比如Memory不够用的时候需要spill到磁盘,或者一些shuffle数据。这些数据会被保存在OS的本地目录中。
例如,Hadoop基准测试TeraSort需要输入数据两倍的空间用于存放这些临时数据。而TeraGen或者TeraValidate则不需要大量的临时数据空间。所以不同的应用程序或者工作负载对于临时数据空间要求不一样,我们在Hadoop集群规划前要提前做好规划。
对于传统的MapReduce程序,研究表明,超过50%的总I/O用来读和写临时数据。这些临时数据主要用于sort,shuffle和缓冲溢出阶段。未来,临时数据可能会被存储在HDFS中,不过本文不讨论。
HDFS和临时数据的访问速度对于Hadoop的性能至关重要,所以HDFS和临时数据对于磁盘的吞吐要求较高。主流的Hadoop厂商一般推荐每个CPU虚拟内核需要100-150MB/S的吞吐。对于这种高吞吐要求的应用,SAN共享存储技术可能无法满足。你可以用存储设备(比如所有机器的所有磁盘)的总吞吐去除以所有虚拟内核的总数,看是否达到100-150MB/S。这种算法适用于所有存储模型。
存储设备的I/O吞吐到底多少是由不同的厂商决定的,这里不再讨论。如果你对集群的I/O性能没有特别较高的要求,也没有SLA,传统的SAN存储对于小规模集群是够的。当你对I/O吞吐要求较高,而且有特定的SLA的时候,你需要考虑选择DAS,闪存或者SSD。
3.4.架构2:NAS架构
这个章节主要是介绍使用NAS存储作为HDFS,这类存储具备了HDFS的功能,比如Isilon。Isilon由一组可扩展的文件服务器组成,这些文件服务器通过他们自己的OS提供类似HDFS的接口。Isilon OneFS OS可以配置为实现NameNode和DataNode的RPC接口。源生的HDFS和Isilon OneFS文件系统处理数据时有点不一样。如下图4所示,所有HDFS数据都是存储在Isilon NAS上。组成Isilon NAS的任何服务器都可以响应NameNode和DataNode功能的请求。这些请求会自动在Isilon NAS的内部网络中进行负载均衡。
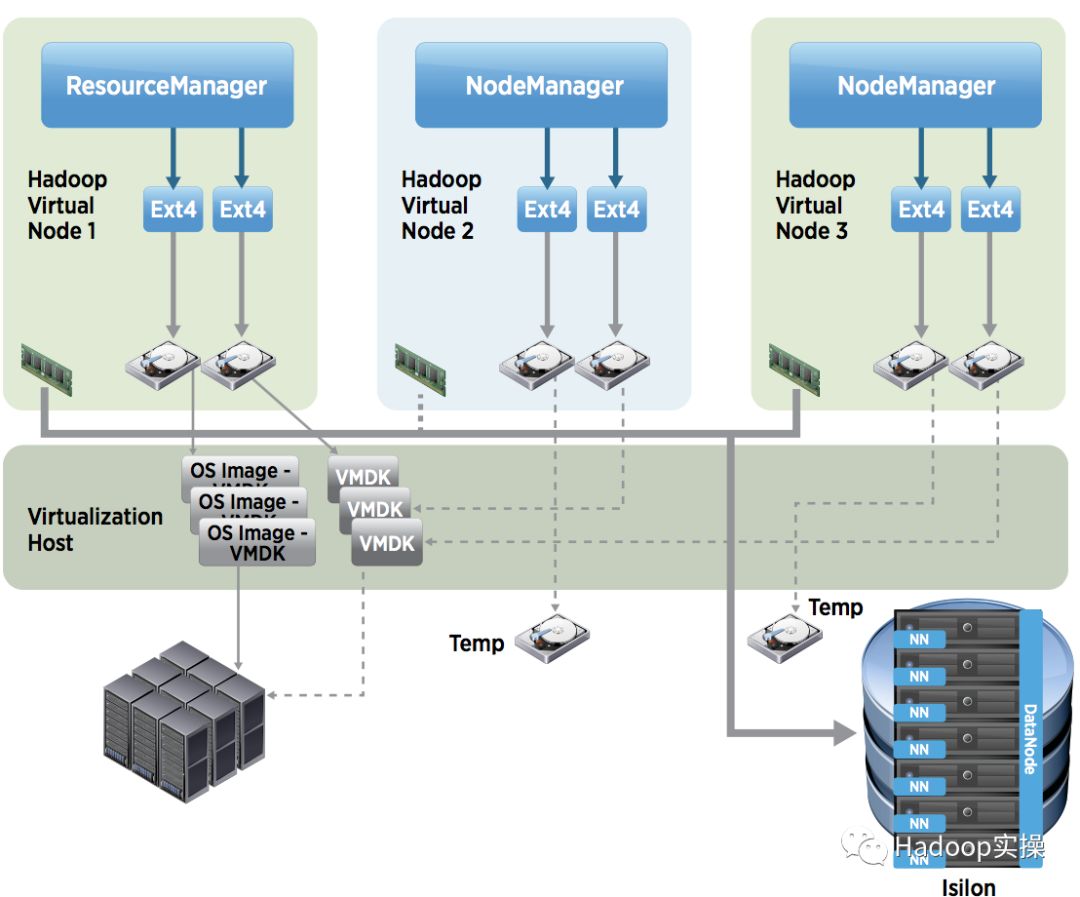
图4:Hadoop虚拟化使用NAS实现存储和计算分离
除了HDFS文件,VM的OS文件可以存储在VMDK文件中,这些VMDK是存在后端的SAN共享存储上的。你在图4的左下部可以看到。对于VM存在SAN上的数据,你可以考虑使用vSphere的特性比如VSphere vMotion。基于NAS的架构可以查看参考文章[10]和[20],这里不再讨论。
以下是这种架构的好处:
1.存储消耗降低,因为诸如Isilon这种不需要像DAS一样存放三副本。
2.可以直接通过NFS,FTP,HTTP或者其他协议将数据放置在Isilon中,而不用再次导入HDFS。HDFS支持这些数据传输协议毕竟没有这些传统设备那么好。
3.不像传统HDFS在一个数据中心是跨很多个服务器,这种方式是集中式的,对于数据管理更加划算。
4.如果一个存储设备挂了,用于控制的OS会检测到并重新进行配置。
5.对于业务数据的访问通过专有网络集中到一个存储设备上。
这种NAS架构将存储和计算进行了分离。企业中采用10Gb甚至更高的网络越来越普遍,Hadoop需要的存储和计算都在本地的要求变得越来越没那么重要。
通过存储和计算分离,Hadoop管理员现在可以随意调整工作节点即NodeManager的数量,而不会影响存储的数据。这样使Hadoop具备了动态伸缩的能力。数据层同样也具备这个好处。
回到图3,如果我们要增加一个新的节点,需要同时增加DataNode和NodeManager服务,意味着我们需要重新平衡数据。在这第二种架构中,我们避免了数据重平衡,通过分离存储和计算的方式,工作节点中不包含DataNode进程,成为“仅计算的工作节点”。
3.4.1.将NAS用作其他存储
在最初搭建一个Hadoop集群时,架构师一般都会考虑利用已有的虚拟化设备,这些一般都是利用SAN或者NFS共享存储来保存VM的数据。这样做的好处是可以减少对基础架构的改动。使用已有的服务器,并且用NAS来作为HDFS存储是可行的,但是应该如何处理临时数据成为一个问题。
对于不使用DAS的VM一个重要的问题就是如何处理因NodeManager,ApplicationMaster以及containser产生的临时数据。
如果对这些临时数据的I/O带宽(bandwidth)进行测试,可以发现其实没那么密集(less intesive),比如在10台或者更小规模的集群中,可以将这些数据就放在SAN或者NFS的共享存储中。但应该监控Hadoop及应用程序对存储I/O带宽(bandwidth)的消耗。以前,这种方式有瓶颈,主要是在连接SAN的时候。Hadoop中的I/O本质是长时间的连续读写数据块,每个数据块可能有数百个MB。这与SAN被设置为IOPS-intensive的I/O类型不匹配,因为有很多服务器会连接到SAN。
如果Hadoop架构团队对I/O的性能要求特别高,则还是建议将临时数据放在DAS或者闪存上。但在没有DAS或者闪存时,可以用以下替代方案:
1.如果只有基于SAN或者NFS的共享存储,则将临时数据放置在这些存储上,但可能会限制整个系统的可扩展性。
2.可以将临时数据放置在NAS设备的专门区域上,通过配置合适的网络来实现。
所有DataNode和NameNode中的数据都会被安全的保存在NAS设备中。进出NAS的流量都会走VM专有的交换机和网口,这些会映射到一些物理交换机。这些交换机在Isilon的前端,即请求先进交换机。
这种设计的一个明显优势是集中存储重要的业务数据,同时仍然提供正常的HDFS接口。同时也可以减少管理单个主机上单个DAS的时间。
更多使用NAS存储来搭建Hadoop集群可以查看参考文章[11]和[21]。
3.5.部署方式总结
在本节中,我们讨论了Hadoop虚拟化的两种不同部署选择。对于用户的规划选择哪种模式我们也都给出了一些指引。两种选择没有绝对的优劣,更多的还是看应用程序对存储的需求。
3.6.系统可用性
当企业完成Hadoop应用需求调研以及设计后,会考虑开始规划VM的资源要求。这个规划包括了系统的可用性。本节我们就讨论一下可用性。CPU,内存,存储,网络以及硬件架构配置会在后面的章节中讨论。Hadoop本身的架构保证了很多恶劣情况下的可用性,比如服务器或者存储故障。我们在下面的章节讨论时会将管理节点和工作节点分开,因为它们的保护要求是不一样的。Hadoop的设计是工作节点故障不是太重要,主要是需要考虑管理节点。
3.7.管理节点的可用性
Hadoop集群在确保其管理节点可用时,需要一切功能正常运行。在管理节点中,NameNode,ResourceManager和ZooKeeper是最重要的,尽管它们不是唯一的管理角色进程。早期的Hadoop版本中的管理节点没有高可用方案,但是在后面的版本中都得到了改进和优化。现在这些管理角色,都有第二个进程运行在其他单独的VM上。比如NameNode,是active-passive的方式,但是另一个NameNode是热备,随时切换,保证了HDFS的高可用。
管理节点为Hadoop集群正常运行提供关键服务。如果没有NameNode,则无法访问或修改HDFS中的数据。如果没有ResourceManager,则无法提交作业到集群上,以及无法进行资源管理。因此需要更广泛的高可用解决方案,而vSphere的一些其他功能恰好可以提供。
虚拟化使重要程序的高可用变的更加容易。例如,通过使用vSphere的一些关键特性,可以让运行管理节点服务的虚拟机不间断的持续运行,即使碰到硬件故障如重启服务器失败。
3.7.1.vSphere的高可用
通过利用多个ESXi主机配置为一个vSphere HA集群可以减少意外停机。可以快速的在服务器或者应用程序中断后恢复,也就为运行在VM中的应用程序提供了经济高效的高可用解决方案。
vSphere通过以下方式保护Hadoop应用程序的可用性:
1.当原有的主机服务器发生故障或者网络连接失败时,它可以在vSphere集群内的活动主机服务器上重新启动VM来防止硬件故障和网络中断。
2.通过持续监控VM并根据需要重新启动来防止操作系统(guest OS)故障。
3.它提供了一种机制来应对应用程序故障。
4.它作为基础架构,可以保护集群内所有的工作负载。
当为vSphere集群的服务器配置vSphere HA之后,不需要执行任何操作来保护新的VM。如果所有VM的数据都存储在共享存储中,那么位于vSphere HA集群内主机上的这些VM将自动被保护。vSphere HA可以与VMware vSphere Distributed Resource Scheduler(vSphere DRS)结合使用,以防止发生故障并在集群内的主机之间提供负载均衡。
Hadoop集群中的NameNode和ResourceManager允许短暂的故障。如果这些主机的硬件,操作系统或者管理软件发生故障,则整个Hadoop集群可能会出现问题(degraded)。可以通过在vSphere HA集群中部署这些角色来解决。
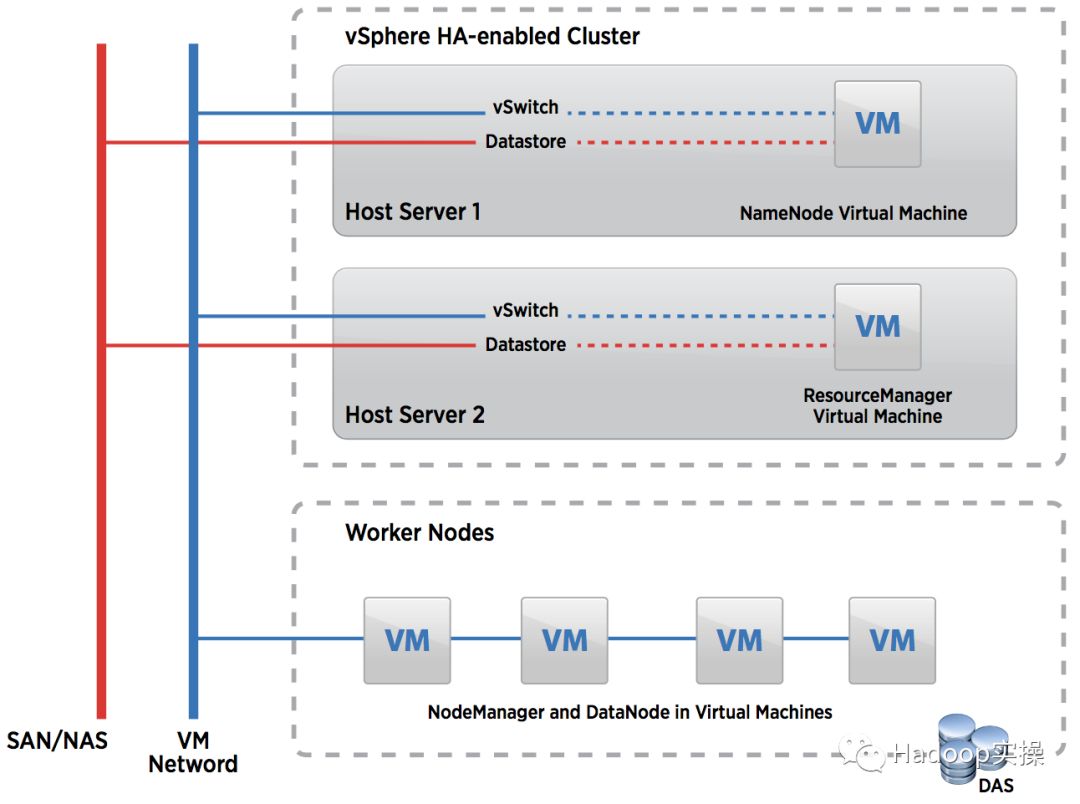
图5:Virtualized Hadoop Architecture Example
图5展示了一个非常简单的启用了vSphere HA的集群示例,该集群由许多ESXi服务器主机组成,以运行NameNode和ResourceManager的VM。其他的管理角色也可以部署在这些VM上,比如Zookeeper。
如果安装了NameNode和ResourceManager的vSphere主机服务器意外故障,则vSphere集群中另一台主机服务器可以调起合适的VM来解决这个问题。这个机制可以与Hadoop系统中的Secondary NameNode进程一起协同工作。
为了存储受保护VM中的数据,需要共享存储比如SAN或者vSAN。管理员可以使用VMware vCenter在vSphere集群上初始化配置vSphere HA功能。更多信息请参考[19]
3.7.2.vSphere容错
vSphere FT的容错功能适用于单个虚拟机。它为那些需要它的系统组件提供比vSphere HA更高级别的故障转移。当在vCenter中将虚拟机配置为容错时,Secondary虚拟机会在单独的主机服务器上与这个主虚拟机同步运行。如果启用了vSphere FT的主虚拟机发生故障时,则Secondary虚拟机会立即接管该虚拟机,而不会导致虚拟机操作系统(guest OS)内进程的中断。然后新的主虚拟机会由新的Secondary虚拟机进行备份,与最开始的容错能力一样。当在特定VM上启用vSphere FT时,vSphere会自动执行所有这些功能。
此vSphere FT功能适用于需要运行关键任务或者进程的虚拟机,比如需要几乎零停机时间的生产系统。vSphere FT需要共享存储才能实现该功能。保护Hadoop系统中关键进程的容错问题具体参考[13]。
3.8.工作节点的可用性
一个Hadoop集群中工作节点的虚拟机占了大多数,远远超过管理节点的虚拟机。在一个Hadoop集群里,有时候你会发现只有五个管理节点,而却有数百个工作节点。Hadoop集群的工作节点自带容错能力,可以检测工作节点发生故障并对集群进行自动修复。如果一个或多个工作节点发生故障,集群的计算能力会减小,但是Hadoop集群可以继续对外提供服务,直到发生故障的工作节点被修复并重新加入集群。
许多架构师遇到了一个问题,即当该节点出现故障时,工作节点中DataNode进程管理的数据会发生什么情况。源生的Hadoop就实现了DataNode中的一份数据库会被默认复制到另外2个节点。这一点在虚拟化的环境中也是一样的。
如果一台工作节点虚拟机中的数据块因为某些原因导致不可用,这些数据块你可以在集群中其他虚拟机上找到它们的副本。VMware为Apache Hadoop提供了源码级别的补充,以使HDFS的副本存储机制能够运行在vSphere上。这个新增的功能叫Hadoop Virtualization Extensions(HVE)。HDFS的HVE实现是完整HVE的子集,可确保文件块复制算法能够在VM环境中正常运行。VMware贡献的代码是对Hadoop物理部署拓扑的一种扩展。HVE技术适用于主流Apache Hadoop发行版。具体参考[12]。
如前所述,Hadoop集群的工作节点自带容错能力,可以检测工作节点发生故障并对集群进行自动修复。尽管工作节点不一定需要vSphere HA支持,但是用vSphere管理所有主机服务器还是有优势的。但Hadoop集群的虚拟化在部署自动化,数据中心整合,更高的资源利用率,系统管理以及所有节点的统一监控和管理提供了运营优势。vSan的存储机制可以跨所有的这些主机服务器,这样工作节点虚拟机你同样也可以使用vSphere HA,就像管理节点虚拟机一样。
3.9.硬件注意事项
硬件和Hadoop商业版本供应商都为配置Hadoop集群提供了硬件的建议。在虚拟化环境中部署Hadoop中你还需要考虑其他的一些重要事情。HDFS是I/O密集型的,所以首先你需要考虑存储。CPU和网络也同样重要。
虚拟化环境中如何进行设计和规划,可以参考 [1], [2], [3]和[4]。下表1提供了CPU,内存和磁盘的一些规范参考,这些规范构成一个初始的可用于POC的Hadoop集群的基准。

表1:工作节点的CPU,内存和磁盘配置
系统管理员在考虑如何选择硬件规格时,对于一些特别的设置需要严格遵守Hadoop厂商的要求和建议。
避免过度使用物理内存等硬件资源。服务器上所有虚拟机中的虚拟CPU(vCPU)应该与逻辑核数相匹配,避免产生CPU电源争用。
对于ResourceManager和NameNode角色,考虑部署额外的内存和辅助电源,以确保集群中这些关键服务器的高性能和可靠性。因为Hadoop数据节点的容错性,所以不需要在部署工作节点VM的ESXi服务器上部署冗余电源。
4.vSphere上Hadoop的部署示例
本章会描述三种不同规模的虚拟化Hadoop集群的部署架构示例,分别是小型,中型和大型集群。
三种部署架构具体取决于应用程序需求,大小以及企业的具体考虑。
有些企业倾向于拥有少量的大型集群,有些则倾向于选择更多数量更小的集群。这个主要取决于企业的业务需求。当然还有一些其他的架构方式在这里不会讨论,具体参考文末的[16],[17]和[18]文章。
4.1.小型集群
VMware IT部门使用此Hadoop部署模式用来分析客户的故障报告,购买行为和其他较为重要的应用。这是典型的Poc集群架构,或者生产系统前期采用。如图6所示,vSphere的四台主机在同一个机架内连接到10Gb的交换机。企业可以从这种架构开始,并在未来考虑扩容。这种架构未特别考虑集群性能以及用户期望的作业执行SLA。
如图6所示,“Hadoop Master 1” 的VM部署active ResourceManager,HiveServer2和Hive MetaStore。“Hadoop Master 2”的VM部署standby ResourceManager,Application History Server和Application Timeline Server。其他五个“Hadoop Worker”的VM主要是部署NodeManager进程以及支持Pivotal SQL查询引擎的其他进程
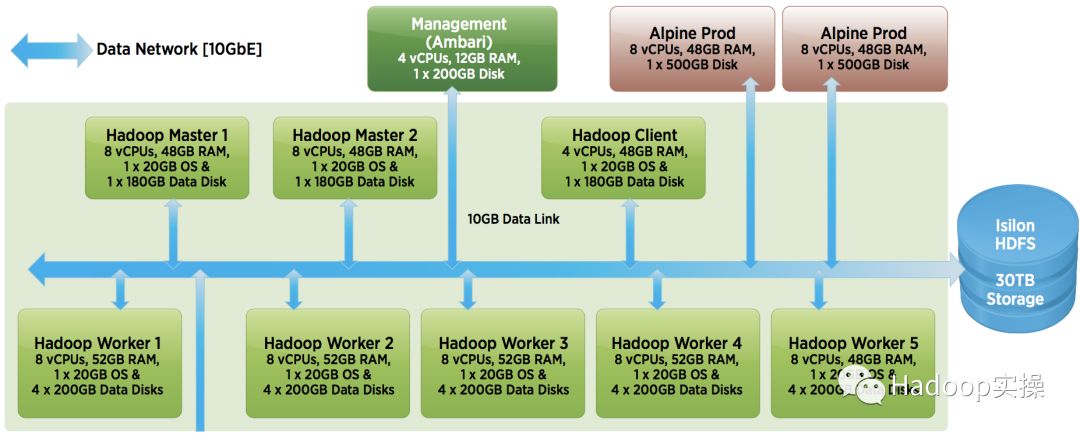
图6:小型集群的Hadoop虚拟化部署
图6还显示了部署第三种角色的VM。 “Hadoop Client”的VM主要用来部署Hive,HDFS,Pig和YARN的客户端配置,包括Zookeeper。最后就是Manager管理进程比如Ambari或者Cloudera Manager,也属于客户端VM。所有的HDFS数据是存储中在Isilon中,图6的右边即是。对于临时或者spill数据,使用的是从一组单独的共享存储设备映射而来的LUNs,是NetAPP的存储产品。因为这个集群规模不大,所以这种共享存储的设计也能满足应用需求。
集群中会运行多种不同的工作负载。一个例子是某种应用程序可以运行在图6右上角的“Alpine”的VM中。在虚拟化的Hadoop集群中,同时运行几种不同的工作负载是比较常见的。其他工具也会被放置在这个集群中,随着时间的推移,应用场景也会慢慢增多。硬件和软件的架构也会慢慢扩展。
在前期刚刚搭建集群时,Hadoop自带的一些基准测试程序如TeraSort也会用到,为了集群后期更好的提供生产而做准备。图6这种架构通常可以用于点击流数据,日志数据以及访问数据的内部IT访问。更多资料,请参加参考文献[14]。
在下一节中,我们将讨论中等规模集群的架构,更多的资源分配,以及性能优化考虑。
早期的小规模Hadoop集群,一般少于25个VM节点,大概6-12个vSphere主机服务器,一般也就在一个物理机架中。这意味着所有的网络流量取决于一个机架的网络。
相比之下,较大的Hadoop集群一般都由多个机架内的服务器一起构成。每台服务器连接到机顶交换机(ToR), 机架通过主干,聚合或者核心交换机进行连接。
这些交换机的数据交互传输速度可能是整个系统性能的关键因素。当跨节点的数据复制流量较为可观时,机架间的流量可能成为系统性能的瓶颈。ToR交换机可以配置为两个作为互备,从而当一个ToR出现问题依旧保证集群的正常运行。
4.2.中型集群
VMware工程师使用装有32台主机服务器的单个机架,对包含Hadoop on vSphere的各种配置和数量的VM进行比较重要且长时间的性能测试。如图7所示,该架构使用2个10GbE的网络交换机来连接各个服务器。这样可以最大限度的降低甚至消除网络瓶颈。如果你想在虚拟化环境进行Hadoop性能测试,这里提供的架构是一个不错的参考。
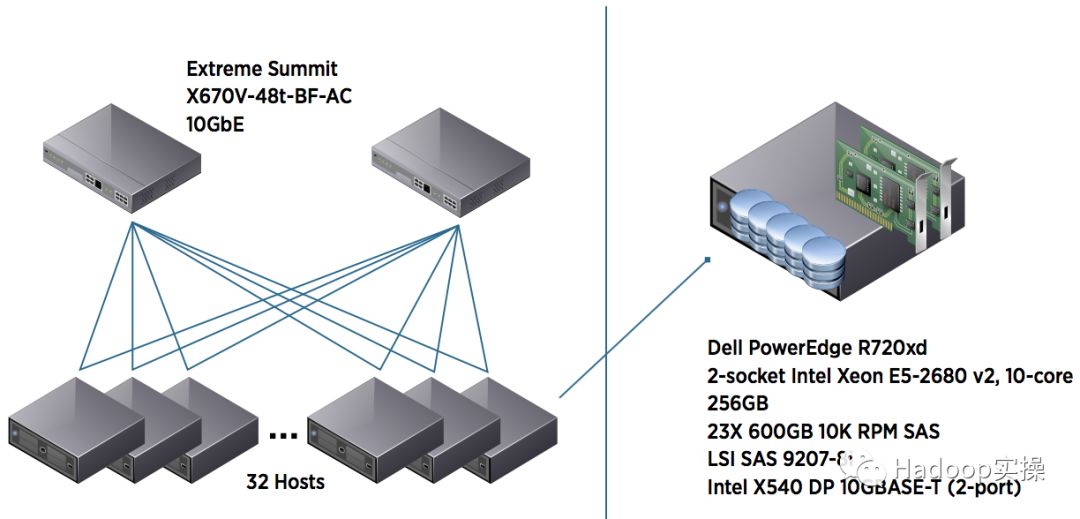
图7:中型集群的Hadoop虚拟化部署
每台服务器都有2个万兆网口,每个网口会连接到单独的万兆交换机。用图7所示的架构进行的基准测试的程序以及结果,在参考文献[1]中都可以找到。这个测试使用的是前面介绍的原始的Hadoop部署模型,计算和存储在同一个VM上作为工作节点。在每台物理服务器上,使用两个,四个甚至更多的VM来作为Hadoop节点,可以较为高效的实现高性能,与物理部署Hadoop相当。基于图7的架构,你可以构建128个VM,相当于Hadoop集群一共有128个节点,我们将此定义为中型集群,目前,较多的企业属于这一类,即集群的节点数并不是太多。
接下来,我们开始大型集群的介绍,往往包括多个机架,多个服务器以及更多的VM。
4.3.大型集群
图8所示的大型集群,刚开始属于中型集群,在几个月内发展到大型集群占用160多台服务器包括320多个虚拟机。起初使用了8个机架,随着时间的发展,该架构扩展到更多的机架,超过220多台服务器,虚拟机发展到之前的两倍,包含2个以上的Hadoop集群。
这个虚拟化的Hadoop集群起初跨8个机架,每个机架包含20台服务器。早期我们决定将每个服务器划分为2个VM。每台服务器包含里面的VM要不就部署管理角色,要不就部署为工作节点。因为每个服务器只划分为2个VM,所以一旦服务器故障不会导致很多VM出现问题。图8中的橙色代表的是管理节点的VM以及服务器。绿色的则全部都是工作节点。
架构团队为了构建独立的vSphere集群,将该Hadoop集群拆分为5个vSphere集群,每个集群都横跨8个机架,包含32台服务器。具体可以查看图8的蓝色标题。vSphere的集群也可以设计为跨一个垂直机架。vSphere集群的服务器数量目前已增加到64个。有了vSphere集群,就可以较为方便的将服务器添加到已有的Hadoop集群。Hadoop集群的大小和vSphere的集群大小是不同的。
使用叶脊(leaf-spine)拓扑网络,每个叶子交换机是10GbE,主干交换机是40GbE的。每台服务器有16块DAS磁盘,平分到2个VM,即每个VM是8块硬盘。每个VM还会配置120GB内存以及16个vCPU,这些参数使得vSphere hypervisor将每个虚拟机维护在一个physical socket中,并位于其NUMA(nonuniform memory access)内存节点边界内,从而提供最佳搭配和性能。
除了在虚拟化Hadoop环境中部署重要的应用程序外,前期测试的一个目标就是看看基于同一个服务器多个并发的工作负载对不同的VM的影响,测试程序使用的是依赖Hadoop核心和其他组件。最后测试证明,多个Hadoop集群可以在同一组硬件上共存,不会相互干扰。具体可以查看参考文献[5]。
图8:大型集群的Hadoop虚拟化部署,跨多个机架
大型集群的部署示例演示了大规模的Hadoop集群可以部署在vSphere之上的VM中,其运行性能与本地物理部署相当甚至还要好。同时证明了一个Hadoop集群可以与另一个相邻集群共享来自不同供应商的硬件,你可以使用不同的Hadoop版本,也可以安装不同的服务。通过改变工作节点VM的数量,每个集群都可以实现动态的扩容和减容。如果你选择本地物理部署,扩容和减容你很难达到与VMware相当的效率。
5.最佳实践
本章介绍在虚拟化环境中运行Hadoop,主要的计算资源比如磁盘,CPU和内存的一些最佳实践。但本章还是以介绍为主,更多细节可以查看参考文献[1]和[4]。
一般来说,可以在虚拟化的Hadoop集群中使用最新的硬件。这样可以提供最佳的CPU时钟速度,内核数量,超线程,物理内存以及缓存大小。
由应用程序基础架构,编程框架和各种工具组成的Hadoop生态系统,一直在持续的改进和完善。一旦发生变化时,根据我们的经验也会告诉大家新的最佳实践,以跟随社区主流的发展方向。比如,Spark正在超越MapReduce。更多细节,请查看参考文献[1],[2]和[4]。
5.1.Disk I/O
尽管Hadoop可以使用各种类型的存储,但本章主要是讨论DAS类型的存储,这也是Hadoop厂商推荐的。如果想使用其他类型的存储,可以参考相应厂商的文档。
1.磁盘的数量
为了获得最佳性能,使用越多的DAS磁盘,性能会越好。因为NodeManager和DataNode进程都非常依赖于磁盘I/O(单盘每秒100MB到150MB),所以你磁盘越多,并发支持越多,就越不会发生单盘的瓶颈问题。
有些vSphere主机有8块本地磁盘,有些服务器则可能是它的2-3倍。对于较大的服务器,Hadoop厂商可能会推荐使用32块硬盘。服务器使用太多的硬盘也有一些缺点。比如更多的磁盘,会增加系统管理员运维DAS磁盘的时间和工作量。
2.每个核对应的磁盘数
为每个核或者vCPU配置1-1.5块磁盘。这个建议与Hadoop厂商的推荐是一致的。对于架构师和系统管理员来说,这种配比方式,也是在前面描述的DAS越多性能越好,与管理更多磁盘的成本更高之间的一种折衷。
3.带宽
为每个核或者vCPU提供至少每秒100MB的带宽。对于SATA磁盘,相当于每个vCPU大约一个磁盘。
4.转速
7200RPM以上的SATA或者SAS都还不错。
5.Striping和RAID
存储HDFS数据的磁盘不建议配置为RAID,因为HDFS本身具有数据块复制的功能,再配RAID会造成存储空间的浪费。如果服务器使用了RAID控制器,可以将磁盘配置为直通模式。如果RAID控制器不支持直通,可以将每个物理磁盘以RAID0的格式创建单个LUN或者虚拟磁盘。
注意:这里的虚拟磁盘是有些厂商特有的概念,而不是VMDK。
与Hadoop厂商的建议一致,在虚拟化Hadoop环境中,对于磁盘也不要使用LVM,RAID和IDE技术,尤其是I/O密集型场景。
6.磁盘控制器
确保本地磁盘控制器有足够的带宽来支持所有的本地磁盘。
5.1.1.规划磁盘空间
Hadoop集群的部署往往会从小规模开始,随着数据量的增长,部署的应用程序越来越多,会慢慢扩容。在虚拟化环境中,通过从现有模板克隆新的VM可以实现快速的Hadoop集群扩容,通过关闭VM又可以达到Hadoop集群减容的目的。
在计划部署一个Hadoop集群时,要用多少存储空间是一个很重要的指标,需要认真对待。我们需要预测数据的增长,临时数据的大小以及Hadoop的副本策略等。特别是根据HDFS所配置的复制因子,加载到HDFS中文件可能是原始数据的三倍或者更多倍。
一个规划存储空间的例子如下:
1.默认情况下,每个HDFS数据库都有三个副本。在规划DataNode的数据空间时尤其需要考虑这一点。
2.HDFS数据块的复制因子根据不同的Hadoop应用程序可以配置为不同。系统架构师可以找应用的同事了解复制策略。
简单规划磁盘例子如下:
1.假设数据增量每周为3TB
2.默认情况下,HDFS的复制因子配置为3
3.因此,每周额外需要9TB的存储空间
4.临时数据空间按照与输入数据一样大小计算。计算结果为每周12TB
5.假设一台服务器是12块3TB的磁盘,那么每3周就需要加入一台新的服务器。
5.1.2.为磁盘创建对齐分区
为了存储VM的VMDK文件,vSphere使用datastore,可隐藏物理存储的特性并提供统一的存储模型。代表存储设备的datastore使用的是VMware Virtual Machine FileSystem(VMFS)格式,这是一种针对存储VM而优化的高性能文件系统格式。
Disk–datastore对齐对于实现虚拟化环境中的I/O操作效率非常重要。对齐会在两个层面实现:vSphere主机层面和每个VM的操作系统内。
1.vSphere主机层面的对齐
在磁盘上创建datastore时,使用vSphere Web UI来实现对齐。以这种方式创建datastore后,vSphere会自动在其控制的磁盘上对齐分区。
可能会出现一种情况,因为要设置很多磁盘对齐,使用vSphere Web UI做这种大量重复的工作,容易出错。对于这种情况,开发自定义的脚本来用作大规模的磁盘对齐会更靠谱。
在vSphere Web UI上通过浏览Hosts and Clusters > Configuration > Storage > Datastore来查看服务器的datastore排列。
2.VM的操作系统磁盘对齐
在虚拟机Linux操作系统中,使用fdisk -lu命令验证分区是否对齐。
5.1.3.为Hadoop集群配置磁盘
存储在datastore里的vSphere VMDK可以以多种形式创建。这里我们暂不讨论原始设备映射的形式(raw device mapping,RDM),主要关注创建VMFS磁盘的以下三种形式:
1.厚置备延迟置零(Zeroed Thick)
虚拟磁盘创建时,所有空间都分配给datastore。由于没有预先置零,所以创建起来会非常快。当虚拟机中的操作系统被写入磁盘时,由于有I/O提交,空间会被置零。置零磁盘可以保证在新磁盘上找不到来自底层存储的旧数据。
2.厚置备置零(eager zeroed thick)
使用这个方法,首次创建磁盘时,所有空间就会预先分配给datastore上的虚拟磁盘。使用厚置备置零,整个空间会被置零。所以你可能需要很长时间才能创建这些磁盘。但一旦创建完毕,它们的性能会明显比新的厚置备延迟置零的磁盘要好。厚置备延迟置零的磁盘一般需要几个小时才能达到厚置备置零的性能。
3.精简配置(Thin provisioning )
与存储阵列上的精简配置类似,VMDK精简磁盘仅在磁盘I/O活动增长时分配空间。磁盘开始很小,在空间置零时会扩展,为磁盘I/O做好准备。它不会超出其允许的大小。恰恰与你猜测的相反,精简配置不会影响性能,非常接近于厚置备延迟置零(Zeroed Thick)。精简磁盘的主要优势在于节省磁盘空间,而不用事先分配所有的空间。但是某些虚拟机OS内的磁盘操作,比如碎片整理,会导致精简磁盘膨胀。
5.1.4.选择你需要用的磁盘格式
为了避免厚置备置零(eager zeroed thick)导致的长时间的配置和创建时间,一些系统管理员在创建数据磁盘时会将厚置备延迟置零(Zeroed Thick)作为首选。
与厚置备延迟置零(Zeroed Thick)相比,厚置备置零(eager zeroed thick)明显要花比较长的时间来配置预分配磁盘。但是,这些预分配的工作可以在运行时提供更好的I/O写入性能。所以我们建议用户a)使用厚置备置零(eager zeroed thick),b)创建为懒惰(lazy)的厚置备延迟置零(Zeroed Thick)磁盘,进行零填充(zero-fill),这样可以将其更改为厚置备置零(eager zeroed thick)磁盘。
这样做是为了让所有写操作都能从磁盘预分配工作中受益,从而提高Hadoop集群的性能。零填充(zero-filling)的过程称为“预热磁盘”( warming up the disks)。根据VMware在内部实验室环境进行的测试,此预热过程可以提升性能。
有很多种“预热磁盘”(warming up the disks)的方法,从执行零填充(zero-filling)磁盘的自定义脚本到运行磁盘写入I/O密集型应用程序(比如TeraGen)都可以。系统管理员可以选择使用哪种方法。
5.2.全闪存
在写这篇文章的时候,业界正在从使用磁盘进行存储过渡到全闪存技术。VMware与一些闪存厂商进行合作比如Intel,在VMware研发实验室进行广泛的测试,以证明其作为Hadoop数据存储的实用性。这些测试使用vSAN作为跨服务器共享存储设备的控制软件。测试结果表明,全闪存存储设备与vSAN的组合在vSphere上运行的Hadoop集群支持的挺好。在企业希望将vSAN用作Hadoop的底层技术的情况下,VMware的建议是利用全闪存存储用于该部署。我们提供了这个基于全闪存的测试文档,以便想要实现这个解决方案的人参考。
5.3虚拟CPU
1.对于执行重要Java进程的VM(例如Hadoop主进程),建议至少使用两个vCPU。查看参考文献[23]了解更多细节。
2.vSphere主机上的物理CPU最好不要超用。建议的办法是在主机服务器上的所有虚拟机中配置的vCPU总数等于该服务器上的物理核心数。这种更保守的方法可以确保没有vCPU在可以执行之前等待物理CPU可用。如果发生这种类型的等待,管理员会在vSphere性能工具中看到%Ready时间在持续增长。
3.当按照推荐的在Bios中启用超线程后,则可以将主机服务器上所有虚拟机中的vCPU总数设置为等于物理内核数量的两倍 - 即等于服务器上的逻辑内核数量。这种“确切的承诺”(exactly committed)的方法适用于需要最佳性能的场景。上文提到的保守的方法和与逻辑核相等(match-to-logical-core)的方法都是可行的,后者的性能提升会更明显。
4.虚拟机vCPU的数量在一个CPU插槽的核数以内,并且为这个插槽专门使用关联的NUMA内存,性能优于跨多个插槽的大型虚拟机。建议将VM中的vCPU限制为小于或等于目标硬件上的一个CPU插槽中的核心数。这可以防止虚拟机跨多个CPU插槽,从而提高效率。可以参考下文“内存”章节的NUMA相关内容。
5.4.内存
1.服务器上虚拟机中配置的所有内存大小的总和不应超过主机服务器上物理内存的大小。
2.避免耗尽虚拟机内操作系统(guest OS)的内存。每个VM都有一个配置的内存大小,以限制其可寻址内存空间。在操作系统(guest OS)中执行一组耗尽内存的进程(如Hadoop进程)时,请确保为操作系统(guest OS)配置了足够多的内存,这样可以在不导致操作系统(guest OS)内存交换的情况下运行这些进程。
3.为了提高速度和效率,NUMA将主机服务器的内存划分为与各个处理器密切相关的部分。每个部分都是NUMA节点,并且在各种架构上具有特定的大小。通过设计VM的内存大小以适应NUMA节点的边界,常驻Hadoop工作负载的性能会最佳。这种VM布局避免了跨NUMA节点迁移或访问。如果虚拟机有足够大的内存,通过设置以跨多个NUMA节点可能会有性能影响。
4.在vSphere主机服务器的物理内存中,考虑vSphere虚拟机管理程序的内存要求。一般建议为管理程序留出6%的物理内存。
5.一个核或者vCPU数至少需要4GB内存。
5.5.网络
1.建议为Hadoop集群使用专门的交换机,如果可以,请保证每台物理服务器连接到了一个ToR交换机。
2.虚拟化Hadoop集群,运行Hadoop作业的服务器每秒至少需要10Gb的带宽。
3.根据系统的网络要求,每个核心需提供200Mb/s - 600Mb/s的聚合网络带宽。
比如:100个节点的Hadoop集群
1. 100*16 cores=1600 cores;
2. 1,600 cores x 50Mb per second =80Gb per second
3. 1,600 x 200Mb = 320Gb ofnetwork traffic
4. 1,600 x 600Mb per second =960Gb per second of network traffic
现在的服务器都有两个以上的网口。在多数情况下,对于支持Hadoop工作负载的ESXi主机来说,两个网口是不够的。在参考文献[1]中给出的示例性能配置中,32个主机服务器中的每一台都有2个网口,每个网口连接到单独的交换机以优化网络使用。
配置ESXi主机网络时,请考虑以下使用者的流量和负载要求:
1.The management network
2.VM port groups
3.IP storage (NFS, iSCSI, FCoE)
4.vSphere vMotion
5.Fault tolerance
Hadoop集群内的VM彼此通信频繁。比如,HDFS需要各个节点交换复制数据块副本。同时,工作节点也会定时向主节点发送心跳。比如,DataNodes定期将心跳消息发送给远端VM中的NameNode进程。
运行在不同虚拟机中的Hadoop进程之间会交换大量数据。在设计这部分基础架构时,支持虚拟机之间流量的网络应与前面讨论的几点分开来。在参考文献[1]中描述的性能测试中,服务器上绑定了两个网口可以提供更好的网络吞吐。
不建议使用单个网卡和单个物理交换机,必须考虑和设计虚拟机到虚拟机的冗余网络。
扩展性是另外一个考虑因素。随着集群越来越大,网络也会变得复杂。另外,管理网络配置并使其在集群中的所有主机上保持一致也会变得困难。在此,使用VMware vSphere Distributed Switch(VDS)和VMware NSX可以管理大规模的Hadoop集群。
5.5.1.vSphere虚拟交换机
vSphere虚拟交换机是vSphere虚拟化平台中的一个软件,除其他功能外,它还逻辑上连接两台虚拟机。它可能会或不会与物理交换机关联。当两台虚拟机位于同一台vSphere主机服务器上并连接到同一台虚拟交换机时,它们之间的网络流量将通过内存中的虚拟交换机。这种流量不需要走物理交换机,也不会通过主机上的物理网卡。此功能可以提高虚拟机之间的网络流量性能。vSphere中有两种类型的虚拟交换机:驻留在一台主机服务器上的标准交换机(vSwitch)和提供跨主机服务器的统一管理界面VDS。
5.5.2.vSphere分布式交换机
VDS技术通过将网络视为聚合资源,比较方便的管理交换机资源。单个主机级虚拟交换机被抽象为一个跨越数据中心级多个主机的大型VDS。端口组成为跨越多个主机的分布式虚拟端口组(dvport groups),并确保VM和虚拟端口必要配置的一致性。这些可以用于vSphere vMotion迁移和网络存储等功能。VDS适用于本文讨论的所有类型的网络。有关vSphere这方面的更多详细信息,请参阅vSphere文档。
5.5.3.为虚拟化Hadoop使用VMware NSX
部署VMware NSX产品用于虚拟网络对于vSphere上的Hadoop具有许多独特的优势。本章不会讨论所有这些好处,而会专注在讨论适用大数据许多场景的一个简单用例。此用例涉及通过在虚拟网络级别进行分段(segmentation)来隔离不同的Hadoop集群及其用户。
企业内不同的用户和用户组在访问不同集群上的应用程序时,为了访问,安全性和数据可见性考虑,必须将这些集群彼此分开。例如,HIPAA,PCI,SOX等不同数据集的不同法规遵从(regulatory compliance)级别的要求。另一个例子是因为共享底层基础架构时,在投产前,开发人员和测试人员需要隔离。
一般需求是要求隔离企业内不同业务部门或小组的使用和访问。同样的原则适用于为多个外部租户提供服务的应用程序和云供应商。这也就是我们经常说的多租户,每个租户拥有一个或多个独立的Hadoop集群,并拥有其自己的数据。根据策略理论不允许跨Hadoop集群访问数据。
VMware NSX分布式防火墙技术允许将一个租户及其Hadoop集群与另一个集群在共享环境中隔离。VMware NSX的分布式防火墙组件允许通过策略控制防止一组虚拟机的用户访问防火墙组以外的任何其他虚拟机和数据。
这种方法使用户能够继续使用他们现有的VLAN和VXLAN。隔离是在虚拟机到虚拟机层面实现的,而不是在硬件层面。每个隔离的单位被称为一个段(segment),整体架构被称为microsegmentation。即使在公共主机服务器上,单独的段(segment)存在虚拟机,也可以使用此方法。它也独立于一组虚拟机可能连接的逻辑交换机。
6.总结
本部署指南讨论了在VMware vSphere上部署Hadoop的各种架构。虚拟化减少了Hadoop架构师和管理员配置和管理一个或多个Hadoop节点集群所需的时间和精力。用户可以随意创建集群,并实现多租户。
通过从硬件服务器上抽象出Hadoop,在vSphere平台上部署Hadoop显得更加灵活。通过组合虚拟机,它还可以提高任何一台服务器上的处理密度,即提高资源使用率。
本文讲述了各种部署架构,为你在vSphere上搭建Hadoop集群提供选择依据。例如,分离Hadoop的存储和计算,使用直连存储(DAS),以及通过其他机制存储各种数据。
本文介绍了如何使用vSphere成功的开发,测试和投产Hadoop应用,通过整合Hadoop和vSphere技术,可提供独特的管理和性能优势。
7.关于作者
Justin Murray是VMware的资深架构师。他从2007年开始在VMware工作,担任过多种职位,主要专注于帮助客户和合作伙伴使用VMware产品在Hadoop和其他平台上部署应用程序。为此,他为虚拟化和应用领域的架构师提供技术材料,并定期就这些主题进行宣讲。
8.参考文献
在VMware vSphere上虚拟化Hadoop的更多技术内容可以在以下文档中找到:
[1]Virtualized Hadoop Performance with VMware vSphere 6 on High-PerformanceServers
http://www.vmware.com/resources/techresources/10452
[2] ABenchmarking Case Study of Virtualized Hadoop Performance on VMware vSphere 5
http://www.vmware.com/files/pdf/VMW-Hadoop-Performance-vSphere5.pdf
[3]Virtualized Hadoop Performance with VMware vSphere 5.1
http://www.vmware.com/resources/techresources/10360
[4] BigData Performance on vSphere 6 – Best Practices for Optimizing Virtualized BigData Applications
http://www.vmware.com/content/dam/digitalmarketing/vmware/en/pdf/techpaper/bigdata-perf-vsphere6.pdf
[5]Deploying Hortonworks Data Platform (HDP) on VMware vSphere – A Technical Reference Architecture
http://hortonworks.com/wp-content/uploads/2014/02/1514.Deploying-Hortonworks-Data-Platform-VMware-vSphere-0402161.pdf
[6]vSphere Resource Management
http://pubs.vmware.com/vsphere-55/topic/com.vmware.ICbase/PDF/vsphere-esxi-vcenter-server-551-resource-management-guide.pdf
[7]Scaling the Deployment of Multiple Hadoop Workloads on a Virtualized Infrastructure
http://www.intel.com.tr/content/dam/www/public/us/en/documents/articles/intel-dell-vmware-scaling-the-deployment-of-multiple-hadoop-workloads-on-a-virtualized-infrastructure.pdf
[8]Toward an Elastic Elephant – Enabling Hadoop for the Cloud
http://labs.vmware.com/vmtj/toward-an-elastic-elephant-enabling-hadoop-for-the-cloud
[9]Cloudera Reference Architecture for VMware vSphere with Locally Attached Storage
http://www.cloudera.com/content/cloudera/en/documentation/reference-architecture/latest/PDF/cloudera_ref_arch_vmware_local_storage.pdf
[10]Cloudera Enterprise Reference Architecture for VMware Deployments with Isilon-based Storage
http://www.cloudera.com/content/cloudera/en/documentation/reference-architecture/latest/PDF/cloudera_ref_arch_vmware_isilon.pdf
[11] EMC Isilon Hadoop Starter Kit for Cloudera
http://hsk-cdh.readthedocs.io/en/latest/
[12]Hadoop Virtualization Extensions on VMware vSphere 5 http://www.vmware.com/files/pdf/Hadoop-Virtualization-Extensions-on-VMware-vSphere-5.pdf
[13]Protecting Hadoop with VMware vSphere 5 Fault Tolerance http://www.vmware.com/files/pdf/techpaper/VMware-vSphere-Hadoop-FT.pdf
[14]Virtualizing Big Data at VMware IT – Starting Out at Small Scalehttp://blogs.vmware.com/vsphere/2015/11/virtualizing-big-data-at-vmware-it-starting-out-at-small-scale.html
[15]VMware vSphere VMFS: Technical Overview and Best Practices http://www.vmware.com/techpapers/2010/vmware-vstorage-virtual-machine-le-system-tech-10110.html
[16]Adobe Deploys Hadoop-as-a-Service on VMware vSphere http://www.vmware.com/files/pdf/products/vsphere/VMware-vSphere-Adobe-Deploys-HAAS-CS.pdf
[17]Virtualizing Hadoop in Large-Scale Infrastructures – EMC Technical White Paper
https://community.emc.com/docs/DOC-41473
[18]Skyscape Cloud Services Deploys Hadoop in the Cloud on VMware vSphere
http://www.vmware.com/files/pdf/products/vsphere/VMware-vSphere-Skyscape-Cloud-Services-Deploys-Hadoop-Cloud.pdf
[19]Hadoop 1.0 High Availability Solution on VMware vSphere
http://docplayer.net/5884381-Apache-hadoop-1-0-high-availability-solution-on-vmware-vsphere-tm.html
[20] BigData with Cisco UCS and EMC Isilon: Building a 60 Node Hadoop Cluster (using Cloudera)
http://www.cisco.com/c/dam/en/us/td/docs/unied_computing/ucs/UCS_CVDs/Cisco_UCS_and_EMC_ Isilon-with-Cloudera_CDH5.pdf
[21] EMCIsilon Hadoop Starter Kit for Hortonworks HDP
http://hsk-hwx.readthedocs.io/en/latest/
[22]Trujillo, G., et al. Virtualizing Hadoop. VMware Press, 2015.
http://www.pearsonitcertication.com/store/virtualizing-hadoop-how-to-install-deploy-and-optimize-9780133811025
[23]Enterprise Java Applications on VMware – Best Practices Guidehttp://www.vmware.com/files/pdf/techpaper/Enterprise-Java_Applications-on-VMware-Best-Practices-Guide.pdf
[24]Apache Hadoop Web Site
http://hadoop.apache.org/
[25]Sammer, E. Hadoop Operations. O’Reilly Media, 2012.
[26] BigData in the Enterprise – Network Design Considerations
http://www.cisco.com/en/US/prod/collateral/switches/ps9441/ps9670/white_paper_c11-690561.html
提示:代码块部分可以左右滑动查看噢
为天地立心,为生民立命,为往圣继绝学,为万世开太平。
温馨提示:要看高清无码套图,请使用手机打开并单击图片放大查看。
推荐关注Hadoop实操,第一时间,分享更多Hadoop干货,欢迎转发和分享。
以上是关于如何在VMware上部署Hadoop的主要内容,如果未能解决你的问题,请参考以下文章